(2018-2021年)Uncertainty 相关SOTA文献笔记整理
Uncertainty 文献笔记
-
- ACL
-
- Word-Level Uncertainty Estimation for Black-Box Text Classifiers using RNNs
- Unsupervised Quality Estimation for Neural Machine Translation
- Self-Training Sampling with Monolingual Data Uncertainty for Neural Machine Translation
- Improving Back-Translation with Uncertainty-based Confidence Estimation
- EMNLP
-
- Towards More Accurate Uncertainty Estimation In Text Classification
- Understanding Neural Abstractive Summarization Models via Uncertainty
- Uncertainty-Aware Semantic Augmentation for Neural Machine Translation
- NIPS
-
- Ovadia, Y., Nado, Z., & Dillon, J. V. (2019). *Can you trust your model‘s uncertainty.pdf*. *NeurIPS*.
- Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
- Detecting Out-of-Distribution Translations with Variational Transformers
- What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?
- AAAI
-
- Addressing the Under-Translation Problem from the Entropy Perspective
- Quantifying Uncertainties in Natural Language Processing Tasks
- Building Calibrated Deep Models via Uncertainty Matching with Auxiliary Interval Predictors
- ICLR
-
- DEEP ORIENTATION UNCERTAINTY LEARNING BASED ON A BINGHAM LOSS
- QUANTIFYING POINT-PREDICTION UNCERTAINTY IN NEURAL NETWORKS VIA RESIDUAL ESTIMATION WITH AN I/O KERNEL
- UNCERTAINTY ESTIMATION AND CALIBRATION WITH FINITE-STATE PROBABILISTIC RNNs
- UNCERTAINTY-GUIDED CONTINUAL LEARNING WITH BAYESIAN NEURAL NETWORKS
- MODELING UNCERTAINTY WITH HEDGED INSTANCE EMBEDDING
- DETECTING OUT-OF-DISTRIBUTION TRANSLATIONS WITH VARIATIONAL TRANSFORMERS
- others
-
- Phrase-level Active Learning for Neural Machine Translation
一边读论文,一边思考最近大家在这块都研究哪些内容,然后考虑哪些点还有进一步研究的价值.
ACL
Word-Level Uncertainty Estimation for Black-Box Text Classifiers using RNNs
摘要:
估计神经网络预测的不确定性为更可靠和可信的文本分类铺平了道路。然而,常见的不确定性估计方法仍然是黑盒,没有解释哪些特性导致了预测的不确定性。这阻碍了用户理解不可靠模型行为的原因。本文提出了一种文本分类器不确定性在word level上的分解和可视化方法。我们的方法建立在递归神经网络RNN和贝叶斯模型的基础上,以便提供不确定性的详细解释,从而对不可靠的模型行为进行更深层次的推理。我们进行了初步的实验,以检验我们的方法的影响和正确性。通过解释和研究情感分析任务的预测不确定性,我们认为我们的方法能够提供更深刻的理解人工决策。
Introduction重点:
-
decomposition of uncertainties on the level of words.
-
We present a novel uncertainty modelling approach that estimates word-level uncertainties in any text classification task.
具体方法:
- applies Bayesian modelling to a sequence attribution technique for Recurrent Neural Networks (RNNs). We implement the approach using TensorFlow and Keras and demonstrate its effectiveness by investi- gating word-level uncertainties in a sentiment analysis task.
How we model uncertainty in a classification task and then describe how we decompose the prediction uncertainties on the level of words.
uncertainty modelling technique called Monte Carlo Dropout:
Unsupervised Quality Estimation for Neural Machine Translation
摘要:
质量估计(QE)是使机器翻译(MT)在现实应用中有用的一个重要组成部分,因为它的目的是在测试时告知用户MT输出的质量。现有的方法需要大量的专家注释数据、计算和训练时间。作为一种替代方案,我们设计了一种无监督的量化宽松方法,在这种方法中,除了MT系统本身,不需要培训或获取额外资源。与目前大多数将机器翻译系统视为黑箱的工作不同,我们探索从机器翻译系统中提取的有用信息,作为翻译的副产品。通过使用不确定性量化的方法,我们实现了与人的质量判断很好的相关性,可以与最先进的监督qmodels相媲美。为了评估我们的方法,我们收集了第一个支持QE黑箱和玻璃箱方法的数据集。
Introduction重点:
it is crucial to have a feedback mechanism to inform users about the trustworthiness of a given MT output。
Quality estimation (QE) aims to predict the quality of the output provided by an MT system at test time when no gold-standard human translation is available.
we propose an alternative glass-box approach to QE that allows us to address the task as an unsupervised problem.
We posit that encoder-decoder NMT models offer a rich source of infor- mation for directly estimating translation quality: (a) the output probability distribution from the NMT system (i.e., the probabilities obtained by applying the softmax function over the entire vocabulary of the target language); and (b) the attention mechanismused during decoding. Our assumption is that the more confident the decoder is, the higher the quality of the translation.编解码器的NMT模型为直接估计翻译质量提供了丰富的信息来源:(a) NMT系统的输出概率分布(即应用softmax函数对目标语言的整个词汇库所获得的概率);(b)解码过程中的注意机制。我们假设解码器越自信,翻译的质量就越高。
深度神经网络(NNs)的输出概率通常不能很好地校准,也就是说,不能代表预测的真实相似度。而soft Max函数容易使得模型过自信,指预测得到的概率质量非常大但是离训练数据很远.
我们提出了一些方法,通过探索不确定性量化方法来更好地估计概率,从而开发出超出top-1预测的输出分布.
We analyze to what extent meaningful information on translation quality can be extracted from multihead attention.
在不同的NMT系统中模型可信度与翻译质量之间的关系
实验表明,从校准良好的NMT模型概率中获得的无监督量化指标在与人类判断的相关性方面可以与强监督的SOTA models相匹敌
Quantifying Uncertainty
Uncertainty quantification in deep learning typically relies on the Bayesian formalism.
深度学习中的不确定性量化通常依赖于贝叶斯公式。
贝叶斯神经网络通常会带来高昂的计算成本,各种各样的逼近方法已经被开发出来以减轻这种负担。
比如Monte Carlo (MC) dropout。
The performance of uncertainty quantification methods is commonly evaluated by measuring calibration.
study the relation between model probabilities and human judgments of translation correctness.
In fact, metrics that 《improving back-translation…》那篇文章 report to perform the best for back-translation do not perform well for QE。
作者提出非监督的QE,主要根据:
1.模型的输出概率分布

compute the entropy of softmax output distribution over target vocabulary of size V at each decoding step and take an average to obtain a sentence-level measure:计算每个解码步骤softmax输出分布在大小为V的目标词汇上的熵,取平均值,得到句子级测度:
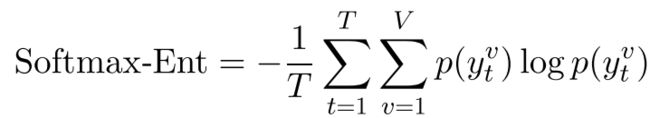
我们假设 单个单词的概率可能提供有用的信息,但取平均值时不可避免地会丢失这些信息。举例来说,考虑单词概率序列[0.1,0.9]和[0.5,0.5]具有相同的平均值,但可能表明NMT系统的行为非常不同,因此输出质量也不同。为了使这种直觉形式化,我们计算了字级对数概率的标准差:

2.不确定性量化评估
使用Monte Carlo (MC) dropout评估模型和数据的不确定性,通过网络进行几次前向传递,并收集由参数受dropout扰动的模型产生的后验概率,Mean and variance of the resulting distribution can then be used to represent model uncertainty.

接着,we measure lexical variation between the MT outputs generated for the same source segment when running inference with dropout. 也就是针对同一个源句子输入,使用MC dropout输出的不同target句子,比较他们的lexical variation。
提出了一个方法,度量不同target之间的相似性:

3.使用attention weights
Attention weights表示源标记和目标标记之间的连接强度,这可能是翻译质量的指标,使用类似熵的定义:

由于transformer对组合很多(不同数目的head,encoder-decoder layers)我们提出计算每个可能的头/层组合的熵值,然后选择最小值或计算平均值
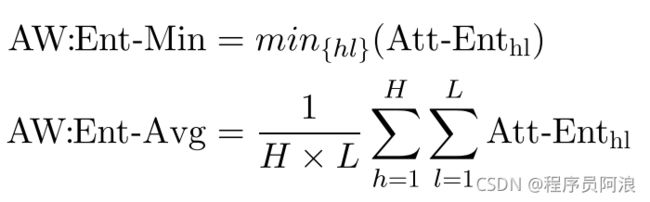
Multilingual Dataset for QE
然后说白了就是构造数量不同对high-, medium-, and low-resource的数据集
evaluate how well a model represents uncertainty is to measure the difference in model confidence under domain shift。A well-calibrated model should produce low confidence estimates when tested on data points that are far away from the training data。
Self-Training Sampling with Monolingual Data Uncertainty for Neural Machine Translation
摘要:
自训练被证明是利用合成并行数据增强模型训练的有效方法。通常的做法是基于大规模单语数据的随机抽样子集来构造合成数据,我们发现这些数据是次优的。在这项工作中,我们建议通过选择信息最丰富的单语句子来补充平行水平数据来改进抽样过程。为此,我们利用从平行数据中提取的双语词典计算单语句子的不确定性。从直觉上看,不确定性较低的单语句子通常对应于易于翻译的模式,这可能不会提供额外的收获。因此,我们设计了一种基于不确定性的抽样策略,以有效地利用单语数据进行自训练,其中不确定性越大的单语句子的抽样概率越大。在大规模WMT英、德、英、汉数据集上的实验结果表明了该方法的有效性。广泛的分析表明,强调单语不确定句的学习,不仅提高了high-uncertainty sentences的翻译质量,而且有利于目标侧low-frequency words的预测。
Introduction重点:
Self-training (Zhang and Zong, 2016) is one of the most commonly used approaches for data augmentation.
自训练的常规步骤:
- randomly sample a subset from the large-scale monolingual data。
- use a “teacher” NMT model to translate the subset data into the target language to construct the synthetic parallel data;
- combine the synthetic and authentic parallel data to train a “student” NMT model.
问题:
how to efficiently and effectively sample the subset from the large-scale monolingual data in the first step has not been well studied.
在这项工作中,我们研究并识别隐含有困难模式的不确定单语句子,并利用它们来提高自我训练的表现。具体来说,我们使用从真实的平行数据中提取的双语词典来测量单语句子的不确定性。
实验表明,NMT models benefit more from the monolingual sentences with higher uncertainty, except on those with excessively high uncertainty
通过语言属性分析,我们发现极不确定的句子包含相对较差的翻译输出,这可能会阻碍NMT模型的训练。
受上述发现的启发,我们提出 一种基于不确定性的自我训练抽样策略,在此策略中,不确定性高的单语句子将以较高的概率被选择。
对生成输出的广泛分析证实了我们的说法,表明我们的方法改进了不确定句子的翻译和低频目标词的预测。
Improving Back-Translation with Uncertainty-based Confidence Estimation
摘要:
反向翻译可以简单有效地利用丰富的单语语料来改进低资源的神经机器翻译(NMT),但在有限的真实双语数据上训练NMT模型生成的合成双语语料不可避免地带有噪声。在这项工作中,我们提出了基于模型不确定性的全信度NMT模型预测。利用基于不确定性的词和句水平置信测度,反译可以更好地应对合成双语语料库中的噪声。在汉英英德翻译任务中的实验表明,基于不确定性的置信度估计信号显著提高了反向翻译的性能。
Back- Translation概念:
具体训练步骤如下(假如要训练一个中译英的模型):
- 首先使用平行语料训练一个英译中的模型(与目标方向相反。)
- 使用目标语言(英语)单语语料通过英译中模型的翻译生成中文。
- 将生成的语料与平行语料混合训练中英模型。
Introduction 重点:
NMT受到数据短缺问题的困扰,改进小数据下的NMT 训练条件引起了广泛关注,其中back translation是一个重要的方向,它的基本思想是利用在有限的真实双语语料库上训练的NMT模型,利用丰富的单语言数据生成合成的双语语料库。back- translation has been widely used in low-resource language translation.然而,由于NMT模型生成的合成语料库不可避免地带有噪声,翻译错误可能会传播到后续步骤,并容易阻碍翻译性能。
model- uncertainty:measure whether the model parameters can best describe the data distribution.
Based on the expectation and variance of word and sentence-level translation probabilities calculated by Monte Carlo Dropout,we introduce various confidence measures.
our goal is to quantify the confidence of model prediction rather than using uncertainty to improve model prediction。
由于标准NMT模型的自回归特性,使用蒙特卡罗Dropout进行decode非常慢。

模型不确定性:其实就是方差对期望的表达公式
只需要把数据喂进网络T次,然后把得到的结果取一个平均值,就是你的最终预测,把结果算一个方差,结果就是你的认知不确定性,公式如下所示:

方差=E (x²)-E (x)²,E (X)是数学期望。

利用了4种sentence-level的confidence measures:
还有很多其他复杂的方法,但是以下方法easy-to-implement and prove to be effective。

实验效果:
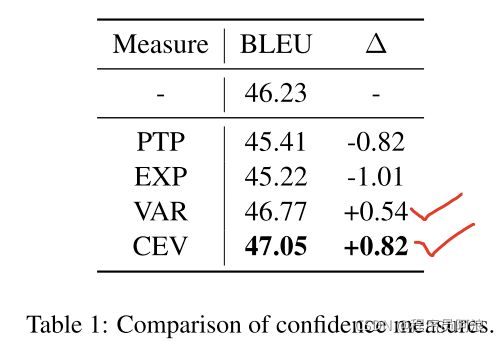
In the following experiments, we use CEV as the default setting.
针对第四个公式,作者解释道:

为啥不直接用 期望 / 方差,来表示置信度?,因为所有的confidence measures 方法都在0-1之间。
然后word-level的置信度同理。
Word- and sentence-level confidence measures are complementary互补的。
Word-level可以提供更细粒度的信息,sentence-level可以应对词遗漏的错误
Instead of applying confidence estimation to the second pass of decoding, we directly integrate confidence scores into the training process.
在基于CEV上的实验效果:
Thanks to more fine-grained quantification of uncertainty, using word-level confidence achieves a higher BLEU score than using sentence-level confidence。
实验结果:
在单语语料的收集方法中(None,search,sample),find that SAMPLE is more effective than SEARCH

EMNLP
Towards More Accurate Uncertainty Estimation In Text Classification
不确定性评估用于文本分类任务,集成三种方法:“mix-up”, “self-ensembling”, “dis- tinctiveness score”,称为MSD。
improving Confidence of Winning Score (CWS),is helpful to improve the accuracy of uncertainty score.
considers a basic way to measure uncertainty score, which is the reciprocal (倒数)of winning score
假设:预测获胜得分与样本不确定性呈负相关
为了减轻过度自信的影响,我们生成新的训练样本表示与不同的得分,这也是负相关的样本不确定性
作者考虑了所有分类结果的不确定性,以前的研究只侧重一到两个不确定分类
模型预测的不确定性来源于:data uncertainty and model uncertainty.
data uncertainty又分为两个方面:
- epistemic认知 uncertainty
- lack of knowledge, such as only few training data or out-of-distribution testing data。
- aleatoric偶然 uncertainty
- caused by noisy data in the generation of both training data and testing data. The
model uncertainty也分为两个方面:
- parametric参数 uncertainty
- comes from different possibilities of parameter values in estimating model parameters under the current model structure and training data;来自在当前模型结构和训练数据下估计模型参数的参数值的不同可能性;
- structural结构 uncertainty
- 对于当前的任务和训练数据,当前的模型设计(例如,layers, loss function)是否合理或足够的不确定性。
由于model uncertainty的求解需要极高的计算量,如神经结构搜索(Neural Architecture Search, NAS),因此我们只同时减小或扩展其他三类不确定性,以提高Confidence of Winning Score (CWS)。
相关工作:
mitigate uncertainty 的方法:
- Bayesian Neural Network (BNN) 两种参数估计方法:
- Kullback-Leibler (KL) divergence
- Monte Carlo dropout
- noise injection
- parameter noise injection adds noise perturbation in network weights
- data noise injection directly inputs noise perturbation into data
scaling uncertainty的方法:
当前许多关于uncertainty score的测量方法都基于softmax vectors
- winning score
- 后续演变,Applying winning score as prediction confidence is proposed,出现了Expected Calibration Error。
- which is the absolute value of the difference between the accuracy and confidence of results.
- Overconfidence Error is proposed by applying winning score as confidence and penalizing samples with confidence values greater than accuracy values。过自信误差是指以winning score作为置信值,惩罚置信值大于准确度值的样本。
- 后续演变,Applying winning score as prediction confidence is proposed,出现了Expected Calibration Error。
- Temperature scaling
- Get the calibrated probability by adding a scalar parameter to each class in calculating softmax vector在计算softmax向量时,通过在每个class中添加一个标量参数,得到校准的概率
improve the accuracy of uncertainty score by reducing the effect of overconfidence and considering three categories of uncertainty simultaneously.通过降低过度自信的影响,同时考虑三种不确定性,提高不确定性评分的准确性。
Understanding Neural Abstractive Summarization Models via Uncertainty
摘要:
seq2seq抽象概括模型的一个优点是它们以自由形式生成文本,但是这种灵活性使得解释模型行为变得困难。在这项工作中,我们通过研究模型的token- level预测的熵或不确定性,以黑盒和白盒的方式分析摘要译码器。对于PEGASUS (Zhang et al., 2020)和BART (Lewis et al., 2020)在两个摘要数据集上的两个强预训练模型,我们发现低预测熵和模型复制token而不是生成新文本之间存在很强的相关关系。解码器的不确定性还与诸如句子位置和相邻标记对之间的句法距离等因素有关,给出了什么样的因素使上下文对模型的下一个输出标记具有特别的选择性。最后,我们研究了解码器的不确定性和注意行为之间的关系,以理解注意是如何引起这些模型中观察到的效应的。我们表明不确定性是一个有用的视角来更广泛地分析摘要和文本分类模型.
Uncertainty-Aware Semantic Augmentation for Neural Machine Translation
摘要:
神经机器翻译的内在不确定性:一句多译
现有的NMT方法在模型训练时只从平行语料库中观察到其中的一个,但在推断时必须处理在相同意义下的足够的变种。导致训练阶段和推理阶段的数据分布不一致。
因此作者提出一种uncertainty-aware的语义增强的方法,从多个语义等价的source sentence中捕捉出全局的语义信息,来获得更好的翻译效果。
引言:
It is natural to enable an NMT model trained with the token-level cross-entropy (CE) to capture such a rich distribution, which exactly motivates our work.
首先通过合成多个源句子去表示每个目标句子的inherent uncertainty.
具体方法:
提出了一种controllable sampling strategy 去cover adequate variations for inputs.通过量化每个decoding步骤中单词分布的清晰度,并选取合适的单词(指概率最大或者多次抽样)然后利用一个CSN语义约束网络去summarize多个源句子,这样可以将相同的meaning into 到一个相近的语义空间,
我们的目标是通过在每个训练实例中添加多个语义等效源输入来bridging训练阶段和推理阶段之间数据分布的差异。
具体sample生成合理源句子的方法:
at each decoding step, if the word distribution is sharp then we take the word with the maximum probability, otherwise the sampling method formulated in Eq:

广泛使用的多项抽样和贪婪搜索策略可以作为可控抽样的特殊情况。
NIPS
Ovadia, Y., Nado, Z., & Dillon, J. V. (2019). Can you trust your model‘s uncertainty.pdf. NeurIPS.
评估模型预测的不确定性,感觉像套娃?
由于样本偏差和非平稳性等各种因素,输入分布往往会从训练分布转移
在dataset shift的情况下,这些方法还没有进行过严格的大规模实证比较
present a large- scale benchmark of existing state-of-the-art methods on classification problems and investigate the effect of dataset shift on accuracy and calibration
提出了一个大规模的benchmark,现有的最先进的方法分类问题,并研究了数据集偏移对精度和校准的影响
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
摘要:深度神经网络(NNs)是强大的黑箱预测器,最近在广泛的任务中取得了令人印象深刻的性能。对网络神经网络中预测的不确定性进行量化是一个具有挑战性而又尚未解决的问题。贝叶斯神经网络(Bayesian nn)学习权重分布,是目前估计预测不确定性的最先进技术;然而,与标准的(非贝叶斯)神经网络相比,这些方法需要对训练过程进行重大修改,在计算上也很昂贵。我们提出了一种贝叶斯网络的替代方案,该方案实现简单,易于并行化,只需要很少的超参数调优,并能产生高质量的预测不确定性估计。通过对分类和回归基准的一系列实验,我们证明了我们的方法产生了校准良好的不确定性估计,与近似贝叶斯神经网络一样好或更好。为了评估数据集漂移的鲁棒性,我们评估了来自已知和未知分布的测试示例的预测不确定性,并表明我们的方法能够表达对非分布示例的较高不确定性。我们通过评估ImageNet上的预测不确定性估计来证明我们方法的可扩展性。
Detecting Out-of-Distribution Translations with Variational Transformers
摘要:
在神经网络机器翻译中,我们利用认知不确定性来检测非训练分布的句子。为此,我们开发了一种测量不确定性的方法,专门为离散随机变量的长序列设计,与输出句子中的单词相对应。这种测量能够传达类似于互信息(MI)的认知不确定性,后者用于单离散随机变量的情况下,如分类。
我们新的不确定性度量方法解决了现有方法在长句子上的naive应用中的一个主要难题。我们训练一个Transformer模型与dropout在德国的任务——英文翻译使用WMT13和Europarl,表明用dropout不确定性测量时能够识别荷兰源的句子,句子使用同一个词类型为德语,给出该模型而不是德国人。
use epistemic(认知) uncertainty to detect out-of-training-distribution sentences in Neural Machine Translation.

What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?
摘要:有两种主要类型的不确定性可以建模。偶然不确定性捕获了观测中固有的噪声。另一方面,认知的不确定性解释了模型中的不确定性——这种不确定性可以在足够的数据下被解释掉。传统上很难在计算机视觉中建模认知的不确定性,但有了新的贝叶斯深度学习工具,这现在是可能的。我们研究了视觉任务贝叶斯深度学习模型中认知不确定性与随机不确定性建模的好处。为此,我们提出了一个贝叶斯深度学习框架,它结合了输入依赖的随机不确定性和认知不确定性。我们在基于逐像素语义分割和深度回归任务的框架下研究模型。此外,我们的明确不确定性公式导致了这些任务的新的损失函数,可以解释为习得衰减。这使得损失对噪声数据的鲁棒性更强,也为分割和深度回归基准提供了新的最先进的结果。
AAAI
Addressing the Under-Translation Problem from the Entropy Perspective
问题:under-translation problem of high-entropy words

作者定义了source-word的熵,熵越大,source word不确定性越大
贡献:
1.source words with larger translation entropy are more likely to be dropped by the neural model.
2.提出一个从粗到细的框架来解决 高熵词的欠译问题。在粗粒度阶段,我们构造伪目标句子来降低这些高熵词的熵。在细粒度阶段,利用衍生的伪目标句对原NMT模型进行改进。
对word的熵的定义:
Assume a word s contains K candidate translations, each of which has a probability pk, the translation entropy for this word can be calculated:
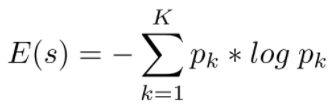
Quantifying Uncertainties in Natural Language Processing Tasks
Recent progress in Bayesian deep learning has made such quantification realizable.
Propose novel methods to study the benefits of characterizing model and data uncertainties for natural language processing (NLP) tasks.
开展情感分析实验,entity recognition,使用卷积和递归神经网络模型进行语言建模,我们证明了明确地建模不确定性不仅对测量输出置信水平是必要的,而且对提高模型在各种NLP任务中的性能也是有用的。
Introduction:
有机器学习模型中很多不确定性的情况:也叫模型不确定性
we are uncertain about whether the structure choice and model parameters can best describe the data distribution。
BNN是其中一种量化模型参数不确定性的方法,bnn将所有模型权重表示为可能值上的概率分布,而不是固定标量
另一种情况是where uncertainty arises is when collected data is noisy.也叫数据不确定性。noises might exist within the data generation process。
往下细分数据不确定性:
data uncertainty is further divided into homoscedastic uncertainty同方差的不确定性 and heteroscedastic uncertainty异方差的不确定性
- 输入空间的同方差不确定性是相同的,可以由系统观测噪声引起。
- 异方差不确定性依赖于输入。例如,在预测Yelp评论的情绪时,单字评论“好”可能得到3星、4星或5星的评级,而带有强烈积极情绪短语的加长评论肯定是5星评级。在本文的其余部分,我们也将异方差不确定性称为输入相关数据不确定性
本文作者使用MC dropout来估计模型的不确定性
Building Calibrated Deep Models via Uncertainty Matching with Auxiliary Interval Predictors
摘要:
随着深度学习在关键应用中的快速应用,何时以及在多大程度上信任这些模型的问题经常会出现,这促使人们需要对固有的不确定性进行量化。虽然识别所有解释模型随机性的来源是具有挑战性的,但用置信区间来表达模型行为的预期变化是很常见的。我们要求预测区间经过校准,反映真实的不确定性,并且要准确。然而,已知现有的获取预测区间的技术在这些标准中至少有一个会产生不满意的结果。为了解决这一挑战,我们开发了一种新的方法来建立校准的估计器。更具体地说,我们对预测和区间估计使用了单独的模型,并提出了一个双层优化问题,允许前者通过不确定性匹配策略利用后者的估计。在回归、时间序列预测和目标局部化方面的实验表明,我们的方法在模型保真度和校准误差方面都比现有的不确定性量化方法取得了显著的改进。
贡献:
- A novel framework to produce reliable prediction inter- vals in continuous-valued regression, that are sharp and well calibrated for any required confidence level;在连续值回归中产生可靠的预测区间的新框架,对于任何所需的置信水平都是锐利的和良好的校准;
- 一种估计均值和预测区间的方法,作为模型推理的两级优化和交替优化策略
- 基于不确定性匹配,提出了一种新的均值与预测不确定性估计正则化方法
- 两种不同的不确定性匹配策略,即Sigma拟合和IQR拟合
- 对不同的用例和模型架构进行严格的评估,包括使用fns的回归、使用LSTMs的时间序列预测和使用cnn的对象定位,与目前的技术水平相比,所有这些都产生了更好的泛化性能和校准误差。
问题:existing techniques for obtaining prediction intervals are known to produce unsatisfactory results in at least one of these criteria。
方法:
we use separate models for prediction and interval estimation, and pose a bi-level optimization problem that allows the former to leverage estimates from the latter through an uncertainty matching strategy. 我们使用独立的模型进行预测和区间估计,并提出一个双层优化问题,允许前者通过不确定性匹配策略从后者利用估计。
ICLR
DEEP ORIENTATION UNCERTAINTY LEARNING BASED ON A BINGHAM LOSS
基于宾汉损失的深度定向不确定性学习
摘要:不确定方向的推理是物体姿态估计、运动估计等感知任务的核心问题之一。在这些场景- ios中,恶劣的照明条件、传感器限制或外观不变性可能导致高度不确定的估计。在这项工作中,我们提出了一种新的基于学习的方向不确定性表示。通过用宾汉分布描述单位四元数的不确定性,我们得到了一种损失,它自然地捕获了表示的对映对称。我们讨论了学习的分布参数的可解释性,并证明了我们的方法在几个具有挑战性的现实世界的姿态估计任务涉及不确定的方向的可行性。
QUANTIFYING POINT-PREDICTION UNCERTAINTY IN NEURAL NETWORKS VIA RESIDUAL ESTIMATION WITH AN I/O KERNEL
利用I/O核残差估计量化神经网络中点预测的不确定性
摘要:神经网络(NNs)已被广泛用于广泛的现实世界回归任务,其目标是预测数值结果,如收入,有效性,或定量结果。在许多这样的任务中,点预测是不够的:还必须估计预测的不确定性(即风险或信心)。在这类任务中最常使用的标准神经网络不提供不确定性信息。现有的方法通过结合贝叶斯模型和神经网络来解决这个问题,但是这些模型很难实现,训练成本更高,并且通常不能像标准神经网络那样准确预测。本文提出了一种新的框架(RIO),**使得在任何预先训练的标准神经网络中估计不确定性成为可能。**神经网络的行为是通过对其预测残差的高斯过程建模来捕获的,高斯过程的核包括神经网络的输入和输出。该框架在12个真实数据集中进行了评估,发现:(1)提供了可靠的不确定性估计,(2)减少了点预测的误差,(3)能很好地适用于大数据集。RIO可以应用于任何标准的神经网络,而无需修改模型架构或培训管道,它为构建真实世界的神经网络应用提供了重要的组成部分。
UNCERTAINTY ESTIMATION AND CALIBRATION WITH FINITE-STATE PROBABILISTIC RNNs
摘要: 不确定性量化是建立可靠可信的机器学习系统的关键。我们提出在递归神经网络(RNNs)中通过递归时间步上的随机离散状态转换来估计不确定性。模型的不确定性可以通过多次运行预测来量化,每次从循环状态转移分布中取样,如果模型是不确定的,就会导致可能不同的结果。除了不确定性量化,我们提出的方法在不同的情况下提供了几个优势。该方法可以:(1)从数据中学习确定性和概率自动机;(2)在真实世界分类任务中学习校准良好的模型;(3)提高分布外检测的性能;
UNCERTAINTY-GUIDED CONTINUAL LEARNING WITH BAYESIAN NEURAL NETWORKS
摘要:持续学习的目的是学习新的任务而不忘记以前学过的任务。当一个人不能从以前的任务中访问数据,并且模型有固定的容量时,这尤其具有挑战性。目前基于正则化的连续学习算法需要外部表示和额外的计算来衡量参数的重要性。相比之下,我们提出了不确定性引导的连续贝叶斯神经网络(UCB),其中学习率根据定义在网络中权重的概率分布中的不确定性进行自适应。在我们不断学习的过程中,**不确定性是一种自然的方式,它可以帮助我们识别哪些是需要记住的,哪些是需要改变的,从而减轻灾难性的遗忘。**我们还展示了我们模型的一个变体,它使用不确定性进行权值剪枝,并通过为每个任务保存二进制掩码来保留剪枝后的任务性能。我们在不同的对象分类数据集上对UCB方法进行了广泛的评估,这些数据集具有短序列和长序列任务,与现有方法相比,我们报告了更好的或达到标准的性能。此外,我们还表明,我们的模型在测试时并不一定需要任务信息,也就是说,它并不假定样本属于哪个任务。
propose a continual learning formulation with Bayesian neural networks
MODELING UNCERTAINTY WITH HEDGED INSTANCE EMBEDDING
摘要:实例嵌入是一种高效、通用的图像表示方法,可用于识别、验证、检索和聚类等应用。许多度量学习方法将输入表示为嵌入空间中的单个点。通常,分与分之间的距离被用来衡量比赛的可信度。然而,这不能代表不确定性,当输入是模糊的,例如,由于遮挡或模糊。这项工作解决了这个问题,并通过“对冲”每个输入在嵌入空间中的位置,明确地建模了不确定性。我们引入了模糊实例嵌入(HIB),其中嵌入被建模为随机变量,模型在变分信息瓶颈原则下训练(Alemi et al., 2016;Achille & Soatto, 2018)。在我们新的n位MNIST数据集上的经验结果表明,当遇到模糊输入时,我们的方法会导致预期的跨嵌入空间“对冲其赌注”的行为。这将提高图像匹配和分类任务的性能,在学习的嵌入空间中有更多的结构,并能够计算与下游性能相关的每个样本的不确定性度量

DETECTING OUT-OF-DISTRIBUTION TRANSLATIONS WITH VARIATIONAL TRANSFORMERS
摘要:我们使用Transformer模型的贝叶斯深度学习等效方法检测神经机器翻译中的训练外分布句子。为此,我们开发了一种新的测量不确定性的方法,专门为长序列的离散随机变量设计。输出句中的单词。我们新的不确定性度量方法解决了现有方法在长句子上的天真应用中的一个主要难题。我们将我们的新度量应用于一个经过dropout近似推理训练的Transformer模型上。在使用WMT13和Europarl进行德英翻译的实验中,我们发现,当使用与德语相同词型的荷兰语源句而不是德语时,我们的测量方法具有dropout不确定性。
others
Phrase-level Active Learning for Neural Machine Translation
解决的问题:Neural machine translation (NMT) is sensitive to domain shift.
从新领域的未标记数据中选择完整的句子和单独的短语
主动学习的两个步骤:data selection/annotation, and model update.
propose a method for incorporating phrase-based active learning into NMT.
我们首先描述了基于句子和基于短语的选择策略,然后提出了一种混合策略
混合选择策略比基于短语和基于句子的选择策略获得了更稳定的翻译性能