{% for article in article_list %}
{% endfor %}
{{article.article_title}}
{{article.article_content}}
目录
0、视频链接
1、环境配置
2、django基本命令
1)常见命令
2)数据库相关的Django命令
3、Django项目
1)Django创建项目
2)项目目录介绍
3)运行初始化的Django项目
4、Django应用
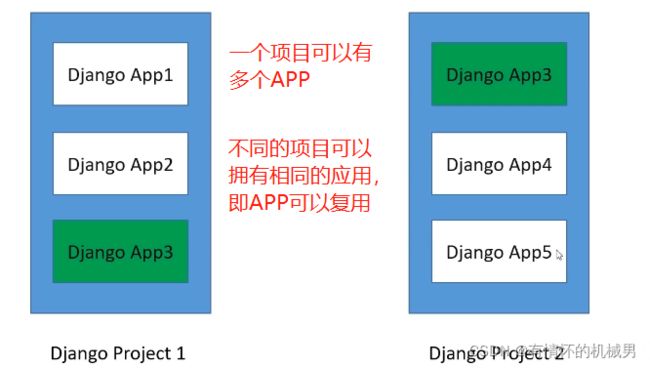
1)Django项目和Django应用
2)Django应用目录
(1)创建Django应用
(2)应用目录各文件介绍
问题1:视图、路由、模型是什么意思?
5、Django视图&Django路由(what、why、how)
1)Django视图(view.py)——创建逻辑函数(数据处理)
2)Django路由(url.py)——创建URL和函数的映射关系
①路由表和路由
②Django路由表的创建——path
③二级路由——项目路由容器转派到各应用路由容器中
3)request对象和response对象
①request对象——接收客户端返回的请求数据
② Response对象——根据客户端的请求在服务端获得的数据处理后要返回给客户端的数据(响应)
4)一个简单的Django项目(含视图及路由文件修改)——helloworld
①应用视图函数编写——获得网页请求,返回“helloworld”
②配置应用层面的路由——获得路由名后,到view.py查找对应的逻辑函数
③配置项目层面的路由——获得URL后,根据路由将截断的URL分配到对应的应用路由表中urls.py
④将APP应用配置到项目中
⑥本项目流程
问题2:什么是Django模型层?
6、Django模型层(models.py)
1)模型层简介(概念和作用)
2)Django中模型层的配置(settings.py)
7、Django模型的创建——创建博客文章类型(models.py)
1)明确博客文章的组成字段及其类型
2)定义字段
3)文章模型的定义
4)python manage.py makemigrations生成迁移文件
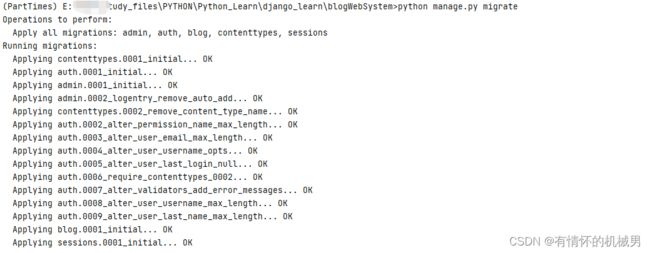
5)python manage.py migrate 迁移模型到数据库
8、Django shell——交互式环境
1)what&why
2)how——向数据库中插入一条记录
9、Django admin模块——管理员功能(用于后台修改数据)
1)what&why
2)how——如何使用admin模块
①创建管理员身份
②运行admin模块
③在admin.py中注册模型
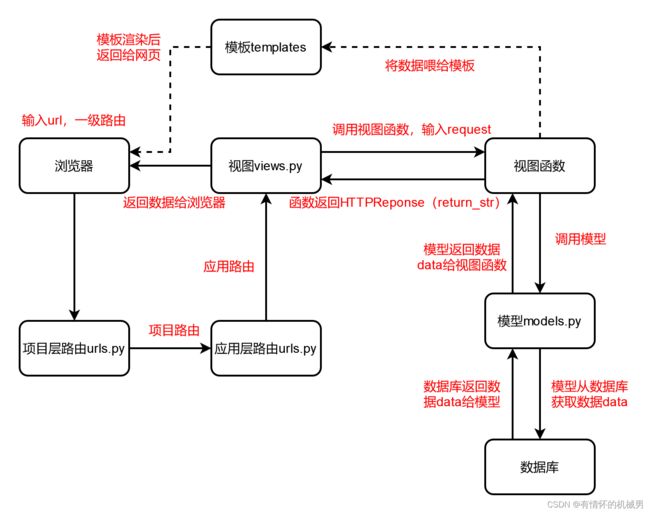
10、从数据库中获取数据并且返回给浏览器
1)编写代码
2)整个过程的流程图
问题3:什么是Django模板(template)
11、django 模板系统
1)模板系统简介
2)简单的模板例子
3)Django模板系统的基本语法
12、boostrap以及boostrap栅格系统
13、【实操】利用boostrap和Django模板实现博客系统
1)博客页面设计(博客首页+博客文章详情页)
2)博客首页设计
①书写博客首页的模板(HTML)
②修改视图文件函数返回模板变量值
③设置路由
④python manage.py runserver运行
3)博客文章详情页设计
①书写博客首页的模板(HTML)
②修改视图文件函数返回模板变量值
③设置路由
④python manage.py runserver运行
4)实现博客首页跳转至文章详情页
①文章详情页URL链接设计
②修改详情页链接路由设置
③修改视图函数get_detail_page
④为博客首页的文章列表添加链接
5)实现上下篇文章跳转
①设计翻页按钮——boostrap翻页组件
②给每一个详情页的上下篇文章按钮设置链接
③修改视图函数
6)实现博客首页分页功能
〇Django分页组件工具——Django.core.paginator.Paginator
①设计分页按钮——boostrap分页组件
②设计分页的URL
③修改视图函数
④修改index.html模板
7)实现最新文章的显示功能
14、总结
15、问题遗留
1)如何将网页上用户输入的信息保存到数据库
2)除了boostrap前端框架是否还有其他前端框架
3)实现一个网页版管理系统
视频链接:
三小时带你入门Django框架_哔哩哔哩_bilibiliDjango框架是Python语言最热门的Web框架之一。本课程将带你学习Django的项目结构,路由配置,和admin模块等知识点,并且将理论与实践结合,利用Django框架高效便捷,容易上手的特性。带你三小时搭建一个网站,让你快速上手Web开发。如果你有简单的Python语法基础,并且渴望项目实践,那么这门课程你不容错过。海量优质原创课程尽在【慕课网】www.imooc.com还请观众老爷 https://www.bilibili.com/video/BV1Sf4y1v77f?p=1
https://www.bilibili.com/video/BV1Sf4y1v77f?p=1
Python3.5+
pycharm IDE
Django2.0
安装Django: pip install django==2.0
测试Django是否安装成功:
终端输入:django-admin
出现下面的图示,不报错即可
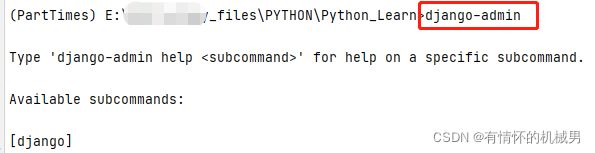
[django]
check:校验项目的完整性
compilemessages
createcachetable
dbshell
diffsettings
dumpdata
flush
inspectdb
loaddata
makemessages
makemigrations
migrate
runserver:进入Django的环境,并且运行Django的项目
sendtestemail
shell:进入Django shell的环境
showmigrations
sqlflush
sqlmigrate
sqlsequencereset
squashmigrations
startapp:启动Django应用
startproject:启动Django项目
test:执行用例
testserver





django-admin startproject 项目名称
django-admin startproject blogWebSystem
创建成功后项目如下所示:

参考:1、Django框架目录介绍 - 我是旺旺 - 博客园 https://www.cnblogs.com/licl11092/p/7595726.html
https://www.cnblogs.com/licl11092/p/7595726.html

python manage.py runserver
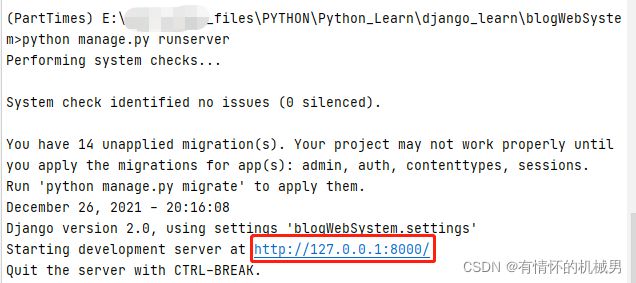
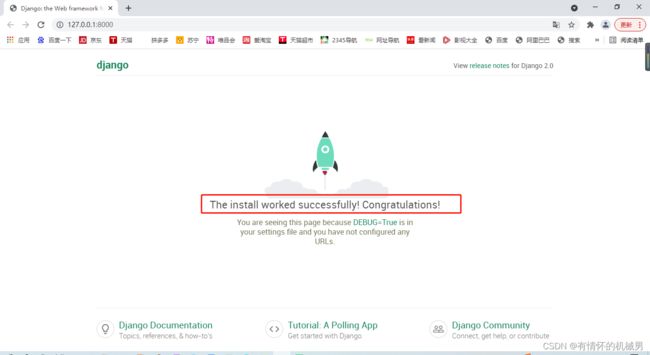
复制链接到网页上打开,出现下面的界面表示创建项目成功


Django manager.py startapp 应用名称
Django manager.py startapp blog



博客《Django中的视图(view) - rain、 - 博客园》中对视图的解释:
视图就是Django项目下的view.py文件,它的内部是一系列的函数或者是类,用来专门处理客户端访问请求后处理请求并且返回相应的数据,相当于一个中央情报处理系统
视图的作用(总结为两点):
①将网页端(客户端)的请求接收,然后将请求反馈给服务端(服务器、本机);
②将服务端的数据返回给网页端(客户端),并且显示在网页上。
其实就是一个中央数据处理站,服务端和客户端的枢纽
博客《django路由介绍_越前浩波的博客-CSDN博客_django路由》中对路由的介绍
简单来说,路由就是URL到函数的映射。
route就是一条路由,它将一个URL路径和一个函数进行映射,例如:
/users -> getAllUsers() /users/count -> getUsersCount()这就是两条路由,当访问 /users 的时候,会执行 getAllUsers() 函数;当访问 /users/count 的时候,会执行 getUsersCount() 函数。
router 可以理解为一个容器,或者说一种机制,它管理了一组 route。
简单来说,route 只是进行了URL和函数的映射,而在当接收到一个URL之后,去路由映射表中查找相应的函数,这个过程是由 router 来处理的。路由系统的工作总结起来就是:制定路由规则,分析url,分发请求到响应视图函数中。
路由系统的路由功能基于路由表,路由表是预先定义好的url和视图函数的映射记录,换句话说,可以理解成将url和视图函数做了绑定,映射关系有点类似一个python字典:
url_to_view_dic = { '路径1': view_func_1, '路径2': view_func_2, '路径n': view_func_n, ... }路由表的建立是控制层面,需要在实际业务启动前就准备完毕,即:先有路由,后有业务。
一旦路由准备完毕,业务的转发将会完全遵从路由表的指导:去往路径1的request --> 被路由器分发到view_func_1函数处理 去往路径2的request --> 被路由器分发到view_func_2函数处理 去往路径n的request --> 被路由器分发到view_func_n函数处理 ...
django框架中的工具:path
所有的web请求都将以django项目目录下的urls.py文件作为路由分发主入口,所以如果要完成最简单的路由功能,只需要在此文件中预先配置好路由表即可。path是django v2的工具。
# 项目urls.py文件, 目前两种工具可以任选使用
re_path(r'home/', views.index)
path('articles/', views.show_article)
路由表示例:
# urls.py文件
urlpatterns = [
# 自带后台管理页面路由
path('admin/', admin.site.urls),
# 新增
path('add/author/$', views.add_author),
path('add/book/$', views.add_book),
# 删除
path('delete/author/(\d+)', views.delete_author),
path('delete/book/(\d+)', views.delete_book),
# 修改
path('edit/author/(\d+)', views.edit_author),
path(r'edit/book/(\d+)', views.edit_book),
]
注:在Django中分为两种路由,一种是应用层面的路由,一种是Django项目层面的路由
Django 二级路由工具:include
二级路由的意思就是把项目urls文件中的路由整理划分,分布到各自的应用目录urls文件中
- 1、降低项目urls路由文件中路由数量,由各自应用urls路由文件承担
- 2、解耦整个项目的路由表,出现路由问题的时候可以单独在二级路由表中处理
- 3、多级路由以树形结构执行查询,在路由数量很大的时候,可以比单路由表有更快的查询速度
re_path(r'game/', include('game_app.urls')),
re_path(r'chat/', include('chat_app.urls')),
re_path(r'vidio/', include('vidio_app,urls'),
用include实现二级路由表,二级路由会将在一级路由匹配到的url截断后再发送给子路由表继续匹配。以如下一级路由表为例,如果服务器收到一个http://www.xxx.com:8080/game/user/add/?name=a&pswd=b的请求,首先会匹配一级路由表中的game/并将截断后的user/add/发送到二级路由表继续匹配。
如上所述,先获得game/,截断后的user/add/发送到game_app.urls路由表中进行下一步的路由表进行匹配
当一个页面数据被请求时,Django就会将请求的所有数据自动传递给约定俗称的request这个参数,而我们只需要拿到这个参数并对其进行一系列的操作即可获得所有与操作有关的数据
操作request对象的相应方法
与由Django自动创建的HttpRequest对象相比,HttpResponse对象是我们的职责范围了。我们写的每个视图都需要实例化,填充和返回一个HttpResponse。
HttpResponse类位于django.http模块中。
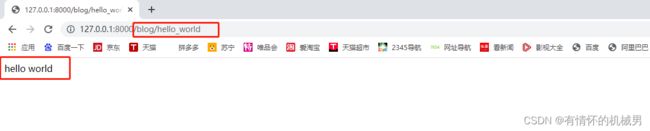
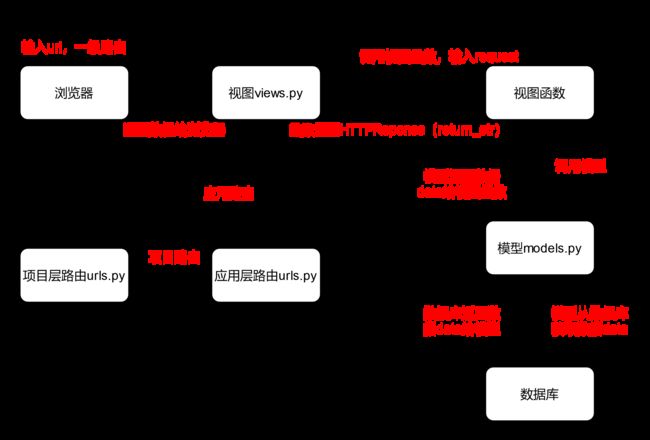
要做的事情其实就是打开Django项目后,在链接上增加/user后,能够通过视图函数得到响应值“helloworld”,并且显示在html中
流程:
- 输入URL
- 将URL传递给项目的urls.py
- 根据URL的一级路由和项目的urls.py中的映射表将URL分配到对应的应用的urls.py文件
- 根据URL的二级路由和应用的urls.py中的映射表将URL分配到下一级应用的urls.py文件
- ...
- 最后根据最后一级应用的urls.py文件的映射表调用view.py中的函数
- view.py中的函数接收由上述步骤得到的请求参数request,获得响应数据reponse
- 然后将Reponse响应数据返回到浏览器中
打开应用目录下的view.py文件,修改如下:
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def hello_world(request):
# 这里不能直接返回字符串,而是需要将字符串传入到HttpResponse类中,实例化响应类后进行返回
return HttpResponse("hello world") 其中request是客户端请求回来的参数对象,Reponse是服务端返回的响应对象
在应用里面新建一个urls.py文件,作为路由配置文件的编写
from django.urls import path
from views import hello_world
urlpatterns = [
# 当指派到本应用的路由一级路由名为hello_world时,调用view.py中的hello_world函数
path('hello_world',hello_world)
]打开项目的urls.py文件
from django.contrib import admin
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
# 将URL分配到对应的APP当中进行二级路由,这里是将其分配到blob.urls中
path("user/",include("blob.urls"))
]打开项目的settings.py文件
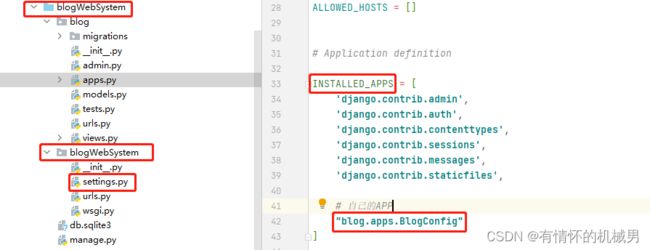
其中blog.apps.BlogConfig是在创建APP的时候生成的,可以查看应用层的apps.py文件
⑤运行项目——python manage.py runserver
修改链接最后运行得到下图结果

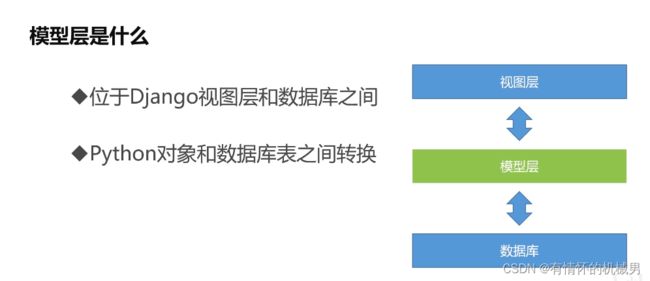
模型层其实就是Python类,主要的作用是与数据库进行数据交互,在数据库和视图之间,类似于DAO(data access object)的作用。
注:创建一个模型,其实就是根据网页的元素设计一张数据表,确定数据表的字段、字段类型、主键等参数

setting.py文件——DATABASES字典
具体Django模型数据库配置可见:
Settings | Django documentation | Django
配置mysql数据库(将下面的postgresql改成mysql即可):
模型的创建:数据表的设计和同步到数据库中




打开models.py
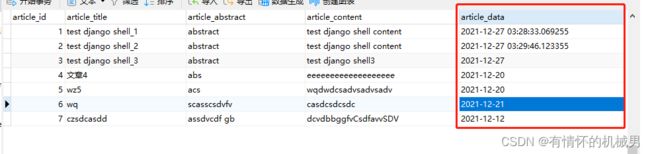
class Article(models.Model):
# 文章id
article_id = models.AutoField(primary_key=True) # 自增、主键
# 文章标题,文本类型
article_title = models.TextField()
# 文章摘要,文本类型
article_abstract = models.TextField()
# 文章正文,文本类型
article_content = models.TextField()
# 文章发布日期,日期类型
article_data = models.DateTimeField(auto_now=True) # 自己填充当前日期
迁移模型到数据库,即创建了一张表到数据库中
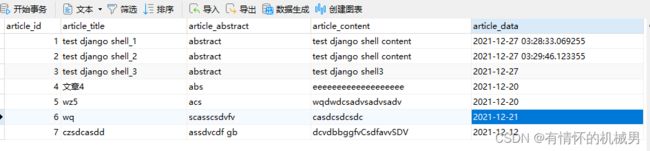
用可视化软件NAVICAT可以看到在数据库db.sqlite3中已经创建了一个数据表
数据表命名规则:应用名_模型名
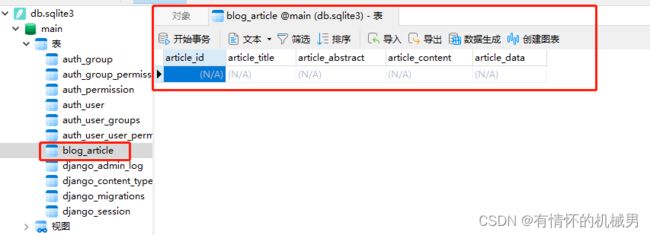
思考:既然模型的创建是数据表的创建,那是否可以直接在可视化软件Navicat中进行数据表的创建呢?
答:如果单单从数据表的创建来看是可以的,但是我们在使用命令python manage.py migrate进行模型的迁移时有可能不单单创建了数据表,还可能对其他文件的一些参数进行了修改,当然这个目前还不确定。


python manage.py shell进入Django shell环境

# 利用Django shell向数据库中插入一条记录,即创建一篇文章
>>> a = Article() # 类实例化
# 设置各个字段的值
>>> a.article_title = "test django shell"
>>> a.article_abstract = "abstract"
>>> a.article_abstract = "abstract"
>>> a.article_content = "test django shell content"# 保存记录到数据库中
>>> a.save()
>>>
# 获取模型Article中所有的记录,即获取数据表中所有的记录
>>> articles = Article.objects.all()
>>> artice = articles[0]
>>> print(artice.title)
# 打印指定数据表的某一记录的字段值
>>> print(artice)
Article object (1)
>>> print(artice.article_title)
test django shell

小结:利用Django shell进行文章的创建(记录的插入非常的麻烦)


python manage.py createsuperuser


python manage.py runserver
输入账号密码
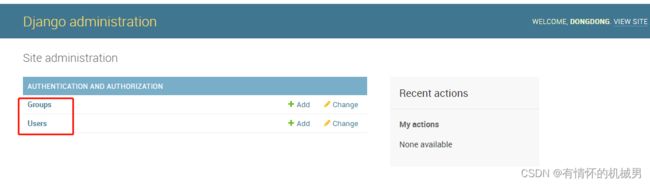
我们看到了可以管理用户和groups,但是没有看到articles,这是因为我们还没有将模型注册到admin模块中,因此在admin身份登录后看不到
from django.contrib import admin
# Register your models here.
# 导入模型
from blog.models import Article
admin.site.register(Article)再次执行②
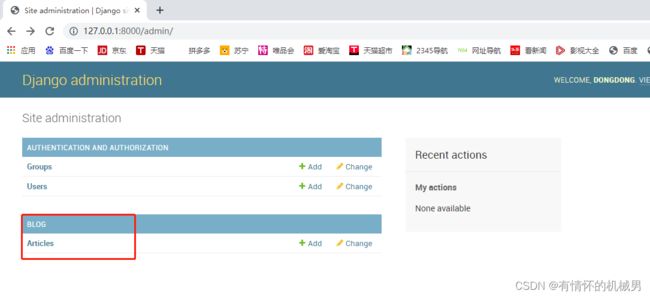
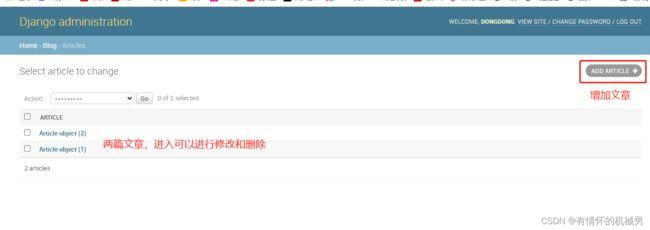
但是可以看到每篇文章的标题显示的都是object格式,无法知道具体文章,因此我们需要在创建模型的时候将文章的title返回,这样就可以显示文章标题了
models.py
class Article(models.Model):
# 文章id
article_id = models.AutoField(primary_key=True) # 自增、主键
# 文章标题,文本类型
article_title = models.TextField()
# 文章摘要,文本类型
article_abstract = models.TextField()
# 文章正文,文本类型
article_content = models.TextField()
# 文章发布日期,日期类型
article_data = models.DateTimeField(auto_now=True) # 自己填充当前日期
def __str__(self):
return self.article_title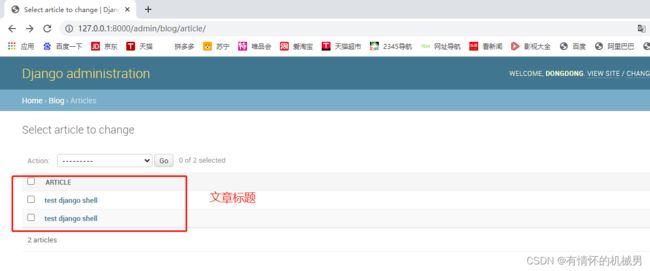
这里涉及到多个文件
view.py:定义一个函数,从模型文件models.py中获得模型,并且通过模型获得模型的数据,返回数据给浏览器;
models.py:定义了模型,实则就是一张数据表,可以轻松的从数据表中获取数据,然后视图
urls.py:定义路由,根据路径分配到其他地方,然后调用相应的视图函数
view.py
from django.shortcuts import render
from django.http import HttpResponse
from blog.models import Article
def get_article_contents(request):
articles = Article.objects.all()
first_article = articles[0]
title = first_article.article_title
abstract = first_article.article_abstract
content = first_article.article_content
return_str = "title:%s, abstract:%s, content:%s"%(title,
abstract,
content)
return HttpResponse(return_str)应用层urls.py
from django.urls import path,include
import blog.views
urlpatterns = [
# 当指派到本应用的路由一级路由名为hello_world时,调用view.py中的hello_world函数
path('hello_world',blog.views.hello_world),
path('content',blog.views.get_article_contents)
]项目层urls.py
rom django.contrib import admin
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
# 将URL分配到对应的APP当中进行二级路由,这里是将其分配到blob.urls中
path("blog/",include("blog.urls"))
]

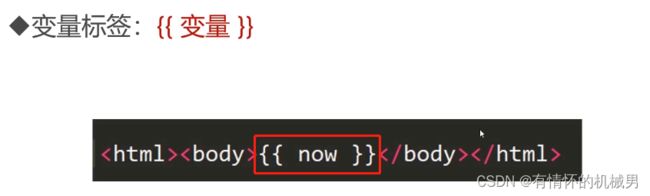
小结:模板系统其实就是一个文本,内容包含了必要的HTML标签以及模板特有的标签占位符组成的。即将之前的HTML文件中的内容用变量来代替了,作为一个HTML模板来使用,等需要使用的时候,只需要向HTML中的变量提供数据即可,这个过程也叫做渲染模板。
Django模板是一个string文本,它用来分离一个文档的展现和数据
模板定义了placeholder和表示多种逻辑的tags来规定文档如何展现
通常模板用来输出HTML,但是Django模板也能生成其它基于文本的形式


Ordering notice
Dear {{ person_name }},
Thanks for placing an order from {{ company }}. It's scheduled to
ship on {{ ship_date|date:"F j, Y" }}.
Here are the items you've ordered:
{% for item in item_list %}
- {{ item }}
{% endfor %}
{% if ordered_warranty %}
Your warranty information will be included in the packaging.
{% endif %}
Sincerely,
{{ company }}
这个模板本质上是HTML,但是夹杂了一些变量和模板标签:
- 用{{}}包围的是变量,如{{person_name}},这表示把给定变量的值插入
- 用{%%}包围的是块标签,如{%if ordered_warranty%}
块标签的含义很丰富,它告诉模板系统做一些事情
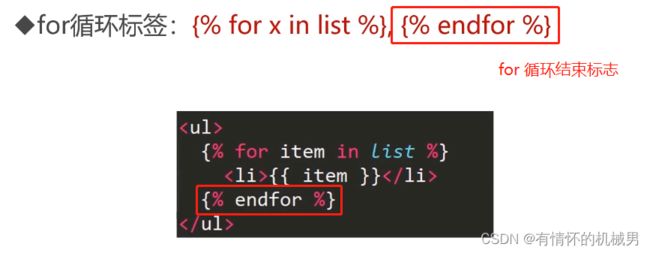
在这个例子模板中包含两个块标签:for标签表现为一个简单的循环结构,让你按顺序遍历每条数据
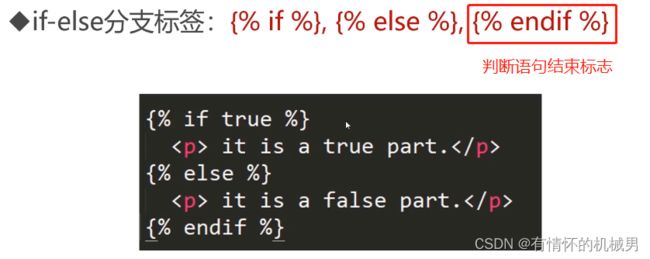
if标签则表现为逻辑的if语句
在这里,上面的标签检查ordered_warranty变量的值是否为True
如果是True,模板系统会显示{%if ordered_warranty%}和{%endif%}之间的内容
否则,模板系统不会显示这些内容
模板系统也支持{%else%}等其它逻辑语句
- 上面还有一个过滤器的例子,过滤器是改变变量显示的方式
上面的例子中{{ship_date|date:"F j, Y"}}把ship_date变量传递给过滤器
并给date过滤器传递了一个参数“F j, Y”,date过滤器以给定参数的形式格式化日期
类似于Unix,过滤器使用管道字符“|”
Django模板支持多种内建的块标签,并且你可以写你自己的标签
其实就是一个前端框架,我们可以利用boostrap系统进行前端网页的设计和布局,以及在boostrap官网上直接复制HTML代码下来用于作为模板
Bootstrap中文网

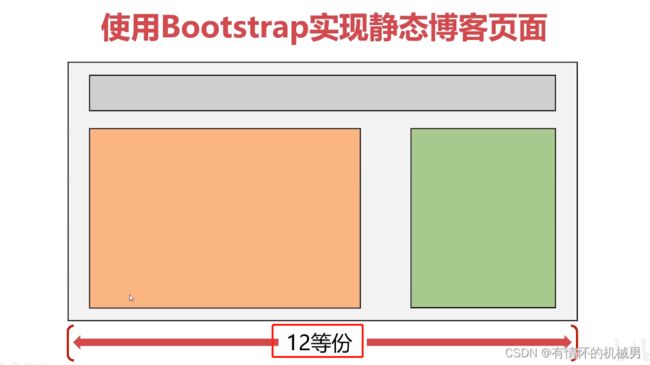
可以利用这12份进行布局,比如左右各几份
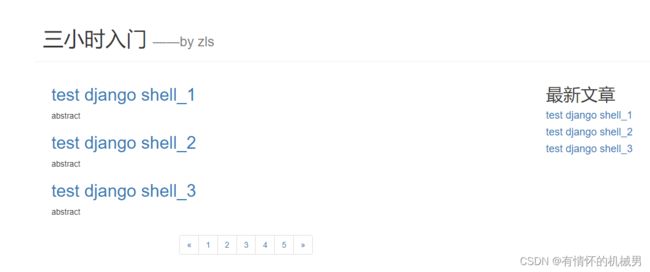
博客首页
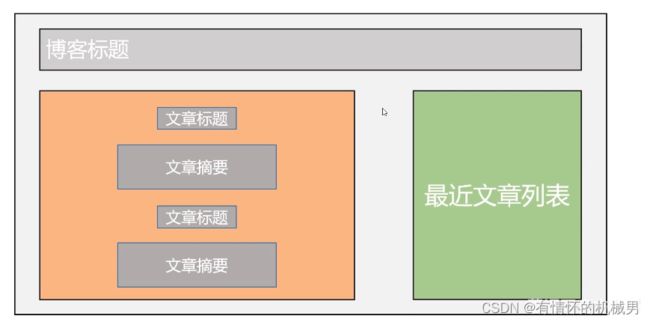
博客详情页

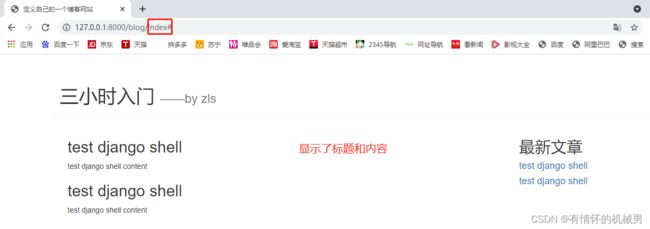
在应用下创建templates文件夹,在templates文件夹下创建blog(应用名)文件夹,blog下创建index.html文件
编辑index.html文件,引入boostrap相关资源,进入官网点击起步复制相关代码(这里引入的资源是css和JavaScript文件)
含有变量:article_list和top_article_list
定义自己的一个博客网站
三小时入门
——by zls
{% for article in article_list %}
{{article.article_title}}
{{article.article_content}}
{% endfor %}
最新文章
{% for top_article in top_article_list %}
{{top_article.article_title}}
{% endfor %}
from django.shortcuts import render
from django.http import HttpResponse
from blog.models import Article
# 从数据库获得所有数据填充到HTML模板中
# 其中render函数就是将变量值数据喂给指定模板
def get_detail_page(request):
all_articles = Article.objects.all()
return render(request,"blog/index.html",
{
'article_list':all_articles,
'top_article_list':all_articles
})from django.urls import path,include
import blog.views
urlpatterns = [
# 当指派到本应用的路由一级路由名为hello_world时,调用view.py中的hello_world函数
path('hello_world',blog.views.hello_world),
path('content',blog.views.get_article_contents),
path("index",blog.views.get_detail_page)
]项目层面的路由不变
在应用下templates文件夹的blog(应用名)文件夹,blog下创建page_detail.html文件
编辑page_detail.html文件,引入boostrap相关资源,进入官网点击起步复制相关代码(这里引入的资源是css和JavaScript文件)
含有变量:cur_article
文章标题1
{{cur_article.article_title}}
{{cur_article.article_content}}
# 选取指定文章的内容,这里以第一篇为例
def get_detail_page(request):
cur_article = Article.objects.all()[0] # 取第一篇文章
return render(request,'blog/page_detail.html',
{
"cur_article":cur_article,
})urlpatterns = [
# 当指派到本应用的路由一级路由名为hello_world时,调用view.py中的hello_world函数
path('hello_world',blog.views.hello_world),
path('content',blog.views.get_article_contents),
path("index",blog.views.get_index_page),
path("detail",blog.views.get_detail_page),
]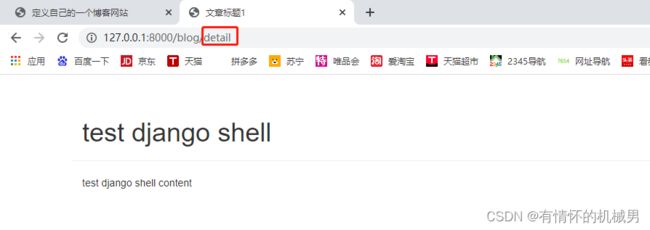
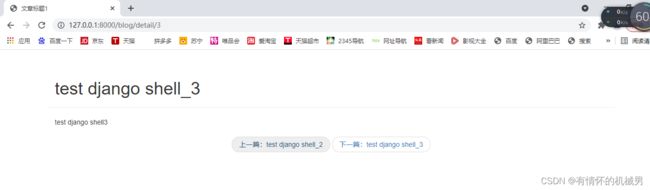
前面设计的详情页URL链接是:http://127.0.0.1:8000/blog/detail
为了能够让每一个详情页URL独一无二,这里将文章的article_id作为唯一标识,其实就是数据表的主键,设计后URL链接为:http://127.0.0.1:8000/blog/detail/{article_id}
urlpatterns = [
# 当指派到本应用的路由一级路由名为hello_world时,调用view.py中的hello_world函数
path('hello_world',blog.views.hello_world),
path('content',blog.views.get_article_contents),
path("index",blog.views.get_index_page),
path("detail/",blog.views.get_detail_page),
] # 选取指定文章的内容
def get_detail_page(request,article_id):
all_articles = Article.objects.all()
cur_article = None
for article in all_articles:
# 遍历所有文章,若文章id和指定的id一样时,获取文章,停止遍历
if article.article_id == article_id:
cur_article = article
break
return render(request,'blog/page_detail.html',
{
"cur_article":cur_article,
})
{% for article in article_list %}
{{article.article_title}}
{{article.article_content}}
{% endfor %}
将上述代码添加到detail_page.html中
{{cur_article.article_title}}
{{cur_article.article_content}}
blog/detail/article_id
# 选取指定文章的内容
def get_detail_page(request,article_id):
all_articles = Article.objects.all()
cur_article = None
previous_article = None
next_article = None
for index,article in enumerate(all_articles):
# 遍历所有文章,若文章id和指定的id一样时,获取文章,停止遍历
if article.article_id == article_id:
cur_article = article
# 当当前页是第一页且不是最后一页时,没有上一页
if index == 0 and index != len(all_articles)-1:
previous_article = article
next_article = all_articles[index+1]
# 当当前页是最后一页且不是第一页时,没有下一页
elif index != 0 and index == len(all_articles)-1:
previous_article = all_articles[index-1]
next_article = article
# 当只有一篇文章时
elif index == 0 and index == len(all_articles)-1:
previous_article = article
next_article = article
else:
previous_article = all_articles[index-1]
next_article = all_articles[index+1]
break
return render(request,'blog/page_detail.html',
{
"cur_article":cur_article,
"previous_article":previous_article,
"next_article":next_article,
})

功能:可以将一个列表按照指定的长度分割成多个子列表
p = Paginator(列表,每页的数目)
属性:
p.num_page:分成了多少页
p.count:列表的长度
p_index = p.page(index):表示取得第index页的对象
p_index.object_list:取得第index页的数据
p_index.has_next():判断是否有下一页,有返回True,没有返回false
p_index.has_previous():判断是否有上一页,有返回True,没有返回false
将上面的分页HTML加入到index.html中
可以参考详情页翻页的设计:blog/index/article_id
但是为了学习新知识,这里使用的是:blog/index?page=article_id的方式设计URL
?page=。。。问号后面的参数可以通过request.GET.get('page')来获取得到
# 从数据库获得所有数据填充到HTML模板中
# 其中render函数就是将变量值数据喂给指定模板
def get_index_page(request):
# 根据请求的参数获得请求的是第几页
page = request.GET.get("page")
# 得到第几页的参数
if page:
page = int(page)
else:
page = 1
# 获取所有的文章
articles = Article.objects.all()
# 利用Django分页组件将文章列表进行分页,每页显示3个文章简介
paginator = Paginator(articles, 3)
# 根据page获得当前页需要显示的文章页
cur_page_articles = paginator.page(page)
# 总页数
total_page_num = paginator.num_pages
# 设置上一页,下一页
# 如果当前页有下一页则下一页加1,否则设置为当前页
if cur_page_articles.has_next():
next_page = page + 1
else:
next_page = page
# 如果当前页有上一页则上一页减1,否则设置为当前页
if cur_page_articles.has_previous():
previous_page = page - 1
else:
previous_page = page
return render(request,"blog/index.html",
{
'article_list':cur_page_articles,
'top_article_list':articles,
'page_num':range(1,total_page_num+1), # 总页数
'previous_page':previous_page,
"next_page":next_page
})
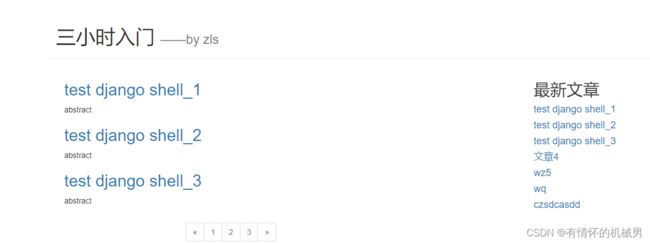
总共7篇文章,每一页显示3篇文章,分成了3页
修改view.py函数即可
# 获取所有的文章
articles = Article.objects.all()
# 获取按照时间排序的的最新的5篇文章,根据发布日期字段进行降序排序
top_article_list = Article.objects.order_by("-article_data")[:5]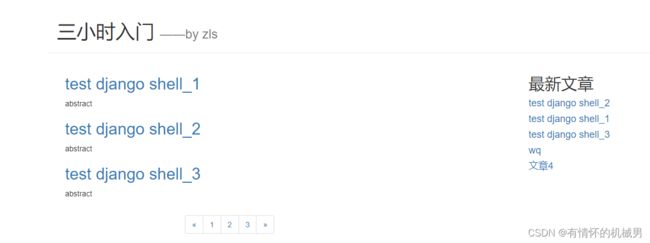
设计一个网页的流程:
- 创建项目
- 创建应用
- 网页布局设计
- 模型设计(数据表设计)
- 根据布局设计网页模板(templates)
- 设计视图函数view.py
- 利用模板和视图进行渲染(喂数据)
本项目目录总览: