杨强教授演讲视频:数据要素与联邦学习(附文字摘要)

关注“亨利笔记”公众号,后台回复: 数据要素,可获取杨强教授演讲PPT。回复 kubefate,可以加入联邦学习开源项目 KubeFATE 交流群。
9月25日,VMware 联合多家合作伙伴举办了「2021 AceCon 智能云边开源峰会」。本次峰会汇聚众多开源领导者及社区重要贡献者,聚焦当下三大热门技术主题:AI,云原生和边缘计算。
微众银行首席人工智能官杨强教授受邀出席本次会议,作为最早研究“联邦学习”的国际人工智能专家之一、“迁移学习”的开创者,杨强教授作了“数据要素与联邦学习”主题演讲。以下为杨强教授精彩演讲的视频回放及内容文字摘要:
杨强教授《数据要素与联邦学习》演讲文字摘要:
大家好,今天我演讲的主题是数据要素与联邦学习。
首先,我们看一下数据要素和人工智能的关系,我们知道数据有它一个特别的特点,就是它本身复制起来是零成本的,非常容易复制。
第二是数据是有价值的,但是它的价值是随场景而定。比方说,你拿一个数据集,它本身不一定产生价值,但是如果你把它和金融的数据结合起来,它就变成一个金融的风控场景;你把它和互联网广告的数据结合起来,那它就变成一个广告的场景。
还有,数据可以使用多次,就是不排他这个概念。跟它相对的就像石油,如果我们拿一桶石油去做一件事,就不能拿它做另外一件事。但数据不一样,数据我们可以重复的拿它来做多种事情。
最后,数据它有资本的特点,就是它有马太效应,数据越多的人,他的服务就可能越好,那么他就可能得到更多的数据。
另一方面,数据又是以指数的形式在增加的。图灵奖获得者 Jim Gray 说过,未来一年半所产生的数据等于历史上所有数据之和,也就说是指数型结构在增长的。
最近,我们国家对数据越来越重视,在2020年国务院令发布了数据要素市场的意见,特别把数据提升到一个要素,就是和土地、劳动力、资本和技术一样提到一个要素的层次,并且提出要加快的培育数据要素市场。
因此,国内的法律和监管也就越来越严,像9月份马上要出台的数据安全法。在此之前,欧盟和美国也是频繁地推出了非常严格的法律。像我们大家熟知的欧盟,就在2018年出了一个 GDPR 法案。美国也相应的有一个加州的消费者隐私法案 CCPA。在我们中国,不仅有数据安全的一个通用法案,同时还有各个行业针对不同人群,针对不同的媒体媒介有不同的法案。

在这个前景下,我们知道数据很有用,同时数据有这些特点,又很容易被滥用。那么,鱼和熊掌是不是可以兼得?什么是鱼?就是计算结果,我们需要利用不同的数据整合起来,建立一个好的模型,我们要的是结果的提升。但是熊掌就是安全,就是我们又要安全又要保护隐私,那么又要结果又要隐私是不是可以兼得?我们提出一个口号叫做数据可用不可见,也就是说数据是可计算的,但是不可获取的,换成英文来说就是:Results,not Data! 我们要的并不是用户的隐私。
隐私计算有一个很长的发展历史,它有一个共同的目标,就是要有多个参与方来联合计算,因为每一个参与方都贡献自己的知识,包括数据。第二是说模型的全局优化是我们关心的,就是每个参与方都很重要,那么我们要多个参与方一起来参加。然后,就是要保护隐私。因此我们的要求是数据隐私和安全,市场、生态也要建立起来,让每个参与者都有动力继续参加并受到激励。因此,数据也要1+1大于2,就是联合起来的价值要有提高,并且要确保大家的数据拥有权、数据收益的获取权和分配权,还有一个非常公平的审计机制。同时,要防止数据垄断和马太效应,要帮助小微企业这种数据拥有方成长起来,所以面临的任务是非常艰巨的。

我们看一下刚才的这个口号,叫做数据可用不可见,我们不妨把它分解开来,就数据有一种是可用的,有一种是不可用。其中,不可用的数据是法律规定不可用的。在可用的数据里面,又分为可见和不可见两种。可见就是传统计算,又可用又可见,就像传统的数据库。但是可用不可见,就是隐私计算的范畴,在这个里面有多个计算模式,我们也是按照时间轴从上到下,最先出现的是针对确定计算的多方安全计算。其次,就是目标是混淆个体以此来保护个体隐私的差分隐私技术,然后再次就是通过硬件来达到隐私保护的安全屋技术。然后就是我们针对AI特别定制的联邦学习的这种范式,那么今天主要是讲联邦学习的这种范式。
AI的力量来自大数据,我们今天知道深度学习等等,没有大数据就没有它的效果。但是我们周边都是小数据,并且是分散的,数据有不同的参与方,每一个参与方都有不同的属主,就是我们数据的主人不一样。因此带来很多利益和隐私的忧虑,以及权利和它对双收益的预期。所以我们把小数据问题给分解成两个问题,一是本身数据就小,从技术上可以用迁移学习来解决。其次,就是数据是分散的、无中心的,并且叠加起来是更加有效的,由于不可能粗暴地把它们合并起来,研究和解决这个问题就是联邦学习的范畴。
我们用这样的一个模式,就是达到数据可用不可见的目的,我们希望采用的是数据不动模型动这样的方式。这个方式需要有三个参与方,一个是甲方,就是数据的需求方,是真正在运用数据。比方说银行是用数据来做营销和风控的,保险是用数据来做营销和保险定价的,那么他们有需求。另外就是乙方,是拥有数据的这一方。我们平常用电、交税,在互联网上的购物行为等等都会产生数据。其次就是丙方,就是隐私计算的厂商、云服务商、大数据汇聚的中心地,还有大数据的交易服务商等等这是丙方。所以今天我们要看的是丙方如何规范自己,能够发展出一套新的套路来,就是技术路线。这个就是联邦学习的范畴。
我们首先来看一下联邦学习的分类。第一类,数据分散的模式是按照样本来分散,每一个终端都有不同的样本,大家合起来变成一个很大样本量的数据。但是每一个样本是在不同的终端上,每个终端有不同的属主,这样大家怎么样把数据给合并起来又不暴露隐私呢?所以我们用横向联邦学习来解决这个问题。

谷歌所提出的 Federated Average (FedAvg)这个算法,就像我们图中左边所示,有不同的数据集,每个数据集都有不同的样本,但是它们的特征层次有很大的重叠,使得我们可以在本地建立起一个粗略的模型,把这个模型的参数加密,然后汇聚在一个服务器,这个服务器对所有的模型参数进行更新以后,再下发到本地,然后在本地再进行更新,完成一轮的参数更替。这样的效果就使得我们的模型能够得到更新,并且大家互相看不到对方的数据,甚至看不到对方的模型参数。
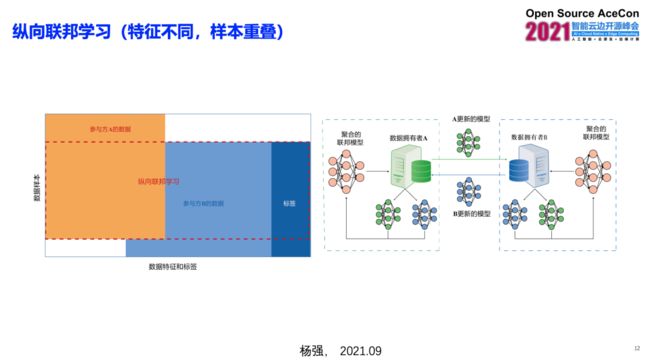
还有一种纵向联邦学习的方式,就是有两方的参与,他们的数据合并起来可以扩充数据的特征空间。比方说,一方收集的数据是用户的互联网行为,另外一方的数据是用户的金融行为,那么双发数据合起来就变成一个更大的特征空间。那这个是需要有一定量的用户,也就是样本是重叠的,那么我们可以依照刚才的那种模式,让大家交换加密后的参数,来形成每一个数据的拥有者都拥有一部分的模型,大家合起来变成一个优化的全局模型,并且以此来使用。比方说,我们可以用这样的一个算法来改造 XGBoost 模型,那么我们在刚才所说的纵向和横向都可以做这样的工作。
这样的工作也被业界发挥很多,我们看到不仅仅是在算法层面,并且还在在安全合规、攻击防御、算法效率(也就是网络的设计)、技术应用和联盟机制等方面。联盟机制就是如何能够鼓励数据孤岛的拥有者加入我们的联盟,并且能够持续的收益,这样他加入这个联盟的动力就越来越强,这样的机制需要用博弈论来非常小心地设计。
联邦学习也可以和迁移学习相结合,刚才一开始讲到,迁移学习是解决小数据的问题,它解决小数据的一个方法就是把模型从原空间迁移到另外一个的空间,在这个另外的空间可以更容易地进行操作。联邦学习和迁移学习的一个结合点,就是当我们的数据是异构的情况下,比方说,当数据分布和数据特征都不一样的情况下,就可以做这种迁移,把它迁移到一个共同的空间去加以联邦合作,这样就可以解决我们在机器学习所说的Non-IID的问题,这也是机器学习的一个严重挑战。

下面我简单回顾一下生态的发展。首先,如果我们要建立一个多方参与的生态,需要建立共同的语言标准,让大家有一个共同的语言能够沟通。我们在今年3月和IEEE发布了第一个联邦学习的基础框架,在之后又有不同的行业框架出现,比方说有通信行业的标准,有金融行业标准等等,一个一个地在不断地出现。现在中国电信又领衔做了一个安全标准,这也是在我们积极参与的。

开源变得很重要,一方面是鼓励业界积极地参与到联邦学习的建设当中,另一方面,让大家对联邦学习的技术平台放心,因为它可以让大家在透明的状态下进行检测。我们微众 AI 团队也是领衔国际发表了很多专利,并且还有很多的社群的参与。
联邦学习是隐私计算的一个发展历程,也是最新的一个发展历程,那么我们回顾一下,隐私计算也是经历了很多迭代的。第一代是安全多方计算,它的目标是精确的计算和精确的查询,好处是有严格的数学证明来保证安全隐私,但是缺点是效率非常低。
第二代是差分隐私技术,主要是针对数据库的开放,数据库在开放的时候,查询方有可能查询到每个个体的隐私数据。因此,差分隐私注入一些噪音,使得在数据查询中对方看不清个体的数据,以此来保护隐私。它的优点是效率大为的提升,缺点是效果大为的下降,因为有噪音进来了,并且它不能百分之百的保证隐私安全。
第三代就是最近硬件厂商所出的加密计算的安全屋,在安全屋里面,可以进行任意的操作,所有参与方都看不见数据。好处是在云计算这端可以保证一定的数据隐私,但缺点是数据还是要出本地的。联邦学习就主要针对是AI的这种复杂建模,它针对的也是数据安全不出本地,然后就是联合建模能够把效果提升,能够把效率提升。

从国家的层面也开展了联邦学习的和隐私计算的安全认证,我们也获得了不同的认证评测。同时,不同的联邦学习平台,比方说银联、微众和中国电信之间也进行了互联互通的成功验证,这个也是非常重要的。特别要指出的是,Gartner今年终于把联邦学习列为在隐私计算里面一个重要的上升通道当中,我们可以看到联邦学习在 Gartner 的成熟度曲线的上升期是被明显的列出,也标志着联邦学习进入一个工业应用的阶段。

《隐私计算白皮书》由工信部的中国信通院发布,也特别地提出了我们的平台 FATE 被很多的参与者应用。有很多的案例了,我就很快地过一下,一个案例就是说银行和互联网公司之间,银行可以横向联邦,互联网公司可以纵向联邦,这样的系统给了一个全局的建模,这个模型特别的适用像银行反洗钱这样的工作。
另外,在集团内部联邦学习有助于子公司之间的沟通,尤其像交叉营销和集团公司的集中管理。在医药健康方向,也可以帮助把多中心的数据结合起来,提高整体的检测效率,像这个应用的是我们跟腾讯和湖北的一些医院做了一个联邦学习的脑卒中的检测,效果大为的提升。像无人车可以保护司机本身的隐私,并且可以提高所有车里面的人工智能的效果,并且可以提升服务中心语音识别的效果,我们在微众银行内部也做了一个成功的测试。
我们还可以做联邦学习和推荐的结合,推荐的算法有很多,尤其在广告上面,可以使得各个数据拥有方在数据层面上隔断,但可以把转化的效果同时提升,我们测试表明了这种方法是非常有效的。

在未来我们正在进行的工作包括安全防御。像左边的部分是原始数据,右边和中间的部分表明,如果不小心的话,在两方合作的时候会有数据的泄漏,我们的安全防御可以保证这样的数据不受泄露。同时可以用自动化的联邦学习降低联邦学习应用的成本,这个叫自动化联邦学习。
最近 Nature 也发表了一个文章叫做Swarm Learning,它的主题是联邦学习在没有一个中央服务器的状态下,可以进行的联邦学习的服务。这样的服务特别的有效,尤其是加了区块链的审计机制以后就非常的有效果。
我最后总结就是说,联邦学习是数据要素一个不可或缺的技术,数据是分可用和不可用,可见和不可见,在这四个象限当中,联邦学习和隐私计算都是适用在可用而不可见的状态下,如何能够使用好数据资源,同时又保护好数据的隐私。
那么商业模式来说,现在也有逐渐成熟的趋势,比方说平台建设商,数据资源的加工商和咨询的服务商,是从三个角度来建立联邦学习隐私计算的商业模式。
最后,我要感谢VMware,感谢大家聆听,谢谢大家。
相关信息:
招聘云原生开发工程师
联邦学习:保护隐私安全以及克服数据孤岛的机器学习
云原生技术赋能联邦学习联邦学习企业级解决方案(附视频和PPT)
视频及PPT:云原生联邦学习平台、实践与应用
要想了解云原生、机器学习和区块链等技术原理,请立即长按以下二维码,关注本公众号亨利笔记 ( henglibiji ),以免错过更新。
