pytorch实现ResNet-18
文章目录
- ResNet-18
-
- 残差学习单元
- ResNet-18 结构
- Pytorch构建ResNet-18
- 使用CIFAR10数据集测试ResNet-18
-
- CIFAR10数据集介绍
- 使用CIFAR10数据集测试ResNet-18
ResNet-18
残差学习单元
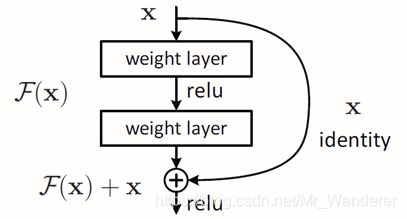
网络层数越多,并不意味着效果越好。当网络深度更深的时候,每一层的误差积累,最终会导致梯度弥散。最后几层能很好的更新,但是前面几层会一直得不到更新。
ResNet设置一个机制,增加短路连接。使30层的网络最差最差也可以退换成22层。
短路连接:如果ch_in和ch_out维度不一致,就把x维度变成ch_out维度。
ResNet-18 结构
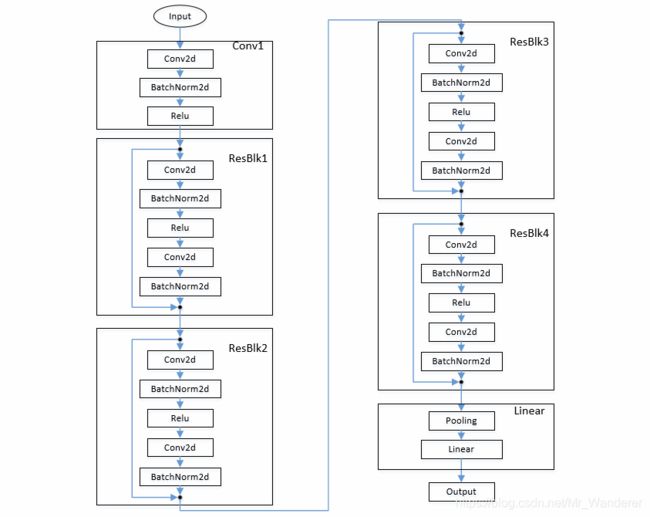
Pytorch构建ResNet-18
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/7/30 23:19
# @Author : Liu Lihao
# @File : resnet.py
import torch
from torch import nn
from torch.nn import functional as F
'''
ResBlock
'''
class ResBlk(nn.Module):
def __init__(self, ch_in, ch_out, stride=1):
# 通过stride减少参数维度
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
'''
:param x: [b, ch, h, w]
:return:
'''
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
return out
'''
ResNet-18
'''
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64)
)
# follow 4 blocks
# [b, 64, h, w] => [b, 128, h/2, w/2]
self.blk1 = ResBlk(64, 128, stride=2)
# [b, 128, h/2, w/2] => [b, 256, h/4, w/4]
self.blk2 = ResBlk(128, 256, stride=2)
# [b, 256, h/4, w/4] => [b, 512, h/8, w/8]
self.blk3 = ResBlk(256, 512, stride=2)
# [b, 512, h/8, w/8] => [b, 512, h/16, w/16]
self.blk4 = ResBlk(512, 512, stride=2)
self.out_layer = nn.Linear(512*1*1, 10)
def forward(self, x):
# [b, 3, h, w] => [b, 64, h, w]
x = F.relu(self.conv1(x))
# [b, 64, h, w] => [b, 512, h/16, w/16]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# [b, 512, h/16, w/16] => [b, 512, 1, 1]
x = F.adaptive_avg_pool2d(x, [1, 1])
# [b, 512, 1, 1] => [b, 512]
x = x.view(x.size(0), -1)
# [b, 512] => [b, 10]
x = self.out_layer(x)
return x
if __name__ == '__main__':
res_net = ResNet18()
tmp = torch.randn(2,3,32,32)
print(res_net.forward(tmp).shape)
使用CIFAR10数据集测试ResNet-18
CIFAR10数据集介绍

- data – 10000x3072 的uint8s格式numpy数组。数组的每一行存储一个32x32的彩色图像,按顺序包含红色、绿色和蓝色三个通道的值,因此每行的长度为32x32x3=3072。图像按行进行存储,如数组的前32个值是图像第一行的红色通道值。
- labels – 取值为0-9的包含10000个数字的list。索引i处的数字表示数组data中第i个图像的标签。
使用CIFAR10数据集测试ResNet-18
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/7/30 22:09
# @Author : Liu Lihao
# @File : origin_restnet_main.py
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
from resnet import ResNet18
def main():
batchsz = 32
'''引入训练集'''
# 一次加载一张图片
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
# transforms.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225])
]), download=True)
# 载入多张照片
cifar_train = DataLoader(cifar_train, batch_size=batchsz, shuffle=True) # shuffle随机化
'''引入测试集'''
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
# transforms.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225])
]), download=True)
# 载入多张照片
cifar_test = DataLoader(cifar_test, batch_size=batchsz, shuffle=True)
# x, label = iter(cifar_train).next()
# print('x:', x.shape, 'label:', label.shape)
'''定义模型,loss函数,优化器'''
device = torch.device('cuda')
model = ResNet18().to(device)
lossFuction = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3) # 不需要转换到GPU
print(model)
'''开始训练和评估'''
for epoch in range(1000):
'''train'''
model.train() # train模式:启用Dropout, Batch Normalization的参数会学习和更新
for batchidx, (x, label) in enumerate(cifar_train):
# x: [b, 3, 32, 32]
# y: [b]
x, label = x.to(device), label.to(device)
# logits: [b, 10]
logits = model(x)
# loss: tensor scalar (标量)
loss = lossFuction(logits, label)
# backward
optimizer.zero_grad() # 每次backward会对梯度累加,因此每次backward前要把梯度清零
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item())
'''eval'''
model.eval() # eval模式:不启用Dropout,Batch Normalization的参数保持不变
with torch.no_grad(): # 告诉pytorch,此段不需要构建计算图,更加安全
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
# x: [b, 3, 32, 32]
# y: [b]
x, label = x.to(device), label.to(device)
# logits: [b, 10]
logits = model(x)
# pred: [b]
pred = logits.argmax(dim=1)
# [b] vs [b] => scalar tensor
correct = torch.eq(pred, label).float().sum().item()
# print(correct)
total_correct += correct
total_num += x.size(0)
acc = total_correct / total_num
print(epoch, 'test acc:', acc)
if __name__ == '__main__':
main()