数据库复习
背景篇:
1.数据库是什么?和数据结构有什么关系
数据库是一类具体的软件,把很多数据给组织起来。在数据库这个软件的内部也会广泛的使用到数据结构。组织起来的目的:curd
数据结构是一门学科,描述数据是如何进行组织。把数据按照不同的结果组织起来的目的:curd
2.有哪些数据库软件
关系型数据库:对于内部的数据组织有严格要求
MySQL:当下互联网公司最广泛使用的数据库(开源免费)
Oracle:世界上最好的数据库(收费)
SQL Server:微软公司,早起捆绑销售造成不火
SQLite:超轻量数据库,在安卓系统中很多用到
非关系型数据库(了解)对于内部的数据组织无严格要求
Redis,HBase,MongoDB...
3.理解MySQL客户端服务器结构:一个应用程序,在实现一些核心逻辑的时候,并不是自己一个人完成的,而是通过网路和其他程序进行交互,共同完成这里的功能,在客户端的任意操作通过网络传输给服务器,及时在一个主机上。服务器是本体
4.理解服务器(电脑)由四部分构成,内存和外存的区别
5..MySQL基本组织数据的结构:
a)客户端服务器结构,服务器是本体
b)库(逻辑上的数据集合)--->表--->行(记录)---->列(字段)
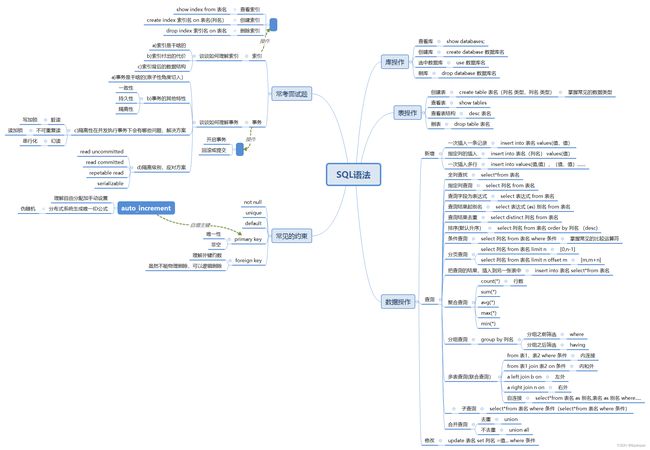
二.SQL编程语言:
常考问题:
1.理解MySQL里有哪些数据类型
varchar(size)----->size表示字符最大长度,和char区别变长
decimal(M,D)----->有效数字,小数点后位数
test---->长文本
datatime--->日期类型
2.熟悉CRUD用法
3.掌握比较运算符:
a)注意= <=>区别
b)<>表示!=
c)between and 表示[a,b]
d)in(a,b,c),出现过为真
e)is null,is not null
f)like 模糊匹配
g)and ,or,and优先级比or高
在条件查询中先执行where,符合条件的记录,再执行select前半部分决定显示哪些列,以及啥样的运算
select name,chinese+english+math as total from exam_result
order by是在查询结果出来后再排序
select name,chinese+english+math as total from exam_result order by total
h)null和其他值进行算术运算,结果还是null
i)delete删除后表还在,记录没了,drop连表都删没了
如何反制数据库的危险操作
1.权限控制
权限进行限制,不是所有的人都能操作,把高风险的操作,集中在有经验的大佬手里
2.备份:
对数据内容进行定期/实时备份
如果一旦数据出现严重问题,就可以进行恢复
3.把问题扼杀在摇篮
找个有经验的大佬一起
数据库的查询操作,是用索引方式实先
约数部分:
primary key:主键要保证唯一性,主键也不能为空
什么是自增主键,如何用
什么是数据库分布式部署:
数据太大,一台机器存不下,使用多台机器分布
分布式系统下,生成唯一ID算法:
时间戳+机房编号/主机编号+随机因子--->哈希值
理解伪随机:通过一系列数学变换,生成一串看起来没啥关系的数据序列,初始值称为随机种子
笛卡尔积:行数是积,列数是和
多表查询步骤:
a)笛卡尔积
b)加上连接条件
c)加上其他条件
d)对结果的列进行精简
理解左外连接和内连接区别:
左外连接就是尽可能显示左表中的数据,如果右边没有就填null,当左侧表中每条记录在右侧都有所体现时候都一样
理解奇淫巧技自连接,把行关系转换为列关系,理解自连接需要起别名,适用于行和行比较
理解套娃思想子查询,子查询返回多条记录用in,
常见面试题:
1.谈谈如何理解索引:
a)索引是干啥的(解决了啥问题)
索引类似于目录,主要存在意思是提高查询效率
举例说明,书,书籍,目录和数据库,表,索引之间关系
b)索引付出的代价:
1.消耗更多的空间
2.虽然提高了查询效率,但是降低了增加,删除,修改的效率(插入新的记录,需要既能够插入硬盘的数据,又要调整索引
c)索引背后的数据结构:
b+树
先谈谈b树
n×搜索树,每个结点可能包含n-1个值,还可能更少,n-1个值把区间划分成n份,这样的意义是表示同样的元素数据集合的时候,比二叉树的高度小,io次数也就降低了不少
引申到b+树
b+树n个值划分成n个区间
b+树和b树比,值可能会重复出现(父元素的值在子元素是以最大/最小的姿态出现的)
在叶子结点这里,b+树会把所有叶子结点,以链表的形式首尾相连(便于范围查找)
正因为,叶子结点是全集数据,只需要把每一行(每一条记录的完整的所有列关联到叶子结点上即可)非叶子结点,只需要保留索引列(只存个id),非叶子结点占用空间非常小(相比于完整的数据集合)就可以在内存中缓存,因此进一步减少了硬盘的Io
2.谈谈如何理解事务:
1.事务是干啥的(从原子性切入)
事务能够把多个SQL打包成一个整体,要么都执行完要么一个都不执行(如果执行出错,则会自动回滚)转账,突然数据库挂了,账号怎么变???
2.事务的其他特性还有啥
一致性:事务执行前后,数据处在一致的状态(数据能对的上,合情合理)
持久性:事务进行的改动,都是写到硬盘里的,不会随着程序的重启/主机重启而丢失
隔离性:并发执行的时候,事务之间能够保持隔离,不相互打扰
3.重点隔离性,在并发执行事务下会有哪些问题,以及如何解决
脏读:事务a修改未提交时,事务b读到了修改时的脏数据(写的时候读了)------->写加锁(写时不读)
不可重复读:一个事务a多次读取同一个数据,发现不一样(读的过程被修改了)---->读加锁(读时不写)
幻读:读A改b(结果集变了) ---------->串行化(读时啥也不干)
4.MySQL的隔离级别有哪些,和上面的问题如何应对
-read uncommitted 允许读未提交的数据 并发max 隔离min 可能存在脏度/不可重复读/幻读
-read committed 只能读提交之后的数据 写加锁 解决了脏度
-repeatable read(默认)读和写都加锁 解决了脏度/不可重复读
serializable 严格执行串行化,并发min,隔离max ,都解决,效率最低
jdbc操作:
1.创建数据源对象
2.建立连接(用户输入)
3.构造要执行的sql语句并解析
4.执行sql
// executeUpdate 对应插入删除修改语句. 返回值表示这次 SQL 操作影响到的行数.
// executeQuery 对应查询语句. 返回值则是返回的临时表数据.ResultSet
5.释放资源