Xilinx关于GTX的IP核serdes仿真和使用
平台:vivado2017.4
芯片:xc7k325tfbg676-2 (active)
关于GTX的开发学习。使用xilinx官方提供的IP核。
最近在学习完PCIE协议,使用逻辑解析PCIE协议代码各种包头。那么数据在外传输用的什么方式呢?这里就是使用了GTX高速串行总线。那么GTX高速串行总线是什么呢?
我们知道一般的数据传输都是采用的并行总线,一条时钟线,并行的数据总线。数据在时钟的边沿传输,和数据在时钟的双沿传输。但是并行传输的发展总归有很大的局限性。在时钟信号的频率很高的时候,就会担心时钟质量,以及数据传输的稳定性。
这里随着技术的发展,高速的串行总线慢慢使用起来了。高速串行总线不需要传输时钟信号(时钟信号从数据中提取出来,这时候就需要保证串行总线上没有很长的连续的零和一)。相比于并行数据传输的效率和准确度都更高。今天我们就看一看在xilinx上的高速串行总线收发器serdes,使用的IP核又叫做(7 Series FPGA GTX/GTH Transceivers)官方关于此IP的介绍信息都在UG476上。
ug476_7Series_Transceivers.pdf • 查看器 • 文档门户 (xilinx.com)
Xilinx的7系列FPGA上都集成的有高速串行总线。在FPGA芯片上叫做GTX和GTH,其中GTX支持的速率从500Mb/s到12.5Gb/s,而且GTH支持的速率高达13.1Gb/s。对于这个速率我们来换算一下就知道有多快了。
12.5Gb/s=1.5625GB/s=1600MB/s
对于很多我们熟知的IP协议都是通过GTX/GTH实现的。比如说,PCIE1.1/2.0/3.0,XAUI,Serial RapidIO(SRIO),Serial Digital Interface (SDI)等等。
目录
GTX基础知识
IP的使用
无编码NONE模式example project仿真
使用8B/10B编码的example project仿真
使用64B/66B编码的example project仿真
-
GTX基础知识
GTX/GTH是集成在FPGA上的,可以通过IP或者原语来调用他们。其在FPGA中的位置如下图所示。
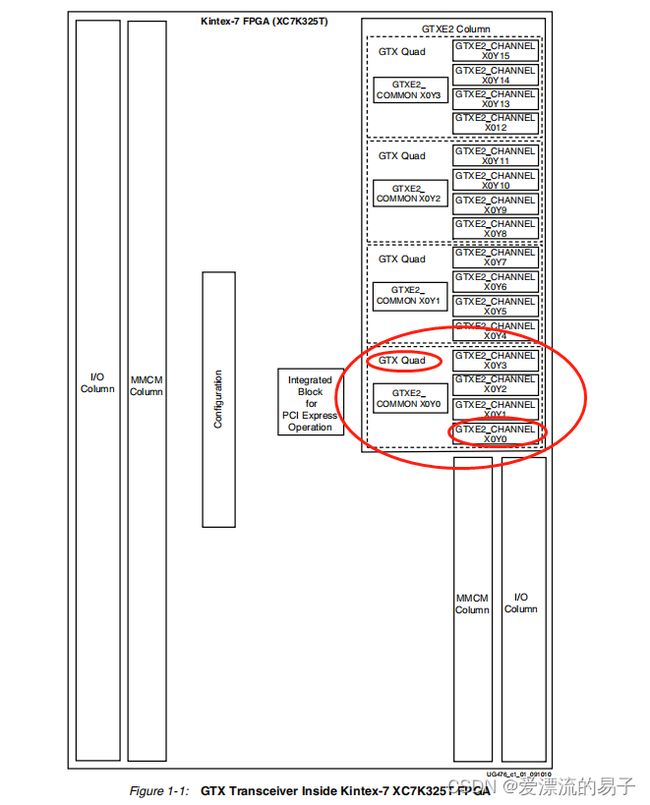
如上图所示,K7(XC7K325T)拥有16个GTX高速收发器。
其中四个GTXE2_CHANNEL和一个GTXE2_COMMON组合在一起叫Quad或者Q。其中GTXE2_COMMON原语包含一个QPLL。
一个Quad结构如下图所示:

一个Quad里面有四组GTXE2_CHANNEL,一个QPLL和一对差分输入。
每个GTXE2_CHANNEL包含一组TX和RX,以及一个CPLL。
CPLL:在GTX里面大概工作在1.6GHZ到3.3GHZ之间。在GTH里面工作在1.6GHZ到5.16GHZ之间。
QPLL的工作范围如下表。

FPGA会根据你设置的需求自动设置QPLL和CPLL。
一个GTXE2_CHANNEL结构如下图所示。
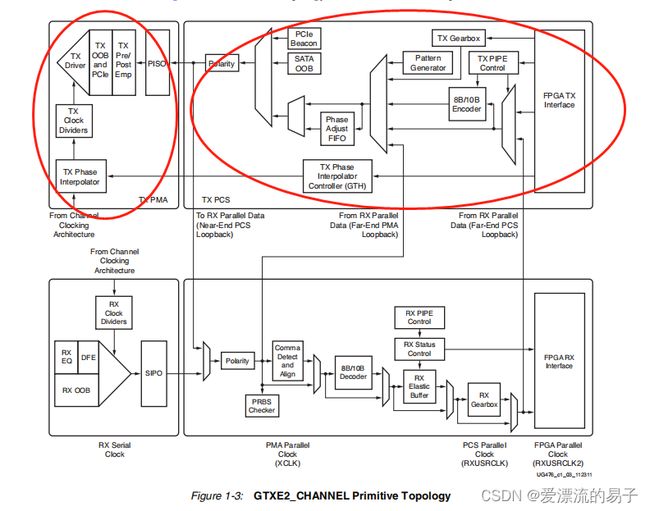
包含一组收发器。对于发射器TX,他包含一个PCS和一个PMA。并行数据经过FPGA TX接口,通过PCS和PMA,然后转化为高速串行数据发送出去。
OOB:Out_OF_Band边带信号。
PISO:Parallel In Serial Out并进串出。
| 模块(TX) |
作用 |
| FPGA TX Interface |
并行数据输入 |
| TX 8B/10B Encoder |
8N/10B编码器,编码TX并行数据。可以绕过。 |
| TX Gearbox |
一些高速数据数率协议使用64B/66B编码。还支持64B/67B编码。 |
| TX Buffer |
TX Buffer连接着两个不同的时钟域XCLK和TXUSERCLK,在PCS中包含两个时钟域XCLK和TXUSERCLK,TX Buffer用于匹配两个时钟域的速率和消除两个时钟域的相位差。 |
| TX Buffer Bypass |
绕过TX缓冲区。 |
| TX Pattern Generator |
伪随机位序列(PRBS)在GTX中可以用来测试高速串行通道传输的误码率。 |
| TX Polarity Control |
硬件上画反了TX和RX可以用它来交换极性。 |
对于RX:
EQ :Equalizer/均衡器;
OOB:Out-Of-Band/边带信号;
CDR:Clock and Data Recovery/时钟恢复;
SIPO:Serial In Parallel Out/串进并出;
| 模块(RX) |
作用 |
| RX Equalizer (DFE and LPM) |
RX模拟信号进来,首先经过RX均衡器,主要作用就是用于补偿信号在信道传输过程中的高频损失。RX接收端有两种自适应均衡器,LPM和DFE。LPM的功耗较低,DFE可以更好补充信道损失。 |
| RX CDR |
每个GTX_CHANNEL收发器中的RX时钟数据恢复(CDR)电路从传入的数据流中提取恢复的时钟和数据。外部数据先经过均衡器,接着均衡器出来的数据就进入时钟数据恢复电路。CDR的目标就是找到最佳的采样时刻。CDR有个最长的连0和连1的忍耐度,如果数据长时间没有电平变换,CDR就会失去精确度。出现错误的采样。(因此我们需要使用数据编码来减少连续的0和1出现的概率,serdes支持8B/10B编码,64B/66B编码) |
| RX Polarity Control |
硬件上画反了TX和RX可以用它来交换极性。 |
| RX Pattern Checker |
内置的PRBS检查器,工作在边界对齐和解码之前,这个功能可以用来测试信号的完整性。 |
| RX Byte and Word Alignment |
串行数据必须边界对齐,才能当做并行数据使用。这个边界是由TX发送的一个可识别序列,通常叫做comma。接收端在数据中找到这个comma,并将后面的数据以这个标识符为边界进行并行化操作。 |
| RX 8B/10B Decoder |
8B/10B解码器。 |
| RX Buffer Bypass |
调整相位差,实现可靠的数据传输。主要解决SPIO并行时钟域到PCS RX XCLK之间的相位差,实现SPIO到PCS之间可靠的数据传输。 |
| RX Elastic Buffer |
GTX/GTH收发器内部包括两个内部并行时钟域:PMA并行时钟域XCLK和RXUSRCLK时钟域。为了正确接收数据,PMA并行速率必须匹配RXUSRCLK时钟速率,并且解决跨时钟域问题。 |
| RX Buffer Bypass |
旁路RX弹性缓冲区是7系列GTP收发器的高级特性。RX相位对齐电路用来调整SIPO并行时钟和XCLK时钟域相位差异,以保证数据从SIPO可靠的传输到PCS组件。 |
| RX Clock Correction |
RX Elastic Buffer区域用来连接两个不同的时钟域,RXUSERCLK和XCLK。即使这两个时钟同频,也存在一些差异,这时候就需要时钟修正。为了进行修正,GTX会定期传输特殊字符,并允许GTX/GTH在弹性缓冲区中删除这些字符。防止接收器上溢和下溢。 |
| RX Channel Bonding |
XAUI和PCIE等协议使用多个串行收发器以产生更高的数据吞吐量。由于每个收发器所在的通道延迟可能存在差异,这会导致通道间数据会存在“错位”现象,RX通道绑定功能就解决此问题。在发送端发送一些特殊字符。接收端收到后判断每个通道间的偏移,并调整。只支持8B/10B编码。 |
-
IP的使用
前面的一堆基础知识全是UG476上面xilinx对他们家产品的介绍。下面我们开始配置一个IP,并对他进行简单的收发测试。
首先在IP catalog搜索GT
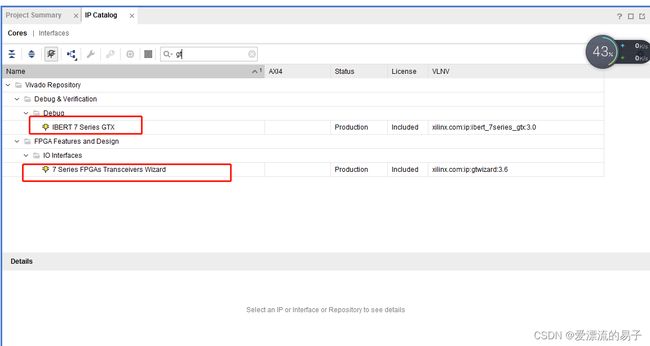
出现了如下两个IP。
IBERT 7 Series GTX是测试GTX传输信道质量。
7 Series FPGA Transceivers Wizard就是我们今天测试的主角。
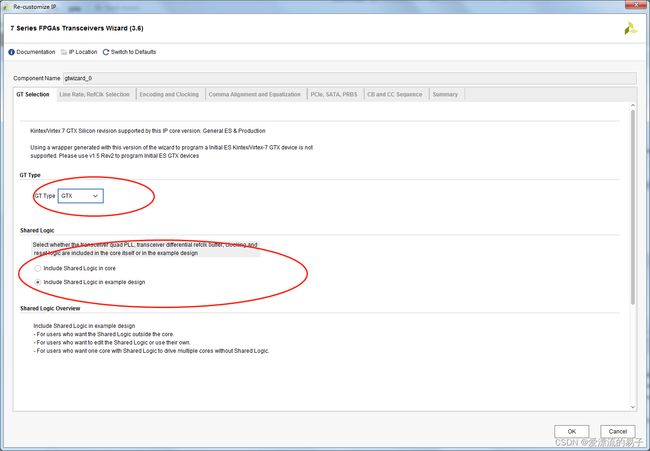
第一页默认就好,我们使用的芯片为xc7k325tfbg676-2 (active)默认为GTX。
接下来第二页配置比较重要。
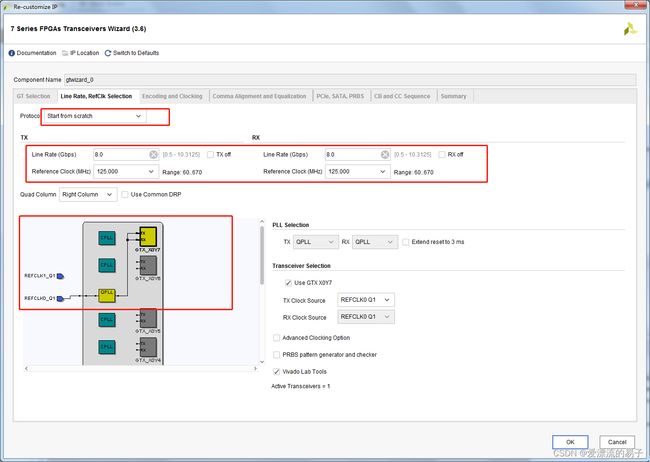
这里serdes支持很多种协议,我们直接选择start form scratch(无协议)。
接下来配置线速度,我们使用的的是GTX,线速度范围可以达到0.5Gbps到10.3125Gbps。
这里的线速度范围内区间都可以选择,软件会根据你选择的速率自动计算好参考时钟的范围。这里我们选择8Gbps,则通过CDR还原出来的串行时钟为4GHZ。通过软件计算后的参考时钟125MHZ(比较常见)。前面我们提到过,CPLL和QPLL支持的线速率参考范围不一样。我们这里设置线速率为8Gpbs已经超过了GTX的CPLL的支持的频率范围(CPLL范围1.6GHZ到3.3GHZ)
接下来是选择哪一个收发器,查看UG476附录GTX Transceiver Package Placement Diagrams。结合硬件原理图,发现使用的是GTX_X0Y7收发器。我们选择了位于BANK116上Quad上的收发器。这里只选择一组。
勾选VIVADO LAB TOOLS,可以方便打开XILINX的example project。
接下来,第三页。配置编码和时钟。
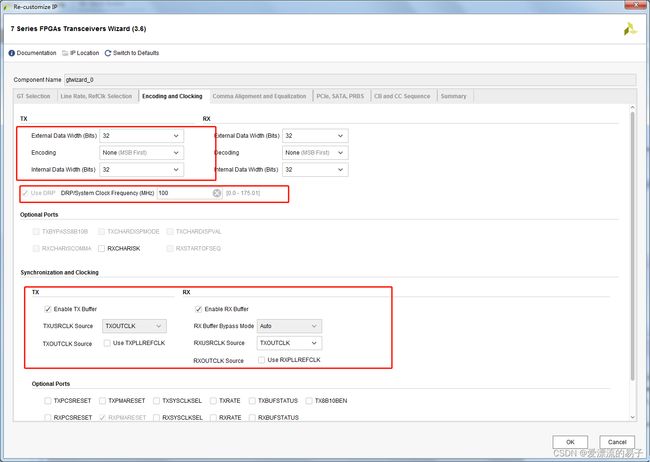
选择数据位宽。外部支持的数据位宽,这里默认32位。
编码方式。
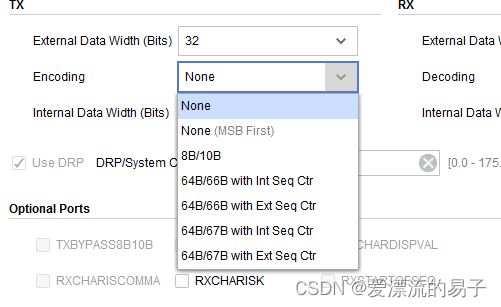
这里支持很多种编码方式。
None无编码。数据直接发送,分LSB和MSB先发。
8B/10B编码。
64B/66B编码。分为两种计数器模式。
64B/67B编码。64B/66B,64B/67B都使用了Gearbox高速编码协议。
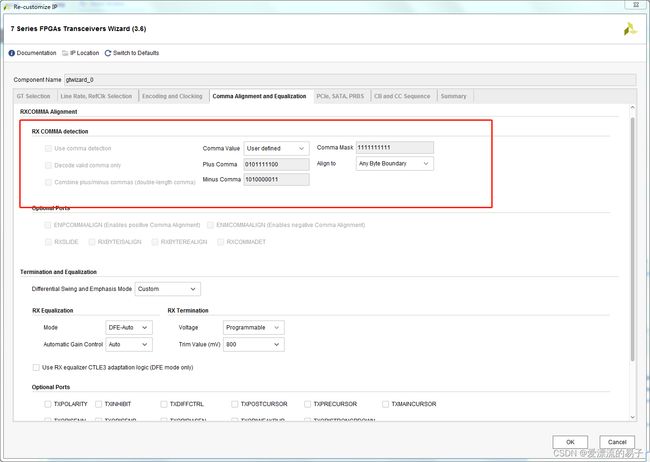
接下来是第四页的配置边界对齐和均衡器设置。
我们先选择的无编码模式,直接默认即可。对于8B/10B编码在配置。
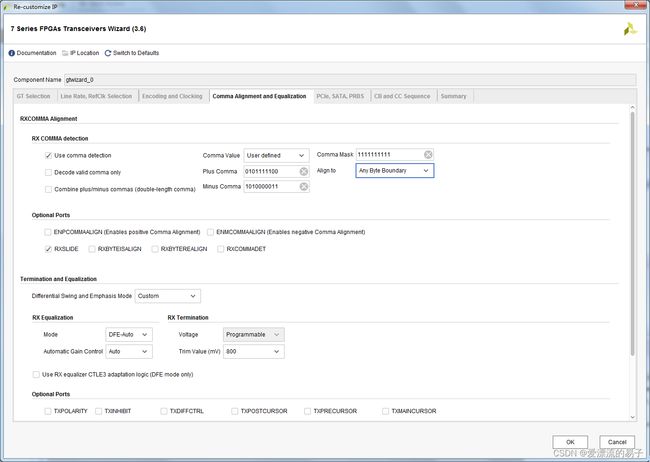
第五页的配置,PCIE部分不设置。悬着LOOPBACK回环。
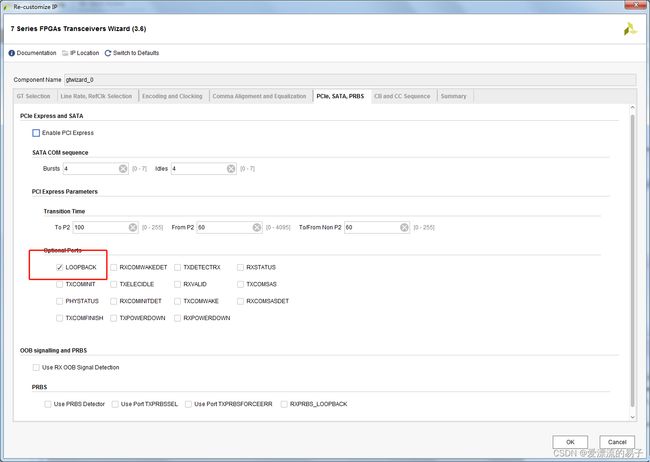
第六页配置时钟校准默认即可。

第七页总结
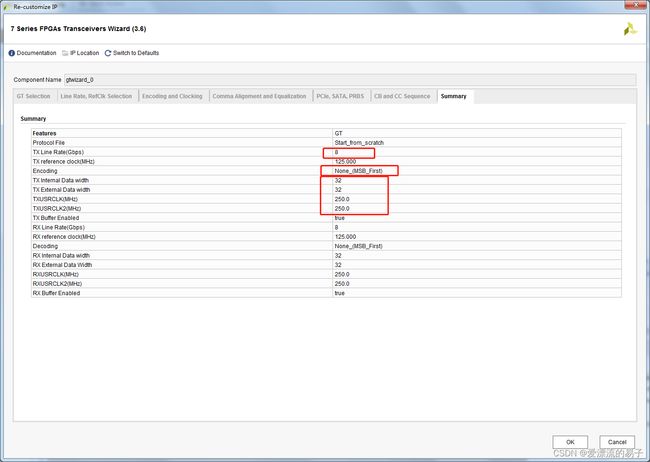
线速率8Gbps,数据位32位,TXUSRCLK25MHZ,编码方式无编码高位在前。
接下来我们打开example project
-
无编码NONE模式example project仿真
模式一:8Gbps速率,无编码模式,数据位宽32位。RX参考时钟125MHZ。
打开例子工程,代码结构如下。
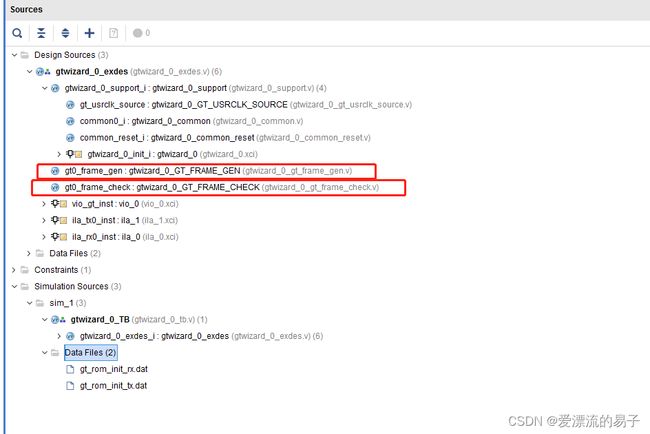
| 模块 |
作用 |
| gtwizard_0_support |
例化GTX,例化时钟,复位,原语等。 |
| gtwizard_0_GT_USRCLK_SOURCE |
产生TX/RXUSRCLK,产生参考时钟。 |
| gtwizard_0_common |
主要例化GTXE2_COMMON原语 |
| gtwizard_0_common_reset |
产生gtwizard_0_common里面的QPLL复位信号 |
| gtwizard_0_GT_FRAME_GEN |
重要模块,产生数据模块。数据产生首先从文件中读取到一个512位深度的ROM中。在从ROM中将数据一个一个发送出去。 |
| gtwizard_0_GT_FRAME_CHECK |
重要模块,数据检查模块。仿真中在TB上将TX连接到了RX,RX接收到的数据为TX发送出去的数据。同样的先从文件中读取数据到ROM,在比较接收的数据和ROM中数据是否一致。从而报错。 |
这里为了测试数据传输。XILINX在文件中设计了递增数列。

我们打开文件。发现发送的数据是一个递增数据。
03020100
0605047C
0A090807
...

接收数据文件gt_rom_init_rx.dat和发送端数据gt_rom_init_tx.dat保持一致。
下面我们来分析收发两端的代码。首先看发送端。
gtwizard_0_GT_FRAME_GEN #
(
.WORDS_IN_BRAM(EXAMPLE_WORDS_IN_BRAM)
)
gt0_frame_gen
(
// User Interface
.TX_DATA_OUT ({gt0_txdata_float_i,gt0_txdata_i,gt0_txdata_float16_i}),//要发送的数据
.TXCTRL_OUT (),//发送端口边界对齐,无编码时不使用
// System Interface
.USER_CLK (gt0_txusrclk2_i),//数据和复位
.SYSTEM_RESET (gt0_tx_system_reset_c)
);发送端的代码很简单,首先从gt_rom_init_tx.dat中读出数据到512位深度的ROM。其次,在每一个时钟沿累加read_counter_i,从ROM中读出数据。发送到TX上。
在看接收端。

接收端的代码相对于发送端要复杂一些。
首先从接收机接收的并行数据是没有经过对齐的。前面提到过对于接收端有个模块叫做RX Byte and Word Alignment即RX字节和字对齐。对齐的过程在gtwizard_0_GT_FRAME_CHECK代码中我们可以看到。是对比接收的数据和设定的参数START_OF_PACKET_CHAR是否一致,如果不一致则产生一个RX_SLIDE让接收器右移一次。这样经过多次的右移,接收器终于对齐了,接收到了正确的数据。这时候模块将对比接收到的数据和ROM中的数据是否一致。来产生ERROR_COUNT_OUT错误的数据个数。
always @(posedge USER_CLK)
begin
if( (system_reset_r2 == 1'b1) | (rxdata_or == 1'b0) ) begin
bit_align_r <= 1'b0;
end else begin
if( ({rx_data_r2[23:0],rx_data_r[31:24]} == START_OF_PACKET_CHAR) || ({rx_data_r2[15:0],rx_data_r[31:16]} == START_OF_PACKET_CHAR) || ({rx_data_r2[7:0],rx_data_r[31:8]} == START_OF_PACKET_CHAR) || (rx_data_r[31:0]== START_OF_PACKET_CHAR) )
begin
bit_align_r <= 1'b1;
end
end
end接下来输出TRACK_DATA_OUT信号,表示链路已经建立,数据可以进行正常的传输。接下来我们修改一下发送模块和接收模块。
我们在发送模块设置一下,当检测到链路建立完毕后,准备发送数据累加数,0,1,2,3,4...
reg data_test_start;
//当链路完成后,进入数据发送模式。
always@(posedge USER_CLK)
begin
if(system_reset_r2)
data_test_start <= 1'b0;
else if(TRACK_DATA_OUT == 1'b1)
data_test_start <= 1'b1;
else
data_test_start <= data_test_start ;
end
//修改发送。在链路建立完成前发送ROM的数据,完成后发送累加数。
always @(posedge USER_CLK)
begin
if(data_test_start == 1'b0)
tx_data_ram_r <= `DLY rom[read_counter_i];
else
tx_data_ram_r <= `DLY {32'h0,data_test,16'h0};
end
reg [31:0] data_test;
always@(posedge USER_CLK)
begin
if(system_reset_r2)
data_test <= 1'b0;
else if(data_test_start == 1'b0)
data_test <= 1'b0;
else
begin
if(data_test == 32'd512)
data_test <= 32'h0;
else
data_test <= data_test + 32'd1;
end
end接收模块照常让他训练,当数据链路建立完毕后,接收来自发射机的数据。当然接收端由于没有修改check机制,接收到的数据会在接收到累加数后报错。不过不影响我们这边的仿真观察。
仿真模型。
发送端
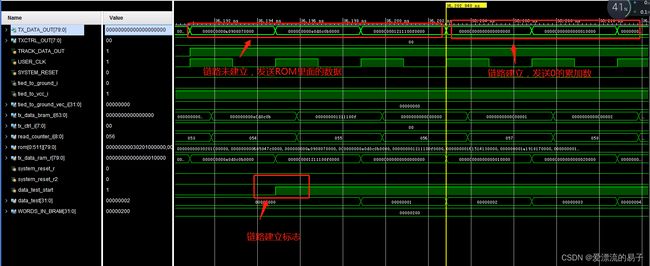
接收端
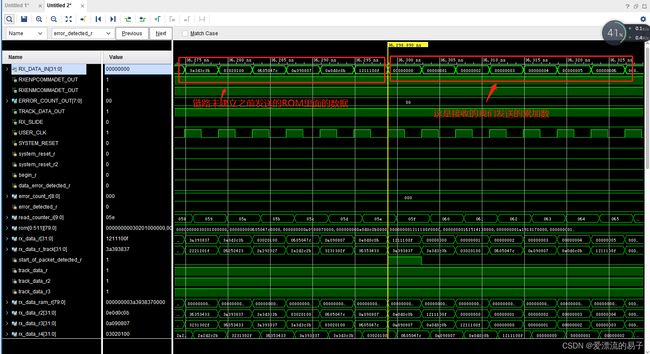
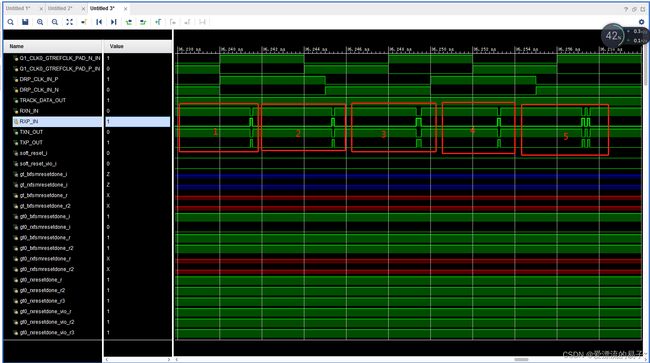
那么数据在没有经过编码的时候是怎么在TX和RX上传输的呢?
这里我们找到在串行总线上传输的前五个数据1,2,3,,4,5,波形和并串转换的数据波形一致。从上面可以看出来,没有经过编码的数据在TX和RX上传输的时候会出现连续的高电平和低电平,这非常不利于RX接收端的CDR的数据时钟恢复。当然我们这里只是做仿真,误码率的测试应该上板结合眼图观察。
-
使用8B/10B编码的example project仿真
模式2:8Gbps速率,8B/10B编码模式,数据位宽32位。RX参考时钟125MHZ。
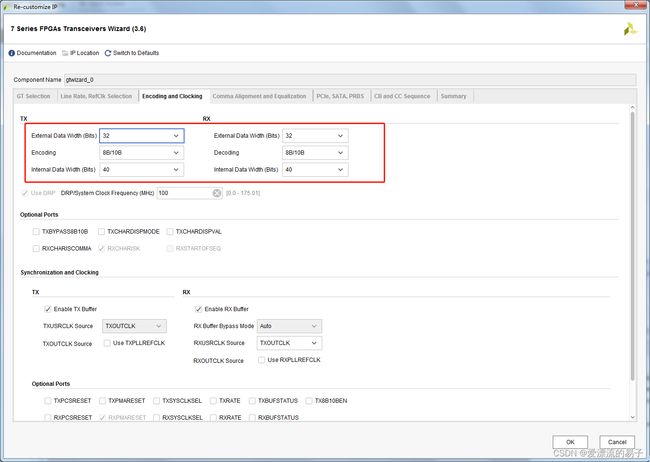
IP配置界面只需要在编码模式界面选择8B/10B编码即可。可以看到外部数据位宽还是32位,但是内部数据位宽已经变成了40位。
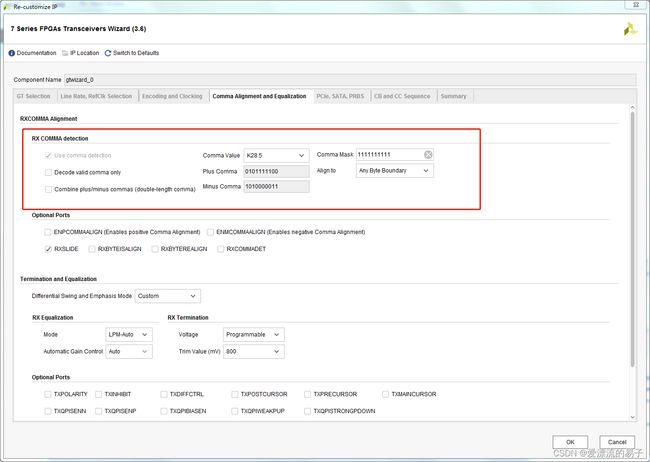
同时,边界对齐自动选择了K28.5,这里我们默认配置就好。
同样的,我们打开example project。
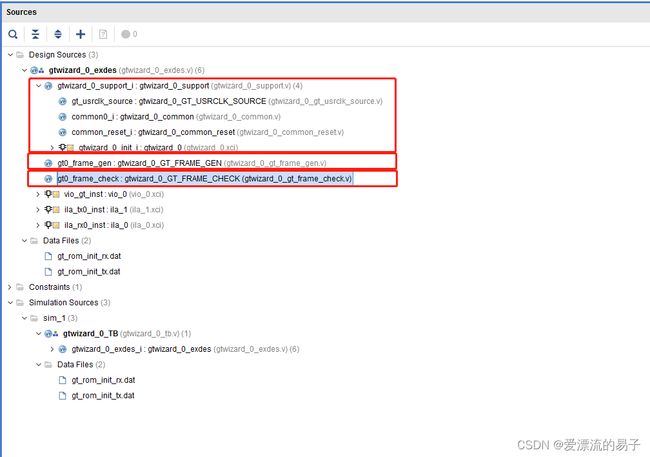
工程的代码结构与无编码模式下结构无差别。各个模块的功能上并无差别,这里就不一一介绍了。
下面看看XILINX准备的收发数据文档。打开文件后发现发送的数据同样是一个递增数列。
03020100
060504BC
0A090807
...

我们看到这里的数据比较奇怪,出现了00000000060504bc0100,低十六位出现了一个0100。
这里我们说的8B/10B编码,那么什么是这个编码呢?他又干了一件什么事呢?
经过上面的仿真我们看到,没有经过编码的数据,在经过TX和RX发送出去后,会出现很长的一段连续的零和一。前面又提到了,RX接收器需要从传入的数据流中提取恢复的时钟和数据。那么对于长时间不变化的数据流,就会造成恢复的时钟出现抖动,从而出现不可预计的误码。就是传输错误。这当然使我们不愿意看到的,那么为了降低这种误码率。使CDR恢复出稳定的时钟,这时候就需要使用编码器。对待发送的数据进行编码。从而使传输的数据中的零和一的数据达到平衡,并且拥有零和一的变化(减少连续零和一的出现)。
这里由于篇幅原因,就不深究了。
XILINX的SERDES使用8B/10B编码来传输数据信息。并且使用了特殊字符(K字符)用做控制功能。TXCHARRISK端口用于指示TXDATA上的数据是K码还是数据。8B/10B编码器检查接收到的TXDATA字节是否匹配任何K码,如果对应则将TXCHARISK拉高。
同理,在接收端,8B/10B解码器,当RXDATA检测到K码时,解码器将驱动RXCHARISK为高电平。
同样的,我们来对模块进行修改一下,改为发送我们自定义的数据。
//当链路完成后,进入数据发送模式。
always@(posedge USER_CLK)
begin
if(system_reset_r2)
data_test_start <= 1'b0;
else if(TRACK_DATA_OUT == 1'b1)
data_test_start <= 1'b1;
else
data_test_start <= data_test_start ;
end
//修改发送。在链路建立完成前发送ROM的数据,完成后发送累加数。
always @(posedge USER_CLK)
begin
if(data_test_start == 1'b0)
tx_data_ram_r <= `DLY rom[read_counter_i];
else
tx_data_ram_r <= `DLY {32'h0,data_test,data_k_comme};
end
reg [31:0] data_test;
reg [15:0] data_k_comme;
always@(posedge USER_CLK)
begin
if(system_reset_r2)
begin
data_test <= 32'h0;
data_k_comme <= 16'h0;
end
else if(data_test_start == 1'b0)
begin
data_test <= 1'b0;
data_k_comme <= 16'h0;
end
else
begin
if(data_test == 32'd512)
begin
data_test <= 32'h060504bc;
data_k_comme <= 16'h0100;
end
else if(data_test == 32'h060504bc)
begin
data_test <= 32'h0;
data_k_comme <= 16'h0;
end
else
begin
data_test <= data_test + 32'd1;
data_k_comme <= 16'h0;
end
end
end同样的我们在链路完成后,在TX上准备自己要发送的数据。发送的数据类容为0到512的数据循环,在一次循环完成后发送一次K码。并重新计数。
同理,在接收模块。接收模块会对接收的数据进行判断。我们需要在第一次判断后就不更改接收后数据位的交换。我们将SEL判定改为在接收到与ROM不同的数据后不重新设置SEL的值。
// Comma realignment logic might be needed. 4 levels of registering for RXDATA to meet timing
// In 4 Byte scenario, when align_comma_word=1, Comma can appear on any of the four bytes.
// { BYTE3 | BYTE2 | BYTE1 | BYTE0 } - Comma can appear on BYTE0/1/2/3
// If Comma appears on BYTE1/2/3, RX_DATA is realigned so that Comma appears on BYTE0 in rx_data_r_track
always @(posedge USER_CLK)
begin
// if(reset_on_error_in_r2 || system_reset_r2) sel <= 2'b00;
if( system_reset_r2) sel <= 2'b00;
else if (begin_r && !rx_chanbond_seq_r)
begin
// if Comma appears on BYTE3 ..
if((rx_data_r[(RX_DATA_WIDTH - 1) : 3*RX_DATA_WIDTH/4] == START_OF_PACKET_CHAR[7:0]) && rxctrl_r[3])
sel <= 2'b11;
// if Comma appears on BYTE2 ..
else if((rx_data_r[(3*RX_DATA_WIDTH/4 - 1):2*RX_DATA_WIDTH/4] == START_OF_PACKET_CHAR[7:0]) && rxctrl_r[2])
begin
sel <= 2'b10;
end
// if Comma appears on BYTE1 ..
else if((rx_data_r[(2*RX_DATA_WIDTH/4 - 1):RX_DATA_WIDTH/4] == START_OF_PACKET_CHAR[7:0]) && rxctrl_r[1])
begin
sel <= 2'b01;
end
// if Comma appears on BYTE0 ..
else if((rx_data_r[(RX_DATA_WIDTH/4 - 1):0] == START_OF_PACKET_CHAR[7:0]) && rxctrl_r[0])
begin
sel <= 2'b00;
end
end
end这样我们在观察发送模块的仿真。
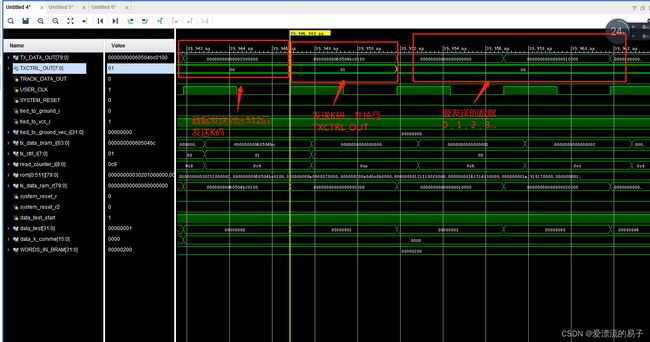
同样的我们观察接收模块的仿真。

同样观察数据在TX和RX上传输的效果。
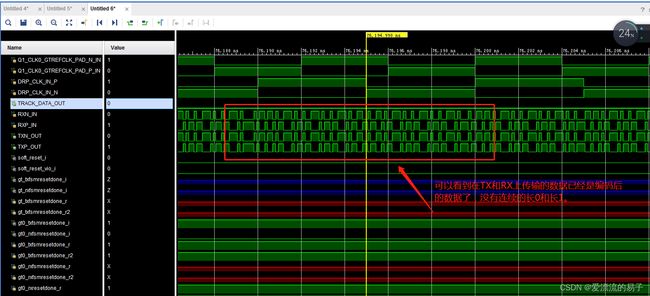
-
使用64B/66B编码的example project仿真
前面看了SERDES在无编码和8B/10B编码下传输的模式。但是对于很多高速的协议使用的则是64B/66B编码,相比较于8B/10B编码减少了编码的开销。
下面我们就在IP上看一下吧。
同样的,我们在IP上选择64B/66B编码,然后在打开example project。配置界面如下,在选择64B/66B编码时,他有两种模式,一个是外部计数器,一个是内部计数器。两种模式下的工程XILINX都在例子工程里面设置好了。这里我们直接选择64B/66B with int Seq Ctr模式。
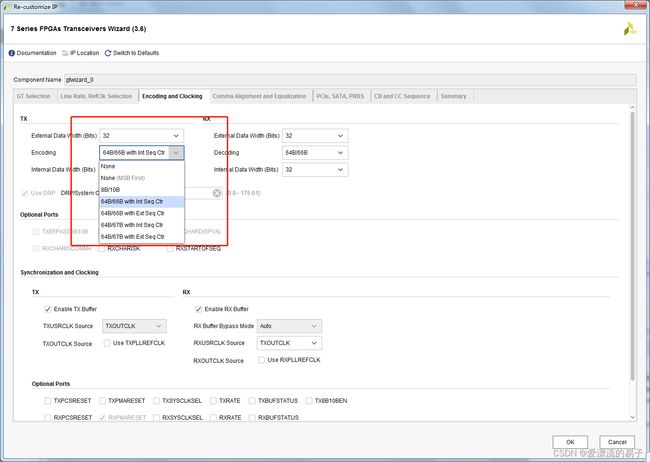
由于选择了64B/66B编码,所以comma就不需要了。默认为不使用。
同样的,我们直接打开例子工程。打开工程后代码的结构如下。相比于无编码和8B/10B编码模式下多了两个模块。这是64B/66B编码模式下特有加扰器和解扰器。
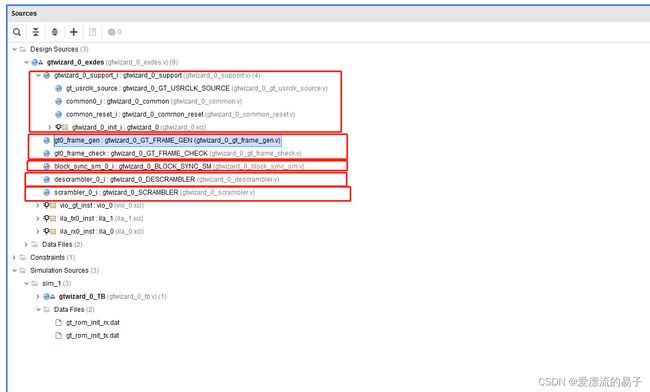
| 模块 |
作用 |
| gtwizard_0_BLOCK_SYNC_SM |
64B/66B编码模式下特有的对齐模块。对接收的gt0_rxheader_i头进行查找。 |
| gtwizard_0_DESCRAMBLER |
64B/66B编码模式下的解扰器。对RX接收的数据进行解扰,解扰后的数据在进入gtwizard_0_GT_FRAME_CHECK模块进行检测。 |
| gtwizard_0_SCRAMBLER |
64B/66B编码模式下的加扰器。 |
那么要使用64B/66B编码,就要了解这个编码的基本信息。64B/66B编码将64bit的数据或控制信息编码成66bit块传输。66bit块的前两位表示同步头,主要用于接收端数据的对齐和结合数据流的同步。表头有01和10两种,01表示后面的64bit都是数据,10表示后面64bit是数据和控制信号的混合。而绕码是一种将数据重新编排或者进行编码以让数据中的0和1的分部更加随机化,从而提高了通信的稳定。
在这里的加扰和解扰的代码XILINX都已经给了出来,我们就不去过多研究了。还是主要看看模块的数据发送和数据接收模块。如何在此例子工程上添加合适的代码发送自己的数据。
同样的XILINX为了数据传输这里,也设置测试的数据。下面我们来看看他测试得数据吧。
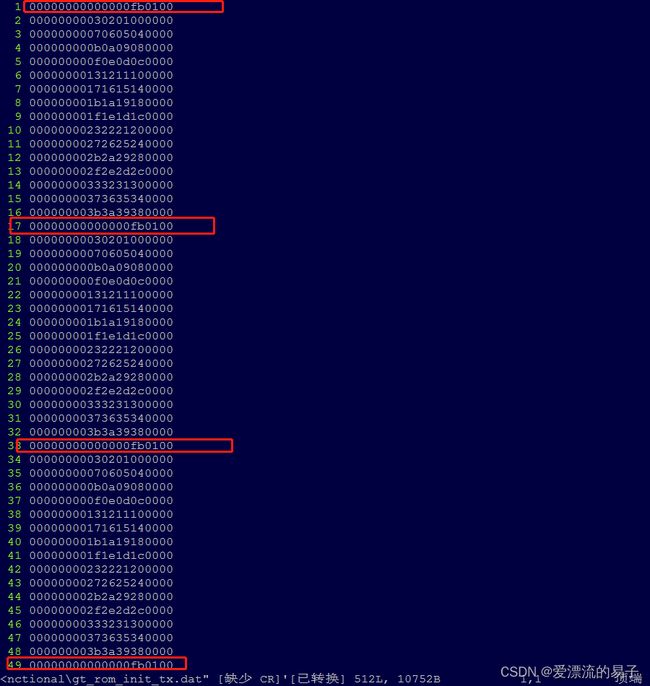
测试的数据为
00000000000000fb0100
00000000030201000000
00000000070605040000
...
递增数据,且每个十五个数据将产生一个00000000000000fb0100用于产生头。
下面,我们来对模块进行修改一下,改为发送我们自定义的数据。首先数据链路建立完成后,产生自定义数据。注意数据在计数器工作模式下,会有一个时间暂停数据发送。也就是在TXDATAVALID_IN等于一的情况下我们在将要发生的数据更新并发送。为零的情况下就暂停数据发送(即锁存)
//当链路完成后,进入数据发送模式。
reg data_test_start;
always@(posedge USER_CLK)
begin
if(system_reset_r2)
data_test_start <= 1'b0;
else if(TRACK_DATA_OUT == 1'b1)
data_test_start <= 1'b1;
else
data_test_start <= data_test_start ;
end
//修改发送。在链路建立完成前发送ROM的数据,完成后发送累加数。
always @(posedge USER_CLK)
begin
if(data_test_start == 1'b0)
tx_data_ram_r <= `DLY rom[read_counter_i];
else
tx_data_ram_r <= `DLY {32'h0,data_test,data_k_comme};
end
reg [31:0] data_test;
reg [15:0] data_k_comme;
always@(posedge USER_CLK)
begin
if(system_reset_r2)
begin
data_test <= 32'h0;
data_k_comme <= 16'h0;
end
else if(data_test_start == 1'b0)
begin
data_test <= 1'b0;
data_k_comme <= 16'h0;
end
else if(TXDATAVALID_IN == 1'b1)
begin
if(data_test == 32'd200)
begin
data_test <= 32'h0000_00fb;
data_k_comme <= 16'h0100;
end
else if(data_test == 32'h0000_00fb)
begin
data_test <= 32'h0;
data_k_comme <= 16'h0;
end
else
begin
data_test <= data_test + 32'd1;
data_k_comme <= 16'h0;
end
end
end
同样的在接收端不做修改。这样收到的数据虽然会产生ERROR_COUNT_OUT错误,但是这是和ROM里面自定义数据对比的情况。我们正常传输的数据还是正确的。
这样我们在观察发送模块的仿真。
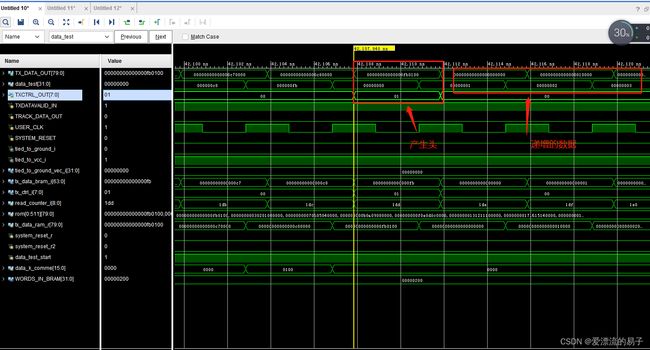
在TXDATAVALID_IN为零的情况下停止更新数据。
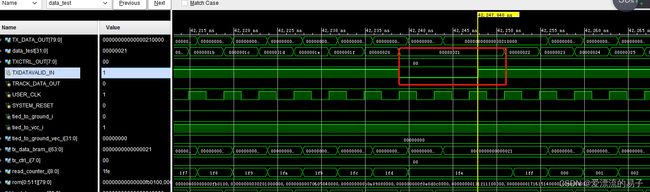
这样我们在观察接收模块的仿真。在RXDATAVALID_IN为零的情况下接收的数据停止更新。且接收的数据是连续的0到200的递增数列。
