分布式锁的原理,并基于redis,zookeeper和mysql方式实现
分布式锁的原理,并基于redis,zookeeper和mysql方式实现
一. 背景
在分布式环境下 为了解决 资源抢占问题 和 幂等性 等问题 ,单机锁已经无法解决这个问题了,所以会使用到分布式锁,
这一篇主要介绍:
- 利用redis实现 非公平性分布式锁 (核心思想)
- 浅谈redisson组件实现 非公平性分布式锁
- 基于mysql实现 非公平性分布式锁
- 基于zookeeper实现 公平性分布式锁
所以接下来的内容会比较多,而且涉及到redis, lua脚本, redisson, zk的使用,所以希望大家可以耐心看下去。
在单机环境下,我们可以直接使用Lock锁或者synchronized,前面的篇章也介绍了ReentrantLock锁的源码解读,
感兴趣的小伙伴可以看一下 ↓↓↓
传送门:并发编程之AQS与ReentrantLock锁源码/原理剖析
二. 利用redis实现分布式锁
1. 原始版本
我们如果想利用redis实现分布式锁,首先能想到的就是针对redis中的某一个key进行操作,如果线程A把这个 key插入到了 redis,那么就相当于线程A获取到该锁,然后执行业务代码,执行完业务代码之后释放锁,然后其他的线程去做相同的操作,根据这个思想,下面是代码实现:
/**
* 原始版本
* 1. 先查看是否可用锁
* 2. 若可用 则占用锁
*/
public void version1(){
String key = "lock";
Object value = redisTemplate.opsForValue().get(key);
if (value == null){
value = Thread.currentThread().getName();
redisTemplate.opsForValue().set(key,value);
// 业务操作
try{
System.out.println("执行业务操作...");
}catch (Exception e){
e.printStackTrace();
}finally {
redisTemplate.delete(key);
}
}
}
代码解读:
1) 首先查看redis中是否存在key=‘lock’的数据。
2) 如果没有,就插入这条数据,其中key = 'lock', value = '当前线程的线程ID'。
3)如果执行了步骤2就相当于获取了锁,然后执行业务代码,执行完之后,删除该条数据,释放锁。
4) 如果执行步骤1的时候发现redis中已经有这条数据了 就表示已经有线程抢占到了锁 则获取锁失败。
这里会存在什么问题呢:
1) 假设执行 redisTemplate.opsForValue().get(key) 之后, 发现redis中没有这条数据,然后执行 redisTemplate.opsForValue().set(key,value) 去上锁,但是在这两步中间,有其他线程首先上锁成功了,那么就会出现不同线程持有锁的问题。
2) 假设线程A上锁成功,但是由于业务代码阻塞或者直接卡死,再或者机器宕机了,没有执行redisTemplate.delete(key) ,那么这个锁永远没法释放,就会形成死锁。
3) 同一个线程不能实现锁的重入。
然后我们思考,如何解决这三个问题:
-
针对与第一个问题,需要做的是 redisTemplate.opsForValue().get(key) 和 redisTemplate.opsForValue().set(key,value) 这两步能原子性执行,我们首先想到的是redis的事务,其实除了直接使用redis的事务,还有一种比较友好和灵活的方式,就是可以利用 lua脚本 实现原子性,大家都知道redis工作方式是单线程的,redis在执行lua脚本中的指令时,可以保证原子性,中途不会被其他线程插入。
-
针对于第二个问题,我们可以利用redis的过期时间机制来实现。
-
针对于第三个问题,我们可以利用redis的hash表的数据结构实现,也就是说redis中在保存lock锁的同时,将线程ID当作hash表中的key,然后将重入次数当作hash表中的value。
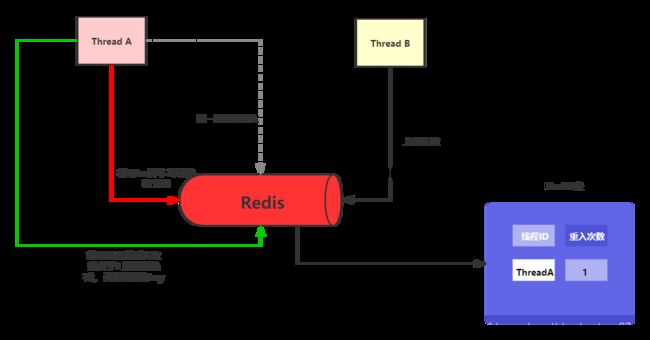
2. 改良版本
根据我们发现的问题和进行思考得到的解决方案,进一步优化和完善,下面是改良版本的代码:
/**
* 改良版本
* 1. 先查看是否可用锁
* 2. 若可用 则占用锁
* 3. 给锁设置过期时间
* 上面这三个步骤利用 lua 脚本保证"原子性"(相比于不使用事务)
* 4. 利用 lua 脚本释放锁
*/
public void version2(){
String key = "lock";
String hkey = Thread.currentThread().getId();
// 执行上锁的lua脚本
Boolean result = lockLua(key, hkey);
if (result){
// 业务操作
try{
System.out.println("执行业务操作...");
}catch (Exception e){
e.printStackTrace();
}finally {
// 执行释放锁的lua脚本
unLockLua(key, hkey);
}
}
}
/**
* 执行上锁的lua脚本
* hkey:当前线程的线程ID
* 暂时这里过期时间写死10秒
*/
private Boolean lockLua(String key, String hkey){
try{
DefaultRedisScript<Boolean> script = new DefaultRedisScript<>();
script.setScriptSource(new StaticScriptSource("if (redis.call('exists', KEYS[1]) == 0) then" +
" redis.call('hset', KEYS[1], ARGV[1], 1);" +
" redis.call('expire', KEYS[1], ARGV[2]);" +
" return true;" +
"end;" +
"if (redis.call('hexists', KEYS[1], ARGV[1]) == 1) then" +
" redis.call('hincrby', KEYS[1], ARGV[1], 1);" +
" redis.call('expire', KEYS[1], ARGV[2]);" +
" return true;" +
"end;" +
"return false;"));
script.setResultType(Boolean.class);
List<String> keys = Collections.singletonList(key);
return redisTemplate.execute(script, keys, hkey, 10);
}catch (Exception e){
logger.error(e.getMessage(),e);
return false;
}
}
/**
* 执行释放锁的lua脚本
* hkey:当前线程的线程ID
* 暂时这里过期时间写死10秒
*/
private void unLockLua(String key, String hkey){
try{
DefaultRedisScript<Boolean> script = new DefaultRedisScript<>();
script.setScriptSource(new StaticScriptSource("if (tonumber(redis.call('hget', KEYS[1], ARGV[1])) == 1) then" +
" redis.call('del', KEYS[1]);" +
" return true;" +
"end;" +
"if (tonumber(redis.call('hget', KEYS[1], ARGV[1])) > 1) then" +
" redis.call('hincrby', KEYS[1], ARGV[1], -1);" +
" return true;" +
"end;" +
"return false;"));
script.setResultType(Boolean.class);
List<String> keys = Collections.singletonList(key);
redisTemplate.execute(script, keys, hkey);
}catch (Exception e){
logger.error(e.getMessage(),e);
}
}
代码解读:
1) 首先利用 redis提供的 RedisScript创建两个lua脚本执行器,一个是lockLua()方法用来上锁,一个是unLockLua()方法用来释放锁, 如果上面代码的lua指令不明白的 可以找一下相关资料 这里就不多说了。
2) 执行业务代码之前 跑lockLua()方法的lua脚本 抢占锁。
3) 若抢占锁成功 执行业务代码 此时该线程允许对该锁的重入。
4) 执行完业务代码 调用unLockLua()方法释放锁,这个时候并不是直接删除key,而是查看当前线程的重入次数是否大于1,若大于1 则对重入次数的数值减1, 如果等于1 则直接删除该key 释放锁。
可能有些小伙伴觉得这个方案没什么问题了 ,但是仔细思考一下 ,是不是有这么一个问题,就是假设我的过期时间设置了10S,而突然某些时刻我的业务代码因为各种各样的原因 执行时间超过了10秒,也就是说我的 业务代码还没有执行完成 由于redis的过期机制 自动删除了该锁 ,那么就会存在多个线程重叠执行,也就相当于锁失效了。
如何解决这个问题呢: 大致思路是可以设置一个当前线程的 守护线程 ,当然这个守护线程是 逻辑上的,不是真正的Daemon守护线程,这个守护线程的 生命周期跟持有锁的线程的生命周期一样 ,这个守护线程的作用就是定时检查当前锁是否快要过期了 而且业务线程还没有结束 如果是这样就给锁 续期 。
3. 最终版本
根据改良版本的实现和思考,进而进行优化和完善,下面直接上代码:
/**
* 最终版本
* 1. 先查看是否可用锁
* 2. 若可用 则占用锁
* 3. 给锁设置过期时间
* 上面这三个步骤利用 lua 脚本保证"原子性"(相比于不使用事务)
* 4. 利用 lua 脚本释放锁
* 5. 启动一个逻辑上的守护线程, 给锁续期
* 6. 如果没有获取到锁 则自旋等待
*/
public void version3() throws InterruptedException {
String key = "lock";
String hkey = Thread.currentThread().getId();
for(;;){
// 自旋 去获取锁
Boolean result = lockLua(key, hkey);
if (result){
break;
}
Thread.sleep(100);
}
// 起一个线程 给锁续期
Thread refreshLock = new RefreshLock(key, 10L, 3, 3L, redisTemplate, refreshRedisScript);
try{
refreshLock.start();
// 业务操作
System.out.println("执行业务操作...");
}catch (Exception e){
e.printStackTrace();
}finally {
// 释放锁
unLockLua(key, hkey);
// 中断守护线程
refreshLock.interrupt();
}
}
/**
* 执行上锁的lua脚本
* hkey:当前线程的线程ID
* 暂时这里过期时间写死10秒
*/
private Boolean lockLua(String key, String hkey){
try{
DefaultRedisScript<Boolean> script = new DefaultRedisScript<>();
script.setScriptSource(new StaticScriptSource("if (redis.call('exists', KEYS[1]) == 0) then" +
" redis.call('hset', KEYS[1], ARGV[1], 1);" +
" redis.call('expire', KEYS[1], ARGV[2]);" +
" return true;" +
"end;" +
"if (redis.call('hexists', KEYS[1], ARGV[1]) == 1) then" +
" redis.call('hincrby', KEYS[1], ARGV[1], 1);" +
" redis.call('expire', KEYS[1], ARGV[2]);" +
" return true;" +
"end;" +
"return false;"));
script.setResultType(Long.class);
List<String> keys = Collections.singletonList(key);
return redisTemplate.execute(script, keys, hkey, 10);
}catch (Exception e){
logger.error(e.getMessage(),e);
return false;
}
}
/**
* 执行释放锁的lua脚本
* hkey:当前线程的线程ID
* 暂时这里过期时间写死10秒
*/
private void unLockLua(String key, String hkey){
try{
DefaultRedisScript<Boolean> script = new DefaultRedisScript<>();
script.setScriptSource(new StaticScriptSource("if (tonumber(redis.call('hget', KEYS[1], ARGV[1])) == 1) then" +
" redis.call('del', KEYS[1]);" +
" return true;" +
"end;" +
"if (tonumber(redis.call('hget', KEYS[1], ARGV[1])) > 1) then" +
" redis.call('hincrby', KEYS[1], ARGV[1], -1);" +
" return true;" +
"end;" +
"return false;"));
script.setResultType(Boolean.class);
List<String> keys = Collections.singletonList(key);
redisTemplate.execute(script, keys, hkey);
}catch (Exception e){
logger.error(e.getMessage(),e);
}
}
/**
* 守护线程
*/
public class RefreshLock extends Thread{
// 上的锁的redis中的key
private final String lockKey;
// 上锁的最大时间
private final Long expireTime;
// 总共允许续期几次
private final Integer count;
// 隔几秒刷新
private final Long refreshTime;
private final RedisTemplate redisTemplate;
private final DefaultRedisScript<Boolean> refreshRedisScript;
RefreshLock(String lockKey, Long expireTime, Integer count, Long refreshTime, RedisTemplate redisTemplate, DefaultRedisScript<Boolean> refreshRedisScript){
this.lockKey = lockKey;
this.expireTime = expireTime;
this.count = count;
this.refreshRedisScript = refreshRedisScript;
this.refreshTime = refreshTime;
this.redisTemplate = redisTemplate;
}
@Override
public void run() {
int countValue = count;
// 每一次自旋都检查是否被中断 如果是 则说明业务线程执行结束
while (!Thread.currentThread().isInterrupted() && countValue > 0){
try {
// 每隔0.5秒检查一次(可自定义)
Thread.sleep(500);
Boolean result = (Boolean) redisTemplate.execute(refreshRedisScript, Collections.singletonList(lockKey),expireTime,refreshTime);
if (result != null && result.equals(true)) {
countValue--;
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
代码解读:
1) 创建一个RefreshLock线程类 作为守护线程,它的run方法逻辑就是:每隔0.5秒去检查一下redis中的锁是否快要过期,如果剩余时间少于我们指定的一个 阈值 :refreshTime ,则给锁续期。
2) 防止无线续期 设置一个 阈值: count 最多续期次数,因为如果续期了多次 业务代码还未执行结束 则考虑是代码性能的问题 ,就需要优化代码了 为不是无限给锁续期。
3) 在执行业务代码之前 我们加了一段 自旋逻辑 去抢占锁 因为当一个线程没有抢占到锁的时候 它更想做的是 阻塞等待抢占到锁 而不是直接返回 。
4) 如何保证守护线程会随着业务线程的结束而结束呢,这里用到的是发送 interrupt() 命令,当业务线程执行完业务代码之后,会在 finally代码块 中向守护线程发送interrupt()友好中断指令,而在守护线程的自旋中 会判断是否被中断 如果中断 则结束,然后会 被JVM回收。
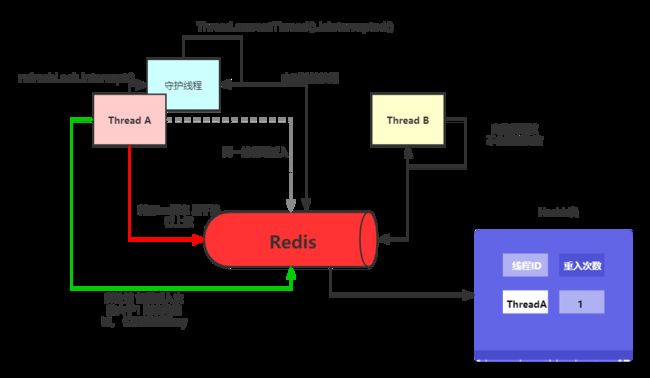
注意: 如果出现lua脚本数据类型转换错误的话,则可能是因为序列化的问题,可以自定义redis的序列化方式:
@Configuration
public class RedisSerializer {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 创建 redisTemplate 模版
RedisTemplate<Object, Object> template = new RedisTemplate<>();
// 关联 redisConnectionFactory
template.setConnectionFactory(redisConnectionFactory);
// 创建 序列化类
GenericToStringSerializer<Object> genericToStringSerializer = new GenericToStringSerializer<>(Object.class);
// 设置 value 的转化格式和 key 的转化格式
template.setValueSerializer(genericToStringSerializer);
template.setKeySerializer(new StringRedisSerializer());
template.afterPropertiesSet();
return template;
}
}
4.小结
从上面的原始版本到最终版本,我们的思路一步步清晰和完善,总结一下思路和需要注意的细节:
- 利用lua保证相对原子性 将多条命令在同一事务中执行
- 利用redis的hash表结构 实现相同线程可重入锁
- 没有抢占到锁的线程会自旋获取锁 不会直接失败
- 起一个业务线程的守护线程 去维护锁的过期时间 并且利用interrupt友好中断 保证守护线程和主线程同时结束
5.补充补充补充!
针对上面利用redis实现的分布式锁,由于性能问题和扩展性问题,结合公司内部使用情况,设计并且落地了最新的版本:
- 将锁续期的守护线程改为利用 时间轮+线程池 的方式实现
- 支持可重入与不可重入
- 采用 AOP+注解 的方式实现简单使用
架构图:
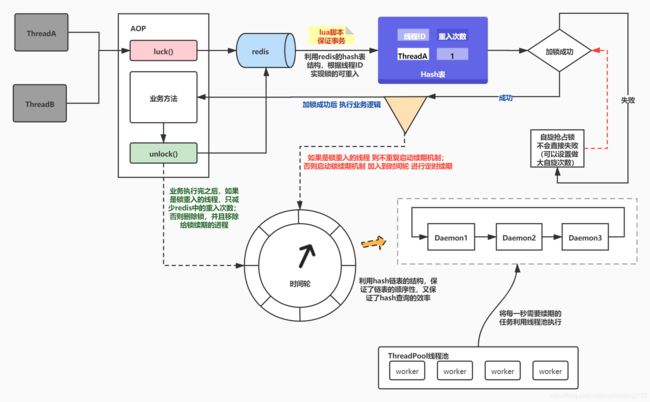
感兴趣的可以去文章最下面的github传送门。
三. 浅谈redisson实现分布式锁
按照我们上面利用redis实现分布式锁最后一个版本的思想,我们会发现要封装出来一个比较完善的分布式锁工具,其实还是要考虑和配置很多信息的 那么有没有市场上比较成熟的框架能帮我们实现呢 ,那就是redisson了 ,当然不仅仅只有redisson ,因为redisson是redis官方推出的 所以下面主要介绍一下它。
这里只是大致说一下如何使用redisson, 并不会对它的源码进行解读。
如果你认真 从文章开头读到了这里 ,那么其实你已经理解redisson的原理和设计了 。
先上一张架构图:
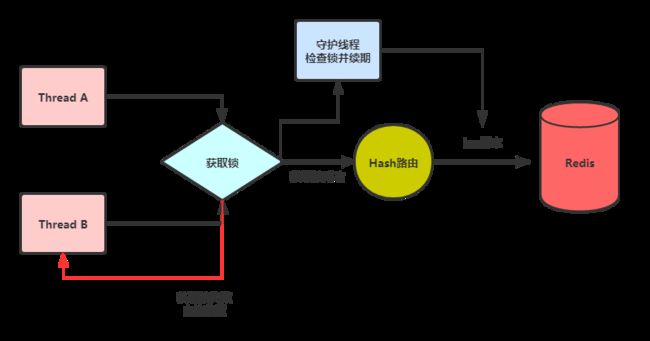
从这张图就能看出来,它的思想和我们前面利用redis一步步推到最后的实现思想几乎一样,是不是发现还有意外收获,不经意间就理解了redisson的设计原理和思想,接下来简单介绍一下在springboot中如何使用reidsson的分布式锁:
-
pom依赖
org.springframework.boot spring-boot-starter-data-redis org.redisson redisson-spring-boot-starter 3.10.6 -
yml配置
spring: # redis redis: host: localhost port: 6379 redisson: # 配置单点模式 config: classpath:redisson-single.yml -
redisson配置
# 单节点配置 singleServerConfig: # 连接空闲超时,单位:毫秒 idleConnectionTimeout: 10000 pingTimeout: 1000 # 连接超时,单位:毫秒 connectTimeout: 10000 # 命令等待超时,单位:毫秒 timeout: 3000 # 命令失败重试次数,如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。 # 如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。 retryAttempts: 3 # 命令重试发送时间间隔,单位:毫秒 retryInterval: 1500 # 重新连接时间间隔,单位:毫秒 reconnectionTimeout: 3000 # 执行失败最大次数 failedAttempts: 3 # 密码 password: null # 单个连接最大订阅数量 subscriptionsPerConnection: 5 # 客户端名称 clientName: null # 节点地址 address: redis://47.103.5.190:6379 # 发布和订阅连接的最小空闲连接数 subscriptionConnectionMinimumIdleSize: 1 # 发布和订阅连接池大小 subscriptionConnectionPoolSize: 50 # 最小空闲连接数 connectionMinimumIdleSize: 32 # 连接池大小 connectionPoolSize: 64 # 数据库编号 database: 0 # DNS监测时间间隔,单位:毫秒 dnsMonitoringInterval: 5000 # 线程池数量,默认值: 当前处理核数量 * 2 threads: 0 # Netty线程池数量,默认值: 当前处理核数量 * 2 nettyThreads: 0 # 编码 codec: !{} # 传输模式 transportMode : "NIO" -
java代码
@Component public class RedissonLockDemo implements ApplicationRunner { private final RedissonClient redissonClient; public RedissonLockDemo(RedissonClient redissonClient) { this.redissonClient = redissonClient; } @Override public void run(ApplicationArguments args) throws Exception { String lockKey = "lock"; // 利用redisson创建锁实例 RLock lock = redissonClient.getLock(lockKey); // 上锁 并设置过期时间为10秒 lock.lock(10, TimeUnit.SECONDS); try{ System.out.println("执行业务代码..."); }catch (Exception e){ e.printStackTrace(); }finally { // 释放锁 lock.unlock(); } }
1) 配置好redisson之后 直接使用RedissonClient创建指定锁的实例,并利用该实例进行上锁,设置过期时间和释放锁,使用起来很简单,特别是如果你理解了前面的内容,你应该立刻就知道他的里面的代码实现的思想和逻辑了。
2) redisson还提供了很多关于分布式锁的API 和其他的功能,强烈向小伙伴们推荐它。
四. 利用mysql实现分布式锁
1. 悲观锁
首先回顾一下什么是悲观锁,悲观锁,正如其名,具有强烈的独占和排他特性。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度。之所以叫做悲观锁,是因为这是一种对数据的修改抱有悲观态度的并发控制方式。我们一般认为数据被并发修改的概率比较大,所以需要在修改之前先加锁。
关于mysql中InnoDB的事务和锁机制,之前的篇章也介绍过,不太了解或者感兴趣的小伙伴也可以看一下 ↓↓↓
传送门: InnoDB引擎的事务与锁
相信从传送门回来的小伙伴对mysql中 InnoDB引擎的排他锁 已经熟悉了,我们在一个事务中,对指定的数据行进行select … for update 或者 在insert/update的时候 是会上排他锁的 ,而该事务结束之前 其他想要获取到该条数据的事务 是会阻塞的,我们就是利用这个机制实现分布式锁。
首先创建一张记录锁信息的表:
CREATE TABLE `lock` (
`lock_key` varchar(11) NOT NULL,
PRIMARY KEY (`lock_key`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- lock_key字段l作为锁的key。
下面是代码实现,环境是springboot:
@Component
public class MysqlLockServer implements ApplicationRunner{
/** 事务管理器顶层接口 PlatformTransactionManager */
private final PlatformTransactionManager platformTransactionManager;
/** jdbcTemplate */
private final JdbcTemplate jdbcTemplate;
/** 默认的事务定义 */
private final TransactionDefinition transactionDefinition = new DefaultTransactionDefinition();
public MysqlLockServer(PlatformTransactionManager platformTransactionManager, JdbcTemplate jdbcTemplate) {
this.platformTransactionManager = platformTransactionManager;
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void run(ApplicationArguments args) throws Exception {
TransactionStatus transaction = platformTransactionManager.getTransaction(transactionDefinition);
try{
try{
// 尝试插入key获取锁
jdbcTemplate.execute("insert into `lock`(`lock_key`) values ('lockKey');");
// 抢占锁
jdbcTemplate.execute("select 1 from `lock` where lock_key = 'lockKey' for update;");
}catch (Exception e){
// 如果抛出异常 说明该key已经存在 则直接去抢占锁
jdbcTemplate.execute("select 1 from `lock` where lock_key = 'lockKey' for update;");
}
// 业务代码
System.out.println("业务代码");
// 删除锁
jdbcTemplate.execute("delete from `lock` where lock_key = 'lockKey';");
// 提交事务
platformTransactionManager.commit(transaction);
}catch (Exception e){
e.printStackTrace();
// 回滚事务
platformTransactionManager.rollback(transaction);
}
}
}
思路解析:
1)因为我们在springboot环境,所以springboot会自动注入 事务管理器顶层接口PlatformTransactionManager 的Bean实例和JdbcTemplate实例。
2)首先尝试执行insert语句 将锁对应的key值插入到数据库,但是我们不能保证刚好 有他线程插入了该数据 ,但是因为我们加了 唯一索引 ,所以在插入的时候会抛出异常,所以我们需要在catch块中也做补偿即可,所以不管insert成功还是失败,都会执行select… for update 尝试获取锁。
3)若获取锁成功,则直接执行业务代码。
4)若获取锁失败,则会阻塞在select…for update的地方 等待获取到锁,再继续向下执行业务代码。
5)最后提交事务,并删除该key的数据,提交事务后,mysql的排他锁会自动释放,其他线程会从select…for update中被唤醒。
6)需要注意的是,要在最外层的catch块中添加事务回滚的逻辑,否则可能会出现死锁的问题。
悲观锁的缺点:
使用悲观锁会存在一定的性能和死锁问题,所以在使用悲观锁的时候 要考虑到死锁问题,而且上面实现的悲观锁,并不能支持锁的重入,所以 我们更倾向于使用乐观锁实现分布式锁,下面介绍基于mysql乐观锁的实现。
2. 乐观锁
乐观锁机制采取了更加宽松的加锁机制。乐观锁是相对悲观锁而言,也是为了避免业务处理时间过长等原因引起数据处理错误的一种机制,但乐观锁不会刻意使用数据库本身的锁机制,而是依据数据本身来保证数据的正确性。
首先创建一张记录锁信息的表:
CREATE TABLE `lock` (
`lock_key` varchar(11) NOT NULL,
`thread_id` bigint(22) DEFAULT NULL,
`entry_count` int(11) unsigned zerofill DEFAULT NULL,
PRIMARY KEY (`lock_key`) USING BTREE,
UNIQUE KEY `lock` (`thread_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-
lock_key字段l作为锁的key,
-
thread_id字段作为持有该锁的线程ID,
-
entry_count字段作为当前持有锁的线程的重入次数。
下面是代码实现,环境是springboot:
@Component
public class MysqlLockServer implements ApplicationRunner{
/** 事务管理器顶层接口 PlatformTransactionManager */
private final PlatformTransactionManager platformTransactionManager;
/** jdbcTemplate */
private final JdbcTemplate jdbcTemplate;
/** 默认的事务定义 */
private final TransactionDefinition transactionDefinition = new DefaultTransactionDefinition();
public MysqlLockServer(PlatformTransactionManager platformTransactionManager, JdbcTemplate jdbcTemplate) {
this.platformTransactionManager = platformTransactionManager;
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void run(ApplicationArguments args) throws Exception {
TransactionStatus transaction = platformTransactionManager.getTransaction(transactionDefinition);
try{
Long threadId = null;
String lockKey = "lockKey";
int result = 0;
try{
// 尝试插入key获取锁
threadId = Thread.currentThread().getId();
jdbcTemplate.execute("insert into lock(lock_key,thread_id) values (" + lockKey +","+ threadId +");");
// 抢占锁
lock(result,threadId);
}catch (Exception e){
// 如果抛出异常 说明该key已经存在 则直接去抢占锁
lock(result,threadId);
}
// 业务代码
System.out.println("业务代码");
// 释放锁 并不是直接释放 而是先减少重入次数
jdbcTemplate.execute("update lock set entry_count = entry_count - 1 where thread_id is not null and thread_id = " + threadId);
// 若不存在重入次数 则删除锁
jdbcTemplate.execute("update lock set thread_id = null where lock_key = "+ lockKey +" and entry_count <= 0;");
// 提交事务
platformTransactionManager.commit(transaction);
}catch (Exception e){
e.printStackTrace();
// 回滚事务
platformTransactionManager.rollback(transaction);
}
}
/**
* 自旋获取锁
*/
private void lock(int result,Long threadId){
while(result == 0){
result = jdbcTemplate.update("update lock set entry_count = entry_count + 1 where thread_id is not null and thread_id = " + threadId);
}
}
}
思路解析:
1)首先尝试执行insert语句 将锁对应的key值和线程ID插入到数据库,但是我们不能保证刚好 有他线程插入了该数据 ,不过因为我们加了 唯一索引 ,所以在插入的时候会抛出异常,所以我们需要在catch块中也做 补偿 ,所以不管insert成功还是失败,都会执行 lock() 方法尝试获取锁。
2)若获取锁成功,则直接执行业务代码。
3)若获取锁失败,则线程会阻塞在lock()方法中的自旋地方 等待获取到锁,再继续向下执行业务代码。
4)最后提交事务,并不会直接删除该key,而是先减少重入次数,然后再检查重入次数是否已经小于等于0了,如果是则删除该lock的数据,提交事务后,其他事务会在lock()方法的自旋中执行成功,然后执行业务代码。
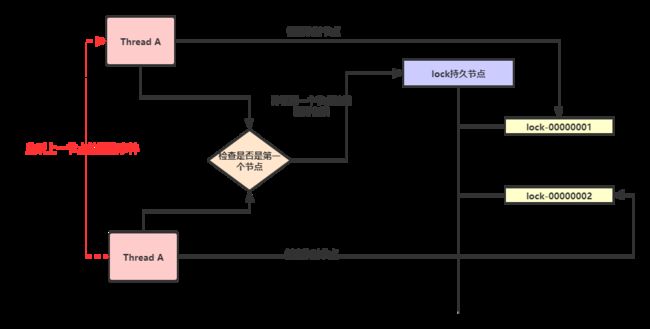
五. 基于zookeeper实现分布式锁
使用过zk的小伙伴应该都清楚,zk的功能很强大,不仅仅对于实现分布式锁,很多中间件都是利用zk的通讯机制实现服务注册和数据监听等功能,本章主要针对于使用zk实现分布式锁,先大致说一下使用zk实现分布式锁利用的特性:
- 节点的有序性(实现公平锁)
- 心跳机制(防止抢占锁的线程异常中断)
- 事件监听(通知获取锁)
- 持久节点(锁的唯一key)
- 临时节点(争抢同一个锁的线程)
思路:
1)首先创建一个该锁的持久节点,这个节点是一直在zk中,不会被删除。
2)当线程要争夺该锁,则在该锁的目录下创建一个临时节点,由于zk的特性,它会对所有临时节点排序,节点名称后面自动有一个数字编号,zk默认会对编号递增( + 1),即先来先到。
3)排在第一个节点的线程,就相当于获取到了锁,执行完业务数据之后,释放锁删除该节点。
4)每个抢夺锁的线程都会监听前一个节点的删除事件,若前一个结点释放锁删除节点之后,当前线程会重新检查是否已经排在第一了,如果是,则重复上一步操作。
5)如果线程在抢占锁的时候发生了异常,由于zk的心跳机制,发现该服务无法通信,则会删除该临时节点,防止出现死锁问题。
下面是代码demo:
# 配置信息:
zookeeper:
address: 127.0.0.1:2181
创建 zkClient:
@Configuration
public class ZookeeperConfig {
@Value("${zookeeper.address}")
private String connectString;
@Bean(name = "zkClient")
public ZooKeeper zkClient(){
ZooKeeper zooKeeper=null;
try {
final CountDownLatch countDownLatch = new CountDownLatch(1);
zooKeeper = new ZooKeeper(connectString, 10000, event -> {
if(Watcher.Event.KeeperState.SyncConnected==event.getState()){
countDownLatch.countDown();
}
});
countDownLatch.await();
System.out.println("zk connect success...");
// 创建锁的持久化节点
zooKeeper.create("/lock", "0".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}catch (Exception e){
e.printStackTrace();
}
return zooKeeper;
}
}
锁的细节实现:
@Component
public class ZookeeperLock implements ApplicationRunner {
// 前一个节点的临时节点
private String watchLock;
// 当前拥有的节点
private String currentLock;
// 阻塞等待锁的线程
private CountDownLatch countDownLatch = new CountDownLatch(1);
// 临时节点的前缀名 例:lock-00000001
private static final String LOCK_PRE ="lock-";
private final ZooKeeper zkClient;
public ZookeeperLock(ZooKeeper zkClient) {
this.zkClient = zkClient;
}
/**
* 抢占锁
*/
private boolean tryLock() throws KeeperException, InterruptedException {
if (currentLock == null){
synchronized (this){
if (currentLock == null){
// 创建临时节点
currentLock = zkClient.create("/lock/" + LOCK_PRE, "0".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(currentLock);
}
}
}
return isFirstNode();
}
/**
* 判断是否是第一个节点
*/
private boolean isFirstNode() throws KeeperException, InterruptedException {
List<String> childrenList = zkClient.getChildren("/lock", false);
TreeSet<String> sortedSet = new TreeSet<>();
for (String children : childrenList) {
sortedSet.add("/lock/" + children);
}
//获得当前节点中的最小的子节点;
String firstNode = sortedSet.first();
SortedSet<String> lessThenCurrentNode = sortedSet.headSet(currentLock);
//通过当前节点与最小节点进行比较 , 如果相等则获取所成功;
if (currentLock.equals(firstNode)) {
return true;
}
// 获得比当前节点更小的最后一个节点,进行监听
if (!lessThenCurrentNode.isEmpty()) {
watchLock = lessThenCurrentNode.last();
// 发起事件监听
waitLock();
// 阻塞等待前一个节点的删除事件 等待唤醒
countDownLatch.await();
//重新判断当前节点是否排在第一
isFirstNode();
}
return false;
}
/**
* 发起事件监听
*/
private void waitLock() throws KeeperException, InterruptedException {
zkClient.exists(watchLock, event -> {
// 捕获到前一个节点的删除事件
if (event.getType() == Watcher.Event.EventType.NodeDeleted){
// 唤醒阻塞等待的线程
countDownLatch.countDown();
}
});
}
/**
* 释放锁
*/
private void unLock() throws KeeperException, InterruptedException {
// 设置version为-1 强制删除
zkClient.delete(currentLock,-1);
}
@Override
public void run(ApplicationArguments args) throws Exception {
try{
if (tryLock()){
// 执行业务代码
System.out.println(1);
}
}catch (Exception e){
e.printStackTrace();
}finally {
unLock();
}
}
}
分析:通过代码我们会发现几个细节
1)zk并没有告诉我们当前节点是否是第一个节点,所以我们需要手写方法实现。
2)所有临时节点都会有一个事件监听,在事件未发生之前,会一直阻塞,所有可以考虑不采用阻塞的机制,而是采用自旋的方式判断自己是否已经是第一个节点了。
扩展: 上述的zk分布式锁的实现思想仍然是基于悲观锁的思想,那么zk能不能也采用 乐观锁 的机制实现呢,其实也是可以的,zk在创建节点的时候, 会为这个节点维护一份元数据信息 ,其中有一个名为dataversion的字段,就是表示这个节点的版本号,每一次修改,该版本号都递增,因此,我们如果想利用该信息实现乐观模式的分布式锁,具体的步骤这里就不过述了。
六. 总结
分布式锁是为了解决资源抢夺和幂等性的问题,那么我们想做的就是在一个时刻 只允许一个线程拥有资源,所以:
利用zk的临时文件特性,事件监听和心跳机制特点实现 公平性 分布式锁;
利用mysql中innoDB引擎的排他锁机制和乐观锁实现 非公平性 分布式锁;
利用redis的单线程(react模型),过期机制和内存效率等特点实现 非公平性 分布式锁;
从这些实现方案,可以总结出来,分布式锁的核心在于几个点:
- 锁的过期机制
- 锁不会被其他线程抢夺
- 不会出现死锁
- 阻塞等待或事件通知机制
- 锁的续期
- …
基于这些点,不管我们用什么工具去实现甚至自己手写去实现,只要考虑周全,其实都是没什么大问题的。
传送门:git源码