第二章-pytorch实现深度神经网络与训练
目录
1. 随机梯度下降算法
2.优化器
3. 损失函数
3.1 均方误差损失
3.2 交叉熵损失
4.防止过拟合
4.1 过拟合的概念
4.2 防止过拟合的方法
5. 网络参数初始化
5.1 网络参数初始化方法
5.2 参数初始化方法应用实例
1.针对某一层的权重进行初始化
2.针对一个网络的权重初始化方法
6.pytorch中定义网络的方式
6.1 数据准备
6.2 网络定义与训练方式1
6.3 网络定义与训练方式2
7. Pytorch模型保存和加载方法
1. 随机梯度下降算法
在深度学习网络中,通常需要设计一个模型的损失函数来约束训练过程,如针对分类问题可以使用交叉熵损失,针对回归问题可以使用均方根误差损失等。模型的训练并不是漫无目的的,而是朝着最小化损失函数的方向去训练,这时就会用到梯度下降类的算法。
梯度下降法(gradient descent)是一个一阶最优化算法,通常也称为最速下降法,是通过函数当前点对应梯度(或者是近似梯度)的反方向,使用规定步长距离进行迭代搜索,从而找到一个函数的局部极小值的算法,最好的情况是希望找到全局极小值。但是在使用梯度下降算法时,每次更新参数都需要使用所有的样本。如果对所有的样本均计算一次,当样本总量特别大时,对算法的速度影响非常大,所以就有了随机梯度下降( stochastic gradient descent,SGD)算法。它是对梯度下降法算法的一种改进,且每次只随机取一部分样本进行优化,样本的数量一般是2的整数次幂,取值范围是32~256,以保证计算精度的同时提升计算速度,是优化深度学习网络中最常用的一类算法。
SGD算法及其一些变种,是深度学习中应用最多的一类算法。在深度学习中SGD通常指小批随机梯度下降( mini-batch gradient descent )算法,其在训练过程中,通常会使用一个固定的学习率进行训练。即

式中,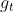 是第t步的梯度,n则是学习率,随机梯度下降算法在优化时,完全依赖于当前batch数据计算得到的梯度,而学习率
是第t步的梯度,n则是学习率,随机梯度下降算法在优化时,完全依赖于当前batch数据计算得到的梯度,而学习率 则是调整梯度影响大小的参数,通过控制学习率的大小,一定程度上可以控制网络的训练速度。
则是调整梯度影响大小的参数,通过控制学习率的大小,一定程度上可以控制网络的训练速度。
随机梯度下降虽然在大多数情况下都很有效,但其还存在一些缺点,如很难确定一个合适的学习率,而且所有的参数使用同样的学习率可能并不是最有效的方法。针对这种情况,可以采用变化学习率的训练方式,如控制网络在初期以大的学习率进行参数更新,后期以小的学习率进行参数更新。随机梯度下降的另一个缺点就是,其更容易收敛到局部最优解,而且当落入局部最优解后,很难跳出局部最优解的区域。
针对随机梯度下降算法的缺点,动量的思想被引入优化算法中。动量通过模拟物体运动时的惯性来更新网络中的参数,即更新时在一定程度上会考虑之前参数更新的方向,同时利用当前batch计算得到的梯度,将两者结合起来计算出最终参数需要更新的大小和方向。在优化时引入动量思想旨在加速学习,特别是面对小而连续且含有很多噪声的梯度。利用动量在一定程度上不仅增加了学习参数的稳定性,而且会更快地学习到收敛的参数。在引入动量后,网络的参数按照下面的方式更新:
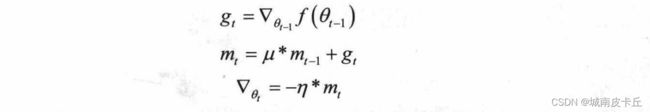
在上述公式中, 为当前动量的累加,
为当前动量的累加, 属于动量因子,用于调整上一步动量对参数更新时的重要程度。引人动量后,在网络更新初期,可利用上一次参数更新,此时下降方向一致,乘以较大的能够进行很好的加速。在网络更新后期,随着梯度逐渐趋近于0,在局部最小值来回震荡的时候,利用动量使得更新幅度增大,跳出局部最优解的陷阱。
属于动量因子,用于调整上一步动量对参数更新时的重要程度。引人动量后,在网络更新初期,可利用上一次参数更新,此时下降方向一致,乘以较大的能够进行很好的加速。在网络更新后期,随着梯度逐渐趋近于0,在局部最小值来回震荡的时候,利用动量使得更新幅度增大,跳出局部最优解的陷阱。
Nesterov项( Nesterov动量)是在梯度更新时做出的校正,避免参数更新太快,同时提高灵敏度。在动量中,之前累积的动量 并不会直接影响当前的梯度所以Nesterov的改进就是让之前的动量直接影响当前的动量,即
并不会直接影响当前的梯度所以Nesterov的改进就是让之前的动量直接影响当前的动量,即
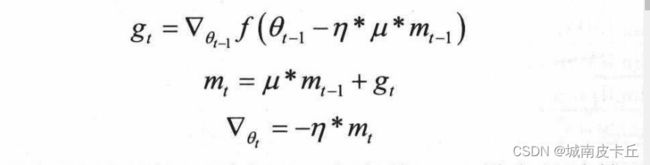
Nesterov动量和标准动量的区别在于,在当前batch梯度的计算上,Nesterov动量的梯度计算是在施加当前速度之后的梯度。所以,Nesterov动量可以看作是在标准动量方法上添加了一个校正因子,从而提升算法的更新性能。
在训练开始的时候,参数会与最终的最优值点距离较远,所以需要使用较大的学习率,经过几轮训练之后,则需要减小训练学习率。因此,在众多的优化算法中,不仅有通过改变更新时梯度方向和大小的算法,还有--些算法则是优化了学习率等参数的变化,如一系列自适应学习率的算法Adadelta、RMSProp及Adam等。
2.优化器
Pytorch中的optim模块提供了多种可直接使用的深度学习优化算法,无需人工实现随机梯度下降算法,直接调用即可。
| 类 | 算法名称 |
| torch.optim.Adadelta() | Adadelta算法 |
| torch.optim.Adagrad() | Adagrad算法 |
| torch.optim.Adam() | Adam算法 |
| torch.optim.Adamax() | Adamax算法 |
| torch.optim.ASGD() | 平均随机梯度下降算法 |
| torch.optim.LBFGS() | L-BFGS算法 |
| torch.optim.RMSprop() | RMSprop算法 |
| torch.optim.Rprop() | 弹性反向传播算法 |
| torch.optim.SGD() | 随机梯度下降算法 |
下面以Adam算法为例,介绍如何在pytorch中使用这些优化算法
import torch
torch.optim.Adam(params,lr=0.001,betas=(0.9,0.999),eps=1e-8)
"""
params:待优化参数的iterable或者定义了参数组的dict,通常为model.parameters()
lr:学习率,默认值为0.001
betas:用于计算梯度以及梯度平方的运行平均值的系数,默认为(0.9,0.999)
eps:为了增加计算数值的稳定性而加到分母中的项,默认为1e-8
weight_decay:权重惩罚(L2惩罚),默认值为0
"""
下面建立一个简单的测试网络,用于演示优化器的使用
import torch.nn as nn
class TestNet(nn.Module):
def __init__(self):
super(TestNet,self).__init__()
#定义隐藏层
self.hidden=nn.Sequential(nn.Linear(13,10),nn.ReLU())
#定义预测回归层
self.regression=nn.Linear(10,1)
# 定义网络层的向前传播路径
def forward(self,x):
x=self.hidden(x)
output=self.regression(x)
return output
#输出网络结构
testNet=TestNet()
"""
上面的程序我们已经建立了一个简单的神经网络,接下来我们定义优化器optim
"""
#第一种定义方式:为不同的层定义统一的学习率
optimizer=torch.optim.Adam(testNet.parameters(),lr=0.001)
#定义方式二:为不同的层定义不同的学习率
optimizer=torch.optim.Adam(
[{"params":testNet.hidden.parameters(),"lr":0.001},#隐藏层单独定义学习率
{"params":testNet.regression.parameters(),"lr":0.002}],#回归层单独定义学习率
lr=0.03#其他层定义统一的学习率
)
定义好优化器后,需要将optimizer.zero_grad()方法和optimizer.step()方法一起使用,对网络中的参数进行更新。其中optimizer.zero_grad)方法表示在进行反向传播之前,对参数的梯度进行清空; optimizer.step()方法表示在损失的反向传播loss.backward()方法计算出梯度之后,调用step()方法进行参数更新。如对数据集加载器dataset、深度网络testnet、优化器optimizer、损失函数loss_fn等,可使用下面的程序进行网络参数更新:
for input,target in dataset:
optimizer.zero_grad()#梯度清0
output=testNet(input)#计算预测值
loss=loss_fn(output,target)#计算损失
loss.backward()#损失后向传播
optimizer.step()#更新网络参数针对学习率,在pytorch中的torch,optim.lr_scheduler模块提供了优化器学习率调整方式,常用的几种如下:
(1)lr_scheduler.LambdaLR(optimizer,lr_lambda,last_epoch=-1):不同的参数组设置不同的学习调整策略,last_epoch参数用于设置何时开始调整学习率,last_epoch=-1表示学习率设置为初始值,在开始训练后准备调整学习率(last_epoch参数的设置)
(2)lr_scheduler.StepLR(optimizer,step_size,gamma=0.1,last_epoch=-1):等间隔调整学习率,学习率会每经过step_size指定的间隔调整为原来的gamma倍。这里的step_size所指的间隔是epoch的间隔。
(3)lr_scheduler.MultiStepLR(optimizer,milestones,gamma=0.1,last_epoch=-1):按照设定的间隔调整学习率。milestones参数通常使用一个列表来指定需要调整学习率的epoch数值,学习率会调整为原来的gamma倍。
(4)lr_scheduler.ExponentialLR(optimizer,gamma,last_epoch=-1):按照指数衰减调整学习率,学习率调整公式为:lr=lr*![]()
(5)lr_scheduler.CosineAnnealingLR(optimizer,T_max,eta_min=0,last_epoch=-1):以余弦函数为周期,并在每个周期最大值时调整学习率,T_max表示在T_max个epoch后重新设置学习率,eta_min表示最小学习率,即每个周期的最小学习率不会小于eta_min。学习率调整公式为:
![]()
其中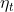 表示在t时刻的学习率,
表示在t时刻的学习率,![]() 为参数eta_min,
为参数eta_min, 为参数T_max。针对已经定义的学习率调整类,可以通过get_lr()方法获取当前的学习率。
为参数T_max。针对已经定义的学习率调整类,可以通过get_lr()方法获取当前的学习率。
3. 损失函数
深度学习的优化方法直接作用的对象是损失函数。在最优化、统计学、机器学习和深度学习等领域中经常能用到损失函数。损失函数就是用来表示预测与实际数据之间的差距程度。一个最优化问题的目标是将损失函数最小化,针对分类问题,直观的表现就是分类正确的样本越多越好。在回归问题中,直观的表现就是预测值与实际值误差越小越好。
pytorch中的nn模块提供了多种可直接使用的损失函数
| 类 | 算法名称 | 适用问题类型 |
| torch.nn.L1Loss() | 平均绝对值误差损失 | 回归 |
| torch.nn.MSELoss() | 均方误差损失 | 回归 |
| torch.nn.CrossEntropyLoss() | 交叉熵损失 | 多分类 |
| torch.nn.NLLLoss() | 负对数似然函数损失 | 多分类 |
| torch.nn.NLLLoss2d() | 图片负对数似然函数损失 | 图像分割 |
| torch.nn.KLDivLoss() | KL散度损失 | 回归 |
| torch.nn.BCELoss() | 二分类交叉熵损失 | 二分类 |
| torch.nn.MarginRankingLoss() | 评价相似度的损失 | |
| torch.nn.MultiLabelMarginLoss() | 多标签分类损失 | 多标签分类 |
| torch.nn.SmoothL1Loss() | 平滑的L1损失 | 回归 |
| torch.nn.SoftMarginLoss() | 多标签二分类问题的损失 | 多标签二分类 |
3.1 均方误差损失
torch.nn.MSELoss(size_average=None,reduce=None,reduction='mean')
其中参数的使用情况如下:
size_average:默认为True。计算的损失为每个batch的均值,否则为每个batch的和。
reduce:默认为True,此时计算的损失会根据size_average参数设定,是计算每个batch的均值或者和
reduction:通过指定参数取值为none、mean、sum来判断损失的计算公式。默认为mean,即计算的损失为每个batch的均值,如果设置为sum,则计算的损失为每个batch的和,如果设置为none,则表示不使用该参数。
对模型的预测输入x和目标y计算均方误差损失方式为:
![]()
如果reduction的取值为sum,则不除以N。
3.2 交叉熵损失
torch.nn.CrossEntropyLoss(weight=None,size_average=None,ignore_index=-100,reduce=None,reduction='mean')
交叉熵损失是将LogSoftMax和NLLLoss集成到一个类中,通常用于多分类问题,其参数的使用情况如下:
ignore_index:指定被忽略且对输入梯度没有贡献的目标值
size_average、reduce、reduction三个参数的使用情况同上。
weight:是1维的张量,包含n个元素,分别代表n类的权重,在训练样本不均衡时,非常有用,默认值为None。

4.防止过拟合
4.1 过拟合的概念
过拟合通常是指针对设计好的深度学习网络,在使用训练数据集时,在训练数据集上能够获得很高的识别精度(针对分类问题),或者很低的均方根误差(针对回归问题),但是把训练好的模型作用于测试集进行预测时,预测效果往往很不理想。
4.2 防止过拟合的方法
(1)增加数据量
更多的训练样本通常会使模型更加稳定,所以训练样本的增加不仅可以得到更有效的训练结果,也能在一定程度上防止模型过拟合,增强网络的泛化能力。但是如果训练样本有限,可以通过数据增强技术对现有的数据集进行扩充。数据增强则是通过已定的规则扩充数据,如在图像分类任务中,物体在图像中的位置、姿态、尺寸、图像的明暗等都会影响分类结果,所以可以通过平移、旋转、缩放等手段对数据进行扩充。
(2)合理的数据切分
针对现有的数据集,在训练深度学习网络时,可以将数据集进行切分为训练集、验证集和测试集(或者使用交叉验证的方法)
(3)正则化方法
正则化通常是在损失函数上添加对训练参数的惩罚范数,通过添加的范数惩罚对需要训练的参数进行约束,防止模型过拟合。常用的正则化参数有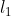 和
和 范数,范数 惩罚项的目的是将参数的绝对值最小化,范数惩罚项的目的是将参数的平方和最小化。在固定的深度学习网络中,使用范数会趋于使用更少的参数,而其他的参数都是0.从而增加网络稀疏性,防止模型过拟合。而利用范数进行约束则会选择更多的参数,但是这些参数都会接近于0,防止模型过拟合。使用正则化方法防止过拟合非常有效。
范数,范数 惩罚项的目的是将参数的绝对值最小化,范数惩罚项的目的是将参数的平方和最小化。在固定的深度学习网络中,使用范数会趋于使用更少的参数,而其他的参数都是0.从而增加网络稀疏性,防止模型过拟合。而利用范数进行约束则会选择更多的参数,但是这些参数都会接近于0,防止模型过拟合。使用正则化方法防止过拟合非常有效。
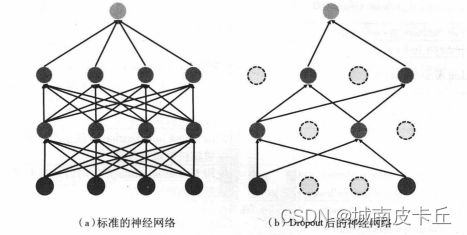
(4)Dropout
在深度学习网络中最常用的正则化技术是通过引入Dropout层,随机丢掉一些神经元,即在每个训练批次中,通过忽略一定百分比的神经元数量(通常是一半的神经元),减轻网络的过拟合现象。简单的来说,针对网络在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为这样训练得到的网络的鲁棒性会更强,不会过度依赖某些局部的特征。
(5)提前结束训练
防止网络过拟合的最直观的方式就是提前终止网络的训练,其通常将数据切分为训练集、验证集和测试集相结合。例如,当网络在验证集上的损失不在减小,或者精度不在增加时,即认为网络已经训练充分,应终止网络的继续训练。但是该操作可能会获得训练不充分的最终参数。
5. 网络参数初始化
5.1 网络参数初始化方法
在nn模块中的init模块下常用的参数初始化类,它们的功能如表:
| 方法(类) | 功能 |
| nn.init.uniform_(tensor,a=0.0,b=1.0) | 从均匀分布U(a,b)中生成值,填充输入的张量或变量 |
| nn.init.normal_(tensor,mean=0.0,std=1.0) | 从给定均值mean和标准差std的正态分布中生成值,填充输入的张量或变量 |
| nn.init.constant_(tensor,val) | 用val的值填充输入的张量或变量 |
| nn.init.eye_(tensor) | 用单位矩阵来填充输入二维张量或变量 |
| nn.init.dirac_(tensor) | 用Dirac delta函数来填充{3,4,5}维输入张量或变量。在卷积层尽可能多地保存输入通道特性 |
| nn.init.xavier_uniform_(tensor,gain=1.0) | 使用Glorot Initialization方法均匀分布生成值,生成随机数填充张量 |
| nn.init.xavier_normal_(tensor,gain=1.0) | 使用Glorot Initialization方法正态分布生成值,生成随机数填充张量 |
| nn.init.kaiming_uniform_(tensor,a=0,mode='fan_in',nonlinearity="leaky_relu") | 使用He initialization方法均匀分布生成值,生成随机数填充张量 |
| nn.init.kaiming_normal_(tensor,a=0,mode='fan_in',nonlinearity="leaky_relu") | 使用He initialization方法正态分布生成值,生成随机数填充张量 |
| nn.init.orthogonal_(tensor,gain=1) | 使用正交矩阵填充张量进行初始化 |
5.2 参数初始化方法应用实例
1.针对某一层的权重进行初始化
对某一层的权重进行初始化。以一个卷积层为例,先使用torch.nn.Conv2d()函数定义一个从3个特征映射到16个特征映射的卷积层,并且使用3*3的卷积核,然后使用标准正态分布的随机数方法进行初始化:
import torch
import matplotlib.pyplot as plt
#针对一个层的权重初始化方法
conv1=torch.nn.Conv2d(3,16,3)
#使用标准正态分布初始化权重
torch.manual_seed(12)#随机数初始化种子
torch.nn.init.normal(conv1.weight,mean=0,std=1)
#使用直方图可视化conv1.weight的分布情况
plt.figure(figsize=(8,6))
plt.hist(conv1.weight.data.numpy().reshape((-1,1)),bins=30)
plt.show()
"""
在上面的程序中使用conv1.weight可以获取conv1卷积层初始权重参数,
torch.manual_seed(12)操作则是定义一个随机数初始化种子,
便于torch.nn.init.normal()生成的随机数重复使用。
使用torch.nn.init.normal()函数时,第一个参数使用conv1.weight,
表示生成的随机数用来替换张量conv1.weight的原始数据,参数mean=O表示均值为0,
参数std=1表示标准差为1。在为conv1.weight重新初始化后,
可以将其中的数值分布可视化,得到的直方图如图3-4所示,生成的数据符合正态分布。
"""
#上面定义了conv1的卷积核权重,通过conv1.bias可以获取该层的偏置参数,
# 通过troch.nn.init.constant()函数使用0.1来初始化偏置
torch.nn.init.constant(conv1.bias,val=0.1)2.针对一个网络的权重初始化方法
对于多层网络每个层的参数初始化方法:
import torch
import torch.nn as nn
class TestNet(nn.Module):
def __init__(self):
super(TestNet,self).__init__()
self.conv1=nn.Conv2d(3,16,3)
self.hidden=nn.Sequential(
nn.Linear(100,100),
nn.ReLU(),
nn.Linear(100,50),
nn.ReLU()
)
self.cla=nn.Linear(50,10)
#定义网络的前向传播路径
def forward(self,x):
x=self.conv1(x)
x=x.view(x.shape[0],-1)
x=x.hidden(x)
output=self.cla(x)
return output
#输出我们的网络结构
testNet=TestNet()
print(testNet)
'''
在上述定义的网络结构中,一共有4个包含参数的层,分别是1个卷积层和3个全连接层。
如果想要对不同类型层的参数使用不同的方法进行初始化,可以先定义一个函数,
针对不同类型层使用不同初始化方法,自定义函数init_weights()
'''
#定义为网络中的每个层进行权重初始化的函数
def init_weights(m):
#如果是卷积层
if type(m) ==nn.Conv2d:
torch.nn.init.normal(m.weight,mean=0,std=0.5)
#如果是全连接层
if type(m) ==nn.Linear:
torch.nn.init.uniform(m.weight,a=-0.1,b=0.1)
m.bias.data.fill_(0.01)
"""
上面的程序中,如果层的type等于nn.Conv2d,则使用均值为0,
标准差为0.5的正态分布进行初始化权重weight;如果是全连接层,
则使用分布在(-0.1,0.1)之间的均匀分布进行初始化权重weight,
偏置bias使用0.01。
"""
"""在网络testNet中,对定义好的函数init_weights()使用apply方法即可,
testNet的初始化程序如下:
"""
torch.manual_seed(13)
testNet.apply(init_weights)
6.pytorch中定义网络的方式
在pytorch中提供了多种搭建网络的方法,下面以一个简单的全连接神经网络回归为例,介绍定义网络的过程,将会使用到Module和Sequential两种不同的网络定义方式。
import torch
import torch.nn as nn
from torch.optim import SGD
import torch.utils.data as Data #用于对数据的预处理
from sklearn.datasets import load_boston#用于导入数据
from sklearn.preprocessing import StandardScaler#用于对数据进行标准化
import pandas as pd
import matplotlib.pyplot as plt6.1 数据准备
下面以波士顿房价数据为例,分别使用Module和Sequential两种方式来定义一个简单的全连接神经网络,并用于网络模型的训练。在定义网络之前,先导入数据,并对数据进行预处理
#读取数据
boston_x,boston_y=load_boston(return_X_y=True)
"""
下面使用StandardScaler()对数据集中的自变量进行标准化处理
在标准化处理之后,需要将数据集转化为张量并设置一个数据加载器,方便模型的训练
"""
#数据标准化处理
ss=StandardScaler(with_mean=True,with_std=True)
boston_xs=ss.fit_transform(boston_x)
#将数据预处理为可以使用pytorch进行批量训练的形式
#训练集x转化为张量
train_x=torch.from_numpy(boston_xs.astype(np.float32))
#训练集y转化为张量
train_y=torch.from_numpy(boston_y.astype(np.float32))
#将训练集转化为张量之后,使用TensorDataset将x和y整合在一起
train_data=Data.TensorDataset(train_x,train_y)
#定义一个数据加载器,将训练数据集进行批量处理
train_loader=Data.DataLoader(
dataset=train_data,#使用的数据集
batch_size=128,#批处理样本大小
shuffle=True,#每次迭代前打乱数据
num_workers=1#使用两个进程
)
"""
上面的程序进行如下操作:
(1)使用StandardScaler()对数据集的自变量进行了标准化处理,
然后使用torch.from_numpy()函数将Numpy数组转化为张量。
(2)针对转化为张量数据的train_x和train_y使用Data.TensorDataset)函数
和Data.DataLoader()函数定义了一个数据加载器,方便使用随机梯度下降类算法优化,
每个batch包含128个样本
"""
6.2 网络定义与训练方式1
import torch
import torch.nn as nn
from torch.optim import SGD
import torch.utils.data as Data #用于对数据的预处理
from sklearn.datasets import load_boston#用于导入数据
from sklearn.preprocessing import StandardScaler#用于对数据进行标准化
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#读取数据
boston_x,boston_y=load_boston(return_X_y=True)
#数据标准化处理
ss=StandardScaler(with_mean=True,with_std=True)
boston_xs=ss.fit_transform(boston_x)
#将数据预处理为可以使用pytorch进行批量训练的形式
train_x=torch.from_numpy(boston_xs.astype(np.float32))
train_y=torch.from_numpy(boston_y.astype(np.float32))
train_data=Data.TensorDataset(train_x,train_y)
#定义一个数据加载器,将训练数据集进行批量处理
train_loader=Data.DataLoader(
dataset=train_data,#使用的数据集
batch_size=128,#批处理样本大小
shuffle=True,#每次迭代前打乱数据
num_workers=0#使用两个进程
)
#第一种定义网络的方式
class myNet(nn.Module):
def __init__(self):
super(myNet,self).__init__()
#定义第一个隐藏层
self.hidden1=nn.Linear(
in_features=13,#第一个隐藏层的输入,数据的特征数
out_features=10,#第一个隐藏层的输出,神经元的数目
bias=True#默认会有偏置
)
self.active1=nn.ReLU()
#定义第二个隐藏层
self.hidden2=nn.Linear(10,10)
self.active2=nn.ReLU()
#定义预测回归层
self.regression=nn.Linear(10,1)
#定义网络的前向传播
def forward(self,x):
x=self.hidden1(x)
x=self.active1(x)
x=self.hidden2(x)
x=self.active2(x)
output=self.regression(x)
return output
"""
上面的程序定义了一个类myNet,在继承了nn.Module类的基础上对其功能进行了定义。
在我们定义的类确定的函数中,包含两个部分,一部分定义了网络结构,
另一部分定义了网络结构的向前传播过程forward()函数。
在程序中网络结构包含3个使用nn.Linear()定义的全连接层和2个使用nn.ReLU()定义的激活函数层。
在定义forward()函数中,通过对输入x进行一系列的层计算,获取最后的输出output
对于定义好的网络结构,可以使用myNet()函数类得到网络结构,使用程序如下:
"""
mynet=myNet()
print(mynet)
#定义好网络之后,可以对已经准备好的数据集进行训练
#对回归模型mynet进行训练并输出损失函数的变化情况,定义优化器和损失函数
optimizer=SGD(mynet.parameters(),lr=0.001)
loss_func=nn.MSELoss()#最小均方误差
train_loss_all=[]#输出每个批次训练的损失函数
#进行训练,并输出每次迭代的损失函数
for epoch in range(30):
# 对训练数据的加载器进行迭代计算
for step,(b_x,b_y) in enumerate(train_loader):
output=mynet(b_x).flatten()#mynet在训练batch上的输出
train_loss=loss_func(output,b_y)#均方根误差
optimizer.zero_grad()#每个迭代步的梯度初始化为0
train_loss.backward()#损失的后向传播,计算梯度
optimizer.step()#使用梯度进行优化
train_loss_all.append(train_loss.item())
"""
在上面的程序中,我们使用SGD(随机梯度下降)优化方法对网络进行了优化,
需要优化的参数可以使用mynet.parameters()获得。在SGD()函数中,lr参数指定了优化时的学习率。
针对回归问题可以使用nn.MSELoss()函数(最小均方根误差)作为损失函数。
代码中使用两层for循环对网络进行参数训练,第一层for循环定义了对整个数据集训练的次数——30次,
第二层for循环利用数据加载器train_loader中的每一个batch对模型参数进行优化。
在优化训练的过程中,把每个batch的损失函数保存在train_loss_all列表中。
"""
plt.figure()
plt.plot(train_loss_all,"r-")
plt.title("Train loss per iterable")
plt.show()在网络训练完毕后,将train_loss_all进行可视化,每个batch上损失函数值的变化情况如下图所示:
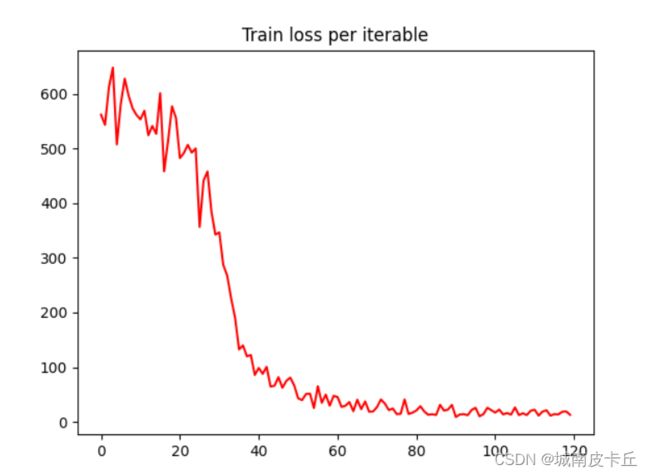
从上图可以发现损失函数的变化趋势是迅速下降,然后在一个小的范围内平稳波动。可以认为网络经过30个epoch,120次左右的迭代计算,损失函数大小达到了稳定。
6.3 网络定义与训练方式2
上上面的网络定义方式中,我们为每个层都指定了一个名称,在pytorch中提供了可以将多个功能层连接在一起的函数nn.Sequential(),大大方便了网络前向传播的定义。
import torch
import torch.nn as nn
from torch.optim import SGD
import torch.utils.data as Data
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
boston_x,boston_y=load_boston(return_X_y=True)
ss=StandardScaler(with_mean=True,with_std=True)
boston_xs=ss.fit_transform(boston_x)
train_x=torch.from_numpy(boston_xs.astype(np.float32))
train_y=torch.from_numpy(boston_y.astype(np.float32))
train_data=Data.TensorDataset(train_x,train_y)
train_loader=Data.DataLoader(
dataset=train_data,
batch_size=128,
shuffle=True,
num_workers=0
)
"""
使用nn.Sequential()定义网络
"""
class myNet2(nn.Module):
def __init__(self):
super(myNet2,self).__init__()
#定义隐藏层
self.hidden=nn.Sequential(
nn.Linear(13,10),
nn.ReLU(),
nn.Linear(10,10),
nn.ReLU()
)
#预测回归层
self.regression=nn.Linear(10,1)
#定义网络的前向传播算法
def forward(self,x):
x=self.hidden(x)
output=self.regression(x)
return output
mynet2=myNet2()
"""
由于nn.Sequential()函数的使用,上面的程序定义网络的结构和前向传播函数得到了简化,
网络中通过nn.Sequential()函数将两个nn.Linear()层和两个nn.ReLU()层统一打
包为self.hidden层,所以前向传播过程函数得到了简化
"""
#对回归模型mynet2进行训练并输出损失函数的变化情况,定义优化器和损失函数
optimizer=SGD(mynet2.parameters(),lr=0.001)
loss_func=nn.MSELoss()#最小均方根误差
train_loss_all=[]#输出每个批次训练的损失函数
#进行训练,并输出每次迭代的损失函数
for epoch in range(30):
for step,(b_x,b_y) in enumerate(train_loader):
output=mynet2(b_x).flatten()#mynet2在训练batch上的输出
train_loss=loss_func(output,b_y)#均方根误差
optimizer.zero_grad()#每个迭代步的初始化参数为0
train_loss.backward()#损失的后向传播,计算梯度
optimizer.step()#使用梯度进行优化
train_loss_all.append(train_loss.item())
# 对训练数据的加载器进行迭代计算
plt.figure()
plt.plot(train_loss_all,"r-")
plt.title("Train loss per iterable")
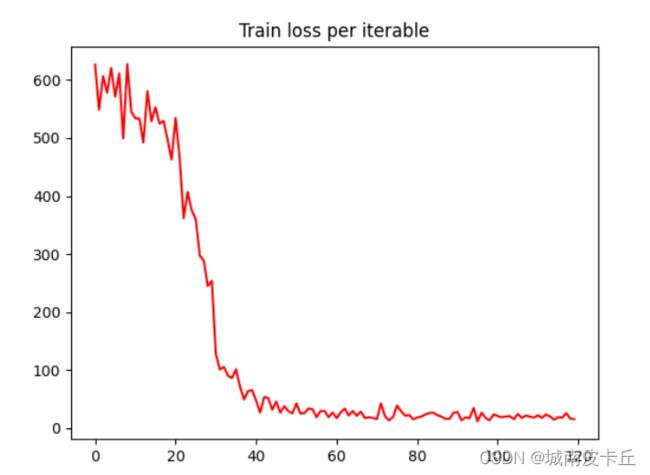
plt.show()
从下图中可以看出损失函数的变化趋势和mynet1相似,先是迅速下降,然后在一个小的范围内平稳波动。可以认为网络经过30个epoch和120次左右的迭代计算后,达到了稳定。
7. Pytorch模型保存和加载方法
对于已经训练好的模型,如何保存以及使用已经训练好的模型呢?
方式一:保存整个模型
#保存整个模型
torch.save(mynet2,"E:\\myModels\\mynet2.pkl")
#导入保存的模型
mynet2_load=torch.load("E:\\myModels\\mynet2.pkl")
"""
上面的程序是使用torch.save()函数将已经训练好的模型保存到指定文件夹下的mynet2.pkl文件。
在模型保存后,可以通过torch.load()函数,将指定的模型文件导入,
"""方式二:只保存模型的参数
torch.save(mynet2.state_dict(),"E:\\myModels\\mynet2_param.pkl")
mynet2_param_load=torch.load("E:\\myModels\\mynet2.pkl")
"""
上面的程序使用mynet2.state_dict()来获取mynet2网络中已经训练好的参数,
然后通过torch.save()将其保存。
同样可以使用torch.load()函数将保存好的参数导入
"""