CLIP-Event: Connecting Text and Images with Event Structures 论文解读
CLIP-Event: Connecting Text and Images with Event Structures

论文:2201.05078v1.pdf (arxiv.org)
代码:limanling/clip-event (github.com)
期刊/会议:CVPR 2022
摘要
视觉-语言(V+L)预训练模型通过理解图像和文本之间的对齐关系,在支持多媒体应用方面取得了巨大的成功。现有的视觉语言预训练模型主要侧重于理解图像中的对象或文本中的实体,它们往往忽略了事件级别及其论元结构的对齐。在这项工作中,我们提出了一个对比学习框架,以加强视觉-语言预训练模型来理解事件和相关的论元(参与者)角色。为此,我们利用文本信息抽取技术获取事件结构知识,并利用多个提示函数通过操纵事件结构来对比困难的负面描述。我们还设计了一个基于最优传输的事件图对齐损失来捕获事件论元结构。此外,我们收集了一个大型事件丰富的数据集(106,875张图像)用于预训练,这提供了一个更具挑战性的图像检索基准,以评估对复杂长句子的理解。实验表明,我们的零样本CLIP-Event在多媒体事件抽取中的论元抽取优于最先进的监督模型,在事件抽取中实现了超过5%的绝对F-score增益,以及在零样本设置下的各种下游任务上的显著改进。
1、简介
真实的多媒体应用不仅需要了解实体知识(即对象和对象类型),还需要了解带有事件论元结构的事件知识(即所涉及的实体及其角色)。例如,89%的图像包括当代多媒体新闻数据中的事件。此外,认识论元(参与者)对于理解新闻是至关重要的,因为如果论元扮演不同的角色,事件可能是矛盾的。例如,图1(a)和图1(b)都是同一个事件类型ATTACK,包含实体抗议者proster和警察police,但它们的论元角色不同,即在第一个事件中抗议者prosetr扮演的是袭击者ATTACKER的角色,在第二个事件中抗议者proster扮演的是目标TARGET的角色,警察则相反。同一组实体的不同论元角色导致两种攻击事件的区别。

然而,现有的视觉-语言预训练模型[5,13,19,28,34,44]侧重于对图像或实体的理解,忽略了事件语义和结构。结果,在需要理解动词的情况下,出现了明显的错误。因此,我们专注于将事件结构知识整合到视觉语言预训练中。以前的工作主要是将视觉事件表示为带有subject和object的动词[14,20,33,36,39,46]。但是,事件包含结构化知识,每个事件被分配到表示一组同义动词的事件类型。每个论元都以文本或图像为基础,并与参与者所扮演的论元角色相关联。如图2所示,carry事件类型为TRANSPORT,protester为AGENT,injured man为ENTITY,stretcher为INSTRUMENT。

从新闻图像中抽取事件结构的研究很少[18,27],对下游应用所需的事件知识获取支持有限。因此,我们提出利用在自然语言处理中已得到充分研究的文本信息抽取技术,从字幕中自动抽取事件结构。字幕基本上指的是与新闻数据中的图像相同的事件,例如,87%的字幕描述了图像中的事件。因此,我们设计了一个自监督的对比学习框架CLIP-Event,利用字幕中丰富的事件知识作为远程监督来解释相关图像中的事件,有效地跨模态传递事件知识。
此外,为了训练健壮的表示,在仅使用图像的情况下,能够区分事件类型(例如TRANSPORT和ARREST)和论元角色(例如TRANSPORT和ARREST)之间的细微差异。我们提出通过操纵事件结构来生成hard negative,我们使用一组广泛的事件提示函数(event prompt function)将正确和操纵的事件结构转换为文本描述。根据最先进的视觉语言预训练模型CLIP[28],我们优化了图像和事件感知文本描述之间的对比学习目标。
此外,为了传递论元结构的知识,我们显式地在视觉和文本中构造由事件类型和论元角色组成的事件图。我们在两个事件图之间引入细粒度对齐,将图像中的对象与相应的文本实体及其论元角色对齐。我们使用最优传输来鼓励基于两个图的结构的全局对齐,这使得模型能够捕获论元之间的交互。例如,具有相似视觉特征的物体趋向于对齐相同的论元角色。
我们的评估主要集中在零样本设置,因为这对于理解现实应用中新的或以前未知的事件至关重要。传统的基于有限预定义事件本体的方法不适用于处理开放世界事件。另一方面,我们的预训练模型能够使用任何不可见类型和论元角色的自然语言描述来识别事件结构,从而实现零样本多媒体事件抽取。
对多媒体事件抽取[18]和Grounded Situation Recognition[27]的评估表明,在零样本设置和监督设置下,CLIP-Event显著优于最先进的视觉-语言预训练模型。并且在图像检索[8]、视觉常识推理[43]、视觉常识推理时间[26]等零样本设置下的各种下游任务中都取得了显著的成绩。
本文的贡献:
- 我们在视觉语言预训练中首次利用了视觉事件和论元结构信息。
- 通过对比负样本事件描述的,我们引入了一个新的框架,负面事件描述是由各种提示函数以hard negative事件和论元为条件生成的。
- 我们提出基于最优传输的事件图对齐,将先前的图像或对象对齐扩展到事件结构感知对齐。
- 我们发布了一个包含106,875张图像的事件丰富图像标题数据集,包括抽取的事件知识,它可以作为一个具有挑战性的图像检索基准,用于评估在现实应用中理解复杂和长句子的能力。
2、我们的方法
我们的目标是将事件结构知识整合到视觉语言预训练中。下面我们将讨论关于模型设计的两个主要问题:(1)如何获得结构事件知识?(2)事件的语义和结构如何编码?
2.1 事件结构知识抽取
文本视觉知识抽取:我们使用最先进的文本信息抽取系统[17,21]抽取了187种类型的事件,涵盖了广泛的有新闻价值的事件。对于图像,我们应用在Open Images[16]上训练的Faster R-CNN[29]来检测对象。
主事件检测:当字幕中有多个事件时,图像通常描述标题的主要事件。使用预训练的CLIP模型[28],我们将主事件检测为更接近依赖解析树[25]的根,具有更多论元,更高的事件类型频率,触发词与图像之间的相似性更高的事件。我们根据这些标准对事件进行排名,并进行多数投票。例如,在图2中,字幕中有两个事件carry和clashes。我们选择carry作为主要事件,因为它是依赖树的根,它有三个论元,而且与图像的相似度更高。
2.2 事件结构驱动的负采样
为了迫使文本和视觉编码器学习关于事件类型和论元角色的健壮特性,我们设计了以下策略来生成具有挑战性的负样本。
负事件抽样。我们在预训练图像字幕数据集上计算最先进的视觉语言预训练模型CLIP[28]的事件类型分类器的混淆矩阵。分类器根据事件类型标签 ϕ v ∈ Φ V ϕ_v∈Φ_V ϕv∈ΦV(例如TRANSPORT)与输入图像 i i i的相似度得分,选择最佳的作为预测事件类型 ϕ v ∗ \phi_v^* ϕv∗。
ϕ v ∗ = arg max ϕ v ∈ Φ V ϕ v T ⋅ i \phi_v^*=\arg \max_{\phi_v \in \Phi_V} \phi_v^T \cdot i ϕv∗=argϕv∈ΦVmaxϕvT⋅i
其中 ϕ v , i \phi_v,i ϕv,i分别代表图2中来自文本和视觉编码器的表示,我们按照CLIP使用文本和视觉Transformer。混淆矩阵是通过比较预测的事件类型与图像的主要事件类型来计算的。因此,负样本事件类型是图像事件类型的难点,即视觉特征与主事件类型模糊的事件类型。例如,在图中,由于其视觉特征与TRANSPORT相似,因此将ARREST作为负样本事件类型进行采样。
负论元采样:对于论元角色,由于每个事件根据定义都有多个论元,因此我们通过执行论元角色序列的右转来操作论元的顺序。具体来说,我们首先根据本体定义对现有的论元角色进行排序,例如图2中的“AGENT, ENTITY, INSTRUMENT”。之后,我们右旋论元角色序列一步,得到“INSTRUMENT, AGENT, ENTITY”。因此,每个论元都被重新分配给一个被操纵的角色,例如,injured man,第二个论元被从ENTITY操纵到AGENT。如果事件只有一个论元,我们根据文本论元抽取系统[21]的论元混淆矩阵采样一个负角色。
描述生成:为了使用Text Encoder对正、负事件结构进行编码,我们设计了多个提示函数,如表1所示:(1)Single Template-based prompt对一个句子中的所有论元进行编码。(2)Composed Template-based Prompt对每个论元使用一个短句。(3)Continuous Prompt应用可学习的前置嵌入[ X i X_i Xi] (4)Caption Editing仅通过更改事件触发词或切换论元,使信息损失最小。(5)GPT-3 base Prompt基于事件结构生成语义一致的自然语言描述。我们使用GPT-3[9],并使用五个手动事件描述示例作为少样本提示[9]来控制生成。GPT-3的输入是示例事件([ex_v])与论元([ex_a])、示例描述([ex_desp])和目标事件([input_v])与论元([input_a])的连接。GPT-3的输出是目标描述([output_desp])。与基于模板的方法相比,这种描述更加自然。

2.3 通过最优传输的事件图对齐
每个事件及其论元可以被组织成图,如图2所示,其中中心节点是事件节点(三角形节点),它通过论元角色连接到实体(圆形节点)。编码事件图结构使模型能够捕获事件和论元之间的交互。例如,injured man应该与被运输的ENTITY对齐,而不是与AGENT对齐。
图像水平对齐。我们计算文本 t t t和图像 i i i之间的余弦相似度 s ( t , i ) s(t, i) s(t,i)和距离 d ( t , i ) d(t, i) d(t,i):
s ( t , i ) = c o s ( t , i ) , d ( t , i ) = c ( t , i ) s(t,i)=cos(t,i),d(t,i)=c(t,i) s(t,i)=cos(t,i),d(t,i)=c(t,i)
c ( ⋅ , ⋅ ) = 1 − c o s ( ⋅ , ⋅ ) c(\cdot,\cdot)=1-cos(\cdot,\cdot) c(⋅,⋅)=1−cos(⋅,⋅)是余弦距离函数, t , i t,i t,i分别来自文本和图像Transformer模型。


实体水平对齐。文本实体 e e e与图像对象 o o o之间的余弦距离同时考虑了提及相似度和类型相似度。
d ( e , o ) = c ( t e , i o ) + c ( ϕ e , ϕ o ) d(e,o)=c(t_e,i_o)+c(\phi_e,\phi_o) d(e,o)=c(te,io)+c(ϕe,ϕo)
t e t_e te是实体 e e e的文本提及, t e \mathbf{t}_e te是实体 e e e在句子中的上下文嵌入。我们使用[28]后面的Text Transformer对句子进行编码,并对实体提及 t e t_e te中的标记应用平均池化。类似地, i o i_o io是对象 o o o的包围框, i o \mathbf{i}_o io是它在图像上上下文化的嵌入,基于包围框中覆盖的补丁的Vision Transformer表示的平均池化。 ϕ e ϕ_e ϕe和 ϕ o ϕ_o ϕo是文本tramsformer编码的类型表示。例如,对于 e = e = e=injured man, ϕ e = ϕ_e = ϕe= PERSON;对于 o = o = o=担架图, ϕ o = ϕ_o = ϕo= PERSON。因此,上述实体与对象之间的距离为:
d ( e , o ) = c ( injured man,担架图 ) + c ( PERSON,PERSON ) d(e,o)=c(\text{injured man,担架图})+c(\text{PERSON,PERSON}) d(e,o)=c(injured man,担架图)+c(PERSON,PERSON)
事件水平对齐。为了获得基于两个图的结构的全局对齐评分,我们使用最优传输[32]来得到文本事件图 G t G_t Gt和图像事件图 G i G_i Gi之间的最小距离 d ( G t , G i ) d(G_t, G_i) d(Gt,Gi),
d ( G t , G i ) = min T T ⊙ C d(G_t,G_i)=\min_T T \odot C d(Gt,Gi)=TminT⊙C
其中 ⊙ ⊙ ⊙代表Hadamard product。 T ∈ R + n × m T∈\mathbb{R}^{n×m}_+ T∈R+n×m表示传输计划,学会了优化两个图之间的软节点对齐。 n n n和 m m m分别为 G t G_t Gt和 G i G_i Gi中的节点数。即文本图 G t G_t Gt中的每个节点都可以被转移到图像图 G i G_i Gi中具有不同权值的多个节点。
C C C是代价矩阵(cost matrix)。我们在事件节点和论元节点之间定义代价。对于事件节点,代价是图像 i i i和触发词 v v v之间的余弦距离
C ( v , i ) = c ( t v , i ) + c ( ϕ v , i ) C(v,i)=c(t_v,i)+c(\phi_v,i) C(v,i)=c(tv,i)+c(ϕv,i)
在图2中, v = carry , ϕ v = TRANSPORT v=\text{carry},\phi_v=\text{TRANSPORT} v=carry,ϕv=TRANSPORT。
C ( v , i ) = c ( carry,完整图 ) + c ( TRANSPORT,完整图 ) C(v,i)=c(\text{carry,完整图})+c(\text{TRANSPORT,完整图}) C(v,i)=c(carry,完整图)+c(TRANSPORT,完整图)
t v t_v tv是文本Transformer的上下文表征。
每个论元⟨ a , e a, e a,e⟩和每个边界框 o o o之间的代价基于对象 o o o与论元角色 a a a和文本实体 e e e的相似性。
C ( < a , e > , o ) = d ( a , o ) + d ( e , o ) = c ( t a , i o ) + c ( t e , i o ) + c ( ϕ e , ϕ o ) C(
t a t_a ta是论元描述,例如 a = ENTITY , e = injured man a=\text{ENTITY},e=\text{injured man} a=ENTITY,e=injured man,
C ( < a , e > , o ) = c ( ENTITY of TRANSPORT,受伤人图 ) + c ( injured man,受伤人图 ) + c ( PERSON,PERSON ) C(
求解 d ( G t , G i ) = min T T ⊙ C d(G_t, G_i) = \min_T T⊙C d(Gt,Gi)=minTT⊙C的最优 T ∈ R + n × m T∈\mathbb{R}^{n×m}_+ T∈R+n×m可以用可微分Sinkhorn-Knopp算法[6,32]来逼近,
T = d i a g ( p ) exp ( − C / γ ) d i a g ( q ) T=diag(p)\exp(-C/\gamma) diag(q) T=diag(p)exp(−C/γ)diag(q)
p ∈ R + n × 1 , q ∈ R + m × 1 p \in \mathbb{R}_+^{n \times 1},q \in \mathbb{R}_+^{m \times 1} p∈R+n×1,q∈R+m×1。从任意正向量 q 0 q_0 q0开始执行以下迭代:
for i=0,1,2,.... util convergence , p i + 1 = 1 ⊘ ( K q i ) , q i + 1 = 1 ⊘ ( K p i + 1 ) \text{for i=0,1,2,.... util convergence},\\ p^{i+1}=\mathbf{1} \oslash(Kq^i),q^{i+1}=\mathbf{1} \oslash(Kp^{i+1}) for i=0,1,2,.... util convergence,pi+1=1⊘(Kqi),qi+1=1⊘(Kpi+1)
⊘ \oslash ⊘指的是逐元素分解。 K = exp ( − C / γ ) K=\exp(-C/\gamma) K=exp(−C/γ)。
T k = d i a g ( p k ) K d i a g ( q k ) T^k =diag(p^k) K diag(q^k) Tk=diag(pk)Kdiag(qk)
2.4 对比学习目标
我们优化图像 i i i和正面描述 t + t^+ t+之间的余弦相似度,使其接近1,而负面描述 t − t^− t−则接近0,
L 1 = ∑ < t , i > D K L ( s ( t , i ) ∥ 1 t ∈ T + ) L_1=\sum_{
D K L ( ⋅ ∣ ∣ ⋅ ) , 1 D_{KL}(\cdot||\cdot),\mathbb{1} DKL(⋅∣∣⋅),1分别是KL散度和显示描述是否为正面描述的指示器函数。它使我们的模型能够处理任意数量的正面和负面描述。此外,我们将其他图像的描述与负面描述包括在同一批中。
我们还最小化两个事件图之间的距离,
L 2 = ∑ < t , i > d ( G t , G i ) L_2 =\sum_{
对事件和论元描述的对比学习和事件图对齐进行了联合优化:
L = λ 1 L 1 + λ 2 L 2 L=\lambda_1L_1 + \lambda_2L_2 L=λ1L1+λ2L2
λ 1 = 1 , λ 2 = 1 \lambda_1=1,\lambda_2=1 λ1=1,λ2=1在本文中。
3、任务评估
3.1 多模态事件抽取(M2E2)
任务设置。多媒体事件抽取[18]旨在(1)将图像分为8种事件类型,(2)将论元角色定位为图像中的包围框。我们选择这个任务作为对事件结构理解的直接评估。
我们的方法。Zero-shot设置:我们评估模型处理开放词汇表事件的能力,以满足现实世界应用程序的要求。此外,零样本评估提供了在预训练期间事件知识编码的有效性的直接比较。如图4a所示,我们选择与图像相似度评分 s ( i , t ) s(i, t) s(i,t)最高的事件类型,对于每个包围框,我们对所选事件类型的候选论元角色进行排序。有监督的设置:我们包括有监督的设置,以证明在直接监督的情况下,模型架构在编码事件知识方面的有效性,详细信息见附录A.3。
评价指标。我们遵循[18]使用F-scores来评估事件类型和论元抽取。
3.2 Grounded Situation Recognition (GSR)
任务设置。Grounded Situation Recognition[27]从504个动词中选择一个事件类型,并预测每个论元角色的实体名称和边界框。
我们的方法。实现类似于图4a中的M2E2,详细信息见附录A.4。
评价指标。我们按照附录中详细的[27]执行。
3.3 图像检索
任务设置。图像检索为每个给定的标题对图像进行排序,这是对图像-文本对齐的直接评估。
我们的方法。我们执行图像和文本 d ( i , t ) d(i, t) d(i,t)的对齐,以及跨两个模态 d ( G i , G t ) d(G_i, G_t) d(Gi,Gt)的事件图。
评价指标。我们使用常规的图像检索措施,包括Recall@1, Recall@5和Recall@10。
3.4 视觉常识推理(VCR)
任务设置。给定一个问题,该任务包含两个子任务:(1)从四个选项中预测答案;(2)理论基础预测,从四个选项来支持答案。
我们的方法。为了评估预训练模型的质量,如图4b所示,我们采用仅依靠图像-文本对齐的零样本设置进行公平的比较,详细信息见附录a .5。
评价指标。我们使用F-scores来评估答案预测和基本原理预测,遵循[43]。
3.5 时间中的视觉常识推理
任务设置。给定一个图像和它的参与者所涉及的事件,VisualCOMET[26]旨在生成参与者的“意图”,详见附录A.6。
我们的方法。如图4b所示,我们根据图像-文本相似度对候选意图进行排序(附录A.6)。
评价指标。在对最先进的模型[26]进行perplexity评价后,我们采用Accuracy@50。
4、实验
4.1 预训练设置
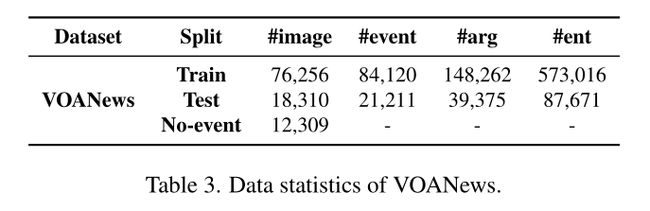
一个新的数据集:我们从新闻网站[1]收集了106,875个富含事件的图片说明。它提供了一个新的具有挑战性的图像检索基准,其中每个句子可能包含多个具有复杂语言结构的事件。平均标题长度为28.3个token,而Flickr30k为13.4个,MSCOCO为11.3个。数据统计显示在表3中。
4.2 Baseline
最先进的多媒体预训练模型。我们通过运行“ViT-B/32”的公开版本与CLIP[28]进行比较,并在接下来的实验中报告分数,以便进行公平的比较。我们进一步使用表3中相同数据集中的图像标题预训练CLIP,以便在数据资源方面进行公平的比较。
最先进的事件抽取模型。目前最先进的事件抽取模型,如wase[18]用于多媒体事件抽取任务,JSL[27]用于接地情况识别任务。
消融研究:CLIP-Event w/o Optimal Transport被包括在内,作为我们模型的一个变体,其中我们删除了事件图之间的对齐。它只在对比损耗L1上训练。
消融研究:每个提示函数仅在训练期间使用,目的是比较其有效性。
4.3 事件抽取任务分析
在零样本设置下,我们在M2E2上获得了5.5%的事件抽取绝对F score增益,在论元抽取上获得33.3%的相对增益,如表4所示。
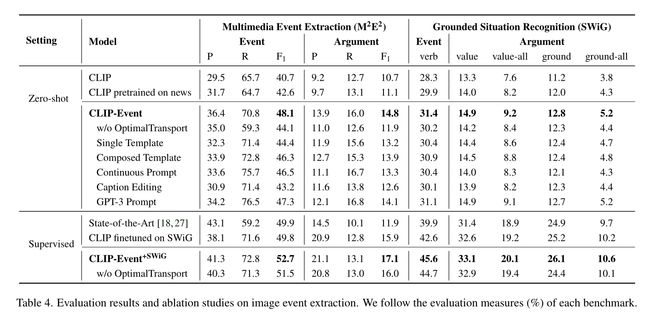
在结构化事件知识的帮助下,对新闻数据进行预训练所获得的收益显著放大。例如,在新闻上预训练的CLIP比在M2E2上的vanilla CLIP提高了1.9%。我们的CLIP-Event将增益显著提高到3.89倍。
Zero-shot CLIP-Event在M2E2数据集上的论元抽取上优于最先进的弱监督模型,表明所提出的最优传输对齐有效地捕获了参数结构,这是以前的视觉语言预训练模型无法实现的。
对于论元本地化,CLIP-Event在M2E2上获得了比SWiG更高的增益,这是因为SWiG使用了不同的论元包围框接地策略。SWiG将扮演相同角色的所有对象合并到一个大的包围框中。如图5b所示,我们的方法首先检测每个对象的论元角色,然后将具有相同角色的对象合并到一个大的包围框中。M2E2允许具有相同论元角色的多个对象,这与我们使用与论元角色对齐的对象的方法是一致的,如图5a所示。

4.4 在下游任务的分析
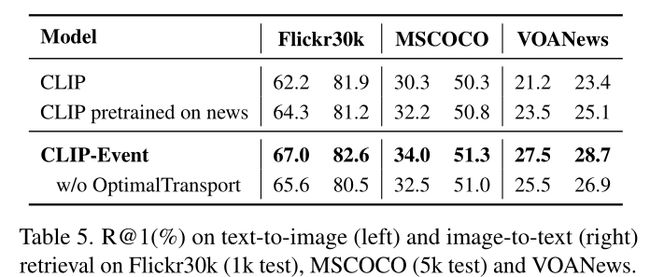
图像检索:1、如图6所示,与Flickr30k和MSCOCO相比,VOANews在字幕中出现的事件较多,句子结构难度更大。在VOANews上的改进比在Flickr30k和MSCOCO上的改进要高得多,这证明了我们的模型能够处理长句子,特别是那些有很多事件的句子。2、下游任务受益于细粒度事件图对齐。例如,在图6中,物体与调查人员和毁坏的汽车之间的强对齐使图像成功地获得更高的排名。

VCR。(1)在VCR上,rationale F1的改进大于answer F1。原理预测更具挑战性,因为它涉及场景的细节,而细粒度对齐很好地捕获了这些细节。(2)事件知识对下游任务尤其有益。在图7中,只有正确答案与输入图像的事件类型相对应。

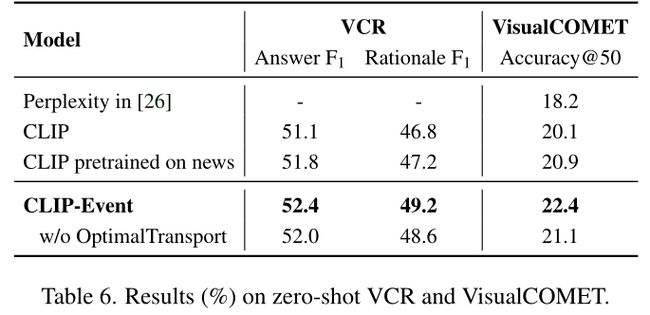
VisualCOMET。我们将我们的结果与最先进的模型的复杂性进行比较,这也是基于检索的。基线是使用VisualCOMET的训练集进行训练的,但我们的模型是一个无监督模型,它达到了优越的性能,表明我们的模型能够理解图像中的事件。
5、相关工作
视觉语言预训练。近年来,基于Transformer架构[35]的视觉-语言预训练模型[5,12,13,15,19,24,28,34,37,44,45]取得了巨大成功。图像结构已被证明对预训练模型有用,例如场景图[41]。然而,事件结构知识在预训练模型中没有很好地捕获,在与动词理解相关的任务中表现出不足[11]。我们是第一个对结构化事件知识进行编码以增强视觉-语言预训练的人。
视觉事件理解。以前的工作将视觉事件简化为动词,使用subject-verb-object三元组[3,7,10,14,20,23,31,33,36,39,46]。情景识别[27,40]旨在检测论元角色和多媒体事件抽取[18]将动词分类为事件类型。然而,它们有限的事件本体无法在实际应用程序中处理openworld事件。相比之下,我们提出的预训练模型支持零样本事件抽取,并在其他需要图像事件推理的下游任务上表现良好。
跨媒体对齐。现有的预训练模型[4,5,19,34,44]在不考虑文本和图像结构的情况下最大化了两种模式的对齐。提出了类似于文本语言结构的图像结构[18,42]。然而,复杂的语言结构和图像结构之间存在着差距。我们建议使用文本事件图结构来填补空白,并在两个事件图上计算全局对齐。
6、总结和未来工作
本文提出将结构事件知识整合到视觉-语言预训练中。我们通过从字幕中自动抽取事件知识和通过对比学习监督图像事件结构理解来实现事件知识的跨媒体迁移。我们通过基于混淆矩阵操作事件结构来生成hard negative,并设计事件提示函数将事件编码成自然的句子。为了传递论元结构知识,我们提出了通过最优传输的事件图对齐损失,以获得基于论元结构的全局对齐。它在零样本设置下的事件抽取和下游任务上优于最先进的视觉语言预训练模型。在未来,我们将把这种能力扩展到视频,以使用论元跟踪来理解事件的演变。