面試就业题库-06
文章目录
- 1. java基础(1)
- 2. javaweb(1)
- 3. ssm+springboot+springCloud(1.5)
-
- 9.1 Spring Cloud 你们在项目中如何使用?
- 9.2 Spring Cloud 的各个组件说明
-
- 9.2.1 Eureka组件: SpringCloud的服务发现和注册的组件(作用阿里的Nacos)
- 9.2.2 Ribbon:负载均衡客户端,需要结合RestTemplate(HttpClient)进行服务的调用
- 9.2.3 Feign:Feign默认集成了Ribbon,用它来管理服务(管理controller配置的路径)
- 9.2.4 Hystrix : 熔断限流的组件
- 9.2.5 GateWay :网关组件
- 9.3 Ribbon和Feign区别
- 9.4 Spring Cloud 注意的细节
- 9.5 springCloud版本号更新的方式
- 9.6 SpringCloud和SpringBoot有版本兼容的
- 4. 企业开发的项目: 技术说明(1.5)
-
- 4.1 针对电商项目来说: SPU和SKU是什么, 用来表示什么?
- 4.2 前后端分离
- 4.3 Shiro和SpringSecurity权限校验框架的区别
- 4.4 分布式缓存redis在项目中如何实现高可用
-
- 4.4.1 项目中哪些地方用到redis
- 4.4.2 介绍以下redis的数据类型以及应用场景
- 4.4.3 描述以下redis的持久化机制
- 4.4.4 描述以下redis的两种持久化机制的区别
- 4.4.5 AOF持久化文件越来越大怎么办
- 4.4.6 redis为什么被称为单线程,以及为什么单线程效率还这么高
- 4.4.7 Redis为什么这么快
- 4.4.8 Redis操作中常见的问题
- 4.4.9 如何保证redis在高并发下的高可用?
- 4.4.10 如何保证Redis缓存中: 热门商品的同步?
- 4.5 常用的消息中间件有那些,底层都用什么协议,有什么区别
- 4.6 常用的高并发解决方案有那些
- 4.7 如何实现CAS单点登录
- 4.8 用户恶意频繁添加购物车, 添加购物车跨域问题, cookie禁用怎么办等常见的购物车问题如何解决(面试官: 项目中遇到了那些问题
- 4.9 怎么实现微信支付接入
- 4.10 为什么对数据库分库分表?
- 4.11 如何处理超时无效订单
- 4.12 如何完成一个秒杀,涉及的技术有那些,如何实现
-
- (1)描述
- (2) 具体操作:
- (3).秒杀涉及的技术,以及实现
- 4.13 如果保证不同数据库的事务一致性
- 4.14 描述openrestry(nginx+lua)和nginx的区别
- 4.15 git代码冲突解决常见的解决方式
- 4.16 如何实现项目的限流,解决方式是什么?
- 4.17 项目中如何实现文件的存储和管理的?FastDFS
- 4.18 FastDFS分布式文件存储和管理常见的坑有那些,如何避免
- 4.19 第三方oauth技术是如何实现的,采用的qq,微信,还是微博,具体怎么实用的
-
- (1)介绍
- (2)Oauth2认证流程
- (3) Spring security Oauth2认证解决方案
- 5. 面试总结(3,4)
1. java基础(1)
2. javaweb(1)
3. ssm+springboot+springCloud(1.5)
9.1 Spring Cloud 你们在项目中如何使用?
- SpringCloud概述
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。Spring Cloud并没有重复制造轮子,它只是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。 - SpringCloud(SpringBoot)如何构建微服务项目
- 创建一个父级项目:
统一springboot, springcloud的版本 - 创建一个子级项目:公共类的子级项目
统一维护其它自己项目要用到类 - 创建一个子级项目: 数据源的子级项目
- 创建一个网关的子级项目: GateWay
- 创建一个业务的子级项目: service
比如:
==商品业务的子级项目
==订单业务的子级项目
==秒杀业务的子级项目 - 创建一个业务接口的子级项目: openFeign
比如:
==商品业务接口的子级项目
==订单业务接口的子级项目
==秒杀业务接口的子级项目 - 创建一个用户访问入口的子级项目: web
- SpringCloud构建的微服务项目之间的调用关系(执行流程)
用户通过客户端访问—>web入口---->GateWay子级项目 ---->openFeign子级项目—>service子级项目—>数据库
9.2 Spring Cloud 的各个组件说明
9.2.1 Eureka组件: SpringCloud的服务发现和注册的组件(作用阿里的Nacos)
- 注册中心 : Eureka server, 负责"保存"的服务(服务指的service子级项目的controller配置路径)
- 生产者: Eureka Client, 负责将服务发送到注册中心,由注册中心负责保存.
- 消费者: Eureka Client, 作用: 用户就是消费者,在客户端输入访问地址(地址服务),如果在注册中心由服务,就去访问,
如果在注册中心没有改服务,就报404
总结: 注册中心, 生产者, 消费者 三者之间的关系,以及通过心跳机制来管理服务

9.2.2 Ribbon:负载均衡客户端,需要结合RestTemplate(HttpClient)进行服务的调用
- 默认的负载均衡:轮询
- 服务器启动时,先从Eureka server获取服务列表,然后在请求微服务时,通过RestTemplate进行http调用
- 自定义访问策略
实现步骤: 自定义一个类, 实现Rule接口,那么我们自定义的类就是一个策略类(代码里面就是算法,确定访问方式)
方式一: 在定义的类上面加上@Configuration这个注解(注意: 该配置类不能被springboot扫描到)
方式二:在全局配置文件application.yml配置 策略类.
9.2.3 Feign:Feign默认集成了Ribbon,用它来管理服务(管理controller配置的路径)
Feign可以通过@FeignClient 注解标识一个接口,通过该接口生成一个代理类来进行远程的微服务调用
9.2.4 Hystrix : 熔断限流的组件
为了防止微服务直接调用时,由于某一个微服务宕机导致整个项目无法访问(雪崩现象),这里采用Hystrix来阻断对存在宕机,异常情况的请求,直接本地返回
- 1)Ribbon集成,首先引入相关的依赖,接着开启@EnableHystrix
接着在调用微服务方法上添加 @HystrixCommand(fallbackMethod = “hiError”)指定服务异常的之后本地执行的方法 - 2)Feign集成,在微服务绑定的接口@FeignClient(value = “service-hi”,fallback = SchedualServiceHiHystric.class)中指定异常时调用本地接口实现
- 判定失败:Hystrix会在某个服务连续调用N次不响应的情况下,立即通知调用端调用失败,避免调用端持续等待而影响了整体服务,执行本地业务。
- 恢复服务:Hystrix间隔时间会再次检查此服务,如果服务恢复将继续提供服务。Hystrix间隔几秒会让其中一个请求去调用远程微服务,如果调用成功,就表示服务正常,后面就重新链接
- 开路 断路
9.2.5 GateWay :网关组件
GateWay (网关):
GateWay的主要功能是路由转发和过滤器。路由功能是微服务的一部分,
比如/api/user转发到到user服务,/api/shop转发到到shop服务。GateWay默认和Ribbon结合实现了负载均衡的功能。
作用:限流处理,认证和授权,单点登录,日志管理等等
GateWay的位置:
客户端发送请求---------所有请求------->GateWay网关: 路由分发----------->openFeign: 远程调用-------->service业务
9.3 Ribbon和Feign区别
-
Ribbon添加maven依赖 spring-starter-ribbon 使用@RibbonClient(value=“服务名称”) 使用RestTemplate调用远程服务对应的方法
-
feign添加maven依赖 spring-starter-feign 服务提供方提供对外接口 调用方使用 在接口上使用@FeignClient(“指定服务名”)
-
Ribbon和Feign的区别: Ribbon和Feign都是用于调用其他服务的,不过方式不同。
- 启动类使用的注解不同,Ribbon用的是@RibbonClient,Feign用的是@EnableFeignClients。
- 服务的指定位置不同,Ribbon是在@RibbonClient注解上声明,Feign则是在定义抽象方法的接口中使用@FeignClient声明。
- 调用方式不同,Ribbon需要自己构建http请求,模拟http请求然后使用RestTemplate发送给其他服务,步骤相当繁琐。Feign则是在Ribbon的基础上进行了一次改进,采用接口的方式,将需要调用的其他服务的方法定义成抽象方法即可,不需要自己构建http请求。不过要注意的是抽象方法的注解、方法签名要和提供服务的方法完全一致。
9.4 Spring Cloud 注意的细节
注意: 配置Feign,以及Rabbion的配置类上, 一定不能被springboot的引导类扫描到.
9.5 springCloud版本号更新的方式
-
采用版本名+版本号,其中版本名采用伦敦地铁站命名,其中按照地铁首字母A-Z依次命令如Hoxton.SR9。但是现在已更改为主版本号.次版本号.修订号如2020.0.0
-
旧版本命名方式中,开发的快照版本(BUILD-SNAPSHOT)到里程碑版本(M),开发的差不多到会发布的候选发布版(RELEASE),最后到正式版(SR)版本。
-
新版本命名是
YYYY.MINOR.MICRO[-MODIFIER],拿2020.0.1-SNAPSHOT 这个版本来说,其中YYYY为年份全称、MINOR为辅助版本号、MICRO为补丁版本号。MODIFIER同上述修饰关键节点,BUILD-SNAPSHOT、里程碑M,正式发行版本RELEASE等当前已发布SpringCloud稳定版本见下图,在线查看地址:https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-dependencies
9.6 SpringCloud和SpringBoot有版本兼容的
浏览器访问https://start.spring.io/actuator/info,在返回的数据中找到spring-cloud即可以查看SpringCloud与SpringBoot版本对应关系。

4. 企业开发的项目: 技术说明(1.5)
4.1 针对电商项目来说: SPU和SKU是什么, 用来表示什么?
==SPU: strand product unit 标准产品单位(并不是一个具体的商品)
比如: 华为 P40 (商品详情页,规格和包装介绍)
华为P40产品标准: cpu高通870, 尺寸6.7
==sku: strored keeping unit 进入库存储单位(表示的就是一个具体的商品)
比如: 华为P40 红色,内存8G+256,表示一个具体的商品
4.2 前后端分离
前后端分离的目的: 实现前端和后台的数据不耦合,最终的效果是前后端都能够独立存在
前端人员开发: 独立开发前端代码
对于前端工程师:调用接口地址,接收json,解析json
后端人员开发: 独立开发后端代码
对于后端java工程师:提供业务的具体接口,响应json数据
后端人员通过swagger自动生成接口地址文档,
swagger使用参考地址: 点击访问swagger

4.3 Shiro和SpringSecurity权限校验框架的区别
相同点:
1:认证功能: 判断当前用户登录是否正确
2:授权功能: 如果用户登录成功,根据用户的角色把角色对应的权限数据(用户能够方位的资源)查询出来,赋值给当前用户.
3:加密功能
4:会话管理
5:缓存支持
6:rememberMe功能…
不同点:
优点:
1:Spring Security基于Spring开发,项目中如果使用Spring(SpringBoot)作为基础,配合Spring Security做权限更加方便.
2:Spring Security功能比Shiro更加丰富些,例如安全防护
=SpringSecutity: 使用比较麻烦(1.认证和授权代码 2.配置等比较麻烦)
=Shiro可以脱离任何第三方框架,也就是说Shiro可以独立使用: 上手容易,配置简单
3:Spring Security社区资源比Shiro丰富
缺点:
1:Shiro的配置和使用比较简单,Spring Security上手复杂
2:Shiro依赖性低,不需要任何框架和容器,可以独立运行,而Spring Security依赖于Spring容器
总结:
权限校验时,设计表来管理权限数据,一般情况下需要设计4张表,里面不包含用户表
=用户表: tab_user
=用户和角色的中间表: user_role(第一张表)
=角色表(第二张表): tab_role(角色数据,书写:游客,普通用户, 管理员,vip用户等)
=角色和权限的中间表: role_resource(第三张表)
=权限表(第四张表): tab_resource(资源数据,书写的资源路径)
4.4 分布式缓存redis在项目中如何实现高可用
4.4.1 项目中哪些地方用到redis
比如: redis缓存来实现用户最近浏览的商品列表
1.最近浏览的记录肯定是需要失效时间的
2.最近浏览的记录肯定是有个数限制的,不可能记录所有的浏览记录
比如: redis保存秒杀的商品信息(快),同时保存秒杀的用户信息(set保存ip保证同一个用户不能重复秒杀)
防止秒杀过程中,同一个用户多次秒杀: 将用户的ip地址存到set集合
比如: redis保证手机验证码(设置失效时间)
比如: redis缓存不经常修改的数据,比如: 首页显示的模板数据和分类数据
比如: redis保存实时在线人数(来人了,人走上了), 点赞次数
总结一下:项目中使用redis的场景
(1)为热点数据加速查询(主要场景)。如热点商品、热点新闻、热点资讯、推广类等高访问量信息等。
(2)即时信息查询。如各位排行榜、各类网站访问统计、公交到站信息、在线人数信息(聊天室、网站)、设备信号等。
(3)时效性信息控制。如验证码控制、投票控制等。
(4)分布式数据共享。如分布式集群架构中的 session 分离,消息队列.
4.4.2 介绍以下redis的数据类型以及应用场景
- redis的数据结构: key=value, key是String字符串类型,value常用的有五种数据类型
- 数据类型: string、 hash、list, set、 sorted set
- redis的应用场景
- 数据不经常修改的,保存到redis
- 时效性数据保存到redis
- 生成自增 id
利用redis原子性,生成id(id不会重复,也就是唯一的,因为redis是单线程的)
在分库分表时,为了保证不同数据库下面相同表的主键唯一性: 主键使用redis自增id.
redis自增id的解释说明:
当 redis 的 string 类型的值为整数形式时,redis 可以把它当做是整数一样进行自增(incr)自减(decr)操作。由于 redis 所有的操作都是原子性的,所以不必担心多客户端连接时可能出现的事务问题。
incr 对值进行加1操作,如果不是整数,返回错误,如果不存在按照从0开始 decr同incr,但是是减1操作 incrby,decrby 增加减去指定的数 - 共享session,其实使用redis+session(redis保存session中数据,实现session的跨域)
- 自动定时过期时间
4.4.3 描述以下redis的持久化机制
- 持久化:就是把内存中的数据序列化到硬盘,保证数据不丢失
- 持久化方式:分别是rdb和aof的持久化方式
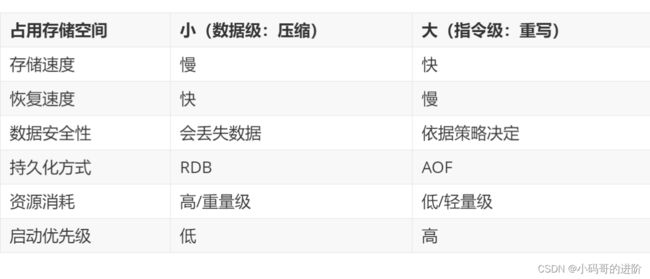
4.4.4 描述以下redis的两种持久化机制的区别
rdb持久化:Redis为我们提供了一个rdb的持久化方式具体每隔一定时间,或者当key的改变达到一定的数量的时候,就会自动往磁盘保存一次
方式1 save 900 1(900秒后1个key改变)
方式2 save 300 10(300秒后10个key改变)
方式3 save 60 10000(60秒后10000个key改变)
aof持久化:Redis还为我们提供了一个aof的持久化方式,这种方式是通过记录用户的操作过程(用户每执行一次命令,就会被Redis记录在XXX.aof文件里,如果突然断电了,Redis的数据就会通过重新读取并执行XXX.aof里的命令记录来恢复数据)来恢复数据
优缺点:
优点: 都是为了防止数据丢失
缺点:
rdb:假如三种方式没有一种被满足,触发不了保存,突然断电,那就会丢失数据
aof:为了解决rdb的弊端,就有了aof的持久化,始终在一个文件里保存记录,但aof 的持久化随着时 间的推移数据量会越来越大,占用很大的空间
更详细了解持久化: 请参考点击网址
4.4.5 AOF持久化文件越来越大怎么办
Redis引入了AOF重写机制压缩文件体积。AOF文件重 写是将Redis进程内的数据转化为写命令同步到新AOF文件的过程。简单说就是将对同一个数据的若干个条命令执行结果转化成最终结果数据对应的指令进行记录。
4.4.6 redis为什么被称为单线程,以及为什么单线程效率还这么高
- redis单线程:
指的网络请求时,发送一次请求操作redis. 只能当前网络请求操作redis结束以后,下个网络请求操作redis. - redis的底层操作是多线程
指的redis进行数据操作时,比如: 设置string ,或者设置hashmap
是通过多线程进行数据操作(提高redis的效率)
详解: Redis为什么是单线程
注意:redis 单线程指的是网络请求模块使用了一个线程,即一个线程处理所有网络请求,其他模块仍用了多个线程。
因为CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽,既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。关于redis的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
4.4.7 Redis为什么这么快
- redis基于内存的数据库,对数据的操作都是在内存进行的,所以快
- redis的数据结构简单都是字符串
- redis里面的保存的数据没有关联关系(redis称之为nosql)
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致 的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
4.4.8 Redis操作中常见的问题
- redis缓存中的数据和数据库中的数据双写不一致的问题,怎么解决?
比如:
情况一: redis缓存数据库, 以及mysql(硬盘)数据库
第一次查询时: 10个数据保存到redis缓存中, mysql保存了10个数据
下次操作时: 将mysql数据库中的10个数据删除了2个,mysql剩余了8个数据库
造成的结果: redis是10个数据, mysql是8个数据 数据不一致性?
解决方案: 在操作mysql数据时,同时清空redis缓存中的数据.
等下次从redis缓存中取数据,首先从数据库中查询.
springboo+redis开发的项目:
@Cacheable 应用到读取数据的方法上,先从缓存中读取,如果没有再从 数据库获取数据,然后把数据添加到缓存中
注解的属性说明:
key = redis的key
condition= 当符合条件时,将从数据库中查询的数据存到redis
@CachePut :应用到修改和添加方法, 当执行新增/修改方法,调用方法时会自动把相应的数据放入缓存
@CacheEvict 应用到删除数据的方法上,当执行删除方法时, 调用方法时会从缓存中删除对应 key 的数据
比如:
情况二: 向redis里面写数据, 同时也向数据库写数据, 也就是双写数据.
在redis写数据时, 由于某种原因(服务器宕机),没有及时向数据库写数据(没有成功 )
出现情况一般是无法解决的.
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
- 缓存雪崩问题(redis失效了)
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而 导致数据库连接异常。
解决方案:
(一)给缓存的失效时间,加上一个随机值,避免集体失效。
(二)使用互斥锁,但是该方案吞吐量明显下降了。
(三)双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
I 从缓存A读数据库,有则直接返回
II A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
III 更新线程同时更新缓存A和缓存B
- 缓存击穿(穿透)问题
缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库 上,从而数据库连接异常
解决方案:
网路请求时–>“过滤器”: 获取请求的key, 去查询redis,判断是否有这个key,如果没有这个key,拒绝该请求->redis
(一)利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
(二)采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作
(三)提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
4.4.9 如何保证redis在高并发下的高可用?
- Redis 主从架构: 主从复制
- Redis 哨兵集群实现高可用
- Redis 压缩持久化文件
- 详细了解: 点击参考该网址
4.4.10 如何保证Redis缓存中: 热门商品的同步?
说明: 热门商品需要在网站首页展示,确定热门商品的遴选规则.
热门商品: 情况一: 根据商品的购买次数,定为热门商品. 情况二: 新上架的商品把它定为热门商品.等等
以情况二为主: 数据库中的热门商品 和 redis缓存中热门商品数据一致性问题?
解决: 通过定时器(spring Task),定时查询数据库,如果有热门商品, 直接set到redis缓存中了.
4.5 常用的消息中间件有那些,底层都用什么协议,有什么区别
- 消息中间件
作用一: 可以实现后台的异步操作.
作用二: 可以实现分布式事务
作用:等等 - 常用的消息中间件
- ActiveMQ
- RocketMQ
- RabbitMQ
- 底层通信协议:
== AMQP协议
AMQP即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同开发语言等条件的限制。
优点:可靠、通用
==MQTT协议
MQTT(Message Queuing Telemetry Transport,消息队列遥测传输)是IBM开发的一个即时通讯协议,有可能成为物联网的重要组成部分。该协议支持所有平台,几乎可以把所有联网物品和外部连接起来,被用来当做传感器和致动器(比如通过Twitter让房屋联网)的通信协议。
优点:格式简洁、占用带宽小、移动端通信、PUSH、嵌入式系统
==STOMP协议
STOMP(Streaming Text Orientated Message Protocol)是流文本定向消息协议,是一种为MOM(Message Oriented Middleware,面向消息的中间件)设计的简单文本协议。STOMP提供一个可互操作的连接格式,允许客户端与任意STOMP消息代理(Broker)进行交互。
优点:命令模式(非topic\queue模式)
详细请参考: 消息中间件详细介绍
4.6 常用的高并发解决方案有那些
- 页面静态化: 将动态页面数据静态化(用户在访问服务器端,不用每次发送请求)
- 使用缓存技术
- 搭建集群
- 用户访问来说: 搭建web服务器集群
- 操作数据库来说: 搭建数据库集群
- 分库分表
- 从查询数据表来说: 提供查询效率
比如: 一张表有10000条数据, 可以把一张表分为10张表: 每张1000条
- 从查询数据表来说: 提供查询效率
- 读写分离
- 对于不经常修改的数据,读操作频率比较高: 把数据放在读表
- 搭建消息队列服务器
比如:
订单模块操作时,生成订单可以异步(服务器端的异步)给当前用户增加积分
结论: 从数据库层面一定程度上解决高并发,操作数据库用到connection
生成订单---->当前用户异步进行积分的累加(生成消息添加到队列), 节省用户的访问时间.
生成订单的同时,立即给当前用户进行积分累加操作: 用户访问时间长了
详细请参考: 高并发常用的解决方案
4.7 如何实现CAS单点登录
- 单点登录
一个大的系统里面,包含多个子系统,登录一个子系统,同时访问其它几个子系统.
比如:
百度—>大的系统
知乎---->子系统
新闻—>子系统
在知乎上登录成功以后,访问其它系统. - 单点登录技术
- spring security
- shiro
- cas
- cas说明单点登录流程以及底层实现.

4.8 用户恶意频繁添加购物车, 添加购物车跨域问题, cookie禁用怎么办等常见的购物车问题如何解决(面试官: 项目中遇到了那些问题
问题一: 1.用户恶意频繁添加购物车,
(1). 限制每个用户或者IP对应的购物车购买数量
(2). 如果频繁添加购物车,当同一用户或者同一IP,在某个时间间隔(5秒)之类添加次数超过10次,就需要输入验证码才能进行再次添加
问题二: 2.添加购物车跨域问题,
- 解决方式一:
前端使用异步请求的jsonp - 解决方式二:(最简单)
后端在web层的controller里面: @Crossrign - 解决方式三:
使用cookie携带数据
由于系统采用的是分布式部署,存在多个系统可以添加购物车。此时就涉及到跨域请求的问题,跨域请求解决方案有JSONP和CORS。采用CORS来解决跨域请求,CORS跨来源资源共享是一份浏览器技术的规范只需要在服务端设置一个允许响应请求的响应头信息,同时由于购物车需要获取和响应cookie还要分别在浏览器请求设置允许请求带上cookie和服务端运行响应带上cookie.
问题三: cookie禁用怎么办等常见的购物车问题如何解决
解决方案一: 在地址栏重写url(在地址栏拼接cookie),这种方案不用
解决方案二: 在前端代码里面判断用户的浏览器是否禁用了cookie, 如果禁用cookie,提醒开启cookie.
4.9 怎么实现微信支付接入
参考地址: 微信Native扫码支付
4.10 为什么对数据库分库分表?
1.为什么需要分库分表

- 如何保证不同数据库同一张表的主键唯一性
- 采用分布式ID
比如: redis生成id, snowflake生成id - snowflake介绍: 参考该网址
- 开源数据库中间件-MyCat产生的背景
如今随着互联网的发展,数据的量级也是成指数的增长,从GB到TB到PB。对数据的各种操作也是愈加的困难,传统的关系型数据库已经无法满足快速查询与插入数据的需求。这个时候NoSQL的出现暂时解决了这一危机。它通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来获取性能上的提升。
但是,在有些场合NoSQL一些折衷是无法满足使用场景的,就比如有些使用场景是绝对要有事务与安全指标的。这个时候NoSQL肯定是无法满足的,所以还是需要使用关系型数据库。如何使用关系型数据库解决海量存储的问题呢?此时就需要做数据库集群,为了提高查询性能将一个数据库的数据分散到不同的数据库中存储。
什么是MyCat?


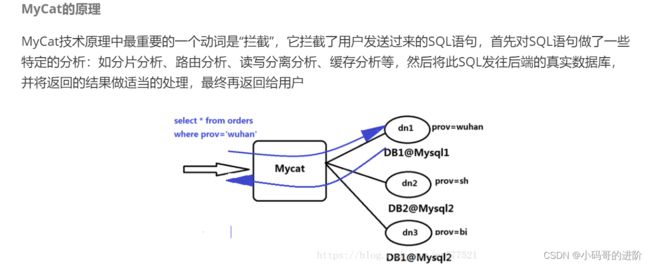
4.数据库读写分离
读写分离简单的说是把对数据库读和写的操作分开对应不同的数据库服务器,这样能有效地减轻数据库压力,也能减轻io压力。主数据库提供写操作,从数据库提 供读操作,其实在很多系统中,主要是读的操作。当主数据库进行写操作时,数据要同步到从的数据库,这样才能有效保证数据库完整性。Quest SharePlex就是比较牛的同步数据工具,听说比oracle本身的流复制还好,mysql也有自己的同步数据技术。mysql只要是通过二进制日志来复制数据。通过日志在从数据库重复主数据库的操作达到复制数据目的。这个复制比较好的就是通过异步方法,把数据同步到从数据库。
主数据库同步到从数据库后,从数据库一般由多台数据库组成这样才能达到减轻压力的目的。读的操作怎么样分配到从数据库上?应该根据服务器的压力把读的操作分配到服务器,而不是简单的随机分配。mysql提供了MySQL-Proxy实现读写分离操作。不过MySQL-Proxy好像很久不更新了。oracle可以通过F5有效分配读从数据库的压力。
大多数互联网业务,往往读多写少,这时候,数据库的读会首先称为数据库的瓶颈,这时,如果我们希望能够线性的提升数据库的读性能,消除读写锁冲突从而提升数据库的写性能,那么就可以使用“分组架构”(读写分离架构)。
用一句话概括,读写分离是用来解决数据库的读性能瓶颈的。
5. 分库分表的实施策略
分表的方式:
水平拆分: 表中的字段都一样
根据表的数据量进行拆分,比如: 10000条数据,分成每张表100条数据
情况: 表中的数据是动态增长的, 如果进行水平拆分.
水平拆分的实施策略: 1. 每月15号拆分 2. 当表中数据增长的10万条数据等等
垂直拆分:
根据查询字段出现的频率来进行拆分,每张表的字段不一样.
表中的数据非常庞大,表中的字段特别多: select id from 表中1
表中只有一个字段id,同样的数据量: select id from 表中2(查询效率高)
4.11 如何处理超时无效订单
- 无效订单说明
指的生成订单后,未付款. 那些未付款的订单就是无效订单.
具体给定一个付款时间,比如30分钟内没有付款,当作无效订单. - 无效订单清除,具体如何操作.
通过定时器调度,去查询数据库,订单数据表里面有两个时间字段:order_create_time, order_end_time
如果说: 结束时间-生成时间>30分钟,且付款状态为未付款状态, 将该订单删除. - 具体操作的方式:
- 在生成订单时,同时向订单表中添加订单创建时间order_create_time
- 开启定时器,间隔30分钟(并没有一个严格的限定),执行查询数据库操作.
查询(order_end_time-order_create_time)>30分钟 并且 订单state=未付款状态.
将生成无效订单消息, 添加到消息队列中(死信消息队列) - 消费无限订单消息: 异步删除无效订单
具体实现参考: 点击,查看:消除超时的无效订单
4.12 如何完成一个秒杀,涉及的技术有那些,如何实现
(1)描述
- 从数据库层面来说:
设计一张秒杀表 ,以及秒杀的订单表,为了提高查询秒杀商品的效率
tab_kill_products表: 定义两个字段秒杀的开始时间,以及结束时间. - 防止同一个用户秒杀多次
将用户的ip添加到redis的set集合中. - 秒杀的实现流程,具体涉及的技术
- redis保存: 秒杀的商品信息
- 限流: GateWay限流
- 定时调度器(spring task): 按照秒杀商品的(end-start)时间,去定时查询秒杀商品
将秒杀的商品存到redis缓存,同时将秒杀的商品展示到秒杀页面. - 异步支付(消息队列): 秒杀商品成功,自动生成订单,异步给该订单付款(节省时间)
- 异步支付时,如何防止订单消息丢失?
消息队列confirm机制. - 秒杀的执行流程
1.执行定时任务: 查询秒杀的商品,展示到秒杀页面
- 用户访问秒杀页面,点击秒杀商品,如果秒杀成功,生成订单,将订单数据信息添加到消息队列中(生产消息)
- 通过消息队列: 异步消息订单数据信息,其实给订单付款
(2) 具体操作:
-
从表中设计来说:
单独设计一张表作为秒杀表(提高查询秒杀商品的效率)
设计秒杀商品的开始时间和结束时间.
在页面上根据时间节点展示秒杀的商品
18点(18-19): 19点(19-20):
-
秒杀: redis+在线支付+ 消息队列(将先进来的用户存到第一位-----)
- 限流
- 记数器思想
将先进入的网站的用户id,存到redis, 存200个, 超出200,不让访问 - gateway限流
- 记数器思想
- 防止重复秒杀
将用户ip存到redis的set数据类型.
- 限流
-
需求分析
所谓“秒杀”,就是网络卖家发布一些超低价格的商品,所有买家在同一时间网上抢购的一种销售方式。通俗一点讲就是网络商家为促销等目的组织的网上限时抢购活动。由于商品价格低廉,往往一上架就被抢购一空,有时只用一秒钟。
秒杀商品通常有两种限制:库存限制、时间限制。
- 秒杀商品存入缓存
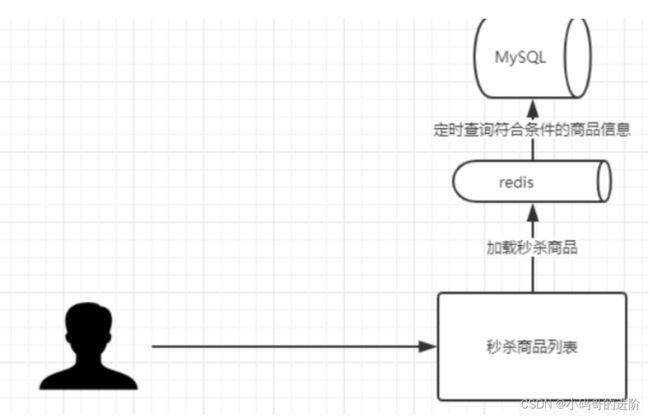
秒杀商品由B端存入Mysql,设置定时任务,每隔一段时间就从Mysql中将符合条件的数据从Mysql中查询出来并存入缓存中,redis以Hash类型进行数据存储。
5. 秒杀注意事项
1)实现秒杀异步下单,掌握如何保证生产者&消费者消息不丢失
用户在下单的时候,需要基于JWT令牌信息进行登陆人信息认证,确定当前订单是属于谁的。同时异步下单,能够解决服务器端压力.
生成者和消费者消息不丢失

按照现有rabbitMQ的相关知识,生产者会发送消息到达消息服务器。但是在实际生产环境下,消息生产者发送的消息很有可能当到达了消息服务器之后,由于消息服务器的问题导致消息丢失,如宕机。因为消息服务器默认会将消息存储在内存中。一旦消息服务器宕机,则消息会产生丢失。因此要保证生产者的消息不丢失,要开始持久化策略,同时开启RabbitMQ数据confirm保护机制
confirm机制
confirm模式需要基于channel进行设置, 一旦某条消息被投递到队列之后,消息队列就会发送一个确认信息给生产者,如果队列与消息是可持久化的, 那么确认消息会等到消息成功写入到磁盘之后发出.
confirm的性能高,主要得益于它是异步的.生产者在将第一条消息发出之后等待确认消息的同时也可以继续发送后续的消息.当确认消息到达之后,就可以通过回调方法处理这条确认消息. 如果MQ服务宕机了,则会返回nack消息. 生产者同样在回调方法中进行后续处理。
2)实现防止相同商品重复秒杀
因为秒杀商品在redis里面,用户秒杀商品时,秒杀一个,从redis里面移除一个,所以相同商品重复秒杀,对应的是当前用户可能重复秒杀的情况, 我们只需要查询当前用户是否购买过此商品即可.
3)实现防止用户重复秒杀(实现思路: 只允许秒杀一次)
4)秒杀流量削峰
我们就可以将秒杀请求暂时存在消息队列中,然后我们的业务服务器高速用户“秒杀进行中”等,等释放系统资源后再去处理其他用户请求。
我们在后台可以开启 n 个队列处理程序,不断的消费消息队列中的任务,然后校验库存接着下单等操作,现在由于我们是有限的队列处理线程在执行,所以最终落到数据库上的并发请求也是有限的。用户请求是可以在消息队列中短暂堆积的,当库存为零了,消息队列堆积的请求也就可以全部释放了。
(3).秒杀涉及的技术,以及实现
-
redis
-
rabbitmq(秒杀成功异步下单,修改库存,从redis移除,秒杀成功未下单的,修改库存,重新添加redis)
-
实现流程:
-
定时任务: 查询当前时间段的秒杀商品,添加到缓存中,显示到秒杀商品页面
-
点击秒杀商品:
2.1.判断库存是否足够, 库存不足, 提示秒杀失败
2.2 存储足够, 提交商品id到后台,生成订单,同时修改秒杀商品的库存个数
2.3 如果超时订单未支付,重新回滚库存个数,添加此商品到redis中
-
4.13 如果保证不同数据库的事务一致性
解决方案有两种:
方式一: 使用分布式事务框架,比如: seata
缺点: 效率低, 优点: 保证数据不丢失
方式二: 使用消息队列解决分布式事务.
优点: 执行效率高, 缺点: 存在数据丢失,就不能保证事务的最终一致性.
具体实现: 点击链接,参考分布式事务的执行
4.14 描述openrestry(nginx+lua)和nginx的区别
- openrestry(nginx+lua)是反向代理web服务器, 底层是封装了nginx+lua(脚本)
- nginx是反向代理的web服务器
4.15 git代码冲突解决常见的解决方式
1、git冲突的场景
- 情景一:多个分支代码合并到一个分支时;
- 情景二:多个分支向同一个远端分支推送代码时;
实际上,push操作即是将本地代码merge到远端库分支上。
关于push和pull其实就分别是用本地分支合并到远程分支 和 将远程分支合并到本地分支
所以这两个过程中也可能存在冲突。
git的合并中产生冲突的具体情况:
<1>两个分支中修改了同一个文件(不管什么地方)
<2>两个分支中修改了同一个文件的名称
两个分支中分别修改了不同文件中的部分,不会产生冲突,可以直接将两部分合并。
2、冲突解决方法 - 情景一:在当前分支上,直接修改冲突代码—>add—>commit。
- 情景二:在本地当前分支上,修改冲突代码—>add—>commit—>push
注:借用vim或者IDE或者直接找到冲突文件,修改
总结:
四种方式:
1、使用“git fetch origin master”将远程分支拉下来;
2、执行命令来手动合并冲突的内容;
3、使用“git add xxx”和“git commit -m…”将改动提交;
4、执行命令将改动提交到远程分支。
4.16 如何实现项目的限流,解决方式是什么?
- 在项目中的那个位置,实现限流的解决方案
网关位置. - 在网关位置,如何实现限流
- 计算器思想: 计算器算法
- 漏桶思想: 漏桶算法
- 令牌桶思想: 令牌桶算法
等等
4.17 项目中如何实现文件的存储和管理的?FastDFS
- 实现文件的存储和管理
- 通过分布式文件存储和管理技术,搭建文件服务器,比如: fastDFS(开源技术)
- 通过Aache提供的分布式文件存储和管理技术,搭建文件服务器,比如: MIO(开源技术)
- 通过云存储技术,比如: 购买七牛云, 阿里云等等
4.18 FastDFS分布式文件存储和管理常见的坑有那些,如何避免
点击参考: 分布式文件FastDFS介绍说明
点击参考: 手把手教你怎么使用FastDFS
4.19 第三方oauth技术是如何实现的,采用的qq,微信,还是微博,具体怎么实用的
(1)介绍
随着国内及国外巨头们的平台开放战略以及移动互联网的发展,第三方登录已经不是一个陌生的产品设计概念了。 所谓的第三方登录,是说基于用户在第三方平台上已有的账号和密码来快速完成己方应用的登录或者注册的功能。而这里的第三方平台,一般是已经拥有大量用户的平台,国外的比如Facebook,Twitter等,国内的比如微博、微信、QQ等。
(2)Oauth2认证流程
第三方认证技术方案最主要是解决认证协议的通用标准问题,因为要实现跨系统认证,各系统之间要遵循一定的
接口协议。
OAUTH协议为用户资源的授权提供了一个安全的、开放而又简易的标准。同时,任何第三方都可以使用OAUTH认
证服务,任何服务提供商都可以实现自身的OAUTH认证服务,因而OAUTH是开放的。业界提供了OAUTH的多种实现如PHP、JavaScript,Java,Ruby等各种语言开发包,大大节约了程序员的时间,因而OAUTH是简易的。互联网很多服务如Open API,很多大公司如Google,Yahoo,Microsoft等都提供了OAUTH认证服务,这些都足以说明OAUTH标准逐渐成为开放资源授权的标准。
Oauth协议目前发展到2.0版本,1.0版本过于复杂,2.0版本已得到广泛应用。
参考:https://baike.baidu.com/item/oAuth/7153134?fr=aladdin
Oauth协议:https://tools.ietf.org/html/rfc6749
下边分析一个Oauth2认证的例子,达内慕课网站使用微信认证的过程:
 1.客户端请求第三方授权
1.客户端请求第三方授权
用户进入达人幕课的登录页面,点击微信的图标以微信账号登录系统,用户是自己在微信里信息的资源拥有者。
 2.点击“微信图标”出现一个二维码,此时用户扫描二维码,开始给达人幕课授权。
2.点击“微信图标”出现一个二维码,此时用户扫描二维码,开始给达人幕课授权。
 3.资源拥有者同意给客户端授权
3.资源拥有者同意给客户端授权
资源拥有者扫描二维码表示资源拥有者同意给客户端授权,微信会对资源拥有者的身份进行验证, 验证通过后,并重定向到达人幕课的网站。
 4.客户端获取到授权码,请求认证服务器申请令牌 此过程用户看不到,客户端应用程序请求认证服务器,请求携带授权码。
4.客户端获取到授权码,请求认证服务器申请令牌 此过程用户看不到,客户端应用程序请求认证服务器,请求携带授权码。
5.认证服务器向客户端响应令牌 认证服务器验证了客户端请求的授权码,如果合法则给客户端颁发令牌,令牌是客户端访问资源的通行证。 此交互过程用户看不到,当客户端拿到令牌后,用户在达人幕课看到已经登录成功。
6.客户端请求资源服务器的资源 客户端携带令牌访问资源服务器的资源。 达人幕课网站携带令牌请求访问微信服务器获取用户的基本信息。
7.资源服务器返回受保护资源 资源服务器校验令牌的合法性,如果合法则向用户响应资源信息内容。 注意:资源服务器和认证服务器可以是一个服务也可以分开的服务,如果是分开的服务资源服务器通常要请求认证 服务器来校验令牌的合法性。
Oauth2.0认证流程如下: 引自Oauth2.0协议rfc6749 https://tools.ietf.org/html/rfc6749

Oauth2包括以下角色:
1、客户端 本身不存储资源,需要通过资源拥有者的授权去请求资源服务器的资源,比如:达人购Android客户端、达人购Web客户端(浏览器端)、微信客户端等。
2、资源拥有者 通常为用户,也可以是应用程序,即该资源的拥有者。
3、授权服务器(也称认证服务器) 用来对资源拥有的身份进行认证、对访问资源进行授权。客户端要想访问资源需要通过认证服务器由资源拥有者授 权后方可访问。
4、资源服务器 存储资源的服务器,比如,达人购用户管理服务器存储了达人购的用户信息,微信的资源服务存储了微信的用户信息等。客户端最终访问资源服务器获取资源信息。
Oauth2在项目的应用
Oauth2是一个标准的开放的授权协议,应用程序可以根据自己的要求去使用Oauth2,项目中使用Oauth2可以实现实现如下功能:
1、本系统访问第三方系统的资源
2、外部系统访问本系统的资源
3、本系统前端(客户端) 访问本系统后端微服务的资源。
4、本系统微服务之间访问资源,例如:微服务A访问微服务B的资源,B访问A的资源。
(3) Spring security Oauth2认证解决方案
本项目采用 Spring security + Oauth2+JWT完成用户认证及用户授权,Spring security 是一个强大的和高度可定制的身份验证和访问控制框架,Spring security 框架集成了Oauth2协议,下图是项目认证架构图:
 1、用户请求认证服务完成认证。
1、用户请求认证服务完成认证。
2、认证服务下发用户身份令牌,拥有身份令牌表示身份合法。
3、用户携带令牌请求资源服务,请求资源服务必先经过网关。
4、网关校验用户身份令牌的合法,不合法表示用户没有登录,如果合法则放行继续访问。
5、资源服务获取令牌,根据令牌完成授权。
6、资源服务完成授权则响应资源信息。
5. 面试总结(3,4)
- 工资福利
- 加班问题
- 公积金如何购买,买在哪里
- 试用期时间以及工资
- 请求贵公司主体业务是什么,如果有共鸣就可以简单说一下自己曾经做过类似的东西!
- 贵公司所采用架构是什么,以主要采用什么技术完成开发。
- 贵公司是前后端分离开发模式,还是针对接口文档开发,或者是后端开发人员需要编写js交互 ,开发技术有哪些,比如数据访问层,业务层,控制层
- 开发工具是否有要求
- 等等