CUDA运行API:RuntimeAPI
目录
1.1-hello-runtime
1.2 Memory
1.3 Stream:
1.4 核函数
1.5 共享内存
1.6 仿射变换:Warpaffine
1.7 Yolov5后处理
1.8 error:
- Cuda开头的函数都属于RuntimeAPI
- RuntimeAPI,与driver最大区别是懒加载:
- 即:第一个runtime API调用时,会进行cuInit初始化,避免驱动api的初始化窘境
- 即:第一个需要context的API调用时,会进行context关联并创建context和设置当前context,调用cuDevicePrimaryCtxRetain实现
- 绝大部分api需要context,例如查询当前显卡名称、参数、内存分配、释放等

- 使用cuDevicePrimaryCtxRetain为每个设备设置context,不再手工管理context,并且不提供直接管理context的API(可Driver API管理,通常不需要)
- 更友好的使用核函数,.cpp和.cu文件无缝对接
本节主要知识点:核函数的使用、线程束布局、内存模型、流的使用
主要可以实现:归纳求和、仿射变换、矩阵变换、模型后处理
1.1-hello-runtime
CUDA运行时API开始,以及与CUDA驱动API的context关系解释
// CUDA运行时头文件
#include
// CUDA驱动头文件
#include
#include
#include
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
int main(){
CUcontext context = nullptr;
cuCtxGetCurrent(&context); //获取当前的context函数
printf("Current context = %p,当前无context\n", context);
// cuda runtime是以cuda为基准开发的运行时库
// cuda runtime所使用的CUcontext是基于cuDevicePrimaryCtxRetain函数获取的
// 即,cuDevicePrimaryCtxRetain会为每个设备关联一个context,通过cuDevicePrimaryCtxRetain函数可以获取到
// 而context初始化的时机是懒加载模式,即当你调用一个runtime api时,会触发创建动作
// 也因此,避免了cu驱动级别的init和destroy操作。使得api的调用更加容易
int device_count = 0;
checkRuntime(cudaGetDeviceCount(&device_count));
printf("device_count = %d\n", device_count);
// 取而代之,是使用setdevice来控制当前上下文,当你要使用不同设备时
// 使用不同的device id
// 注意,context是线程内作用的,其他线程不相关的, 一个线程一个context stack
int device_id = 0;
printf("set current device to : %d,这个API依赖CUcontext,触发创建并设置\n", device_id);
checkRuntime(cudaSetDevice(device_id));
// 注意,是由于set device函数是“第一个执行的需要context的函数”,所以他会执行cuDevicePrimaryCtxRetain
// 并设置当前context,这一切都是默认执行的。注意:cudaGetDeviceCount是一个不需要context的函数
// 你可以认为绝大部分runtime api都是需要context的,所以第一个执行的cuda runtime函数,会创建context并设置上下文
cuCtxGetCurrent(&context);
printf("SetDevice after, Current context = %p,获取当前context\n", context);
int current_device = 0;
checkRuntime(cudaGetDevice(¤t_device));
printf("current_device = %d\n", current_device);
return 0;
} 1.2 Memory
主要类型:pinned memory、global memory 、shared memory等
整个Host Memory内存条而言,操作系统区分为两个大类(逻辑区分,物理上是同一个东西):
- Pageable memory,可分页内存 普通房间,内存不够时,将会被移到cpu内存中
- Page lock memory,页锁定内存 vip房间

Memory总结:
1. pinned memory 具有锁定特性,是稳定不会被交换的(相当于每次去这个房间都一定能找到你)2. pageable memory 没有 锁定特性 ,对于第三方设备(比如 GPU ),去访问时,因为无法感知内存是否被交换,可能得不到正确的数据(每次去房间找,说不准你的房间被人交换了)3. pageable memory 的性能比 pinned memory 差,很可能 降低你程序的优先级 然后把内存交换给别人用4. pageable memory 策略能使用内存假象,实际 8GB 但是可以使用 15GB ,提高程序运行数量(不是速度)5. pinned memory 太多, 会导致操作系统整体性能降低 (程序运行数量减少), 8GB 就只能用 8GB 。注意不是你的应用程序性能降低,这一点一般都是废话,不用当回事6. GPU 可以直接访问 pinned memory 而不能访问 pageable memory (因为第二条)
数据从cpu内存传输到GPU:必须经过Pinned Memory
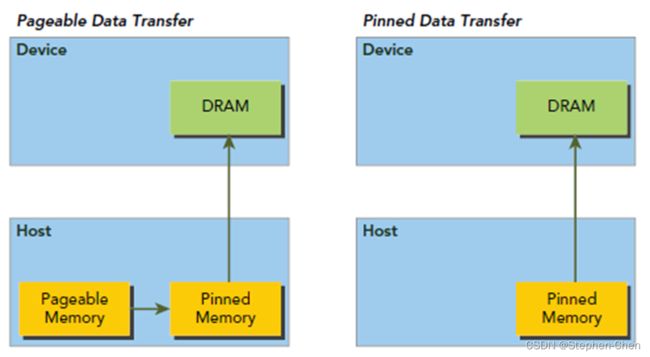

原则:
- GPU可以直接访问pinned memory,称之为(DMA Direct Memory Access)
- 对于GPU访问:距离计算单元越近,效率越高,所PinnedMemory<GlobalMemory<SharedMemory
- 代码中,由new、malloc分配的,是pageable memory,由cudaMallocHost分配的是PinnedMemory,由cudaMalloc分配的是GlobalMemory
- 尽量多用PinnedMemory储存host数据,或者显式处理Host到Device时,用PinnedMemory做缓存,都是提高性能的关键
int main(){
int device_id = 0;
checkRuntime(cudaSetDevice(device_id));
// globe memory分配100个大小
float* memory_device = nullptr;
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float))); // pointer to device
//pageable memory 520.25
float* memory_host = new float[100];
memory_host[2] = 520.25;
checkRuntime(cudaMemcpy(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice)); // 返回的地址是开辟的device地址,存放在memory_device
//pinnedMemory内存
float* memory_page_locked = nullptr;
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float))); // 返回的地址是被开辟的pin memory的地址,存放在memory_page_locked
//将device赋值到
checkRuntime(cudaMemcpy(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost)); //
printf("%f\n", memory_page_locked[2]);
checkRuntime(cudaFreeHost(memory_page_locked));
delete [] memory_host;
checkRuntime(cudaFree(memory_device));
return 0;
}1. 在gpu上开辟一块空间,并把地址记录在mem_device上
2. 在cpu上开辟一块空间,并把地址记录在mem_host上,并修改了该地址所指区域的第二个值
3. 把mem_host所指区域的数据都复制到mem_device的所指区域
4. 在cpu上开辟一块空间,并把地址记录在mem_page_locked上
5. 最后把mem_device所指区域的数据又复制回cpu上的mem_page_locked区域
1.3 Stream:
- 流是一种基于context之上的任务管道抽象,一个context可以创建n个流
- 流是异步控制的主要方式
- nullptr表示默认流,每个线程都有自己的默认流
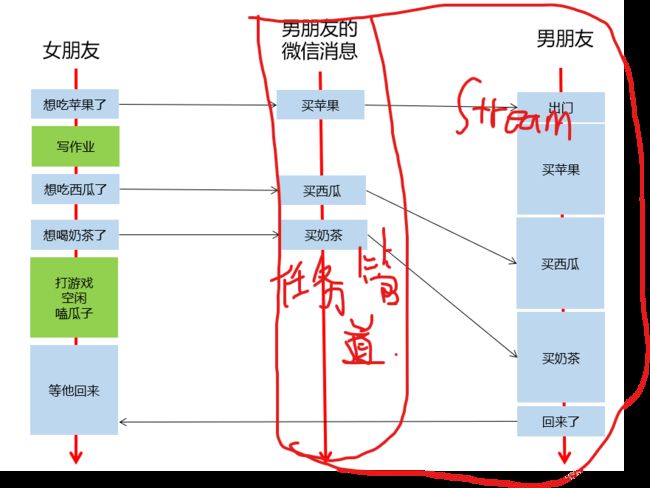
- 男朋友的微信消息,就是任务队列,流的一种抽象
- 女朋友发出指令后,他可以做任何事情,无需等待指令执行完毕,(指令发出的耗时也是极短的)
- 即,异步操作,执行的代码,加入流的队列后,立即返回,不耽误时间
- 女朋友发的指令被流送到流中排队,男朋友根据流的队列,顺序执行
- 女盆友选择性,在需要的时候等待所有执行结果
- 新建一个流,就是新建一个男朋友,给他发指令就是给他发微信,你可以新建很多个男朋友
- 通过cudaEvent可以选择性等待任务队列中部分任务是否就绪
int main(){
int device_id = 0;
checkRuntime(cudaSetDevice(device_id));
cudaStream_t stream = nullptr;
checkRuntime(cudaStreamCreate(&stream)); //创建一个流
// 在GPU上开辟空间
float* memory_device = nullptr;
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float)));
// 在CPU上开辟空间并且放数据进去,将数据复制到GPU
float* memory_host = new float[100];
memory_host[2] = 520.25;
// 异步复制操作,主线程不需要等待复制结束才继续
checkRuntime(cudaMemcpyAsync(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice, stream));
// 在CPU上开辟pin memory,并将GPU上的数据复制回来
float* memory_page_locked = nullptr;
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float)));
checkRuntime(cudaMemcpyAsync(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost, stream)); // 异步复制操作,主线程不需要等待复制结束才继续
printf("%f\n", memory_page_locked[2]);//结果是0,因为还没等待结果返回
checkRuntime(cudaStreamSynchronize(stream)); //统一等待流队列中的结果
printf("%f\n", memory_page_locked[2]);
// 释放内存
checkRuntime(cudaFreeHost(memory_page_locked));
checkRuntime(cudaFree(memory_device));
checkRuntime(cudaStreamDestroy(stream));
delete [] memory_host;
return 0;
}注意:确定不需要指针后才释放这个参数指针
指令发出后,流队列中存储的是指令参数,不能加入队列后立即释放参数指针,会导致流队列执行该指令时指针失效而出错。
1.4 核函数
核函数开辟parray_host=narray=10个线程打印10次
#include
#include
//核函数:在GPU上运行 CUDAC++
__global__ void test_print_kernel(const float* pdata, int ndata){
int idx = threadIdx.x + blockIdx.x * blockDim.x;
/* dims indexs
gridDim.z blockIdx.z
gridDim.y blockIdx.y
gridDim.x blockIdx.x
blockDim.z threadIdx.z
blockDim.y threadIdx.y
blockDim.x threadIdx.x
Pseudo code:
position = 0
for i in 6:
position *= dims[i]
position += indexs[i]
*/
printf("Element[%d] = %f, threadIdx.x=%d, blockIdx.x=%d, blockDim.x=%d\n", idx, pdata[idx], threadIdx.x, blockIdx.x, blockDim.x);
}
void test_print(const float* pdata, int ndata){
// <<>>
dim3 gridDim
dim3 blockDim
int nthreads = gridDim.x*gridDim.y*gridDim.z*blockDim.x*blockDim.y*blockDim.z
test_print_kernel<<<1, ndata, 0, nullptr>>>(pdata, ndata);
// 在核函数执行结束后,通过cudaPeekAtLastError获取得到的代码,来知道是否出现错误
// cudaPeekAtLastError和cudaGetLastError都可以获取得到错误代码
// cudaGetLastError是获取错误代码并清除掉,也就是再一次执行cudaGetLastError获取的会是success
// 而cudaPeekAtLastError是获取当前错误,但是再一次执行 cudaPeekAtLastError 或者 cudaGetLastError 拿到的还是那个错
// cuda的错误会传递,如果这里出错了,不移除。那么后续的任意api的返回值都会是这个错误,都会失败
cudaError_t code = cudaPeekAtLastError();
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("kernel error %s:%d test_print_kernel failed. \n code = %s, message = %s\n", __FILE__, __LINE__, err_name, err_message);
}
}
- 1.核函数是cuda编程的关键
- 2.通过xxx.cu创建一个cudac程序文件,并把cu交给nvcc编译,才能识别cuda语法
- 3.__global__表示为核函数,由host调用。__device__表示为设备函数,由device调用
- 4.__host__表示为主机函数,由host调用。__shared__表示变量为共享变量
- 5.host调用核函数:function<<<gridDim, blockDim, sharedMemorySize, stream>>>(args…);
- 6.只有__global__修饰的函数才可以用<<<>>>的方式调用
- 7.调用核函数是传值的,不能传引用,可以传递类、结构体等,核函数可以是模板,返回值必须是void
- 8.核函数的执行,是异步的,也就是立即返回的
- 9.线程layout主要用到blockDim(块)、gridDim(网格)
- 10.核函数内访问线程索引主要用到threadIdx、blockIdx、blockDim、gridDim这些内置变量

1.5 共享内存
- 共享内存因为更靠近计算单元,所以访问速度更快
- 共享内存通常可以作为访问全局内存的缓存使用
- 可以利用共享内存实现线程间的通信
- 通常与__syncthreads同时出现,这个函数是同步block内的所有线程,全部执行到这一行才往下走
- 使用方式,通常是在线程id为0的时候从global memory取值,然后syncthreads,然后再使用
#include
#include
//demo1 //
/*
demo1 主要为了展示查看静态和动态共享变量的地址
*/
const size_t static_shared_memory_num_element = 6 * 1024; // 6KB
__shared__ char static_shared_memory[static_shared_memory_num_element];
__shared__ char static_shared_memory2[2];
__global__ void demo1_kernel(){
extern __shared__ char dynamic_shared_memory[]; // 静态共享变量和动态共享变量在kernel函数内/外定义都行,没有限制
extern __shared__ char dynamic_shared_memory2[];
printf("static_shared_memory = %p\n", static_shared_memory); // 静态共享变量,定义几个地址随之叠加
printf("static_shared_memory2 = %p\n", static_shared_memory2);
printf("dynamic_shared_memory = %p\n", dynamic_shared_memory); // 动态共享变量,无论定义多少个,地址都一样
printf("dynamic_shared_memory2 = %p\n", dynamic_shared_memory2);
if(blockIdx.x == 0 && threadIdx.x == 0) // 第一个thread
printf("Run kernel.\n");
}
/demo2//
/*
demo2 主要是为了演示的是如何给 共享变量进行赋值
*/
// 定义共享变量,但是不能给初始值,必须由线程或者其他方式赋值
__shared__ int shared_value1;
__global__ void demo2_kernel(){
__shared__ int shared_value2;
if(threadIdx.x == 0){
// 在线程索引为0的时候,为shared value赋初始值
if(blockIdx.x == 0){
shared_value1 = 123;
shared_value2 = 55;
}else{
shared_value1 = 331;
shared_value2 = 8;
}
}
// 等待block内的所有线程执行到这一步
__syncthreads();
printf("%d.%d. shared_value1 = %d[%p], shared_value2 = %d[%p]\n",
blockIdx.x, threadIdx.x,
shared_value1, &shared_value1,
shared_value2, &shared_value2
);
}
void launch(){
demo1_kernel<<<1, 1, 12, nullptr>>>();
demo2_kernel<<<2, 5, 0, nullptr>>>();
} 1. sharedMemPerBlock 指示了block中最大可用的共享内存
- 所以可以使得 block 内的threads可以相互通信。
- sharedMemPerBlock 的应用例子 [1.example1.jpg](figure/1.example1.jpg) [2.example2.jpg](figure/2.example2.jpg)
2. 共享内存是片上内存,更靠近计算单元,因此比globalMem速度更快,通常可以充当缓存使用
- 数据先读入到sharedMem,做各类计算时,使用sharedMem而非globalMem
3. demo_kernel<<<1, 1, 12, nullptr>>>();其中第三个参数12,是指定动态共享内存dynamic_shared_memory的大小
- dynamic_shared_memory变量必须使用extern __shared__开头
- 并且定义为不确定大小的数组[]
- 12的单位是bytes,也就是可以安全存放3个float
- 变量放在函数外面和里面都一样
- 其指针由cuda调度器执行时赋值
4. static_shared_memory作为静态分配的共享内存
- 不加extern,以__shared__开头
- 定义时需要明确数组的大小
- 静态分配的地址比动态分配的地址低
5. 动态共享变量,无论定义多少个,地址都一样
6. 静态共享变量,定义几个地址随之叠加
7. 如果配置的各类共享内存总和大于sharedMemPerBlock,则核函数执行出错,Invalid argument
- 不同类型的静态共享变量定义,其内存划分并不一定是连续的
- 中间会有内存对齐策略,使得第一个和第二个变量之间可能存在空隙
- 因此你的变量之间如果存在空隙,可能小于全部大小的共享内存就会报错1.6 仿射变换:Warpaffine
目的:主要解决图像的缩放和平移来处理目标检测中常见的预处理行为。
- 1.warpaffine是对图像做平移缩放旋转变换进行综合统一描述的方法
- 2.同时也是一个很容易实现cuda并行加速的算法
- 3.在深度学习领域通常需要做预处理,比如CopyMakeBorder,RGB->BGR,减去均值除以标准差,BGRBGRBGR -> BBBGGGRRR
- 4.如果使用cuda进行并行加速实现,那么可以对整个预处理都进行统一,并且性能贼好
- 5.由于warpaffine是标准的矩阵映射坐标,并且可逆,所以逆变换就是其变换矩阵的逆矩阵
- 6.对于缩放和平移的变换矩阵,其有效自由度为3

1.7 Yolov5后处理
仅仅考虑使用核函数对Yolov5推理结果进行解码并恢复成框,掌握后处理所解决的问题的能力,以及对于性能的考虑。
- 对于后处理的代码研究,可以把PyTorch的数据通过转换成numpy后,tobytes再写到文件,然后再到c++中读取的方式,能够快速进行问题研究和排查,此时不需要tensorRT推理也可以做后处理研究。这也叫变量控制法
- 2.fast_nms_kernel会在极端情况少框,但是这个极端情况一般不会出现,实测几乎没有影响
- 3.fast nms在cuda实现上比较简单,高效,不用排序
yolov5的输出tensor(n x 85) 。其中85是cx, cy, width, height, objness, classification * 80
CPU解码:
- 避免多余的计算,需要知道有些数学运算需要的时间远超过很多if,for循环中用if减少数学运算是性能的关键
- nms的实现是可以优化的,例如remove flag并且预先分配内存,reserve对输出分配内存
多利用if判断 ,少几个计算
vector cpu_decode(float* predict, int rows, int cols, float confidence_threshold = 0.25f, float nms_threshold = 0.45f){
vector boxes;
int num_classes = cols - 5;
for(int i = 0; i < rows; ++i){
float* pitem = predict + i * cols;
float objness = pitem[4];
if(objness < confidence_threshold)
continue;
//这两个if判断会减少很多计算
float* pclass = pitem + 5;
int label = std::max_element(pclass, pclass + num_classes) - pclass;
float prob = pclass[label];
float confidence = prob * objness;
if(confidence < confidence_threshold)
continue;
float cx = pitem[0];
float cy = pitem[1];
float width = pitem[2];
float height = pitem[3];
float left = cx - width * 0.5;
float top = cy - height * 0.5;
float right = cx + width * 0.5;
float bottom = cy + height * 0.5;
boxes.emplace_back(left, top, right, bottom, confidence, (float)label);
}
std::sort(boxes.begin(), boxes.end(), [](Box& a, Box& b){return a.confidence > b.confidence;});
std::vector remove_flags(boxes.size());
std::vector box_result;
box_result.reserve(boxes.size());
auto iou = [](const Box& a, const Box& b){
float cross_left = std::max(a.left, b.left);
float cross_top = std::max(a.top, b.top);
float cross_right = std::min(a.right, b.right);
float cross_bottom = std::min(a.bottom, b.bottom);
float cross_area = std::max(0.0f, cross_right - cross_left) * std::max(0.0f, cross_bottom - cross_top);
float union_area = std::max(0.0f, a.right - a.left) * std::max(0.0f, a.bottom - a.top)
+ std::max(0.0f, b.right - b.left) * std::max(0.0f, b.bottom - b.top) - cross_area;
if(cross_area == 0 || union_area == 0) return 0.0f;
return cross_area / union_area;
};
for(int i = 0; i < boxes.size(); ++i){
if(remove_flags[i]) continue;
auto& ibox = boxes[i];
box_result.emplace_back(ibox);
for(int j = i + 1; j < boxes.size(); ++j){
if(remove_flags[j]) continue;
auto& jbox = boxes[j];
if(ibox.label == jbox.label){
// class matched
if(iou(ibox, jbox) >= nms_threshold)
remove_flags[j] = true;
}
}
}
return box_result;
}
- box_result.reserve(boxes.size()); 提升NMS速度
- if(ibox.label == jbox.label){ :类别框匹配,匹配相同的直接在remove_flags设为True,速度比删除快
GPU解码:
- 表示输出数量不确定的数组,用[count, box1, box2, box3]的方式,此时需要有最大数量限制
- 通过atomicAdd实现数组元素的加入,并返回索引
- 一样的,不必要的计算,尽量省掉
Thrust:cuda C的STL
vector gpu_decode(float* predict, int rows, int cols, float confidence_threshold = 0.25f, float nms_threshold = 0.45f){
vector box_result;
cudaStream_t stream = nullptr;
checkRuntime(cudaStreamCreate(&stream));
float* predict_device = nullptr;
float* output_device = nullptr;
float* output_host = nullptr;
int max_objects = 1000;
int NUM_BOX_ELEMENT = 7; // left, top, right, bottom, confidence, class, keepflag
checkRuntime(cudaMalloc(&predict_device, rows * cols * sizeof(float)));
checkRuntime(cudaMalloc(&output_device, sizeof(float) + max_objects * NUM_BOX_ELEMENT * sizeof(float)));
checkRuntime(cudaMallocHost(&output_host, sizeof(float) + max_objects * NUM_BOX_ELEMENT * sizeof(float)));
checkRuntime(cudaMemcpyAsync(predict_device, predict, rows * cols * sizeof(float), cudaMemcpyHostToDevice, stream));
decode_kernel_invoker(
predict_device, rows, cols - 5, confidence_threshold,
nms_threshold, nullptr, output_device, max_objects, NUM_BOX_ELEMENT, stream
);
checkRuntime(cudaMemcpyAsync(output_host, output_device,
sizeof(int) + max_objects * NUM_BOX_ELEMENT * sizeof(float),
cudaMemcpyDeviceToHost, stream
));
checkRuntime(cudaStreamSynchronize(stream));
int num_boxes = min((int)output_host[0], max_objects);
for(int i = 0; i < num_boxes; ++i){
float* ptr = output_host + 1 + NUM_BOX_ELEMENT * i;
int keep_flag = ptr[6];
if(keep_flag){
box_result.emplace_back(
ptr[0], ptr[1], ptr[2], ptr[3], ptr[4], (int)ptr[5]
);
}
}
checkRuntime(cudaStreamDestroy(stream));
checkRuntime(cudaFree(predict_device));
checkRuntime(cudaFree(output_device));
checkRuntime(cudaFreeHost(output_host));
return box_result;
}
1.8 error:
1. 若cuda核函数出错,由于他是异步的,立即执行cudaPeekAtLastError只会拿到对输入参数校验是否正确的状态,而不会拿到核函数是否执行正确的状态
2. 因此需要等待核函数执行完毕后,才真的知道当前核函数是否出错,一般通过设备同步或者流同步进行等待
3. 错误分为可恢复和不可恢复两种:
- 可恢复:
- 参数配置错误等,例如block越界(一般最大值是1024),shared memory大小超出范围(一般是48KB)
- 通过cudaGetLastError可以获取错误代码,同时把当前状态恢复为success
- 该错误在调用核函数后可以立即通过cudaGetLastError/cudaPeekAtLastError拿到
- 该错误在下一个函数调用的时候会覆盖
- 不可恢复:
- 核函数执行错误,例如访问越界等等异常
- 该错误则会传递到之后的所有cuda操作上
- 错误状态通常需要等到核函数执行完毕才能够拿到,也就是有可能在后续的任何流程中突然异常(因为是异步的)