Python自动化测试
第一章 Python自带的UnitTest单元测试框架
一、什么是框架
框架是由大佬开发或者专业的研发团队研发的技术骨架,框架是一个半成品,框架是对常用的功能,基础的代码进行封装的一个工具,这个工具对外提供了一些API,其他的开发者只需要调用框架的接口即可,可以省去很多代码的编写,从而提高工作效率。
二、什么是自动化工具
1、自动化框架
自动化测试大佬(测试领导等)对系统做自动化测试而封装的测试框架,其他的自动化测试工程师去调用自动化测试框架完成测试工作,简单来说,自动化框架就是大佬封装的一个对系统进行自动化测试的工具而已,测试人员只需要学会使用这个工具对系统进行测试即可。
2、自动化测试框架的作用
2.1 提高测试效率,降低维护成本
2.2 提高代码的复用性
2.3 减少人工的干预
3、unittest单元测试框架和自动化测试框架的关系
3.1 单元测试
单元测试主要是针对程序的最小单元进行测试,最小单元一般指的是程序的方法。
备注:在python中,为了细致性的区分方法和函数,将类以外的定义的方法叫做函数,类里面的方法叫做方法
3.2 自动化测试框架有哪些
自动化框架主要有:unittest(单元测试工具)、pom、ddt(数据驱动工具)、全局配置文件工具、selenium二次封装、assert(断言)、邮件发送等。简单来说,自动化测试框架包含了所有的测试工作所需的测试框架。
三、Python中pytest和unittest的对比
基于python的单元测试框架:unittest和pytest
基于java的单元测试框架:junit和testng
1、用例编写规则
1.1unittest
unittest提供了TestCases测试用例类、testsuits测试套件、testfixtures测试夹具、testLoader测试类加载器、testrunner测试运行器、但是必须遵循以下的规则:
(1)测试文件必须先导入unittest包:import unittest
(2)测试类必须继承unittest.TestCase
(3)测试方法必须以test开头
1.2pytest
pytest是基于python的第三测试框架,基于unittest的扩展框架,必须遵循以下的规则:
(1)测试文件名必须以test_开头或者___test结尾
(2)测试类的命名必须以Test开头
(3)测试方法必须以test_开头
2、测试用例的前置和后置
2.1 unittest
| 包名 | 方法 | 含义 |
|---|---|---|
| unittest | setUp()/tearDown() | 在每个执行用例之前或者用例之后执行1次,主要用于浏览器的打开和关闭 |
| unittest | setUpClass()/tearDownClass() | 在每个类运行之前后者运行之后运行一次,主要用于创建数据库链接、创建日志对象/关闭数据库连接,销毁日志对象的场景 |
| unittest | setUpModule()/setDownModule() | 在每个模块之前或者模块之前和之后执行一次 |
2.2 pytest
| 级别 | 方法 | 含义 |
|---|---|---|
| 方法级别 | setup_mothod()/reardown() | 在每个方法之前或者方法之后执行 |
| 函数级别 | setup_function()/teardown() | 在每个方法之前或者之后执行 |
| 类级别 | setup_class()/tearndown() | 在每个类之前后者之后执行 |
| 模块级别 | setup_module()/teardown() | 在每个模块之前或者之后执行 |
备注:还可以在函数之前加@pytest.fixture()实现以上的这些方法;pytest中将类中定义的方法叫做方法,在类之外叫做函数。
3、断言
3.1 unittest
- assertTrue(a):判断a是否为真
- assertEqual(a,b):判断a和b是否一致
- assertIn(a,b):判断a是否在b里面
- assertNotEqual(a,b):判断a!=b
- assertNotIn(a,b):判断a是否在b里面
- assertFalse(a):判断a是否为假
3.2 pytest
原生的assert
4、 测试报告
4.1 unittes
htmlesrunner:导包,下载py3支持包,导入即可使用
4.2 pytes
pytest-HTML、allure插件
5、失败重跑
5.1 unittest
没有
5.2 pytest
pytest-returnfailures插件
6、数据驱动
6.1 unittest
@ddt
6.2 pytest
@pytest.mark.parametrize装饰器
7、 用例分类执行
7.1 unittest
默认执行所有,也可以通过通过testsuite来执行部分用例,或者使用-k参数来执行
7.2 pytest
@pytest.mark
四、unittest框架主要工作
1、测试发现
从多个文件中收集并加载测试执行用例
2、测试执行
将测试用例按照一定的顺序和条件去执行
3、测试判断
用断言去判断测试用例的执行结果(实际结果)与预期结果是否一致
4、测试报告
统计测试测试进度,通过个数,失败个数等,形成测试报告
五、unittest中重要插件
1、TestCase
2、TestSuite
3、TestFixture
4、TestLoader
5、TestRunner
六、组件的使用(重点)
1、命名规范
1.1 模块的命名规范
项目名称_功能模块名称,例如:epr管理系统下的登录模块—>erp__login.py(python中一个py文件就可以看作一个模块)
1.2 类的命名规范
项目名称(首字母大写)_功能模块名称(首字母大写)。例如:epr管理系统下的登录模块类—>class Erp__Login(其中class是声明一个类)
1.3 测试方法的命名
严格遵顼test0x_功能模块名称(或者测试点)点方式来命名,因为unittest底层采用ASCII来匹配方法,如果不按照这种方式来命名,对于测试方法的执行顺序不好控制,以这样的方式来命名的话,严格按照0x的大小顺序执行测试方法。
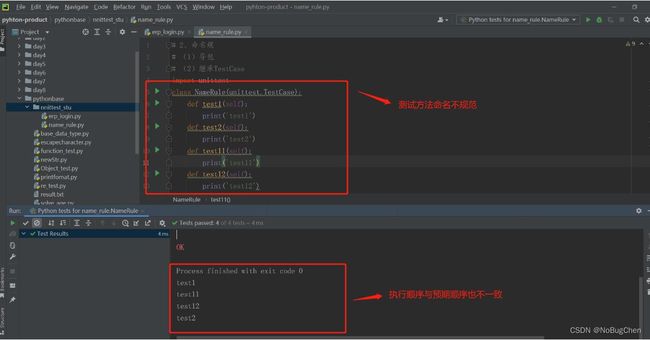
案例1:按照test1、test2、test11、test12的顺序执行测试方法
# 2、命名规
# (1)导包
# (2)继承TestCase
# 测试方法的执行应该按照:test1->test2->test11->test12的顺序执行
import unittest
class NameRule(unittest.TestCase):
def test1(self):
print('test1')
def test2(self):
print('test2')
def test11(self):
print('test11')
def test12(self):
print('test12')
#结果:与预期的执行顺序不一致
#Process finished with exit code 0
#test1
#test11
#test12
#test2
结果截图:
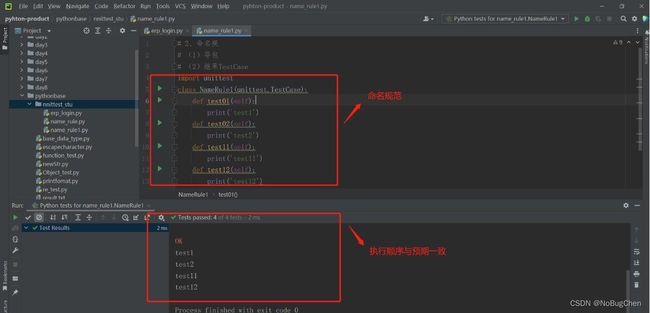
案例2:按照test1、test2、test11、test12的顺序执行测试方法
# 2、命名规
# (1)导包
# (2)继承TestCase
import unittest
class NameRule1(unittest.TestCase):
def test01(self):
print('test1')
def test02(self):
print('test2')
def test11(self):
print('test11')
def test12(self):
print('test12')
结果截图:
2、unittest.TestCase类的使用
新建的测试用例类继承TestCase类,这样需要进行测试的测试用类就可以使用TestCase的方法了。案例:erp关系系统登录和新增用户的两个模块的测试
# 1、TestCase的用法
# (1)导包
# (2)继承
import unittest
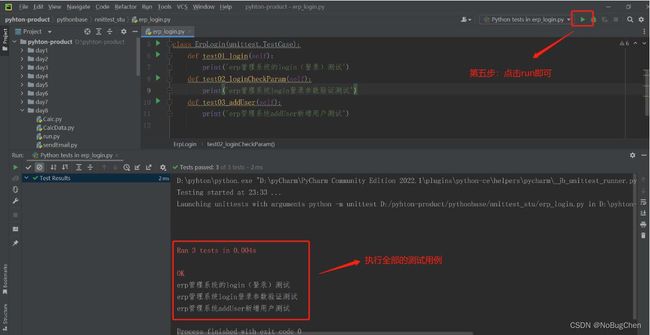
class ErpLogin(unittest.TestCase):#光标点击到这里,右键,点击run,执行下面的全部方法,也就是执行全部测试用例
def test01_login(self):# 光变点击到这里,右键,点击run,执行test01_login这个方法
print('erp管理系统的login(登录)测试')
def test02_loginCheckParam(self):
print('erp管理系统login登录参数验证测试')
def test03_addUser(self):
print('erp管理系统addUser新增用户测试')
2.1 测试用例的执行方式
测试用例的执行方法主要有两种,在pycharm中执行和在命令行中执行
2.2.1 在pycharm中执行
第一种方式:点击类左边的执行按钮或者将光标移动到类的左边,点击右键,点击run,执行类中全部的测试方法
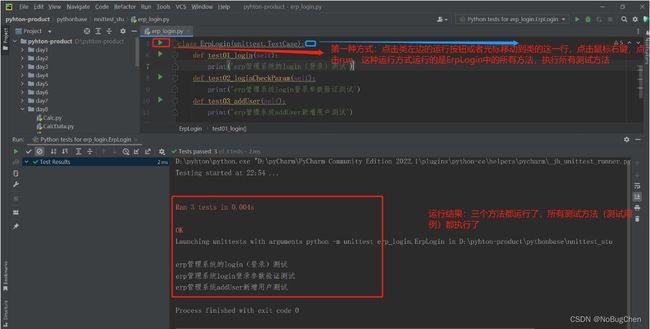
备注:这种方式本质上就是“运行一个类”,包括这个类中的所有方法
第二种运行方式:点击类中的某个方法的左边的执行按钮或者将光标移动到某个方法的左边,点击右键,点击run则执行的是该测试类的某个具体的方法。
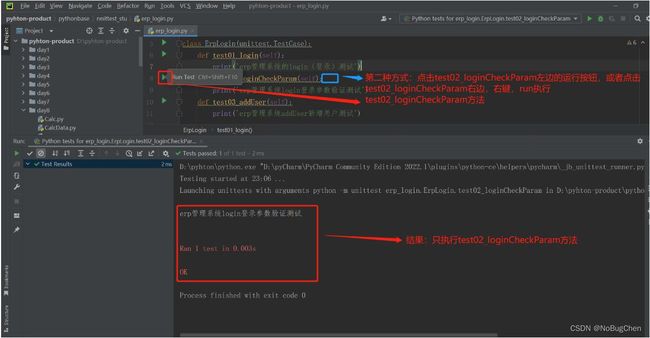
备注:这中运行方式的本质上就是运行测试类中指定的某个方法。
第三种运行方式:配置pycharm全局配置和临时配置,这种方式是运行测试类的全部测试方法
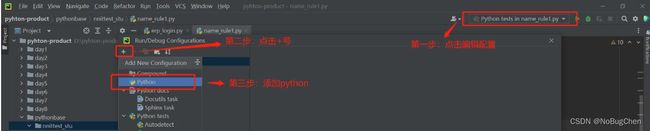
(1)临时配置:临时配置某个测试类的运行方式
第一步:配置运行

第二步:配置python test中的unittest

第三步:配置需要测试的脚本

第四步:配置好测试脚本之后,点击apply和ok即可

(2)全部配置(查询资料即可),这里不在叙述
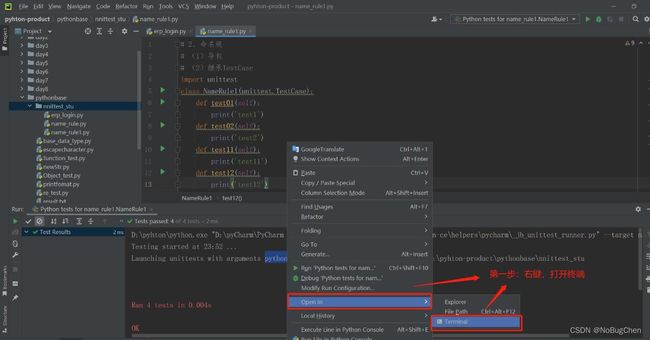
2.2.2 命令行的方式执行测试方法
(1)命令行的发现:使用python -m unittest 的命令来执行测试方法(Launching unittests with arguments python -m unittest name_rule1.NameRule1 in D:\pyhton-product\pythonbase\nnittest_stu**–>**使用D:\pyhton product\pythonbase\nnittest_stu中的参数python-m unittest name_rule1.NameRule1启动unittest)

第一步:右键,打开命令行终端
第二步:输入指令python -m unittest name_rule.NameRule1即可
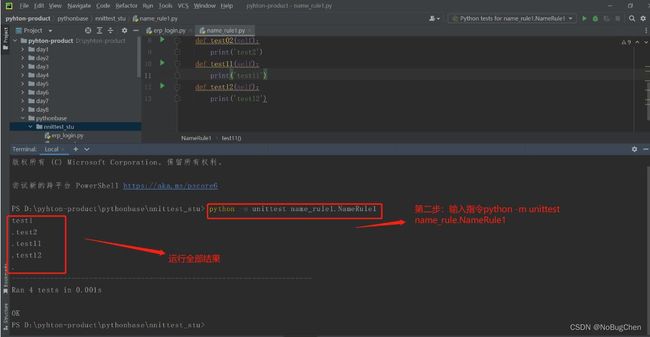
备注:命令行的方式本质上是使用python指令来运行python程序,可以通过python --help查看指令用法
(1)比如我想通过python指令的方式只允许NameRule1中的test01方法
#python --help
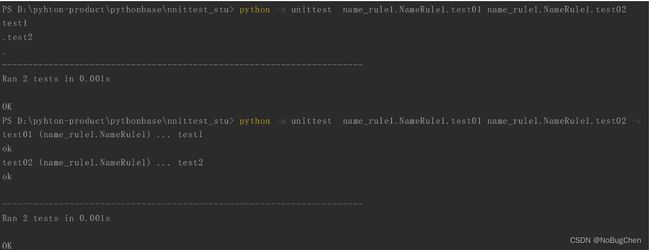
python -m unittest name_rule1.NameRule1.test01
(2)通过python指令运行NameRule1中的test01和test02方法,并打印详细信息
# -v 表示详细打印处运行结果
# -m 表示将py程序作为一个脚本来执行
# -k 表示匹配模式,用于直想运行测试类中的某些方法(两种匹配方式)
python -m unittest name_rule1.NameRule1.test01 name_rule1.NameRule1.test02 -v
(3)几个重要参数(-m,-v,-k)
| 参数 | 意义 |
|---|---|
| -m | 将python程序作为脚本运行 |
| -v | 打印运行详细信息 |
| -k | 匹配模式,有两种匹配模式,通配符和字符串 |
备注:统配符主要是继承Jenkins的时候用,为什么?所有的命令行的方式都是加非GUI的方式。postman:非GUI newman;Jmeter jmeter指令
(4)执行类似test的所有方法,并打印出详细运行信息
python -m unittest name_rule1.NameRule1 -k * -v
通配符:-k *_的方式进行匹配

字符串:-k 字符串(根据字符串进行模糊匹配),在类中顺序逐个寻找包含含字符串的方法名test01 例如,test01可以通过0、1、tst、tst01等字符串找到,但是不能通过10tset的方式找到,也就是倒序方式不能找到

2.2.3 使用unittest.main的方式运行
以模块的方式运行。在pycharm中配置main运行方式
注意:点击main左边的运行按钮运行不是main运行,是命令行的方式

配置pyhton的main运行


2.2 pycharm和命令行的联系
我个人的理解是这样的,pycharm中配置运行本质上就是调用python指令来完成的,在python中,有一个程序为python.exe,这个程序可以让我们使用python指令来运行我们py文件,因此pycharm只是将命令行的运行方式变成了界面运行,方便我们操作。main的运行方式是指就是通过python 模块名.py来完成的。
2.3 执行结果
- . 执行成功
- F 执行失败
- S 跳过:@unittest.skip()用在测试方法上,跳过不执行
- E 错误
# 2、命名规
# (1)导包
# (2)继承TestCase
import unittest
class NameRule1(unittest.TestCase):
# 执行成功
def test01(self):
print('test1')
# 执行错误
def test02(self):
print('test2')
raise Exception("执行错误")
# 执行跳过
@unittest.skip('跳过')
def test11(self):
print('test11')
# 执行失败
def test12(self):
self.assertTrue(0)#0不为True
print('test12')
if __name__ == '__main__':
print('=============main================')
unittest.main()

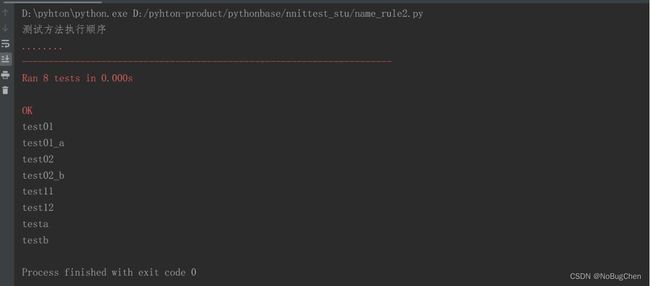
2.4 测试方法的执行顺序(没有深入研究,记住命名规范即可)
按照ASCII的方式执行测试方法,test01一定在test02之前运行。ASCII码按照testxx的方式进行读取测试方法,按照读取到的第一个字母的ASCII码的大小进行执行,如果ASCII码的值越小,ASCII小的优先执行。ASCII码规则:【0-9 A-Z a-z】A=65 a=97
# 2、命名规
# (1)导包
# (2)继承TestCase
import unittest
class NameRule(unittest.TestCase):
def testa(self):
print('testa')
def testb(self):
print('testb')
def test11(self):
print('test11')
def test12(self):
print('test12')
def test01(self):
print('test01')
def test02(self):
print('test02')
def test01_a(self):
print('test01_a')
def test02_b(self):
print('test02_b')
def t1(self):#没有按照命名规范进行命名,不执行
print('t1')
def t2(self):
print('t2')
if __name__ == '__main__':
print('测试方法执行顺序')
unittest.main()
执行结果
2.5unittest中main方法解析
参数解析(加粗的表示比较重要的几个参数)
| 参数名称 | 参数说明 |
|---|---|
| module=‘_ main _’ | 测试方法所在的路径,'_ main _'表示当前路径 |
| defaultTest=None | 待测试方法名称,默认是所有的测试方法(用列表的形式传参[‘类.测试方法’,[‘类.测试方法’,…]) |
| argv=None | 接收外部参数 |
| testRunner=None | 运行测试器,默认是TestTextRunner(文本测试运行器) |
| testLoader=loader.defaultTestLoader | 测试类加载器,默认测试类加载器为defaultTestLoader |
| exit=True | 是否在测试结束之后结束python程序 |
| verbosity=1 | 类似于命令行的-v 表示测试结束之后输出的结果是否详细,只有三个值:0,1,2 |
| failfast=None | 失败的时候是否结束测试 |
| catchbreak=None | |
| buffer=None | |
| warnings=None | |
| * | |
| tb_locals=False |
3、TestSuite的使用
3.1 TestSuite的作用
在unittest提供了TestSuite(测试套件)类,测试套件的主要功能是实现测试类里面需要执行测试方法,在测试套件中制定好了需要进行的测试方法,即可完成测试类中指定测试方法的执行,比如,在erp管理系统中,只完成登录模块参数检验和登录验证的测试。
# 1、TestCase的用法
# (1)导包
# (2)继承
import unittest
class ErpLogin1(unittest.TestCase):
def test01_login(self):
print('erp管理系统的login(登录)测试')
def test02_loginCheckParam(self):
print('erp管理系统login登录参数验证测试')
def test03_addUser(self):
print('erp管理系统addUser新增用户测试')
if __name__ == '__main__':
print('==========erp管理系统登录模块的验证===================')
# 只完成登录参数校验的验证测试和登录的测试
# 第一种方法,在main方法中指定需要测试测试方法
# unittest.main(defaultTest=['ErpLogin1.test02_loginCheckParam','ErpLogin1.test01_login'])
# 第二种方法 采用测试套件TestSuite
# testSuite = unittest.TestSuite()
# 添加需要测试的测试方法
# testSuite.addTest(test=ErpLogin1('test02_loginCheckParam'))#本质上就是testsuite来实现的
# testSuite.addTest(ErpLogin1('test01_login'))#这里使用的是方法名
# 这里也可以使用addTests()参数是可迭代对象,其实就是列表
# testSuite.addTests([ErpLogin1('test02_loginCheckParam'), ErpLogin1('test01_login')])
# 执行测试方法,将测试的结果使用文本的方式打印出来
# unittest.TextTestRunner().run(testSuite)
# 第三种方法,通过类加载器的方式来实现
# 获取测试套件
suite = unittest.TestSuite()
# 发现测试方法,并加载测试方法
testMotheds = unittest.defaultTestLoader.discover(start_dir=r'D:\pyhton-product\pythonbase\nnittest_stu',pattern='*_login1.py')
# 添加需要测试的方法
suite.addTests(testMotheds)
# 执行测试
unittest.main()
3.2 TestSuite常用方法
- addTest():添加一个测试方法,传递的参数是一个测试对象即可,例如ErpLogin1(‘test01_login’)
- addTests():添加多个测试方法,传递的参数是测试对象的列表,例如[ErpLogin1(‘test02_loginCheckParam’), ErpLogin1(‘test01_login’)]
3.3 TestSuite的运行
testTuite的本质就是作为unittest.TextTestRunner().run()的参数,unittest.TextTestRunner().run()对测试方法进行测试,需要的是一个测试套件作为参数,而测试套件则确定了要执行哪些测试方法。
3.4 执行测试方法中常用的方式
3.4.1 通过main方法来传递参数(通解)
其中比较重要的一个参数是defaultTest,指定需要加载测试方法有哪些,这样就可以实现一个或者多个方法的执行。
3.4.2 通过suite(测试套件)添加需要的测试方法(适用于一个测试类)
- suite = unittest.TestSuite() :获取测试套件
- suite.addTest()/suite.addTests(testObject):添加待测试方法对象,例如:ErpLogin1(‘test01_login’)(实例化了一个测试对象)
- unittest.TextTestRunner.run(suite):执行测试方法
3.4.3 使用默认类加载器的方式来加载并执行测试方法(适用于多个测试类)
- suite=unittest.testSuite():获取测试套件
- testMethods = unittest.defaultLoader.discover(start_dir,parten):发现测试方法(目录+模式,可以加载多个测试文件Test.py)*
- suite.addTests(testMethods):添加测试对象,原理和suite.addTest()一样
- unittest.main():执行测试方法
4、TestFixTure的使用(setxxx的方法一般被叫做夹具)
4.1 setUp()和tearDown()的使用(在每个方法之前或者之后执行一次)
- 适用场景:一般用于打开浏览器和关闭浏览器,简单来说就就是进行测试方法执行的时候,前置条件是什么,做完之后还要做哪些收尾工作。
- 导包:import unittest
- 继承:继承TestCase类
- 重写setUp和tearDown方法
- 运行测试方法:unittest.main(defaultTest=[])
案例:
import unittest
# 需求:在测试登录功能之前,必须先要打开浏览器,加载浏览器,关闭浏览器
# 打开浏览器和关闭浏览器是每一次登录之前就要做的事,因此在进行登录测试之前,
# 先打开浏览器,然后登录测试,关闭浏览器
class TestLogin(unittest.TestCase):
def setUp(self) -> None:
print('打开浏览器,加载浏览器')
def tearDown(self) -> None:
print('关闭浏览器')
def test01_login(self):
print('test01_login')
def test02_login2(self):
print('test02_login2')
if __name__ == '__main__':
print('==============main=================')
unittest.main(defaultTest=['TestLogin.test01_login', 'TestLogin.test02_login2'])
结果:
==============main=================
打开浏览器,加载浏览器
test01_login
关闭浏览器
打开浏览器,加载浏览器
test02_login2
关闭浏览器
..
----------------------------------------------------------------------
Ran 2 tests in 0.000s
4.2 setUpClass()和tearnDownClass()使用(在测试类之前或者之后执行一次)
-
适用场景:一般用于连接数据库和关闭数据库连接以及一些日志对象的销毁
-
导包:import unittest 和 需要导入的数据库连接类
-
继承:继承TestCase类
-
重写setUpClass和tearDownClass方法,必须在方法前加装饰器@classmethod
-
运行测试方法:unittest.main(defaultTest=[])
案例:
# database.py
class DataBase():
def link(self):
print('连接数据库')
def close(self):
print('关闭数据库')
import unittest
# 导入数据库连接类所在的包(自定义)
import database
# 需求:在测试登录功能之前,必须先要打开浏览器,加载浏览器,关闭浏览器
# 打开浏览器和关闭浏览器是每一次登录之前就要做的事,因此在进行登录测试之前,
# 先打开浏览器,然后登录测试,关闭浏览器
class TestLogin(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None:
db = database.DataBase()
db.link()
@classmethod
def tearDownClass(cls) -> None:
database.DataBase().close()
def setUp(self) -> None:
print('打开浏览器,加载浏览器')
def tearDown(self) -> None:
print('关闭浏览器')
def test01_login(self):
print('test01_login')
def test02_login2(self):
print('test02_login2')
if __name__ == '__main__':
print('==============main=================')
unittest.main(defaultTest=['TestLogin.test01_login', 'TestLogin.test02_login2'])
结果:
==============main=================
连接数据库
打开浏览器,加载浏览器
test01_login
关闭浏览器
打开浏览器,加载浏览器
test02_login2
关闭浏览器
关闭数据库
..
----------------------------------------------------------------------
Ran 2 tests in 0.000s
4.3 setUpModule()和tearDownModule()的使用(函数级别的,在模块之前或者之后执行一次)
在python中,所谓的模块指的就是一个py文件。setUpModule和setDownModule都是定义在木块中的函数,这个做个演示即可,使用的场景不是很多。因为测试用例一般是独立的,不可以相互关联。
案例:
# database.py
class DataBase():
def link(self):
print('连接数据库')
def close(self):
print('关闭数据库')
import unittest
import database
# 需求:在测试登录功能之前,必须先要打开浏览器,加载浏览器,关闭浏览器
# 打开浏览器和关闭浏览器是每一次登录之前就要做的事,因此在进行登录测试之前,
# 先打开浏览器,然后登录测试,关闭浏览器
def setUpModule():
print('setUpAndtearDown.py模块之前')
def tearDownModule():
print('setUpAndtearDown.py模块之后')
class TestLogin(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None:
db = database.DataBase()
db.link()
@classmethod
def tearDownClass(cls) -> None:
database.DataBase().close()
def setUp(self) -> None:
print('打开浏览器,加载浏览器')
def tearDown(self) -> None:
print('关闭浏览器')
def test01_login(self):
print('test01_login')
def test02_login2(self):
print('test02_login2')
if __name__ == '__main__':
print('==============main=================')
unittest.main(defaultTest=['TestLogin.test01_login', 'TestLogin.test02_login2'])
结果:
==============main=================
..
----------------------------------------------------------------------
Ran 2 tests in 0.000s
OK
setUpAndtearDown.py模块之前
连接数据库
打开浏览器,加载浏览器
test01_login
关闭浏览器
打开浏览器,加载浏览器
test02_login2
关闭浏览器
关闭数据库
setUpAndtearDown.py模块之后
Process finished with exit code 0
4.4 忽略测试用例
在执行一些测试用例的时候,我们可能会对一些测试用例进行忽略,不需要进行测试,在unittest中有两种忽略方式:无条件忽略和有条件忽略。
- @unittest.skip(des):参数为忽略的原因
- @unitest.skipIf():两个参数,第一个参数是忽略的条件,为真就忽略;第二个为什么忽略的描述。
- @unittest.skipUnless():和@unitest.skipIf()一样,只不过是为假的时候才会忽略。
备注:@unittest.skip(des)放在方法之前,表示测试方法跳过,忽略;@unittest.skip(des)放在模块上面,直接跳过整个模块
七、数据驱动
1、为什么要有数据驱动
在软件测试中,测试用例的数据往往都是写在excel表格中,而不是我们去拿着软件边想边测试,因此在进行测试用例的时候,我们需要将测试数据(测试用例)从excel中读取出来,然后让测试方法去执行我们写的测试用例。
2、驱动模式介绍
- 数据驱动:
- 关键字驱动:将核心业务逻辑封装成方法,然后直接调用方法
- 混合驱动模式:关键字+数据驱动——》市场主流
- 行为测试驱动:Lettuce
3、DDT
- DDT定义:data driver test,数据驱动测试点。特点:可以完美的和unittest结合使用,通过数据驱动,将我们写的测试用例读取出来,然后执行测试用例。
- DDT的使用:通过装饰器的形式来调用。
- 装饰器:完成某种特定功能的函数(就是java中的注解)
- 在python中的定义:以@开头,装饰器主要有两种,一种是类装饰器,另一种是函数装饰器。
4、DDT中的装饰器(重点)
- @ddt():类装饰器,声明当前类是ddt的框架
- @data():函数装饰器,用于给测试方法传递数据,其中*表示格式化传递的数据,如果传递的是列表(字典,元组)的嵌套,就会把列表(字典,元组)进行格式化
- @unpack():函数装饰器,将传输的数据进行解包,一般作用于元组tuple和列表list
- @file_data():函数装饰器,可以直接读取json和ymal文件
5、@data的使用
传值类型:@data可以传递的数据类型有:数字(float、int、bigint、double、compix)、字符串string、列表list、元组tuple、集合set
import unittest
from ddt import ddt, data
@ddt # 类装饰器,表示要使用ddt框架
class DataSend(unittest.TestCase):
# 传递数字
@data(10)
def test01_data_send_int(self, param1):
print(param1)
# 传递字符串
@data('string')
def test02_data_send_string(self, param1):
print(param1)
# 传递元组
@data((1, 2, 3))
def test03_data_send_tuple(self, param1):
print(param1)
# 传递列表
@data([4, 5, 6, 7])
def test04_data_send_list(self, param1):
print(param1)
# 传递字典
@data({'name': 'bugchen', 'age': 18})
def test05_data_send_dict(self, param1):
print(param1)
if __name__ == '__main__':
unittest.main()
# 结果:
# 10
# string
# (1, 2, 3)
# [4, 5, 6, 7]
# {'name': 'bugchen', 'age': 18}
传值个数:@data传值的个数为一个的时候,测试方法执行一次,传递多个值的时候,就执行多次,总的来说,传递几个值,测试方法就会执行几次
import unittest
from ddt import ddt, data
@ddt
class DataNums(unittest.TestCase):
@data(12)
def test01_one(self, param1):
print(param1)
@data(1, 2)
def test02_two(self, param1):
print(param1)
@data(['a'])
def test03_three(self, param1):
print(param1)
@data(['b'], ['b', 'c'])
def test04_four(self, param1):
print(param1)
if __name__ == '__main__':
unittest.main()
# 结果
# 12
# 1
# 2
# ['a']
# ['b']
# ['b', 'c']
6、@unpack的使用
从上面我们可以看出,虽然传递多个参数的时候,我们可以执行多次,但是当我们在测试方法中接收数据的时候,只能接收一种数据类型的参数,对于列表,元组这样的数据类型我们该怎么接收呢?总不能接收之后在处理吧!因此@unpack就是用来解包的,对于元组和类型,列表类型的参数,它可以解析成多个单个值,比如(1,2,3)解析之后就是1,2,3三个值,这个时候,测试方法需要三个参数来进行接收;[‘1’,‘2’,‘3’]经过解析之后就是1,2,3三个字符串,这个时候也需要三个参数进行接收,不然会报错,参数个数必须一一对应。
import unittest
from ddt import ddt, data, unpack
@ddt
class DataNums(unittest.TestCase):
@data([1, 2, 3]) # 数据类型是列表
@unpack # 解包 1,2 ,3需要三个参数接收
def test05(self,p1,p2,p3):#参数于解包后的参数个数对应
print(p1)
print(p2)
print(p3)
if __name__ == '__main__':
unittest.main()
# 结果
# 1
# 2
# 3
备注:使用@unpack需要注意
- 集合不能解包
- 如果是数字或者字符串不需要解包
- 列表可以解包
- 元组可以解包
- 字典可以解包,但是测试方法接收的值必须于字典的键一致
import unittest
from ddt import ddt, data, unpack
@ddt
class DataNums(unittest.TestCase):
@data({'name': 'bugchen', 'age': 18}, {'name': 'chen', 'age': 28})
@unpack # 因为字典中有两个键,因此参数需要用两个键来接收,并别键的名称一致
#def test06(self, p1, p2):#不一致,报错
# print(p1)
# print(p2)
def test06(self,name,age):#一致,运行成功
print(name)
print(age)
if __name__ == '__main__':
unittest.main()
# 结果
# OK
# bugchen
# 18
# chen
# 28
八、unittest实战
需求规格说明书:随机输入三个正整数个数,判断是否构成三角形,以及构成的什么边的三角形。(暂且不考虑正整数的范围)
测试需求:如果不能构成三角行,输出“不能构成三角形”;如果输入非法,提示“非法输入”;普通三角形用1表示,等腰三角形用2表示,等边三角形用3表示。
实战要求:编写测试用例,形成测试用例表,并从测试用例表中读取测试用例,执行测试用例,形成测试报告。
1、测试思路
1.1 等价类划分
1.1.1随机输入三个正整数个数
划分为两个等价类:三个正整数(有效)、三个非正整数(无效)
- 三个正整数: 1种
- 其中一个非正整数:小数、字符、负数、0 4种
1.1.2 判断是否构成三角形,以及构成的什么边的三角形
划分为两个等价类:构成和不构成
构成:普通,等腰,等边 5种
不构成:任意两边之和小于等于第三边 6种
2、编写测试用例(TriangleTestCase.xlsx)(暂且只写一部分)
| 测试编号 | 参数a | 参数b | 参数c | 预期结果 | 实际结果 | 是否通过 |
|---|---|---|---|---|---|---|
| 1 | 2 | 2 | 2 | 3 | ||
| 2 | 2.2 | 3 | 4 | 非法输入 | ||
| 3 | 5 | ’a‘ | 7 | 非法输入 | ||
| 4 | -23 | 45 | 34 | 非法输入 | ||
| 5 | 23 | 10 | 0 | 非法输入 | ||
| 6 | 5 | 12 | 13 | 1 | ||
| 7 | 39 | 39 | 40 | 2 | ||
| 8 | 20 | 15 | 15 | 2 | ||
| 9 | 17 | 23 | 23 | 2 | ||
| 10 | 30 | 30 | 30 | 3 | ||
| 11 | 17 | 17 | 34 | 不能构成三角形 | ||
| 12 | 50 | 100 | 50 | 不能构成三角形 | ||
| 13 | 300 | 150 | 150 | 不能构成三角形 | ||
| 14 | 700 | 500 | 1300 | 不能构成三角形 | ||
| 15 | 1800 | 56 | 29 | 不能构成三角形 | ||
| 16 | 90 | 170 | 90 | 不能构成三角形 |
3、python自动化思路
导入测试模块——》读取测试用例(数据驱动)——》编写测试方法——》执行测试用例——》形成测试报告——》自动发送测试报告给组长或者经理(暂且不做)
测试部分的代码如下:
# 测试模块,负责三角模块的测试
# 导入unittest测试单元
import xlrd
from xlutils import copy # 在写入excel表的时候,需要先拷贝再写入
import unittest
# 导入数据驱动
from ddt import ddt, data, unpack
# 导入待测试的测试用例数据的模块
from day9.data import TriangleData
# 导入需要测试的模块
from day9.function import triangle
@ddt # 声明使用ddt框架
class TestTriangle(unittest.TestCase):
# 获取TriangleData模块下的TriangleData类,并通过TriangleData获取测试用例数据
triangleData = TriangleData.TriangleData().triangleData
# print(triangleData)
@data(*triangleData) # 传入数据 *表示解析数据格式,解析成列表的格式
@unpack # 解包的数据类型为:列表、元组、字典
def test01_isTriangle(self, row, a, b, c, except_res):
t = triangle.Triangle()
# 执行测试用例,真实结果
real_res = t.isTriangle(a, b, c)
# 将执行的结果写入工作簿
write_isTriangle_result(row, real_res, except_res)
# 断言进行预期结果与真实结果的判断
self.assertEqual(except_res, real_res) # 注意,先传入预期结果,在传入实际结果
def write_isTriangle_result(row, real_res, except_res):
# 将实际结果和预期结果
is_pass = '否'
if except_res == real_res:
is_pass = '是'
# 将处理的结果写入cal_test表中
# 打开源文件,并保留源文件的数据格式
wb = xlrd.open_workbook(filename=r'D:\pyhton-product\day9\testCases\TriangleTestCase.xlsx',
encoding_override='utf-8')
# 复制原始的工作簿
c_wb = copy.copy(wb)
# 获取工作表
c_sheet = c_wb.get_sheet(0)
# 写入数据
c_sheet.write(row, 5, real_res)
c_sheet.write(row, 6, is_pass)
# 保存复制下来的表格
c_wb.save(r'D:\pyhton-product\day9\testCases\TriangleTestCase.xlsx')
# 这一部分用于执行测试用例和生成测试报告
# if __name__ == '__main__':
# unittest.main()
每个包的含义:
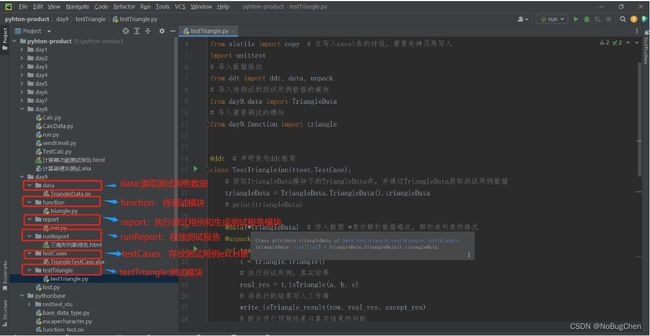
测试报告:

备注:源码可以私信我,我将源码给需要学习的小伙伴,希望能和喜欢软件测试的小伙伴一起交流自动化技术。