CasRel的Keras代码学习
论文:
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
是一个三元组抽取的方法,此方法简单明了,作者源码是Keras写的,值得学习。
模型结构如下:
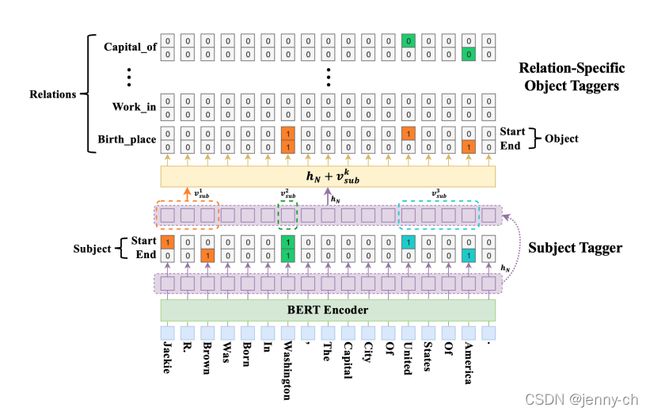
下面是主要的模型代码:
def E2EModel(bert_config_path, bert_checkpoint_path, LR, num_rels):
bert_model = load_trained_model_from_checkpoint(bert_config_path, bert_checkpoint_path, seq_len=None)
for l in bert_model.layers:
l.trainable = True
tokens_in = Input(shape=(None,))
segments_in = Input(shape=(None,))
gold_sub_heads_in = Input(shape=(None,))
gold_sub_tails_in = Input(shape=(None,))
sub_head_in = Input(shape=(1,))#这个维度为什么?
sub_tail_in = Input(shape=(1,))
gold_obj_heads_in = Input(shape=(None, num_rels))
gold_obj_tails_in = Input(shape=(None, num_rels))
tokens, segments, gold_sub_heads, gold_sub_tails, sub_head, sub_tail, gold_obj_heads, gold_obj_tails = tokens_in, segments_in, gold_sub_heads_in, gold_sub_tails_in, sub_head_in, sub_tail_in, gold_obj_heads_in, gold_obj_tails_in#注意这里复制了一下,方便后面使用,意义何在?
mask = Lambda(lambda x: K.cast(K.greater(K.expand_dims(x, 2), 0), 'float32'))(tokens)
#通过Lambda层创建mask,就不需要再输入mask了
tokens_feature = bert_model([tokens, segments])
pred_sub_heads = Dense(1, activation='sigmoid')(tokens_feature)
pred_sub_tails = Dense(1, activation='sigmoid')(tokens_feature)
subject_model = Model([tokens_in, segments_in], [pred_sub_heads, pred_sub_tails]) #第一步提取的subject,直接使用的指针网络
sub_head_feature = Lambda(seq_gather)([tokens_feature, sub_head])
sub_tail_feature = Lambda(seq_gather)([tokens_feature, sub_tail])
sub_feature = Average()([sub_head_feature, sub_tail_feature])
tokens_feature = Add()([tokens_feature, sub_feature])#h+v
pred_obj_heads = Dense(num_rels, activation='sigmoid')(tokens_feature)
pred_obj_tails = Dense(num_rels, activation='sigmoid')(tokens_feature)
object_model = Model([tokens_in, segments_in, sub_head_in, sub_tail_in], [pred_obj_heads, pred_obj_tails]) #然后就是object,也是指针网络
hbt_model = Model([tokens_in, segments_in, gold_sub_heads_in, gold_sub_tails_in, sub_head_in, sub_tail_in, gold_obj_heads_in, gold_obj_tails_in],
[pred_sub_heads, pred_sub_tails, pred_obj_heads, pred_obj_tails])#这个是整个模型
#后面是计算各种loss
gold_sub_heads = K.expand_dims(gold_sub_heads, 2)
gold_sub_tails = K.expand_dims(gold_sub_tails, 2)
sub_heads_loss = K.binary_crossentropy(gold_sub_heads, pred_sub_heads)
sub_heads_loss = K.sum(sub_heads_loss * mask) / K.sum(mask) # * 是对应位置相乘,最后得到一个数值
sub_tails_loss = K.binary_crossentropy(gold_sub_tails, pred_sub_tails)
sub_tails_loss = K.sum(sub_tails_loss * mask) / K.sum(mask)
obj_heads_loss = K.sum(K.binary_crossentropy(gold_obj_heads, pred_obj_heads), 2, keepdims=True)
obj_heads_loss = K.sum(obj_heads_loss * mask) / K.sum(mask)
obj_tails_loss = K.sum(K.binary_crossentropy(gold_obj_tails, pred_obj_tails), 2, keepdims=True)
obj_tails_loss = K.sum(obj_tails_loss * mask) / K.sum(mask)
loss = (sub_heads_loss + sub_tails_loss) + (obj_heads_loss + obj_tails_loss)
hbt_model.add_loss(loss)
hbt_model.compile(optimizer=Adam(LR))
hbt_model.summary()
return subject_model, object_model, hbt_model#返回三种model
代码对应模型结构,简洁明了。有些地方已经注释在代码里了。
存疑:
1、sub_head_in = Input(shape=(1,))维度为什么是(1,) ???
2、对输入层都复制一遍,是后面还会用到