MySQL 数据同步到 Redis 缓存方案
MySQL与Redis缓存的同步的两种方案主要有两种:
- 方案1:通过MySQL自动同步刷新Redis,MySQL触发器+UDF函数实现
- 方案2:解析MySQL的binlog实现,将数据库中的数据同步到Redis
1.UDF的实现方式
MySQL 数据库除了系统提供的内置函数外,还提供了用户自定义函数的功能UDF(User defined Function)。
1.1 为什么需要用UDF
既然MySQL本身提供了大量的函数,并且也支持定义函数,为什么我们还需要UDF呢?这主要基于以下几点:
1、UDF的兼容性很好,这得益于MySQL的UDF基本上没有变动
2、比存储方法具有更高的执行效率,并支持聚集函数
3、相比修改代码增加函数,更加方便简单
当然UDF也是有缺点的,这是因为UDF也处于mysqld的内存空间中,不谨慎的内存使用很容易导致mysqld crash掉。
1.2 UDF几个常用的API
name_init()
在执行SQL之前会被调用,主要做一些初始化的工作,比如分配后续用到的内存、初始化变量、检查参数是否合法等。
name_deinit()
在执行完SQL后调用,大多用于内存清理等工作。init和deinit这两个函数都是可选的
name()
UDF的主要处理函数,当为单次调用型时,可以处理每一行的数据;当为聚集函数时,则返回Group by后的聚集结果。
name_add()
在每个分组中每行调用
name_clear()
在每个分组之后调用
1.3 UDF方案下的数据同步过程
过程大致如下:
- 在MySQL中对要操作的数据设置触发器Trigger,监听操作
- 客户端(NodeServer)向MySQL中写入数据时,触发器会被触发,触发之后调用MySQL的UDF函数
- UDF函数可以把数据写入到Redis中,从而达到同步的效果

方案分析:
- 这种方案适合于读多写少,并且不存并发写的场景
- 因为MySQL触发器本身就会造成效率的降低,如果一个表经常被操作,这种方案显示是不合适的
2.解析binlog的实现方式
binlog 是归档日志,属于 MySQL Server 层的日志。可以实现主从复制和数据恢复数据恢复两个作用。当需要恢复数据时,可以取出某个时间范围内的binlog 进行重放恢复即可。
在介绍该方案之前我们先来介绍一下MySQL复制的原理,如下图所示:
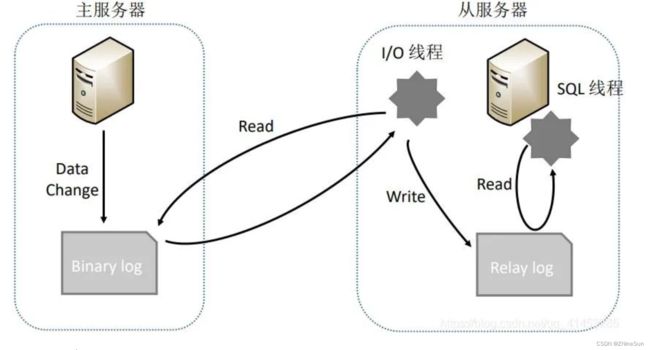
主服务器操作数据,并将数据写入Bin log
从服务器调用I/O线程读取主服务器的Bin log,并且写入到自己的Relay log(中继日志)中,再调用SQL线程从Relay log中解析数据,从而同步到自己的数据库中
更详细的主从复制原理可以移步此处:《mysql设置主从数据库的同步》
上面MySQL的整个复制流程可以总结为一句话,那就是:从服务器读取主服务器Bin log中的数据,从而同步到自己的数据库中
我们的方案也是如此,就是在概念上把主服务器改为MySQL,把从服务器改为Redis而已(如下图所示),当MySQL中有数据写入时,我们就解析MySQL的Bin log,然后将解析出来的数据写入到Redis中,从而达到同步的效果

我下面以实际开发的场景为例,给大家进行一个实例分析。
操作对象:云服务器数据库、本地数据库、redis缓存
其中云数据库与本地数据库是主从关系。云数据库作为主数据库主要提供写,本地数据库作为从数据库从主数据库中读取数据。
我们要达到的目的的则是本地数据库读取到数据之后,解析Bin log,然后将数据写入写入同步到Redis中,然后客户端从Redis读数据,整体流程如下图所示:

业务场景很简单,唯一的技术难度则是如何解析MySQL的Bin Log。
这需要对binlog文件以及MySQL有非常深入的理解,同时由于binlog存在Statement、Row、Mixedlevel多种形式,分析binlog实现同步的工作量是非常大的。
当然我们能够想到的很多公司也肯定想的到,并且准备了很多优秀的开源项目,其中比较推荐的则是阿里巴巴旗下的一款开源项目Canal,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)
具体的操作可移步:《基于Canal的Mysql&Redis数据同步实现》
但是在实际开发中可能有人会用下面的方案:
客户端有数据来了之后,先将其保存到Redis中,然后再同步到MySQL中
这种方案本身也是不安全/不可靠的,因此如果Redis存在短暂的宕机或失效,那么会丢失数据,具体原因可以参考:《如何保证数据库和缓存双写一致性》,因为这篇文章已经将数据同步一致性所有的场景分析的很详细了,所以本文便不做介绍了。