JUC 高并发编程(10):Fork/join 架构
Fork/join
概述
从JDK1.7开始,Java提供 Fork/Join框架 用于并行执行任务,它的思想就是将一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。
- 这种思想和MapReduce很像(
input --> split --> map --> reduce --> output)
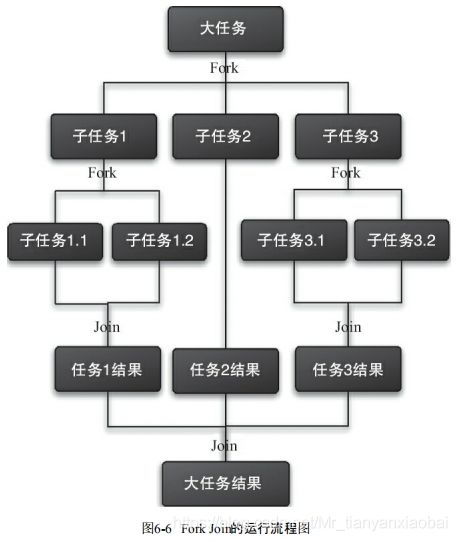
主要有两步:
- 第一、任务切分;
- 第二、结果合并
它的模型大致是这样的:线程池中的每个线程都有自己的工作队列
(PS:这一点和ThreadPoolExecutor不同,ThreadPoolExecutor是所有线程公用一个工作队列,所有线程都从这个工作队列中取任务),当自己队列中的任务都完成以后,会从其它线程的工作队列中偷一个任务执行,这样可以充分利用资源。
传统分支编程的弊端
分治的原理就是切割大任务成小任务来完成。看起来好像也不难实现啊!为什么专门弄一个新的框架呢?
我们先看一下,在不使用 Fork-Join 框架时,使用普通的线程池是怎么实现的。
- 我们往一个线程池提交了一个大任务,规定好任务切割的阀值。
- 由线程池中线程(假设是线程A)执行大任务,发现大任务的大小大于阀值,于是切割成两个子任务,并调用 submit() 提交到线程池,得到返回的子任务的 Future。
- 线程A就调用 返回的 Future 的 get() 方法阻塞等待子任务的执行结果。
- 池中的其他线程(除线程A外,线程A被阻塞)执行两个子任务,然后判断子任务的大小有没有超过阀值,如果超过,则按照步骤2继续切割,否则,才计算并返回结果。
咦,好像一切都很美好。真的吗?别忘了, 每一个切割任务的线程(如线程A)都被阻塞了,直到其子任务完成,才能继续往下运行 。
-
如果任务太大了,需要切割多次,那么就会有多个线程被阻塞,性能将会急速下降。更糟糕的是,如果你的线程池的线程数量是有上限的,极可能会造成池中所有线程被阻塞,线程池无法执行任务。
-
代码如下:
public class CountTest { public static void main(String[] args) throws InterruptedException, ExecutionException { ForkJoinPool forkJoinPool = new ForkJoinPool(); //创建一个计算任务,计算 由1加到12 CountTask countTask = new CountTask(1, 12); Future<Integer> future = forkJoinPool.submit(countTask); System.out.println("最终的计算结果:" + future.get()); } } class CountTask extends RecursiveTask<Integer> { private static final int THRESHOLD = 2; private int start; private int end; public CountTask(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; boolean canCompute = (end - start) <= THRESHOLD; //任务已经足够小,可以直接计算,并返回结果 if (canCompute) { for (int i = start; i <= end; i++) { sum += i; } System.out.println("执行计算任务,计算 " + start + "到 " + end + "的和 ,结果是:" + sum + " 执行此任务的线程:" + Thread.currentThread().getName()); return sum; } else { //任务过大,需要切割 System.out.println("任务过大,切割的任务: " + start + "加到 " + end + "的和 执行此任务的线程:" + Thread.currentThread().getName()); int middle = (start + end) / 2; //切割成两个子任务 CountTask leftTask = new CountTask(start, middle); CountTask rightTask = new CountTask(middle + 1, end); //执行子任务 leftTask.fork(); rightTask.fork(); //等待子任务的完成,并获取执行结果 invokeAll(leftTask,rightTask); // int leftResult = leftTask.join(); // int rightResult = rightTask.join(); //合并子任务 // sum = leftResult + rightResult; // return sum; return leftTask.join()+rightTask.join(); } } } -
运行结果:
切割的任务:1加到10 执行此任务的线程是 pool-1-thread-1 切割的任务:1加到5 执行此任务的线程是 pool-1-thread-2 切割的任务:6加到10 执行此任务的线程是 pool-1-thread-3池的线程只有三个,当任务分割了三次后,池中的线程也就都被阻塞了,无法再执行任何任务,一直卡着动不了。为了解决这个问题,工作窃取算法呼之欲出
工作窃取(work-stealing)算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:

在《Java 并发编程的艺术》对工作窃取算法的解释:
- 假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。
- 比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
具体步骤:
- Fork-Join 框架的线程池 ForkJoinPool 的任务分为“外部任务” 和 “内部任务”。
- “外部任务”是放在 ForkJoinPool 的全局队列里;
- ForkJoinPool 池中的每个线程都维护着一个内部队列,用于存放“内部任务”。
- 线程切割任务得到的子任务就会作为“内部任务”放到内部队列中。
- 当此线程要想要拿到子任务的计算结果时,先判断子任务有没有完成,如果没有完成,则再判断子任务有没有被其他线程“窃取”,一旦子任务被窃取了则去执行本线程“内部队列”的其他任务,或者扫描其他的任务队列,窃取任务,如果子任务没有被窃取,则由本线程来完成。
- 最后,当线程完成了其“内部任务”,处于空闲的状态时,就会去扫描其他的任务队列,窃取任务
工作窃取算法优缺点:
- 优点:充分利用线程进行并行计算,减少线程间的竞争
- 缺点:消耗更多系统资源,只有一个任务时会出现竞争
Fork-join 框架的使用
Fork/Join有三个核心类:
-
ForkJoinPool: 执行任务的线程池,继承了 AbstractExecutorService 类。
-
ForkJoinWorkerThread: 执行任务的工作线程(即ForkJoinPool线程池里的线程)。每个线程都维护着一个内部队列,用于存放“内部任务”。继承了 Thread 类。
-
ForkJoinTask: 一个用于ForkJoinPool的任务抽象类。实现了 Future 接口
因为 ForkJoinTask 比较复杂,抽象方法比较多,日常使用时一般不会继承ForkJoinTask来实现自定义的任务,而是继承ForkJoinTask的两个子类,实现 compute() 方法:RecursiveTask:子任务带返回结果时使用RecursiveAction: 子任务不带返回结果时使用
-
compute 方法的实现模式一般是:
if 任务足够小 直接返回结果 else 分割成N个子任务 依次调用每个子任务的fork方法执行子任务 依次调用每个子任务的join方法合并执行结果
Fork-Join 例子演示1 :利用 RecursiveTask 计算 1+2+…+12 的结果。
-
使用Fork/Join框架首先要考虑到的是如何分割任务,如果我们希望每个子任务最多执行两个数的相加,那么我们设置分割的阈值是2,由于是12个数字相加。同时,观察执行任务的线程名称,理解工作窃取算法的实现。
public class CountTest { public static void main(String[] args) throws InterruptedException, ExecutionException { ForkJoinPool forkJoinPool = new ForkJoinPool(); //创建一个计算任务,计算 由1加到12 CountTask countTask = new CountTask(1, 12); // 提交任务 Future<Integer> future = forkJoinPool.submit(countTask); System.out.println("最终的计算结果:" + future.get()); } } class CountTask extends RecursiveTask<Integer> { //设置阈值 private static final int THRESHOLD = 2; private int start; private int end; public CountTask(int start, int end) { this.start = start; this.end = end; } //实现compute 方法,将任务的具体操作进行实现 @Override protected Integer compute() { int sum = 0; //判断此时与阈值之间的关系 boolean canCompute = (end - start) <= THRESHOLD; //任务已经足够小,可以直接计算,并返回结果 if (canCompute) { for (int i = start; i <= end; i++) { sum += i; } System.out.println("执行计算任务,计算 " + start + "到 " + end + "的和 ,结果是:" + sum + " 执行此任务的线程:" + Thread.currentThread().getName()); } else { //任务过大,需要切割 System.out.println("任务过大,切割的任务: " + start + "加到 " + end + "的和 执行此任务的线程:" + Thread.currentThread().getName()); int middle = (start + end) / 2; //切割成两个子任务 CountTask leftTask = new CountTask(start, middle); CountTask rightTask = new CountTask(middle + 1, end); //执行子任务 leftTask.fork(); rightTask.fork(); //等待子任务的完成,并获取执行结果 int leftResult = leftTask.join(); int rightResult = rightTask.join(); //合并子任务 sum = leftResult + rightResult; } return sum; } } -
结果显示:
任务过大,切割的任务: 1加到 12的和 执行此任务的线程:ForkJoinPool-1-worker-1 任务过大,切割的任务: 7加到 12的和 执行此任务的线程:ForkJoinPool-1-worker-3 任务过大,切割的任务: 1加到 6的和 执行此任务的线程:ForkJoinPool-1-worker-2 执行计算任务,计算 7到 9的和 ,结果是:24 执行此任务的线程:ForkJoinPool-1-worker-3 执行计算任务,计算 1到 3的和 ,结果是:6 执行此任务的线程:ForkJoinPool-1-worker-1 执行计算任务,计算 4到 6的和 ,结果是:15 执行此任务的线程:ForkJoinPool-1-worker-1 执行计算任务,计算 10到 12的和 ,结果是:33 执行此任务的线程:ForkJoinPool-1-worker-3 最终的计算结果:78
Fork-Join 例子演示2 :利用 RecursiveAction 遍历指定目录(含子目录)找寻指定类型文件
- 代码如下
public class FindDirsFiles extends RecursiveAction{ /** * 当前任务需要搜寻的目录 */ private File path; public FindDirsFiles(File path) { this.path = path; } public static void main(String [] args){ try { // 用一个 ForkJoinPool 实例调度总任务 ForkJoinPool pool = new ForkJoinPool(); FindDirsFiles task = new FindDirsFiles(new File("D:/")); //异步调用 pool.execute(task); System.out.println("Task is Running......"); Thread.sleep(1); int otherWork = 0; for(int i=0;i<1000000;i++){ otherWork = otherWork+i; } System.out.println("Main Thread done sth......,otherWork=" + otherWork); //阻塞的方法 task.join(); System.out.println("Task end"); } catch (Exception e) { e.printStackTrace(); } } @Override protected void compute() { List<FindDirsFiles> subTasks = new ArrayList<>(); File[] files = path.listFiles(); if(files!=null) { for(File file:files) { if(file.isDirectory()) { subTasks.add(new FindDirsFiles(file)); }else { //遇到文件,检查 if(file.getAbsolutePath().endsWith("txt")) { System.out.println("文件:"+file.getAbsolutePath()); } } } if(!subTasks.isEmpty()) { for (FindDirsFiles subTask : invokeAll(subTasks)) { //等待子任务执行完成 subTask.join(); } } } } }
ForkJoinPool 的源码解析
ForkJoinPool 与其它的 ExecutorService 区别主要在于它使用 “工作窃取” 。
WorkQueue 是一个ForkJoinPool中的内部类,它是线程池中线程的工作队列的一个封装,支持任务窃取。
-
如果存在执行2个任务的子线程,就可以看成存在 A,B两个 WorkQueue在执行任务,A的任务执行完了,B的任务没执行完,那么A的WorkQueue就从B的WorkQueue的ForkJoinTask 数组中拿走了一部分尾部的任务来执行,可以合理的提高运行和计算效率。工作窃取得到基本原理
-
WorkQueue 的具体结构如下:

-
WorkQueue主要中有两个数组(array 与 owner):任务数组ForkJoinTask和工作线程数组ForkJoinWorkerThread
- ForkJoinTask 负责存放提交的任务
- ForkJoinWorkerThread 负责执行这些任务

任务提交
-
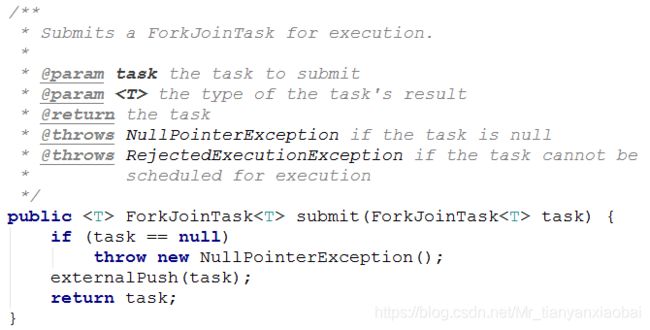
继承 RecursiveTask 则用 submit 提交任务,可以看到下面源代码中,会有一个返回值
-
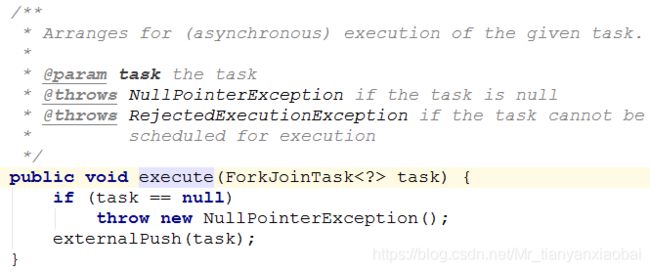
继承 RecursiveAction 的线程池 则利用 excute 提交任务:
-
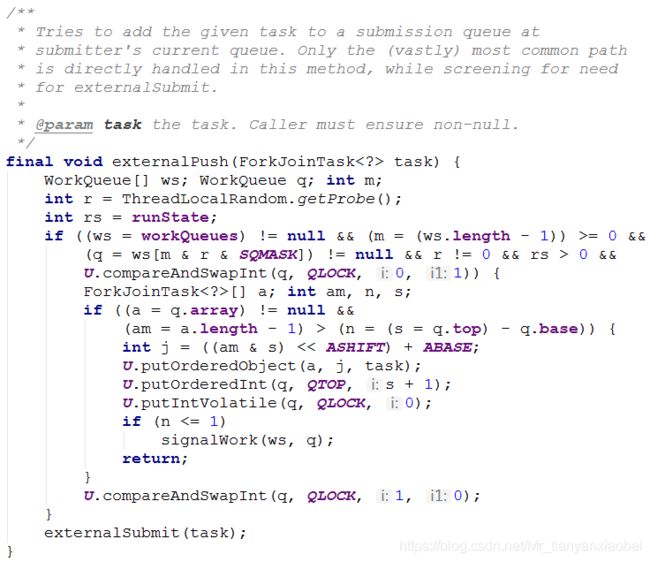
实际上,这两种方法都调用了 externalPush 将传入的任务提交到线程池
-
同样是提交任务,submit 会返回 ForkJoinTask ,而execute不会
-
任务提交给线程池以后,会将这个任务加入到当前提交者的任务队列中。
-
该任务就会提交到 任务数组 array 中
ForkJoinWorkerThread

从代码中我们可以清楚地看到,ForkJoinWorkThread 持有 ForkJoinPool 和ForkJoinPool.WorkQueue 的引用,以表明该线程属于哪个线程池,它的工作队列是哪个
ForkJoinTask
-
fork(): 把当前任务push 到当前线程的工作队列的头部,即希望它开始执行该任务

可以看到,如果是 ForkJoinWorkerThread 运行过程中fork(),则直接加入到它的工作队列中,否则,重新提交任务。 -
join() 和 invoke(): 主要作用是阻塞当前线程并等待获取结果

通过 doJoin 或者 doInvoke 可以得到任务当前的状态有:- 已完成(NORMAL):直接返回任务结果
- 被取消(CANCELLED):直接抛出CancllationException
- 信号(SIGNAL)
- 出现异常(EXCEPTIONAL):直接抛出对应异常
-
doJoin 和 doInvoke:
private int doJoin() { Thread t; ForkJoinWorkerThread w; int s; boolean completed; //线程是ForkJoinWorkerThread if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) { //任务执行完,直接返回 if ((s = status) < 0) return s; //没有执行完,取出任务执行 if ((w = (ForkJoinWorkerThread)t).unpushTask(this)) { try { //执行 completed = exec(); } catch (Throwable rex) { //记录异常信息,并设置状态为EXCEPTIONAL return setExceptionalCompletion(rex); } //顺利执行完 if (completed) return setCompletion(NORMAL); } return w.joinTask(this); }else //等待 return externalAwaitDone(); }