SQL语言
DDL语句引导词:CREATE(建立), ALTER(修改), DROP(撤销)
DML语句引导词:INSERT, DELETE, UPDATE, SELECT
DCL语句引导词:GRANT, REVOKE
建立数据库
CREATE TABLE语法形式:
CREATE TABLE 表名(列名 数据类型 [PRIMARY KEY | UNIQUE] [NOT NULL] [, 列名 数据类型 [NOT NULL], ...])[]表示其括起的内容可以省略,|表示其隔开的两项可取其一。
- PRIMARY KEY:主键约束,每个表只能创建一个主键约束。
- UNIQUE:唯一性约束(候选键),可以有多个唯一性约束。
- NOT NULL:非空约束,不允许有控制出现。
数据类型:
- char(n)
- varchar(n)
- int
- numeric(p, q)
- real
- date
- time
INSERT INTO简单语法形式:
INSERT INTO 表名[(列名 [, 列名] ...]) VALUES (值 [, 值], ...);查询
SELECT 列名 [[, 列名] ...]
FROM 表明
[ WHERE 检索条件];![]()
检索条件:and,or, not
通过DISTINCT使得没有重复的元组
结果排序:ORDER BY 列名 [asc | desc]
模糊查询:
- 列名 [not] like "字符串"
- % 匹配零个或多个字符
- _ 匹配任意单个字符
- \ 转义字符
多表联合查询
SELECT 列名 [[, 列名] ...]
FROM 表名1,表名2,...
WHERE 检索条件![]()
表更名与表别名
SELECT 列名 as 列别名 [[, 列名 as 列别名] ...]
FROM 表名1 as 表别名1,表名2 as 表别名2,...
WHERE 检索条件;增删改
INSERT INTO 表名 [(列名[, 列名] ...)]
VALUES (值[, 值] ...);/子查询
DELETE FROM 表名 [WHERE 条件表达式]
UPDATE 表名
SET 列名 = 表达式 | (子查询)
[[, 列名 = 表达式 | (子查询)] ...]
[WHERE 条件表达式]修正与撤销
ALTER TABLE tablename
[add {colname datatype, ...}] //增加新列
[drop {完整约束名}] //删除完整性约束
[modify {colname datatype, ..}] //修改列定义
DROP table 表名
DROP database 数据库名
(NOT)IN 子查询
表达式 [NOT] IN (子查询)θ some/θ all 子查询
表达式 θ some (子查询)
表达式 θ all (子查询)
//θ是比较运算符: <, >, >=, <=, =, <>
(NOT) EXISTS 子查询
[NOT] EXISTS 子查询
//不加NOT形式的EXIST谓词可以不用结果计算与聚集计算
//结果计算
SELECT 列名 | expr | agfunc(列名) [[, 列名 | expr | agfunc(列名)] ...]
FROM 表名1 [, 表名2 ...]
[WHERE 检索条件]
//expr可以是常量、列名、或有常量列名特殊函数及算数运算符构成的算数运式
//agfunc()是一些聚集函数
//聚集函数
COUNT() //个数
SUM() //求和
AVG() //求平均
MAX() //求最大
MIN() //求最小分组查询与分组过滤
//分组查询
SELECT 列名| expr | agfunc(列名) [[, 列名 | expr | agfunc(列名)] ...]
FROM 表名1 [, 表名2 ...]
[WHERE 检索条件]
[GROUP BY 分组条件]
//聚集函数不允许用于WHERE子句
//分组过滤
SELECT 列名| expr | agfunc(列名) [[, 列名 | expr | agfunc(列名)] ...]
FROM 表名1 [, 表名2 ...]
[WHERE 检索条件]
[GROUP BY 分组条件[HAVING 分组过滤条件]]关系代数操作
//交-并-差
子查询 {UNION [ALL] | INTERSECT [ALL] | EXCEPT [ALL] 子查询}
//带ALL保留重复元组
//空值
is [not] null //空值不能运算
//内连接、外连接
SELECT 列名 [[, 列名] ...]
FROM 表名1 [NATURAL]
[INNER | {LEFT | RIGHT | FULL} [OUTER]] JOIN 表名2
{ON 连接条件 | USING (COLNAME{, COLNAME ...})}
[WHERE 检索条件] ...;回顾SQL-SELECT
SELECT [ALL | DISTINCT] {* | expr [[AS] c_alias]{, ...}}
FROM tableref {, ...}
[WHERE search condition]
[GROUP BY column {, ...} [HAVING search_condition]]
| subquery [UNION [ALL] | INTERSECT [ALL] | EXCEPT [ALL]]
[CORRRESAPONDING [BY](colname {, ...})]subquery;
tableref ::== tablename [corr_name]
select statement ::== subquery [ORDER BY result_colunm [ASC | DESC]{, ...}]视图
//定义视图
CREATE VIEW view_name [(列名[, 列名]...)]
as 子查询 [with check option]
//撤销
DROP VIEW view_name数据库完整性
数据库完整性是指DBMS应保证的DB的一种特性,再任何情况下的正确性、有效性和一致性。
- DBMS允许用户定义一些完整性约束规则(用SQL-DDL来定义)
- 当DB更新操作时,DBMS自动按照完整性约束条件进行检查,以确保更新操作符合语义完整性
完整性约束条件的一般形式:
- Integrity Constraint ::= (O, P, A, R)
- O:数据集合:约束的对象
- P:谓词条件:什么样的约束
- A:触发条件:什么时候检查
- R:响应动作:不满足时怎么办
静态约束
- 列完整性-域完整性约束
- 表完整性-关系完整性约束
SQL语言实现约束的方法:CREATE TABLE、断言
CREATE TABLE table_name
((colname datatype [DEFAULT{default_constant | NULL}]
[col_constr {col_constr...}]
|, table_constr)
{,{colname datatype [DEFAULT{default_constant | NULL}]
[col_constr {col_constr...}]
|, table_constr
}}
);
//域约束 col_constr
{NOT NULL |
[CONSTRAINT constraintname]
{UNIQUE
| PRIMARY KEY
| CHECK(search_cond)
| REFERENCES tablename [(colname)]
[ON DELETE {CASCADE | SET NULL}]}}
//表约束 table_constr
[CONSTRAINT constraintname]
{UNIQUE (colname {, colname...})
| PRIMARY KEY (colname {, colname...})
| CHECK(search_cond)
| FOREIGN KEY (colname {, colname...})
REFERENCES tablename [(colname {, colname...})]
[ON DELETE CASCADE]}
//断言
create assertion check 动态完整性(触发器)
CREATE TRIGGER trigger_name BEFORE | AFTER
{INSERT | DELETE | UPDATE[OF colname{, colname...}]}
ON table_name [REFERENCING corr_name_def{, corr_name_def...}]
[FOR EACH ROW | FOR EACH STATEMENT] //对更新操作的每一条结果(前者),或者整个更新操作完成(后者)
[WHEN (search_condition)]
{statement
| BEGIN ATOMIC statement;{statement; ...}END}数据库安全性
DBMS的安全机制:
- 自主安全机制:存取控制。通过权限再用户之间的传递,使用户自主管理数据库安全性;
- 强制安全性机制:通过对数据和用户强制分类,使得不同类别用户能够访问不同类别的数据;
- 推断控制机制:防止通过历史信息,推断出不该被其知道的信息;防止通过公开信息(通常是一些聚集信息)推断出私密信息(个体信息),通常再一些由个体数据构成的公共数据库中此问题尤为重要;
- 数据加密存储机制:通过加密、解密保护数据,密钥、加密/解密方法与传输;
自主安全性
自主安全性是通过授权机制来实现的。
- DBMS允许用户定义一些安全性控制规则(用SQL-DCL来定义)
- 当有DB访问操作时,DBMS自动按照安全性控制规则进行检查,检查通过则允许访问,不通过则不允许访问
自主安全性访问原则
AccessRule :== (S, O, t, P)
- S:请求主体(用户)
- O:访问对象
- t:访问权利
- P:谓词
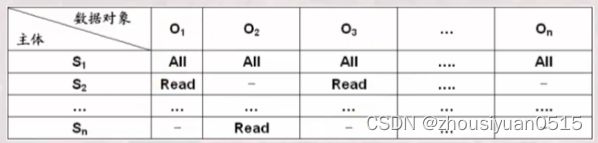
自主安全性的实现方式
存储矩阵
视图
通过视图可以限制用户对关系中某些数据项的存取。
CREATE EMPV1 AS SELECT * FROM EMPLOYEE
CREATE EMPV2 AS SELECT PNAME, D# FROM EMPLOYEE通过视图课将数据访问对象与谓词结合起来,限制用户对关系中某些元组的存取。
CREATE EMPV3 AS SELECT * FROM EMPLOYEE WHERE P# =: USERID
CREATE EMPV4 AS SELECT * FROM EMPLOYEE WHERE HEAD =: USERID授权命令
GRANT {all PRIVILEGES | priviledge{, priviledge...}}
ON [TABLE] tablename | viewname
TO {public | user-id{, user-id...}}
[WITH GRANT OPTION]
//user-id,某一个用户账户
//public,允许所有有效用户使用授予的权利
//priviledge,SELECT | INSERT | UPDATE | DELETE | ALL PRIVILEDGES
//WITH GRANT OPTION选项是允许被授权者传播这些权利强制安全性
强制安全性通过数据对象进行安全性分级绝密(Top Secret)、机密(Secret)、可信(Confidential)和无分类(Unclassfied)