利用kafka connect获取Oracle的DDL操作日志
1.登陆Oracle:
lsnrctl status 查看监听
lsnrctl start 开启监听
为了使在kafka的服务器上可以访问到oracle这台服务器的ip,需要在oracel的安装目录下(/data/oracle/product/11.2.0/db_1/network/admin)的listener.ora中添加ip监听

[oracle@172~]sqlplus / as sysdba
SQL>shutdown immediate
SQL>startup mount
SQL>alter database archivelog;
SQL>alter database open;
SQL>alter database add supplemental log data (all) columns;
SQL>conn username/password
创建我们要用的数据库:
SQL> create table test_user(id number(19) not null primary key, username varchar2(100),password varchar2(100),modified timestamp(0) default SYSTIMESTAMP not null);
创建自增序列,使主键自增:
SQL> create sequence test_user_seq start with 1 increment by 1;
为时间列创建一个索引:
SQL> create index test_modified_index on test_user (modified);
插入数据:
SQL> insert into test_user(username,password) values('tom','111');
1 row created.
SQL> insert into test_user(username,password) values('bob','222');
1 row created.
SQL> insert into test_user(username,password) values('jhon','333');
1 row created.
SQL> insert into test_user(username,password) values('rose','444');
1 row created.
SQL> insert into test_user (username,password) values('amy','555');
1 row created.
SQL> commit;
注意insert之后要commit一下,否则topic中读不到这条记录。
2.启动kafka
nohup kafka-server-start.sh \
/home/hadoop/apps/kafka_2.11-1.1.0/config/server.properties \
1>~/kafkalogs/kafka_std.log \
2>kafkalogs/kafka_err.log &
3.添加相关组件
1)、从https://github.com/erdemcer/kafka-connect-oracle下载整个项目,把整个项目mvn clean package成kafa-connect-oracle-1.0.jar。
2)、下载一个oracle的jdbc驱动jar—ojdbc7.jar
3)、将kafa-connect-oracle-1.0.jar and ojdbc7.jar放在kafka的安装包下的lib目录下,
4)、将github项目里面的config/OracleSourceConnector.properties文件拷贝到kafak/config
4.修改配置文件
配置kafka的config/connect-standalone.properties文件
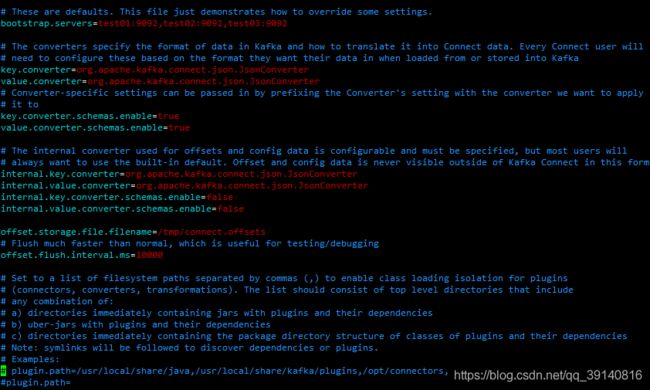
OracleSourceConnector.properties中配置
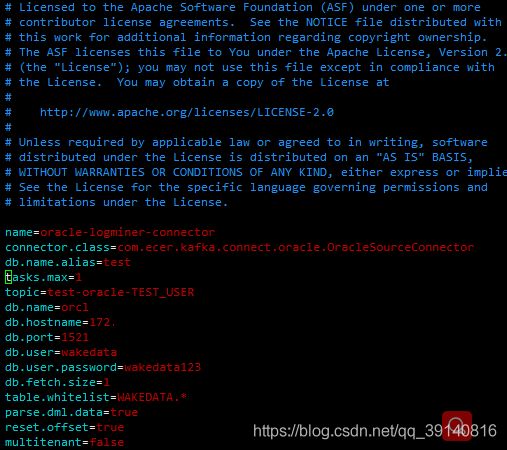
主要改变topic名字、db.name名字、db.port数据端口、db.user用户名、db.user.password密码、table.whitelist捕获的表
注意:tables.whitelist单表用用户名"."表名。用户名下全部表,用 用户名.*,这里的用户名和表名最好都大写。
3)、创建topic
kafka-topics.sh \
--create \
--zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 \
--replication-factor 3 \
--partitions 10 \
--topic kafka_test_TEST_USER
5、运行
启动connector
[oracle@hadoop kafka_2.11-1.1.0] bin/connect-standalone.sh config/connect-standalone.properties config/OracleSourceConnector.properties
启动consumer
[oracle@hadoop kafka_2.11-1.1.0]# bin/kafka-console-consumer.sh --bootstrap-server hadoop01:9092,hadoop02:9092,hadoop03:9092 --from-beginning --topic test-oracle-TEST_USER
oracle中插入数据
SQL> insert into test_user(username,password) values('wangyu','11111111111');
SQL>commit;
SQL>Delete from test_user where ID=81;
SQL>commit;
SQl>update test_user set username='jj',password='45' where id=22;
SQL>commit;
最后结果:
![]()
![]()
![]()
这种方式是基于日志的,可以做到实时响应DML操作,可以同时监听多个表,输入到kafka的数据以key:value的形式显示。
参考文档
https://github.com/erdemcer/kafka-connect-oracle
https://docs.oracle.com/cd/B19306_01/server.102/b14215/logminer.htm