{{π型人才培养计划}}Apache Spark RDD
Apache Spark RDD
一、概述
Apache Spark™ is a unified analytics engine for large-scale data processing.
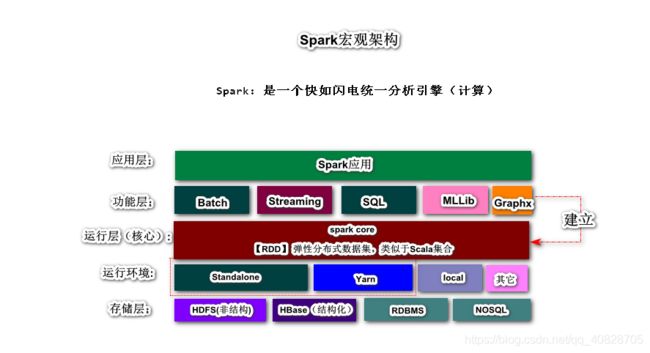
Spark是一个使用大数据处理的统一分析引擎(计算)
官网地址:http://spark.apache.org/

官方介绍: Lightning-fast unified analytics engine (Spark快如闪电统一分析引擎)
快如闪电
- Spark是基于内存式计算引擎。不同于Hadoop框架中MapReduce,在计算时将任务分为粗粒度MapTask和ReduceTask,Shuffle通常比较耗时,因为MapTask映射结果需要溢写到磁盘,ReduceTask需要通过网络拉取负责计算的分区数据。
- Spark计算任务可以划分细粒度Stage(阶段),每一个Stage都支持分布式并行计算。不同于MapReduce
- Spark在计算时,每一个阶段的计算中间结果都支持Cache(缓存),利用缓存进行结果复用和故障恢复
- Spark在底层进行大量优化,包括查询优化、物理引擎、内存管理等
统一
Spark框架提供了大数据处理的所有主流方案
- 批处理 Batch Processing(Spark RDD 弹性分布式数据集),代替MR
- 流处理 Stream Processing(Spark Streaming 和 Spark Structured Streaming),代替Storm
- 交互式查询支持, 类似于Hive(Spark SQL),代替Hive
- 机器学习 Machine Learning(Spark MLLib)
- 图形计算 NOSQL(Spark GraphX)
- 其它Spark第三方生态库
分析引擎
Spark作用类似于MapReduce,是一个分布式并行计算引擎
大数据需要解决三个问题:数据采集、存储、计算(Spark解决)
特点
- 高性能:Spark提供了一个先进的计算模型:DAG(Dirtected Acycle Graph有向无环图,计算任务),可以将计算任务划分多个Stage,每一个Stage都支持分布式并行计算。Spark底层进行了大量优化(内存管理、网络传输、数据序列化、物理引擎、任务管理等)
- 易用性:Spark应用可以基于多种编程语言开发(Scala【推荐】、Java、Python、R、SQL),提供了大概80个操作方法(高阶函数)可以极大简化大数据应用的开发
- 通用性:Spark拥有一个强大生态库,可以解决大数据的批、流、SQL、Graph、ML、AI、BI等一系列问题
- 运行环境:Spark应用可以运行在多种集群中环境中,如Yarn、Mesos、K8S、Cloud,或者运行Spark自带资源管理调度系统(Standalone),local模式,常用于测试开发
二、集群环境搭建
Standalone模式
Standalone模式(又称为独立模式集群),本质是一种类似于Hadoop Yarn
资源管理和调度系统,主要对分布式集群中计算资源(内存、CPU、网络、IO等一系列硬件)。Spark应用需要运行在Standalone集群中,进行并行计算
注意:搭建伪分布式集群
准备工作
CentOS7【内存:2G以上】
Hadoop版本2.9.2
Spark版本2.4.4
-
安装CentOS7
-
关闭防火墙
[root@localhost ~]# systemctl stop firewalld [root@localhost ~]# systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. -
修改主机名
[root@localhost ~]# vi /etc/hostname SparkOnStandalone -
配置网络
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 BOOTPROTO=static IPADDR=192.168.126.100 # 要根据VMNet8调整IP地址 NETMASK=255.255.255.0 ONBOOT=yes [root@localhost ~]# systemctl restart network -
配置主机名IP映射
[root@localhost ~]# vi /etc/hosts 192.168.126.100 SparkOnStandalone [root@localhost ~]# ping SparkOnStandalone PING SparkOnStandalone (192.168.126.100) 56(84) bytes of data. 64 bytes from SparkOnStandalone (192.168.126.100): icmp_seq=1 ttl=64 time=0.024 ms 64 bytes from SparkOnStandalone (192.168.126.100): icmp_seq=2 ttl=64 time=0.039 ms -
关闭虚拟机配置双网卡
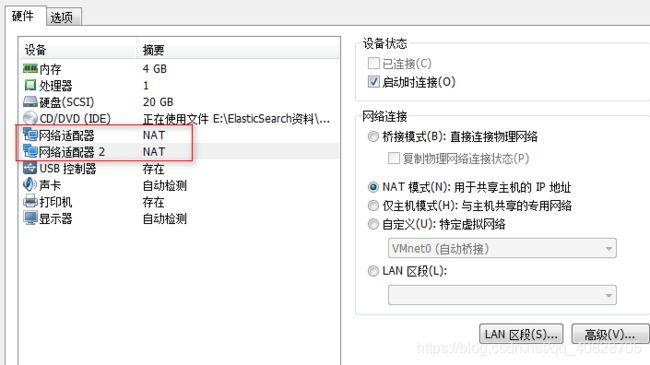
-
安装文本编辑器
vim[root@SparkOnStandalone ~]# yum install -y vim
安装Hadoop HDFS
-
安装JDK
[root@SparkOnStandalone ~]# rpm -ivh jdk-8u171-linux-x64.rpm 准备中... ################################# [100%] 正在升级/安装... 1:jdk1.8-2000:1.8.0_171-fcs ################################# [100%] Unpacking JAR files... tools.jar... plugin.jar... javaws.jar... deploy.jar... rt.jar... jsse.jar... charsets.jar... localedata.jar... -
配置SSH免密登陆
[root@SparkOnStandalone ~]# ssh-keygen -t rsa // 按四次回车 产生公私玥文件 [root@SparkOnStandalone ~]# ll -a .ssh/ 总用量 8 drwx------. 2 root root 38 11月 22 11:22 . dr-xr-x---. 3 root root 247 11月 22 11:22 .. -rw-------. 1 root root 1679 11月 22 11:22 id_rsa -rw-r--r--. 1 root root 404 11月 22 11:22 id_rsa.pub // 将当前主机的公钥文件中的内容拷贝指定主机的授权列表中 [root@SparkOnStandalone ~]# ssh-copy-id SparkOnStandalone [root@SparkOnStandalone ~]# ll -a .ssh/ 总用量 16 drwx------. 2 root root 80 11月 22 11:23 . dr-xr-x---. 3 root root 247 11月 22 11:22 .. -rw-------. 1 root root 404 11月 22 11:23 authorized_keys -rw-------. 1 root root 1679 11月 22 11:22 id_rsa -rw-r--r--. 1 root root 404 11月 22 11:22 id_rsa.pub -rw-r--r--. 1 root root 195 11月 22 11:23 known_hosts // 测试SSH免密登陆,如无需密码登陆 SSH免密登陆配置成功 如需要密码 重试配置 [root@SparkOnStandalone ~]# ssh SparkOnStandalone Last login: Fri Nov 22 11:17:58 2019 from 192.168.126.1 -
安装Hadoop
[root@SparkOnStandalone ~]# tar -zxf hadoop-2.9.2.tar.gz -C /usr [root@SparkOnStandalone usr]# cd /usr/hadoop-2.9.2/ [root@SparkOnStandalone hadoop-2.9.2]# ll 总用量 128 drwxr-xr-x. 2 501 dialout 194 11月 13 2018 bin drwxr-xr-x. 3 501 dialout 20 11月 13 2018 etc drwxr-xr-x. 2 501 dialout 106 11月 13 2018 include drwxr-xr-x. 3 501 dialout 20 11月 13 2018 lib drwxr-xr-x. 2 501 dialout 239 11月 13 2018 libexec -rw-r--r--. 1 501 dialout 106210 11月 13 2018 LICENSE.txt -rw-r--r--. 1 501 dialout 15917 11月 13 2018 NOTICE.txt -rw-r--r--. 1 501 dialout 1366 11月 13 2018 README.txt drwxr-xr-x. 3 501 dialout 4096 11月 13 2018 sbin drwxr-xr-x. 4 501 dialout 31 11月 13 2018 share -
对HDFS进行配置
core-site.xml[root@SparkOnStandalone hadoop-2.9.2]# vi etc/hadoop/core-site.xml <!--nn访问入口--> <property> <name>fs.defaultFS</name> <value>hdfs://SparkOnStandalone:9000</value> </property> <!--hdfs工作基础目录--> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop-2.9.2/hadoop-${user.name}</value> </property>hdfs-site.xml[root@SparkOnStandalone hadoop-2.9.2]# vi etc/hadoop/hdfs-site.xml <property> <name>dfs.replicationname> <value>1value> property> <property> <name>dfs.namenode.secondary.http-addressname> <value>SparkOnStandalone:50090value> property> <property> <name>dfs.datanode.max.xcieversname> <value>4096value> property> <property> <name>dfs.datanode.handler.countname> <value>6value> property>slaves[root@SparkOnStandalone hadoop-2.9.2]# vi etc/hadoop/slaves SparkOnStandalone -
配置Hadoop&JDK环境变量
[root@SparkOnStandalone ~]# vim /root/.bashrc HADOOP_HOME=/usr/hadoop-2.9.2 JAVA_HOME=/usr/java/latest PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin CLASSPATH=. export HADOOP_HOME export JAVA_HOME export PATH export CLASSPATH [root@SparkOnStandalone ~]# source /root/.bashrc -
启动Hadoop HDFS服务
# namenode在第一次启动时需要格式化 [root@SparkOnStandalone ~]# hdfs namenode -format # 启动HDFS服务 [root@SparkOnStandalone ~]# start-dfs.sh [root@SparkOnStandalone ~]# jps 11554 DataNode 11750 SecondaryNameNode 11433 NameNode 11998 Jps # 或者访问: http://192.168.126.100:50070
安装Spark
-
解压缩安装
[root@SparkOnStandalone ~]# tar -zxf spark-2.4.4-bin-without-hadoop.tgz -C /usr [root@SparkOnStandalone spark-2.4.4-bin-without-hadoop]# cd /usr [root@SparkOnStandalone usr]# mv spark-2.4.4-bin-without-hadoop/ spark-2.4.4 [root@SparkOnStandalone usr]# cd spark-2.4.4/ [root@SparkOnStandalone spark-2.4.4]# ll 总用量 100 drwxr-xr-x. 2 1000 1000 4096 8月 28 05:52 bin # Spark操作指令 drwxr-xr-x. 2 1000 1000 230 8月 28 05:52 conf # 配置文件 drwxr-xr-x. 5 1000 1000 50 8月 28 05:52 data # 数据 drwxr-xr-x. 4 1000 1000 29 8月 28 05:52 examples # 示例代码 drwxr-xr-x. 2 1000 1000 8192 8月 28 05:52 jars # 运行所需类库 drwxr-xr-x. 4 1000 1000 38 8月 28 05:52 kubernetes # spark k8s容器支持 -rw-r--r--. 1 1000 1000 21316 8月 28 05:52 LICENSE drwxr-xr-x. 2 1000 1000 4096 8月 28 05:52 licenses -rw-r--r--. 1 1000 1000 42919 8月 28 05:52 NOTICE drwxr-xr-x. 7 1000 1000 275 8月 28 05:52 python # spark python支持 drwxr-xr-x. 3 1000 1000 17 8月 28 05:52 R # r语言支持 -rw-r--r--. 1 1000 1000 3952 8月 28 05:52 README.md -rw-r--r--. 1 1000 1000 142 8月 28 05:52 RELEASE drwxr-xr-x. 2 1000 1000 4096 8月 28 05:52 sbin # spark系统管理相关的指令 drwxr-xr-x. 2 1000 1000 42 8月 28 05:52 yarn # spark对yarn集群集成整合目录 -
修改Spark配置文件
[root@SparkOnStandalone spark-2.4.4]# cd conf/ [root@SparkOnStandalone conf]# cp spark-defaults.conf.template spark-defaults.conf [root@SparkOnStandalone conf]# cp spark-env.sh.template spark-env.sh [root@SparkOnStandalone conf]# vim spark-env.sh SPARK_WORKER_INSTANCES=1 SPARK_MASTER_HOST=SparkOnStandalone SPARK_MASTER_PORT=7077 SPARK_WORKER_CORES=4 SPARK_WORKER_MEMORY=2g LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native SPARK_DIST_CLASSPATH=$(hadoop classpath) export SPARK_MASTER_HOST export SPARK_MASTER_PORT export SPARK_WORKER_CORES export SPARK_WORKER_MEMORY export LD_LIBRARY_PATH export SPARK_DIST_CLASSPATH export SPARK_WORKER_INSTANCES [root@SparkOnStandalone conf]# cp slaves.template slaves [root@SparkOnStandalone conf]# vim slaves SparkOnStandalone -
启动Spark服务
[root@SparkOnStandalone spark-2.4.4]# sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /usr/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.master.Master-1-SparkOnStandalone.out SparkOnStandalone: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-SparkOnStandalone.out # 验证方式一 [root@SparkOnStandalone spark-2.4.4]# jps 11554 DataNode 11750 SecondaryNameNode 19447 Jps 11433 NameNode 19179 Master # 独立模式集群 主服务 19291 Worker # 从服务 # 验证方式二 http://192.168.126.100:8080/

-
spark-shell 指令窗口,可以运行Spark应用
重要参数:
–master : 表示spark shell连接那种类型的集群环境
–total-executor-cores num 表示计算任务的JVM进程所需要占用的核心数量
--master MASTER_URL spark://host:port, mesos://host:port, yarn, k8s://https://host:port, or local (Default: local[*]). --total-executor-cores num[root@SparkOnStandalone spark-2.4.4]# bin/spark-shell --master spark://SparkOnStandalone:7077 --total-executor-cores 2 Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://SparkOnStandalone:4040 Spark context available as 'sc' (master = spark://SparkOnStandalone:7077, app id = app-20191122120954-0000). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.4 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171) Type in expressions to have them evaluated. Type :help for more information. scala> 1+1 // spark应用 统计单词出现的次数 scala> :paste // Entering paste mode (ctrl-D to finish) sc .textFile("hdfs://SparkOnStandalone:9000/text.txt") .flatMap(_.split(" ")) .map((_,1)) .groupByKey() .map(t => (t._1,t._2.size)) .saveAsTextFile("hdfs://SparkOnStandalone:9000/result") // Exiting paste mode, now interpreting.注意:Spark Shell会自动初始化两个核心对象
SparkContext和Spark Session计算结果:
[root@SparkOnStandalone ~]# hdfs dfs -cat /result/* (Kafka,1) (Hello,4) (Hadoop,3)
Yarn模式
SparkOnYarn, Yarn是 Hadoop框架提供的一个分布式资源管理和调度系统
ResourceManager
NodeManager
克隆虚拟机
对克隆机进行微调
# 修改主机名
[root@SparkOnYarn ~]# vim /etc/hostname
SparkOnYarn
# 修改ens33网卡的IP地址
[root@SparkOnYarn ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
192.168.126.101
# 修改主机名映射
192.168.126.101 SparkOnYarn
# 修改Hadoop core-site.xml\hdfs-site.xml\slaves主机名配置
[root@SparkOnYarn ~]# vim /usr/hadoop-2.9.2/etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://SparkOnYarn:9000</value>
</property>
[root@SparkOnYarn ~]# vim /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>SparkOnYarn:50090</value>
</property>
[root@SparkOnYarn ~]# vim /usr/hadoop-2.9.2/etc/hadoop/slaves
SparkOnYarn
# SSH免密登陆重新配置
[root@SparkOnYarn ~]# rm -rf .ssh/
[root@SparkOnYarn ~]# ssh-keygen -t rsa
[root@SparkOnYarn ~]# ssh-copy-id SparkOnYarn
# 删除克隆机上HDFS的历史数据
[root@SparkOnYarn ~]# rm -rf /usr/hadoop-2.9.2/hadoop-root/*
# 重新格式化HDFS
[root@SparkOnYarn ~]# hdfs namenode -format
# 启动HDFS的服务
[root@SparkOnYarn ~]# start-dfs.sh
安装Yarn集群
[root@SparkOnYarn ~]# vim /usr/hadoop-2.9.2/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>SparkOnYarnvalue>
property>
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
[root@SparkOnYarn ~]# cp /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml
[root@SparkOnYarn ~]# vim /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
启动Yarn集群
[root@SparkOnYarn ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-resourcemanager-SparkOnYarn.out
SparkOnYarn: starting nodemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-nodemanager-SparkOnYarn.out
[root@SparkOnYarn ~]# jps
8945 NodeManager
5811 DataNode
8807 ResourceManager
6008 SecondaryNameNode
5657 NameNode
9164 Jps
Spark&Yarn整合
[root@SparkOnYarn spark-2.4.4]# vim conf/spark-env.sh
HADOOP_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop
YARN_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop
SPARK_EXECUTOR_CORES=4
SPARK_EXECUTOR_MEMORY=1g
SPARK_DRIVER_MEMORY=1g
LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native
SPARK_DIST_CLASSPATH=$(hadoop classpath)
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs:///spark-logs"
export HADOOP_CONF_DIR
export YARN_CONF_DIR
export SPARK_EXECUTOR_CORES
export SPARK_DRIVER_MEMORY
export SPARK_EXECUTOR_MEMORY
export LD_LIBRARY_PATH
export SPARK_DIST_CLASSPATH
# 开启historyserver optional
export SPARK_HISTORY_OPTS
[root@SparkOnYarn spark-2.4.4]# vim conf/spark-defaults.conf
# 开启spark history server日志记录功能
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs:///spark-logs
[root@SparkOnYarn ~]# hdfs dfs -mkdir /spark-logs
[root@SparkOnYarn ~]# /usr/spark-2.4.4/sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /usr/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-SparkOnYarn.out
[root@SparkOnYarn ~]# jps
8945 NodeManager
5811 DataNode
11811 HistoryServer
8807 ResourceManager
6008 SecondaryNameNode
11880 Jps
5657 NameNode
测试运行
-
SparkShell
[root@SparkOnYarn spark-2.4.4]# bin/spark-shell --help --master yarn --total-executor-cores NUM 【不适用于Yarn】 --executor-cores NUM 每一个计算进程Cores数量 --num-executors NUM 计算进程数量 [root@SparkOnYarn spark-2.4.4]# bin/spark-shell --master yarn --executor-cores 2 --num-executors 2 Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 19/11/22 17:11:09 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME. Spark context Web UI available at http://SparkOnYarn:4040 Spark context available as 'sc' (master = yarn, app id = application_1574413099567_0001). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.4 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171) Type in expressions to have them evaluated. Type :help for more information. scala> :paste // Entering paste mode (ctrl-D to finish) sc .textFile("hdfs://SparkOnYarn:9000/text.txt") .flatMap(_.split(" ")) .map((_,1)) .groupByKey() .map(t => (t._1,t._2.size)) .saveAsTextFile("hdfs://SparkOnYarn:9000/result") // Exiting paste mode, now interpreting. -
远程提交运行
修改WordCount应用代码
package com.baizhi import org.apache.spark.{SparkConf, SparkContext} /** * spark版本的单词统计 */ object WordCountApplicationOnYarn { def main(args: Array[String]): Unit = { //1. 创建SparkContext,上下文对象提供spark应用运行环境信息 val conf = new SparkConf() .setAppName("WordCount Apps") .setMaster("yarn") // yarn集群模式 val sc = new SparkContext(conf) //2. 编写DAG计算任务 有向无环图(某逻辑开发 --》 多重计算 --》最终输出) val rdd = sc.textFile("hdfs://SparkOnYarn:9000/text.txt") val result = rdd .flatMap(line => line.split(" ")) .map(word => (word, 1L)) // (Hello,1L) .groupByKey() .map(t2 => (t2._1, t2._2.size)) result.saveAsTextFile("hdfs://SparkOnYarn:9000/result2") //3. 释放资源 sc.stop() } }重新打包
重新发布
[root@SparkOnYarn spark-2.4.4]# bin/spark-submit --master yarn --class com.baizhi.WordCountApplicationOnYarn --executor-cores 2 --num-executors 2 /root/spark-day1-1.0-SNAPSHOT.jar
三、Spark应用开发
创建工程导入依赖
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.4.4version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>4.0.1version>
<executions>
<execution>
<id>scala-compile-firstid>
<phase>process-resourcesphase>
<goals>
<goal>add-sourcegoal>
<goal>compilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
开发WordCount应用
package com.baizhi
import org.apache.spark.{SparkConf, SparkContext}
/**
* spark版本的单词统计
*/
object WordCountApplication {
def main(args: Array[String]): Unit = {
//1. 创建SparkContext,上下文对象提供spark应用运行环境信息
val conf = new SparkConf()
.setAppName("WordCount Apps")
.setMaster("spark://SparkOnStandalone:7077")
val sc = new SparkContext(conf)
//2. 编写DAG计算任务 有向无环图(某逻辑开发 --》 多重计算 --》最终输出)
val rdd = sc.textFile("hdfs://SparkOnStandalone:9000/text.txt")
val result = rdd
.flatMap(line => line.split(" "))
.map(word => (word, 1L)) // (Hello,1L)
.groupByKey()
.map(t2 => (t2._1, t2._2.size))
result.saveAsTextFile("hdfs://SparkOnStandalone:9000/result")
//3. 释放资源
sc.stop()
}
}
在Windows操作系统配置主机名映射
C:\Windows\System32\drivers\etc\HOSTS
192.168.126.100 SparkOnStandalone
将Spark应用打包集群运行(远程)
//1. 通过Maven Package插件将Spark应用 打成Jar包
//2. 将Jar包上传到虚拟机中
//3. 提交任务
[root@SparkOnStandalone spark-2.4.4]# bin/spark-submit --help
--master MASTER_URL # 使用spark集群环境
--class CLASS_NAME # spark应用入口类的全限定名
--total-executor-cores NUM # spark应用的计算进程占用核心数量Cores
如:
[root@SparkOnStandalone spark-2.4.4]# bin/spark-submit --master spark://SparkOnStandalone:7077 --class com.baizhi.WordCountApplication --total-executor-cores 2 /root/spark-day1-1.0-SNAPSHOT.jar
在Local本地模拟运行(本地)
package com.baizhi
import org.apache.spark.{SparkConf, SparkContext}
/**
* spark版本的单词统计
*/
object WordCountApplicationOnLocal {
def main(args: Array[String]): Unit = {
//1. 创建SparkContext,上下文对象提供spark应用运行环境信息
val conf = new SparkConf()
.setAppName("WordCount Apps")
.setMaster("local[*]") // local 本地模式 模拟Spark应用运行 [*] 当前计算机的所有核心 cores 6
val sc = new SparkContext(conf)
//2. 编写DAG计算任务 有向无环图(某逻辑开发 --》 多重计算 --》最终输出)
val rdd = sc.textFile("hdfs://SparkOnStandalone:9000/text.txt")
val result = rdd
.flatMap(line => line.split(" "))
.map(word => (word, 1L)) // (Hello,1L)
.groupByKey()
.map(t2 => (t2._1, t2._2.size))
result.saveAsTextFile("hdfs://SparkOnStandalone:9000/result")
//3. 释放资源
sc.stop()
}
}
org.apache.hadoop.security.AccessControlException解决方案:
- 在运行Spark应用时,添加虚拟机参数
-DHADOOP_USER_NAME=root
四、Spark架构篇
MapReduceOnYarn(回顾)
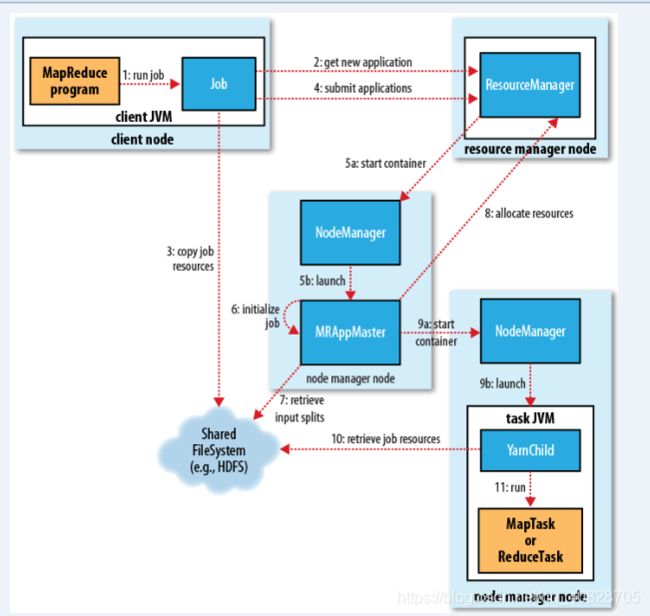
工作步骤
- 第一步:在ClientNode上,初始化JVM容器(RunJar),运行MapReduce应用,然后实例化Job对象
- 第二步:将Job对象,注册到Yarn集群的ResourceManager之上,返回一个ApplicationId
- 第三步:将Job对象的资源(任务的jar、配置文件、计算的数据切片信息等)提交到一个共享的文件系统(通常指的HDFS,大数据计算原则:移动计算而不移动数据)
- 第四步:正式的将MapReduce的Job提交到Yarn计算中运行(注意:此步骤后所有的操作都发生在Yarn集群)
- 第五、六步:Yarn集群的ResourceManager会在某空闲的NodeManager会加载一个JVM容器MRAppMaster(负责Job的监控和管理),并且对Job进行进一步的初始化
- 第七步: MRAppMaster会从共享的文件系统(HDFS)获取数据切片信息,(一个Splits —》 MapTask, ReduceTask【默认为1,或者手动设定】)
- 第八步:MRAppMaster会请求Yarn集群的ResourceManager分配相应单位的计算资源(JVM进程)
- 第九步:MRAppMaster会在ResourceManager分配的空闲的NodeManager上启动相应单位的计算进程(YarnChild)
- 第十、十一步:接下来YarnChild(Task JVM)会从共享的文件系统(HDFS)获取资源(任务jar包,计算数据),运行MapTask/ReduceTask
- 第十二步: 当任务运行结束后,释放资源
分析问题
- MapReduce任务分为粗粒度的MapTask和ReduceTask,并且计算针对于进程(JVM)的,并不能发挥多核CPU的优势
- MapReduce慢,MapTask映射的结果需要溢写在磁盘中存储,Reduce任务计算时需要通过网络从磁盘拉取负责计算分区数据,造成的大量资源开销
- MapReduce完成复杂的科学计算,可能需要将多个任务串联起来,多个任务的数据通过HDFS这样的共享文件系统进行共享(MR—> R1 —> MR2 —> R2 —>MR3 —>R3 …), 计算延迟较高。本来就很慢,串联更慢。
- MapReduce只能够进行Batch(大数据的批处理计算),不支持(Streaming,SQL【借助于Hive】、ML【借助于Mahout】等)
- MapReduce计算中间结果不支持缓存(Cache)
SparkOnStandalone架构
将基于Spark开发的应用打包,提交到Standalone集群中运行

工作步骤
- 第一步:在提交Spark应用时会初始化Driver(JVM进程),并且创建SparkContext
- 第二步:Driver会根据任务需要的资源信息,请求资源管理器(ClusterManager)分配计算计算
- 第三步:ClusterManager会根据将分配的计算资源反向注册给Driver
- 第四步:Driver端的DAGScheduler划分Stage,将一个复杂的计算任务肢解为若个小的任务,每一个Stage阶段都包含一个TaskSet
- 第五步:Driver端的TaskScheduler会根据阶段的划分,逐一提交Stage的TaskSet,运行在预支的计算节点。Spark计算节点在运行任务时,TaskSet中的每一个Task运行在Thread线程中,进行分布式并行计算。
- 第六步:当所有阶段的任务运行结束后,通过SparkContext释放占用的计算资源,通知ClusterManager回收
总结特点
- Spark可以将任务进行细粒度的拆分,每一个切分后的任务子集,都支持分布式并行计算。不同于MapReduce粗粒度的阶段划分
- Spark任务在运行时针对线程的,不同于MapReduce进程,能够充分发挥多核CPU计算优势
- Spark的Executor中有Cache缓冲区,可以将计算产生的中间结果进行缓存,便于重复计算和故障恢复。
- …
五、Spark Core之RDD
RDD(Resilent Distrutbed DataSet): 弹性分布式数据集,是Spark中最为核心的抽象,代表一个不可变,可分区,支持并行计算的数据集合。
RDD的创建
通过Scala(Seq)集合
package com.baizhi.datasource
import org.apache.spark.{SparkConf, SparkContext}
object CreateRDDWithCollection {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("rdd create").setMaster("local[3]")
val sc = new SparkContext(conf)
// 通过集合构建RDD
// 分区和任务并行度关系
/*
p0:
Hello Scala (Hello,1) (Scala,1) (Hello,1) (Spark,1)
Hello Spark
p1:
Hello Hello Hello
*/
// 方式1
// val rdd = sc.parallelize(List("Hello Scala","Hello Spark","Hello Hello Hello"),2)
// 方式2
val rdd = sc.makeRDD(List("Hello Scala","Hello Spark","Hello Hello Hello"),2)
rdd
.flatMap(_.split(" "))
.map((_,1))
.groupByKey() // shuffle
.map(t2 => (t2._1,t2._2.size))
.foreach(println)
sc.stop()
}
}
通过文件系统
-
Local
package com.baizhi.datasource import org.apache.spark.{SparkConf, SparkContext} object CreateRDDWithLocalFileSystem { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("rdd create").setMaster("local[3]") val sc = new SparkContext(conf) // 通过local fs构建RDD // 分区和任务并行度关系 //-------------------------------------------------------- // 方式1 // 返回值RDD[String: 一行记录] // val rdd = sc.textFile("file:///d://README.txt") // // rdd // .flatMap(_.split(" ")) // .map((_,1)) // .groupByKey() // shuffle // .map(t2 => (t2._1,t2._2.size)) // .foreach(println) //-------------------------------------------------------- // 方式2 // 返回值RDD(path,完整内容) val rdd = sc.wholeTextFiles("file:///d://README.txt") // rdd.foreach(t2 => println(t2._1 +"\t" + t2._2)) rdd .map(t2 => t2._2) // Tuple2 --> String .flatMap(wholeText => wholeText.split("\n")) // 文本 --> line .flatMap(line => line.split(" ")) .map((_,1)) .groupByKey() // shuffle .map(t2 => (t2._1, t2._2.size)) .foreach(println) sc.stop() } } -
HDFS
确保HDFS集群服务正常
package com.baizhi.datasource import org.apache.spark.{SparkConf, SparkContext} object CreateRDDWithHDFS { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("rdd create").setMaster("local[3]") val sc = new SparkContext(conf) // 通过local fs构建RDD // 分区和任务并行度关系 //-------------------------------------------------------- // 方式1 // 返回值RDD[String: 一行记录] // val rdd = sc.textFile("hdfs://SparkOnStandalone:9000/README.md") // // rdd // .flatMap(_.split(" ")) // .map((_, 1)) // .groupByKey() // shuffle // .map(t2 => (t2._1, t2._2.size)) // .foreach(println) //-------------------------------------------------------- // 方式2 // 返回值RDD(path,完整内容) val rdd = sc.wholeTextFiles("hdfs://SparkOnStandalone:9000/README.md") // rdd.foreach(t2 => println(t2._1 +"\t" + t2._2)) rdd .map(t2 => t2._2) // Tuple2 --> String .flatMap(wholeText => wholeText.split("\n")) // 文本 --> line .flatMap(line => line.split(" ")) .map((_, 1)) .groupByKey() // shuffle .map(t2 => (t2._1, t2._2.size)) .foreach(println) sc.stop() } }
通过RDBMS
通过MySQL数据库表构建Spark核心抽象RDD
user表—> RDD
package com.baizhi.datasource
import java.sql.DriverManager
import com.mysql.jdbc.Driver
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.io.{IntWritable, LongWritable}
import org.apache.hadoop.mapreduce.lib.db.{DBConfiguration, DBInputFormat}
import org.apache.spark.rdd.JdbcRDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 通过RDBMS创建RDD
*/
object CreateRDDWithRDBMS {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("rdd with rdbms")
val sc = new SparkContext(conf)
// 方法一
// m1(sc)
// 方法二
m2(sc)
sc.stop()
}
def m1(sc: SparkContext) = {
// 创建hadoop配置对象 DBInputFormat
val hadoopConf = new Configuration()
// 数据库的连接参数
hadoopConf.set(DBConfiguration.DRIVER_CLASS_PROPERTY, "com.mysql.jdbc.Driver")
hadoopConf.set(DBConfiguration.URL_PROPERTY, "jdbc:mysql://localhost:3306/hadoop")
hadoopConf.set(DBConfiguration.PASSWORD_PROPERTY, "1234")
hadoopConf.set(DBConfiguration.USERNAME_PROPERTY, "root")
hadoopConf.set(DBConfiguration.INPUT_QUERY, "select * from user ")
hadoopConf.set(DBConfiguration.INPUT_COUNT_QUERY, "select count(*) from user")
// 将自定义序列化对象定义配置对象中
hadoopConf.set(DBConfiguration.INPUT_CLASS_PROPERTY, "com.baizhi.datasource.User")
// 参数三:查询出来数据的序号 0~n 参数四:为value类型 extends DBWritable
val rdd = sc.newAPIHadoopRDD(hadoopConf, classOf[DBInputFormat[User]], classOf[LongWritable], classOf[User])
rdd.foreach(t2 => println(t2._1 + "\t" + t2._2.name + "\t" + t2._2.sex + "\t" + t2._2.id))
}
def m2(sc: SparkContext) = {
val rdd = new JdbcRDD(
sc,
() => {
//1. 加载驱动类
Class.forName("com.mysql.jdbc.Driver")
// classOf[Driver]
//2. 创建JDBC连接对象
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/hadoop", "root", "1234")
connection
},
"select * from user where id >= ? and id <= ?",
1,
4,
1,
rs => (rs.getInt("id"), rs.getString("name"), rs.getString("sex"))
)
rdd.foreach(t3 => println(t3._1 + "\t" + t3._2 + "\t" + t3._3))
}
}
总结:
- 方法一:使用的是Hadoop的InputFormat构建RDD,如果是其它的存储系统,只需要使用相应格式的InputFormat
- 方法二:使用Spark提供的JdbcRDD对象构建,但是有很大的局限性,必须使用范围查询,如果需要全表查询请使用方法一
通过HBase
通过HBase中的BigTable创建RDD时,准备工作:
- HDFS服务正常
- ZooKeeper服务正常
- HBase服务正常
3505 Jps 2337 SecondaryNameNode 1814 NameNode 2759 QuorumPeerMain 3047 HMaster 1929 DataNode 3215 HRegionServer
导入HBase集成依赖
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>1.4.10version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>1.4.10version>
dependency>
<dependency>
<groupId>com.google.protobufgroupId>
<artifactId>protobuf-javaartifactId>
<version>2.5.0version>
dependency>
开发应用
package com.baizhi.datasource
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, HConstants}
import org.apache.spark.{SparkConf, SparkContext}
/**
* 通过HBase创建RDD
*/
object CreateRDDWithHBase {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("rdd with rdbms")
val sc = new SparkContext(conf)
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set(HConstants.ZOOKEEPER_QUORUM, "HadoopNode00")
hbaseConf.set(HConstants.ZOOKEEPER_CLIENT_PORT, "2181")
hbaseConf.set(TableInputFormat.INPUT_TABLE, "baizhi:t_user")
// 操作多个列使用空格分隔
hbaseConf.set(TableInputFormat.SCAN_COLUMNS, "cf1:name cf1:pwd cf2:age cf2:salary")
val rdd = sc.newAPIHadoopRDD(
hbaseConf,
classOf[TableInputFormat], // 基于HBase数据输入格式
classOf[ImmutableBytesWritable],
classOf[Result]
)
rdd.foreach(t2 => {
val rowKey = t2._1
val result = t2._2 // result代表的是hbase中的一行记录
val name = Bytes.toString(result.getValue("cf1".getBytes(), "name".getBytes()))
val pwd = Bytes.toString(result.getValue("cf1".getBytes(), "pwd".getBytes()))
val age = Bytes.toString(result.getValue("cf2".getBytes(), "age".getBytes()))
val salary = Bytes.toString(result.getValue("cf2".getBytes(), "salary".getBytes()))
println(Bytes.toString(rowKey.get()) + "\t" + name + "\t" + pwd + "\t" + age + "\t" + salary)
})
sc.stop()
}
}
远程运行依赖问题
发现问题
在集群中运行Spark应用时,发现找不到第三方的依赖,如图所示:
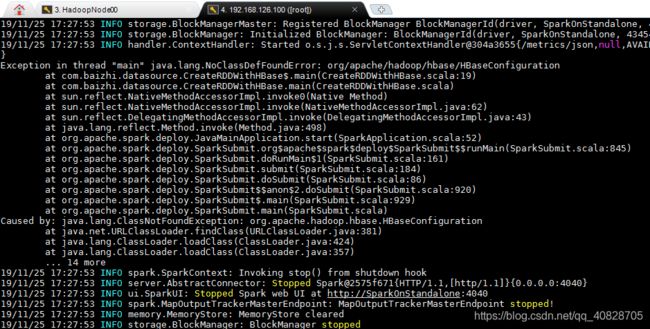
解决方法
-
在对spark应用打包时,将第三方依赖加入到应用中【推荐】
使用Maven的打包插件,
maven-assembly-plugin<build> <plugins> <plugin> <artifactId>maven-assembly-pluginartifactId> <configuration> <archive> <manifest> <mainClass>com.baizhi.datasource.CreateRDDWithHBasemainClass> manifest> <manifestEntries> <Class-Path>.Class-Path> manifestEntries> archive> <descriptorRefs> <descriptorRef>jar-with-dependenciesdescriptorRef> descriptorRefs> configuration> <executions> <execution> <id>make-assemblyid> <phase>packagephase> <goals> <goal>singlegoal> goals> execution> executions> plugin> plugins> build>

-
将第三方依赖,提前拷贝到Spark集群中每一个计算节点【不太常用】
# 1. 将第三方依赖的jar包上传到集群计算节点 [root@SparkOnStandalone spark-2.4.4]# mkdir 3rdLib [root@SparkOnStandalone spark-2.4.4]# cp /root/mysql-connector-java-5.1.47.jar /usr/spark-2.4.4/3rdLib/ # 2. 通知Spark在运行任务时,使用加载第三方的Jar目录 spark.executor.extraClassPath=/usr/spark-2.4.4/3rdLib/* spark.driver.extraClassPath=/usr/spark-2.4.4/3rdLib/*注意:MySQL必须开启远程访问,默认只允许本机访问
六、RDD实现原理(面试重点)
Spark架构
回顾RDD概念:RDD(弹性分布式数据集),是Spark中最为核心的抽象,代表的是不可变,可分区,支持容错并行计算的分布式数据集。
创建方式:
- scala的集合(Seq)
- 文件系统(Local和HDFS)
- 通过RDBMS(MySQL)
- 通过HBase
运行时依赖:
- 将第三方的依赖打包到Spark应用,完整JAR包
RDD的血统(lineage)
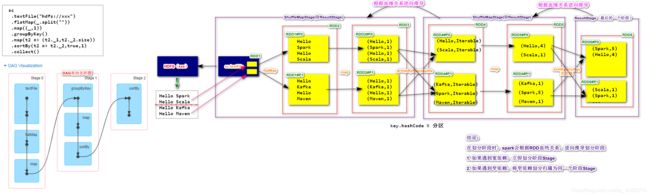
分析:WordCount Spark 应用
sc
.textFile("hdfs://SparkOnStandalone:9000/text.txt") // 通过HDFS初始化RDD
.flatMap(_.split(" ")) // RDD1 ---> RDD2(flatMap)
.map((_,1)) // RDD2 ---> RDD3(map)
.groupByKey() // RDD3 ---> RDD4(groupoByKey)
.map(t2 =>(t2._1,t2._2.size)) // RDD4 ---> RDD5(map)
Spark应用中,进行转换操作的RDD存在血统(lineage,血缘)依赖关系。RDD的血统依赖关系分为了NarrowDependency(窄依赖)和WidthDependency(宽依赖)。Spark在根据转换算子(高阶函数)逆向推导出来所有的Stage,每一个Stage会实现本地计算,任务的并行度和Stage分区一一对应的,大数据计算的特点尽可能较少网络传输。
窄依赖 (Narrow)
父RDD的一个分区只能被一个子RDD所使用
1:1多个父RDD的分区对应一个子RDD
n:1
宽依赖(Width)
- 一个父RDD的分区可以被多个子RDD的所使用
1:N
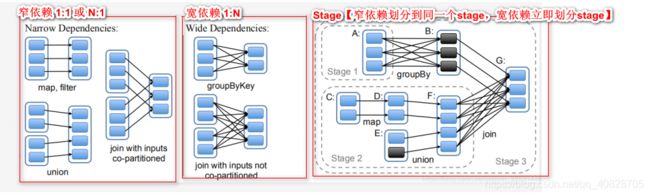
RDD原理剖析
总结如下:
- Spark RDD存在血统(lineage 父RDD—> 子RDD)关系,分为窄(Narrow)和宽(Width)依赖
- Spark运行时,会找到最后的一个RDD反向推导划分Stage;如果是窄依赖,则将RDD划分同一个Stage,如果是宽依赖,则立即划分产生新的Stage
- 对于每一个Stage,都包含了一个TaskSet(任务集); TaskSet中的Task的数量和分区数量一样的(1:1);Spark在进行计算时,逐一提交Stage
- Stage中的TaskSet在提交时,会以一种负载均衡方式提交给多个计算节点实现并行计算
Spark任务提交源码剖析【重点】
流程: ① 提交任务 —> ②划分阶段 —> ③ 封装TaskSet —> ④ 提交TaskSet
# 第一步:
SparkContext # runJob // spark应用的运行入口
dagScheduler.runJob
# 第二步:
DAGScheduler # runJob
submitJob // 提交任务
# 第三步:
DAGScheduler # submitJob
eventProcessLoop # post(JobSubmitted) // 将提交任务的事件 存放到事件处理器中
# 第四步:
DAGSchedulerEventProcessLoop # onReceive(Event) // DAG调用器接受一个事件,并对事件进行处理
doOnReceive(event)
# 第五步:
DAGSchedulerEventProcessLoop # doOnReceive(event)
// scala样例类的模式匹配 匹配到第一个case语句
case JobSubmitted => dagScheduler.handleJobSubmitted() // 处理任务提交的事件
# 第六步:
DAGScheduler # handleJobSubmitted
var finalStage: ResultStage = null // 最终(最后一个)Stage
// 通过finalRDD(最后一个RDD)创建ResultStage
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
// 最后一行 提交最后一个阶段
submitStage(finalStage)
# 第七步:
DAGScheduler # submitStage(finalStage)
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id) // 获取当前stage的父Stage【重点,宽窄依赖】
logDebug("missing: " + missing)
if (missing.isEmpty) { // 判断父stage是否为空,如果为空,表示到血统最顶端,则开始进行阶段提交
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get) // 提交当前阶段的TaskSet
} else { // 判断父stage是否为空,如果不为空,则通过递归方式,继续寻找父Stage
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
# getMissingParentStages(stage) // 根据依赖类型不同,划分stage
// 如果是 ShuffleDependency【宽依赖】 则创建ShuffleMapStage划分阶段
// 如果是 NarrrowDependency【窄依赖】 则将窄依赖的RDD存放到stack,等待后续访问
for (dep <- rdd.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) {
missing += mapStage
}
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
# 第八步:
DAGScheduler # submitMissingTasks(stage, jobId.get) // 通过DAGScheduler逐一提交划分好的阶段
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage => // 根据stage类型不同,封装不同的Task实例,并且Task数量由当前stage的分区数量决定
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
}
// 首先封装了TaskSet(tasks.toArray) 将上面的Seq[Task]转为定长数组 封装到TaskSet中
// taskScheduler.submitTasks(taskSet)
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
RDD的容错机制
RDD支持高度容错,容错机制分为三种:
重新计算【默认策略】
指Spark RDD在进行计算时,可能因为意外的情况导致计算没有正确完成,则会触发RDD容错处理。
- 如果是窄依赖,只需要计算当前未完成的分区即可
- 如果是宽依赖,父RDD的所有分区都需要进行重新计算(不可避免的会造成多余计算)
Cache(缓存)
Spark RDD在进行计算时,可以将RDD的结果显式缓存到内存(memory)或者磁盘(disk)中。通常情况下,会将宽依赖的父RDD进行缓存
使用方法:
package com.baizhi
import org.apache.spark.{SparkConf, SparkContext}
/**
* spark版本的单词统计
*/
object WordCountApplicationOnLocalWithCache {
def main(args: Array[String]): Unit = {
//1. 创建SparkContext,上下文对象提供spark应用运行环境信息
val conf = new SparkConf()
.setAppName("WordCount Apps")
.setMaster("local[*]") // local 本地模式 模拟Spark应用运行 [*] 当前计算机的所有核心 cores 6
val sc = new SparkContext(conf)
//2. 编写DAG计算任务 有向无环图(某逻辑开发 --》 多重计算 --》最终输出)
val rdd = sc.textFile("hdfs://SparkOnStandalone:9000/text.txt")
// 将血统祖宗RDD Cache
rdd.cache()
rdd.count()
val start = System.currentTimeMillis()
rdd.count()
val end = System.currentTimeMillis()
println("使用cache应用耗费时间:" + (end - start)) //
// 取消cache
rdd.unpersist()
val start2 = System.currentTimeMillis()
rdd
.count()
val end2 = System.currentTimeMillis()
println("没有cache应用耗费时间:" + (end2 - start2))
//3. 释放资源
sc.stop()
}
}

注意:
-
RDD#cache方法默认会将RDD缓存内存中
-
RDD#persist(storageLevel),支持其它缓存等级

-
_2表示RDD数据会拥有原始和数据备份 -
_SER表示RDD以序列化对象的形式进行存储 -
如果选择合理的存储等级? 如果内存空间大建议使用
MEMORY_ONLY或者MEMORY_ONLY_SER;如果内存一般建议使用MEMORY_AND_DISK或者MEMORY_AND_DISK_SER
Checkpoint(检查点机制)
除了使用缓存机制可以有效的保证RDD的故障恢复,但是如果缓存失效还是会在导致系统重新计算RDD的结果,所以对于一些RDD的lineage较长的场景,计算比较耗时,用户可以尝试使用checkpoint机制存储RDD的计算结果,该种机制和缓存最大的不同在于,使用checkpoint之后被checkpoint的RDD数据直接持久化在共享文件系统中,一般推荐将结果写在 hdfs 中,这种checpoint并不会自动清空。注意checkpoint在计算的过程中先是对RDD做mark,在任务执行结束后,再对mark的RDD实行checkpoint,也就是要重新计算被Mark之后的rdd的依赖和结果,因此为了避免Mark RDD重复计算,推荐使用策略。
工作原理:
checkpoint并不是在计算时,立即将RDD的结果写在HDFS中,它会标记Mark需要进行Checkpoint处理的RDD
① 初始化 —> ② 标记 —> ③ 处理Checkpoint RDD —> ④ 处理完成后 checkpoint RDD之前血统中止
package com.baizhi
import org.apache.spark.{SparkConf, SparkContext}
/**
* spark版本的单词统计
*/
object WordCountApplicationOnLocalWithCheckpoint {
def main(args: Array[String]): Unit = {
//1. 创建SparkContext,上下文对象提供spark应用运行环境信息
val conf = new SparkConf()
.setAppName("WordCount Apps")
.setMaster("local[*]") // local 本地模式 模拟Spark应用运行 [*] 当前计算机的所有核心 cores 6
val sc = new SparkContext(conf)
// 设置了检查点目录
sc.setCheckpointDir("hdfs://SparkOnStandalone:9000/checkpoint1")
//2. 编写DAG计算任务 有向无环图(某逻辑开发 --》 多重计算 --》最终输出)
val rdd = sc.textFile("hdfs://SparkOnStandalone:9000/text.txt")
// rdd.cache()
// 对需要进行检查点操作的RDD应用检查点操作
// rdd.checkpoint()
rdd.count()
val mapRDD = rdd
.flatMap(_.split(" "))
.map((_, 1))
mapRDD.cache() // 双重容错: 对宽依赖的父RDD应用cache,然后对RDD设置了检查点
mapRDD.checkpoint()
mapRDD
.groupByKey()
.map(t2 => (t2._1, t2._2.size))
.foreach(println)
//3. 释放资源
sc.stop()
}
}
七、RDD的操作API
RDD的操作分为了两种类型Transformation(转换算子)和Action(行动算子)
Transformation
SparkRDD的转换算子,主要作用对RDD进行转换操作,所有的转换算子都是懒执行的(lazy),也就意味着不会立即应用转换操作,直到遇到行动算子后才会触发真正的计算,Spark这样的设计主要提供资源利用和计算效率的提升。
| Transformation | Meaning |
|---|---|
| map(func) | Return a new distributed dataset formed by passing each element of the source through a function func. |
| filter(func) | Return a new dataset formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator => Iterator when running on an RDD of type T. |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator) => Iterator when running on an RDD of type T. |
| sample(withReplacement, fraction, seed) | Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed. |
| union(otherDataset) | Return a new dataset that contains the union of the elements in the source dataset and the argument. |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in the source dataset and the argument. |
| distinct([numPartitions])) | Return a new dataset that contains the distinct elements of the source dataset. |
| groupByKey([numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable) pairs. Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will yield much better performance. Note: By default, the level of parallelism in the output depends on the number of partitions of the parent RDD. You can pass an optional numPartitions argument to set a different number of tasks. |
| reduceByKey(func, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral “zero” value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| sortByKey([ascending], [numPartitions]) | When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument. |
| join(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| cogroup(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable, Iterable)) tuples. This operation is also called groupWith. |
| cartesian(otherDataset) | When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
| pipe(command, [envVars]) | Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process’s stdin and lines output to its stdout are returned as an RDD of strings. |
| coalesce(numPartitions) | Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset. |
| repartition(numPartitions) | Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. |
| repartitionAndSortWithinPartitions(partitioner) | Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than calling repartition and then sorting within each partition because it can push the sorting down into the shuffle machinery. |
结论:
- RDD的转换算子中,如果允许设置分区数量,则此转换算子为宽依赖的算子
- RDD的宽依赖的转换算子,如果没有设定分区数量,则分区数量和父RDD的分区数量保持一致,也可以手动设定子RDD的分区数量,设定优先
-
map(fun) : 对源RDD的元素应用函数操作返回一个新的RDD
val sourceRDD = sc.makeRDD(ListBuffer("a","b","c")) // map sourceRDD .map(str => (str,str)) .foreach(println) //------------------------------------------------------- (b,b) (c,c) (a,a) -
filter(fun) : 对源RDD的元素进行过滤保留符合条件的元素返回一个新的RDD
val sourceRDD = sc.makeRDD(ListBuffer("a","b","c")) sourceRDD .map(str => (str,str)) .filter(t2 => ! t2._1.equals("b")) .foreach(println) //------------------------------------------------------- (c,c) (a,a) -
flatMap(fun) : 将源RDD的元素展开为0~n个元素,并返回一个新的RDD
val sourceRDD2 = sc.parallelize(Vector("Hello Scala", "Hello Hello Hello")) sourceRDD2 .flatMap(line => line.split(" ")) .foreach(println) //------------------------------------------------------- Hello Scala Hello Hello Hello -
mapPartitions(func) : 对源RDD的每一个分区独立应用函数操作,返回一个新的RDD
// mapPartitions val sourceRDD3 = sc.parallelize(Vector("Hello Scala", "Hello Hello Hello"), 2) sourceRDD3 .mapPartitions(itar => { val lb = ListBuffer[(String, Int)]() while (itar.hasNext) { val line = itar.next() lb.+=((line, 1)) } lb.iterator }) .foreach(println) //--------------------------------------------------------- (Hello Scala,1) (Hello Hello Hello,1) -
mapPartitionsWithIndex(func) : 对源RDD的每一个分区应用函数操作,注意携带分区的索引序号,并返回一个新的RDD
val sourceRDD4 = sc.parallelize(Vector("Hello Scala", "Hello Hello Hello","Hadoop"), 2) sourceRDD4 .mapPartitionsWithIndex((index, itar) => { val lb = ListBuffer[(String, Int)]() while (itar.hasNext) { val line = itar.next() lb.+=((line, index)) // 对源RDD每一个分区应用函数操作 返回(line,分区索引) } lb.iterator }) .foreach(println) -
sample(withReplacement, fraction, seed) : 数据取样采样方法,
三个参数:
- withReplacement 表示数据是否允许重复
- fraction 分数,每个数据被抽选中的概率
- seed 种子用以底层产生随机数
// sample val sourceRDD5 = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7)) sourceRDD5 // .sample(false, 0.5d) // 数据不允许重复 每一个元素抽选中概率为0.5 .sample(true, 1.8) // 数据允许重复, 每一个数可以被抽选中的次数 .foreach(println) //--------------------------------------------------------- 1 5 3 3 3 5 5 5 6 -
union(rdd) : 将源RDD和参数RDD的内容合并,返回一个新的RDD
// union val sourceRDD6 = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7), 1) val sourceRDD7 = sc.makeRDD(List(5, 6, 7, 8, 9), 1) sourceRDD6 .union(sourceRDD7) // 新RDD(1,2,3,4,5,6,7,5,6,7,8,9) .sortBy(e => e, true,1) .foreach(println) //----------------------------------------------------------- 1 2 3 4 5 5 6 6 7 7 8 9 -
intersection(otherDataset) : 将源RDD和参数RDD的内容求交集,返回一个新的RDD
// 前台系统大量数据 敏感词 敏感词词库 val sourceRDD8 = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7), 1) val sourceRDD9 = sc.makeRDD(List(5, 6, 7, 8, 9), 1) sourceRDD8 .intersection(sourceRDD9) // 新RDD(5,6,7) .sortBy(e => e, true, 1) .foreach(println) //----------------------------------------------------------- 5 6 7 -
distinct([numPartitions]) : 对源RDD元素进行去重,返回一个新的RDD
// distinct val sourceRDD10 = sc.makeRDD(List(1, 2, 3, 3, 4, 4, 5, 6), 2) sourceRDD10 .distinct(1) .foreach(println) //------------------------------------------------------------ 4 1 6 3 5 2 -
groupByKey([numPartitions]):对一个源RDD (k,v)进行调用,返回一个k相同的(K, Iterable)
注意: 如果不设定分区数量,则子RDD的分区数量和父RDD的分区数量一致,如果设定,则以设定的优先;
// groupByKey 根据key进行分组操作 val sourceRDD11 = sc.makeRDD(List(("Hello", 1), ("Spark", 1), ("Hello", 1), ("Scala", 1)), 2) sourceRDD11 .groupByKey(4) // 宽依赖的算子 .foreach(println) //------------------------------------------------------------ (Spark,CompactBuffer(1)) (Hello,CompactBuffer(1, 1)) (Scala,CompactBuffer(1)) -
reduceByKey(func, [numPartitions])
重要: 对一个源RDD (k,v)进行调用,返回一个新的结果RDD(k,v);注意:根据key对values进行给定的函数聚合操作
// reduceByKey val sourceRDD12 = sc.makeRDD(List(("Hello", 1), ("Spark", 1), ("Hello", 1), ("Scala", 1)), 2) // (Hello,(1,1,1)) // 1+1 = 2 // 2+1 = 3 val rdd = sourceRDD12 .reduceByKey( new Partitioner { // 自定义分区规则 override def numPartitions: Int = 3 override def getPartition(key: Any): Int = { val k = key.asInstanceOf[String] if (k.startsWith("H")) 0 else if (k.startsWith("S")) 1 else 2 } }, (v1, v2) => v1 + v2 // 或 _+_ ) println(rdd.getNumPartitions) //rdd.foreach(println) // 方法2: /* sourceRDD12 .reduceByKey(_ + _, 2) .foreach(println) */ // 方法3: val rdd2 = sourceRDD12 .reduceByKey(_ + _) println(rdd2.getNumPartitions) // 2 -
aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) : 根据key进行聚合操作
注意:首先分区内的计算,再进行分区间的计算
// aggregateByKey val sourceRDD13 = sc.makeRDD(List(("Hello", 1), ("Spark", 1), ("Hello", 1), ("Scala", 1)), 2) /* 源RDD p0 (Hello,1) => (hello,1+1) => (hello,2+2) => (hello,4) (spark,1) => (spark,1+1) p1 (Hello,1) => (hello,1+1) (Scala,1) */ sourceRDD13 .aggregateByKey(1)( (zeroValue, default) => zeroValue + default, // 分区内的聚合操作 (p1, p2) => p1 + p2 // 不同分区间的聚合操作 ) .foreach(println) //------------------------------------------------------------ (Spark,2) (Hello,4) (Scala,2) -
sortByKey([ascending], [numPartitions]) : 对源RDD(k,v)调用,根据k进行排序返回一个新的RDD
// sortByKey val sourceRDD14 = sc.parallelize(List(("b", 1), ("a", 1), ("c", 1), ("a", 1)), 2) sourceRDD14 //.sortByKey(false, 1) // 排序规则和排序后的分区数量 .sortBy(t2 => t2._1,false,1) .foreach(println) //------------------------------------------------------------ (c,1) (b,1) (a,1) (a,1) -
join(otherDataset, [numPartitions]) : 两个RDD(K,V)和(K,W)进行连接操作,返回一个新的RDD(K,(V,W))
// join val sourceRDD15 = sc.parallelize(List((1, "zs"), (2, "ls"), (3, "ww"), (4, "zl"))) val sourceRDD16 = sc.parallelize(List((1, 18), (3, 28), (2, 9),(5,10))) sourceRDD15 // .join(sourceRDD16, 2) // 相当于内连接 //.leftOuterJoin(sourceRDD16,2) // 左外连接 .rightOuterJoin(sourceRDD16,2) // 相当于右外连接 .foreach(t2 => println(t2._1 + "\t" + t2._2._1 + "\t" + t2._2._2)) //------------------------------------------------------------ 2 Some(ls) 9 1 Some(zs) 18 3 Some(ww) 28 5 None 10 -
cogroup(otherDataset, [numPartitions]: 共同分组,两个RDD(K,V)和(K,W)进行共同分组,返回一个新的RDD (K, (Iterable, Iterable))
// cogroup val sourceRDD17 = sc.parallelize(List(("b", 1), ("a", 1), ("c", 1), ("a", 1)), 2) val sourceRDD18 = sc.parallelize(List(("e", 1), ("a", 1), ("c", 1), ("a", 1)), 2) // sourceRDD17 (a,[1,1]) (b,[1]) (c,[1]) // sourceRDD18 (a,[1,1]) (e,[1]) (c,[1]) // cogroup后:(a,([1,1],[1,1])) (b,([1],[])) (c,([1],[1])) sourceRDD17 .cogroup(sourceRDD18) .foreach(println) //------------------------------------------------------------ (e,(CompactBuffer(),CompactBuffer(1))) (b,(CompactBuffer(1),CompactBuffer())) (a,(CompactBuffer(1, 1),CompactBuffer(1, 1))) (c,(CompactBuffer(1),CompactBuffer(1))) -
cartesian(otherDataset): 笛卡尔连接 交叉连接,尝试源RDD和另外一个RDD的元素各种组合可能
// cartesian 笛卡尔乘积 val sourceRdd19 = sc.makeRDD(List("a", "b", "c")) val sourceRdd20 = sc.makeRDD(List(1, 2, 3)) sourceRdd19 .cartesian(sourceRdd20) // ("a",1) ("a",2) ("a",3) ... .foreach(println) -
pipe(command, [envVars]) : 不是很重要,在RDD的每一个分区执行一个Shell指令或者脚本
-
coalesce(numPartitions) : 将源RDD的分区数量减少为numPartitions返回一个新的RDD
// coalesce 减少分区数量 val sourceRDD21 = sc.makeRDD(List("a", "b", "c", "d"), 4) val rdd2 = sourceRDD21 .coalesce(5) println(rdd2.getNumPartitions) // 4 设置过大的分区数量 无意义,依然使用父RDD的分区数 //rdd2.foreach(println) -
repartition(numPartitions) : 重新分区
stage (TaskSet) --> Task :Partition ---> Task:Thread// repartition 重新分区 val sourceRDD22 = sc.makeRDD(List("a", "b", "c", "d"), 4) val rdd3 = sourceRDD22 .repartition(5) // 父RDD 4 ---> 子RDD 2 println(rdd3.getNumPartitions) //rdd3.foreach(println) -
repartitionAndSortWithinPartitions(partitioner): 重新分区,并对分区内的数据进行局部排序
// repartitionAndSortWithinPartitions val sourceRDD23 = sc.parallelize(List(("b", 1), ("e", 2), ("a", 1), ("c", 1), ("a", 3), ("a", 2)), 2) sourceRDD23 .repartitionAndSortWithinPartitions(new Partitioner { override def numPartitions: Int = 4 override def getPartition(key: Any): Int = { val k = key.asInstanceOf[String] if (k.startsWith("a") || k.startsWith("e")) 0 else if (k.startsWith("b")) 1 else if (k.startsWith("c")) 2 else 3 } }) .foreach(println) // --------------------------------------------------------------------- (b,1) (a,1) (a,3) (a,2) (e,2) (c,1)
Action
行动算子
任意的行动算子都会触发spark应用的真实计算
- 通常情况下Action算子的返回值为Unit或者结果的集合
- 而Transformation算的返回值为新的RDD
| Action | Meaning |
|---|---|
| reduce(func) | Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect() | Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| count() | Return the number of elements in the dataset. |
| first() | Return the first element of the dataset (similar to take(1)). |
| take(n) | Return an array with the first n elements of the dataset. |
| takeSample(withReplacement, num, [seed]) | Return an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| takeOrdered(n, [ordering]) | Return the first n elements of the RDD using either their natural order or a custom comparator. |
| saveAsTextFile(path) | Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
| saveAsSequenceFile(path) (Java and Scala) | Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that implement Hadoop’s Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| saveAsObjectFile(path) (Java and Scala) | Write the elements of the dataset in a simple format using Java serialization, which can then be loaded using SparkContext.objectFile(). |
| countByKey() | Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach(func) | Run a function func on each element of the dataset. This is usually done for side effects such as updating an Accumulator or interacting with external storage systems. Note: modifying variables other than Accumulators outside of the foreach() may result in undefined behavior. See Understanding closures for more details. |
-
reduce(func) : 对RDD中的元素进行聚合操作
reduceByKey: 根据k对v进行聚合操作
- 转换算子
- 返回值新的RDD
reduce: 直接对RDD中的元素进行聚合操作
- 行动算子
- 返回值和源RDD中的元素类型一致
val sourceRDD = sc.makeRDD(ListBuffer(1, 2, 3, 4, 5)) // reduce action算子 val sum:Int = sourceRDD .reduce((v1, v2) => v1 + v2) // 1+2 // 3+3 // 6+4 // 10+5 println("sum:"+sum) // 15 -
collect() : 收集方法,将RDD的所有元素以数组形式返回给Driver端
val sourceRDD = sc.makeRDD(ListBuffer(1, 2, 3, 4, 5)) val arr: Array[Int] = sourceRDD.collect() println(arr.mkString(",")) //----------------------------------------------------- 1,2,3,4,5 -
count() : 返回RDD中元素的个数
// count val count = sourceRDD.count() println(count) //5 -
first() : 返回RDD中的第一个元素
// first val first = sourceRDD.first() println(first) // 1 -
take(n) : 返回RDD中的前N个元素, 排行榜
// take(n) 保留单词出现次数最多前三个 val tuples: Array[(String, Int)] = sc .makeRDD(List("Hello Spark", "Hello Scala", "Hello Hello Spark", "Scala very good")) .flatMap(_.split(" ")) .map((_, 1)) .groupByKey() .map(t2 => (t2._1, t2._2.size)) .sortBy(_._2, false, 1) .take(3) for (t2 <- tuples) { println(t2._1 + "\t" + t2._2) } //----------------------------------------------------------------------- Hello 4 Spark 2 Scala 2 -
takeSample(withReplacement, num, [seed]) : 数据采样
注意:
第二个参数:取样数据的数量,不同于转换算子Sample Fraction
// takeSample(withReplacement, num, [seed]) val arr = sourceRDD.takeSample(false, 2) println(arr.mkString(">>")) -
takeOrdered(n, [ordering]) : 获取RDD中前N个元素,使用默认的或者给定的排序规则
// takeOrdered(n) 保留单词出现次数最多前三个 val tuples: Array[(String, Int)] = sc .makeRDD(List("Hello Spark", "Hello Scala", "Hello Hello Spark", "Scala very good")) .flatMap(_.split(" ")) .map((_, 1)) .groupByKey() .map(t2 => (t2._1, t2._2.size)) .takeOrdered(3)(new Ordering[(String, Int)] { /** * * @param x * @param y * @return */ override def compare(x: (String, Int), y: (String, Int)): Int = if (x._2 > y._2) -1 else 1 }) for (t2 <- tuples) { println(t2._1 + "\t" + t2._2) } //------------------------------------------------------ Hello 4 Spark 2 Scala 2 -
saveAsTextFile(path) : 将RDD中的内容保存到HDFS或者Local File System
sourceRDD.saveAsTextFile("file:///D:\\result")注意:
local[*], RDD的分区数量和CPU Cores一致 -
saveAsSequenceFile(path): 将RDD的内容以序列化文件的形式保存在HDFS或者Local FileSystem
val rdd = sc.makeRDD(List((1, "zs"), (2, "ls"))) // 对于 basic types like Int, Double, String 自动转换Hadoop Writable(序列化) rdd.saveAsSequenceFile("file:///d://result2") -
saveAsObjectFile(path): 将RDD的内容以Java序列化方法保存在HDFS或者Local FileSystem
// 将RDD中的内容以Java序列化方式写到指定Path // sourceRDD.saveAsObjectFile("file:///d://result3") val rdd = sc.objectFile("file:///d://result3") rdd.foreach(println) //------------------------------------------------------ 1 2 3 4 5 -
countByKey(): 统计相同key的value数量,返回HashMap
sc .makeRDD(List("Hello Spark", "Hello Scala", "Hello Hello Spark", "Scala very good")) .flatMap(_.split(" ")) .map((_, 1)) .countByKey() .foreach(println) //------------------------------------------------------ (good,1) (Scala,2) (Hello,4) (Spark,2) (very,1) -
foreach : 对RDD中的每一个元素进行遍历处理
foreach行动算子可以将RDD的处理结果写到任意的可以存储的外围系统
注意:安装并运行Redis服务
// 将RDD的计算结果写到Redis中 [root@SparkOnStandalone ~]# tar -zxf redis-4.0.10.tar.gz [root@SparkOnStandalone ~]# cd redis-4.0.10 [root@SparkOnStandalone redis-4.0.10]# make && make install [root@SparkOnStandalone redis-4.0.10]# cp redis.conf /usr/local/bin/ [root@SparkOnStandalone redis-4.0.10]# cd /usr/local/bin [root@SparkOnStandalone bin]# vim redis.conf # 开启redis远程访问 bind 0.0.0.0 [root@SparkOnStandalone bin]# ./redis-server redis.conf# 导入jedis依赖 <dependency> <groupId>redis.clientsgroupId> <artifactId>jedisartifactId> <version>2.9.0version> dependency> <dependency> <groupId>mysqlgroupId> <artifactId>mysql-connector-javaartifactId> <version>5.1.47version> dependency>
将计算结果写出到Redis或MySQL中
package opt.transformations
import java.sql.DriverManager
import org.apache.spark.{SparkConf, SparkContext}
import redis.clients.jedis.Jedis
object ActionTest2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("transformation test")
val sc = new SparkContext(conf)
// redis 连接对象 不允许序列化(只能够当前JVM使用)
/*
val jedis = new Jedis("SparkOnStandalone", 6379)
sc
.makeRDD(List("Hello Spark", "Hello Scala", "Hello Hello Spark", "Scala very good"))
.flatMap(_.split(" "))
.map((_, 1))
.groupByKey()
.map(t2 => (t2._1, t2._2.size))
.foreach(t2 => jedis.set(t2._1, t2._2.toString)) // rdd的行动算子
*/
classOf[com.mysql.jdbc.Driver]
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "1234")
sc
.makeRDD(List("Hello Spark", "Hello Scala", "Hello Hello Spark", "Scala very good"))
.flatMap(_.split(" "))
.map((_, 1))
.groupByKey()
.map(t2 => (t2._1, t2._2.size))
.foreach(t2 => {
val pstm = connection.prepareStatement("insert into t_word values(?,?)")
pstm.setString(1, t2._1)
pstm.setInt(2, t2._2.toInt)
pstm.executeUpdate()
pstm.close()
})
connection.close()
sc.stop()
}
}
在测试时发现问题:
出现
Caused by: java.io.NotSerializableException: java.lang.Object异常原因: 当算子函数使用到外部的变量,则变量会序列化传输到任务节点。但是,通常情况下,数据存储系统的连接对象都不允许序列化
解决方案:
-
方法一
//------------------------------------------方案1---------------------------------------------- sc .makeRDD(List("Hello Spark", "Hello Scala", "Hello Hello Spark", "Scala very good")) .flatMap(_.split(" ")) .map((_, 1)) .groupByKey() .map(t2 => (t2._1, t2._2.size)) .foreach(t2 => { classOf[com.mysql.jdbc.Driver] val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "1234") val pstm = connection.prepareStatement("insert into t_word values(?,?)") pstm.setString(1, t2._1) pstm.setInt(2, t2._2.toInt) pstm.executeUpdate() pstm.close() connection.close() })注意:foreach行动迭代处理RDD中元素时,会对每一个RDD的元素创建一个连接对象,会造成大量的资源浪费和性能损耗
-
方法二(优化版)
//------------------------------------------方案2---------------------------------------------- sc .makeRDD(List("Hello Spark", "Hello Scala", "Hello Hello Spark", "Scala very good")) .flatMap(_.split(" ")) .map((_, 1)) .groupByKey() .map(t2 => (t2._1, t2._2.size)) .foreachPartition(itar => { // 对RDD的每一个分区(Task, 保证Task共享一个连接对象)应用迭代操作 // itar代表的是每一个分区所有元素的迭代器 classOf[com.mysql.jdbc.Driver] val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "1234") val pstm = connection.prepareStatement("insert into t_word values(?,?)") itar.foreach(t2 => { pstm.setString(1, t2._1) pstm.setInt(2, t2._2) pstm.executeUpdate() }) pstm.close() connection.close() })
八、RDD共享变量
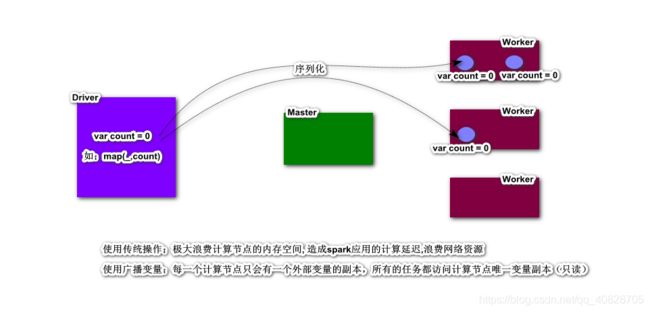
共享变量定义:在Spark的算子函数中,如果使用到了算子函数外部的变量,则该变量会序列化并拷贝到任务节点,每一个任务操作的是拷贝的变量副本
Spark提供了两种类型的共享变量:**广播变量(broadcast variable)**和累加器(accumulator)
广播变量(broadcast variable) 【重点】
优化策略定义广播变量,广播变量在使用时,每一个计算节点只会有一个可读的副本,所有的计算任务共享这一个相同的广播变量
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
object BroadcastVariableTest {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("broadcast test").setMaster("local[*]"))
// 用户信息 ...
val userInfo = Map((1, "zs"), (2, "ls"), (3, "ww"))
val orderIno = List(("001", "iphone11", 4999.0D, 1), ("002", "打底裤", 99D, 3), ("003", "滑板车", 399D, 1), ("004", "刮胡刀", 199D, 2))
// 统计每一个用户(谁)花费的总额
val rdd = sc.parallelize(orderIno)
//================================================================
val value = sc.broadcast(userInfo) // 将userInfo外部变量作为一个广播变量
//================================================================
rdd
.groupBy(t4 => t4._4) // rdd 分区 5
.foreach(t2 => {
val userId = t2._1
val buffer = t2._2
var sum = 0.0 // 这个所有订单的消费总额
buffer.foreach(t4 => {
sum += t4._3
})
// zs 5398
// println(userInfo(userId) + "\t" + sum)
// 通过广播变量的方法获取只读结果
println(value.value(userId) + "\t" + sum)
})
sc.stop()
}
}
//----------------------------------------------------------
ww 99.0
ls 199.0
zs 5398.0
累加器(accumulator)
累加器的主要作用就是进行共享性操作(累加),累加器的累加结果可以返回给Driver使用
import org.apache.spark.{SparkConf, SparkContext}
/**
* 累加器操作
*/
object AccumulatorTest {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("accumulator test").setMaster("local[*]"))
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5))
// 第一步: 定义累加器
val longAccumulator = sc.longAccumulator("Sum") // 累加器起别名
rdd.foreach(n => {
// 累加器操作
longAccumulator.add(n) // 0 + 1 + 2 + 3 + 4 + 5
})
// 最后:累加器的结果可以在Driver端获取
println(longAccumulator.value) // 15
sc.stop()
}
}
作业
-
认真梳理Spark&RDD的知识细节?
-
编程作业
-
收集某系统的访问日志数据,格式如下
# 客户端的访问IP地址 访问时间 请求方式 请求URI地址 响应状态码 响应字节大小 192.168.10.1 2019-11-28 10:23:00 /GET /user/queryAll 200 1024 123.234.121.6 2019-11-28 10:23:02 /POST /user/save 404 1024 192.168.10.1 2019-11-28 10:23:03 /GET /user/queryAll 200 1024 ... // 1. 系统健壮性统计(状态码分布) a. 通过spark应用计算 200/98% 404/1.5% 500/0.5% b 写入到MySQL中 c. 并且进行数据的可视化展示【饼图】,要求使用ajax获取mysql中数据,做到动态展示 【AJAX + SpringBoot +MyBatis + Bootstrap】 sc .textFile("hdfs://SparkOnStandalone:9000/logs/2019-11-28.log") .flatMap(line => line.split(" ")(5)) .map((_,1)) .reduceByKey(_+_) .foreachPartition( // mysql or redis) // 2. 统计系统访问PV(page view): 系统每日访问量,换句话来说PV = 访问记录数 页面展示(柱状图或者折线图) sc .textFile("hdfs://SparkOnStandalone:9000/logs/2019-11-28.log") .filter(....) .count() // 3. 系统UV(Unique view) : 系统每日独立用户的访问量 : groupBy(Ip) count ---------------------------------------------------------------------------------- jar提交spark集群运行 2019-11-29 02:00:00
-
====================================
rdd
.groupBy(t4 => t4._4) // rdd 分区 5
.foreach(t2 => {
val userId = t2._1
val buffer = t2._2
var sum = 0.0 // 这个所有订单的消费总额
buffer.foreach(t4 => {
sum += t4._3
})
// zs 5398
// println(userInfo(userId) + "\t" + sum)
// 通过广播变量的方法获取只读结果
println(value.value(userId) + "\t" + sum)
})
sc.stop()
}
}
//----------------------------------------------------------
ww 99.0
ls 199.0
zs 5398.0
### 累加器(accumulator)
> 累加器的主要作用就是进行共享性操作(累加),累加器的累加结果可以返回给Driver使用
```scala
import org.apache.spark.{SparkConf, SparkContext}
/**
* 累加器操作
*/
object AccumulatorTest {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("accumulator test").setMaster("local[*]"))
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5))
// 第一步: 定义累加器
val longAccumulator = sc.longAccumulator("Sum") // 累加器起别名
rdd.foreach(n => {
// 累加器操作
longAccumulator.add(n) // 0 + 1 + 2 + 3 + 4 + 5
})
// 最后:累加器的结果可以在Driver端获取
println(longAccumulator.value) // 15
sc.stop()
}
}
作业
-
认真梳理Spark&RDD的知识细节?
-
编程作业
-
收集某系统的访问日志数据,格式如下
# 客户端的访问IP地址 访问时间 请求方式 请求URI地址 响应状态码 响应字节大小 192.168.10.1 2019-11-28 10:23:00 /GET /user/queryAll 200 1024 123.234.121.6 2019-11-28 10:23:02 /POST /user/save 404 1024 192.168.10.1 2019-11-28 10:23:03 /GET /user/queryAll 200 1024 ... // 1. 系统健壮性统计(状态码分布) a. 通过spark应用计算 200/98% 404/1.5% 500/0.5% b 写入到MySQL中 c. 并且进行数据的可视化展示【饼图】,要求使用ajax获取mysql中数据,做到动态展示 【AJAX + SpringBoot +MyBatis + Bootstrap】 sc .textFile("hdfs://SparkOnStandalone:9000/logs/2019-11-28.log") .flatMap(line => line.split(" ")(5)) .map((_,1)) .reduceByKey(_+_) .foreachPartition( // mysql or redis) // 2. 统计系统访问PV(page view): 系统每日访问量,换句话来说PV = 访问记录数 页面展示(柱状图或者折线图) sc .textFile("hdfs://SparkOnStandalone:9000/logs/2019-11-28.log") .filter(....) .count() // 3. 系统UV(Unique view) : 系统每日独立用户的访问量 : groupBy(Ip) count ---------------------------------------------------------------------------------- jar提交spark集群运行 2019-11-29 02:00:00
-
-
尝试商品热卖榜(不要求)