Text to image论文精读ALR-GAN:文本到图像合成的自适应布局优化
ALR-GAN是北京工业大学学者提出的一种自适应布局优化生成对抗网络,其可以在没有任何辅助信息的情况下自适应地优化合成图像的布局。
文章发表于2023年,IEEE Transactions on Multimedia(TMM)期刊(CCF B,JCR1区),是一篇值得一读的文章。
文章链接:https://ieeexplore.ieee.org/document/10023990
一、原文摘要
文章提出了一种新的文本到图像生成网络——自适应布局优化生成对抗网络(ALR-GAN),其能够在没有任何辅助信息的情况下自适应地优化合成图像的布局。ALR-GAN包括一个自适应布局优化(ALR)模块和一个布局视觉优化(LVR)丢失。ALR模块将合成图像的布局结构(指物体和背景的位置)与相应的真实图像对齐。在ALR模块中,我们提出了一种自适应布局优化(Adaptive Layout refine, ALR)损失来平衡难特征和易特征的匹配,以实现更高效的布局结构匹配。LVR损失在细化布局结构的基础上,进一步细化布局区域内的视觉表示。在两个广泛使用的数据集上的实验结果表明,ALR-GAN在文本到图像生成任务中具有竞争力。
二、为什么提出ALR-GAN?
文本到图像生成(T2I)旨在从文本描述中合成逼真的图像。为了实现这一具有挑战性的跨模态生成任务,研究者们主要通过:①促进高分辨率图像合成;②细化图像细节;③增强图像语义这些方面来进行改进。
但它们往往专注于单一物体的合成,如鸟、花或狗。对于复杂的图像合成任务,合成的对象很容易被放置在图像的各种不合理的位置上,即布局结构很容易混乱。
在之前的一些工作中,一些方法使用辅助信息如:对象边框object bounding box, 对象形状object shape, 和场景图scene graph来辅助生成,但是①这种辅助信息的获取一般价格昂贵,不利于任务的推广应用;②这些方法通常忽略了布局区域内的视觉质量。
ALR-GAN的目标就是在没有辅助信息的情况下改进合成图像的布局。
ALR-GAN提出了一种自适应布局优化生成对抗网络来改善合成图像的布局,包括一个自适应布局优化(ALR)模块和布局视觉优化(LVR)损失。ALR模块和提出的自适应布局细化(ALR)损失的作用是自适应地将合成图像的布局结构与其对应的真实图像的视觉表示对齐。
三、ALR-GAN模型
3.1、模型框架

上图显示了所提出的ALR- GAN的架构,可以看到其是一种类似StackGAN++、AttnGAN、MirrorGAN、DM-GAN的多阶段模型,由文本编码器、三个生成器和三个鉴别器组成,另外框架还包含几个新组件:初始特征转换模块(IFTM)、自适应布局优化(ALR)模块、布局视觉优化(LVR)损耗。
ALR模块配备了所提出的自适应布局细化(LVR)损失以自适应地细化合成图像的布局结构,辅助其对应的真实图像。
LVR损失旨在增强布局区域内的纹理感知和风格信息。
主要流程:文本编码器将输入的文本描述(单个句子)转换为句子特征s0和单词特征W,IFTM将文本嵌入s和噪声z∼N(0,1)转换为图像特征H0,ALR模块在训练过程中对生成器合成图像的布局结构进行自适应细化(后两层次),三个鉴别器对三个阶段的生成器分别鉴别优化,帮助生成器更好的训练。
3.2、自适应布局优化(ALR)模块
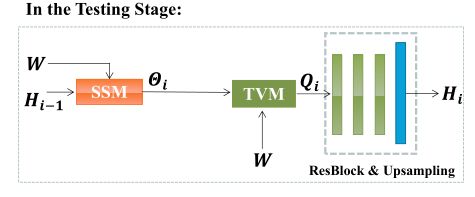
可以看到ALR模块包括一个语义相似矩阵(semantic Similarity Matrix, SSM)和一个文本视觉矩阵(Text-vision Matrix ,TVM)
1️⃣、布局结构构建
SSM语义相似矩阵 θ \theta θ(semantic Similarity Matrix) SSM矩阵用于计算单词W和图像子区域 H i − 1 H_{i−1} Hi−1之间的语义匹配,计算方法与AttnGAN大致相同: θ k , j = exp ( S k , j ′ ) ∑ k = 1 T exp ( S k , j ′ ) , S k , j ′ = ( h i − 1 k ) T w j \theta_{k, j}=\frac{\exp \left(S_{k, j}^{\prime}\right)}{\sum_{k=1}^{T} \exp \left(S_{k, j}^{\prime}\right)}, \quad S_{k,j}^{\prime}=\left(h_{i-1}^{k}\right)^{T} w_{j} θk,j=∑k=1Texp(Sk,j′)exp(Sk,j′),Sk,j′=(hi−1k)Twj,其中 θ k , j θ_{k,j} θk,j为第j个单词 w i w_i wi与第k个图像子区域 h i − 1 k h^k_{i−1} hi−1k之间的语义相似度权值。
由于生成器对文本语义的理解不正确或不充分,合成图像的布局结构往往是混乱的。因此,我们希望合成图像的 θ \theta θ与真实图像的 θ ∗ \theta* θ∗对齐。
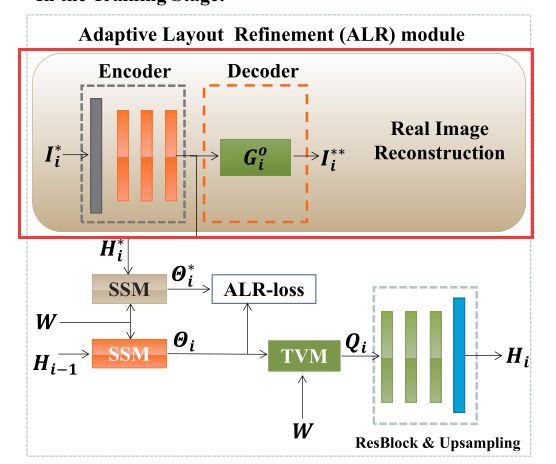
通俗来讲,要保证合成图像的 θ \theta θ与真实图像的 θ \theta θ对齐,即要使合成图像SSM语义相似矩阵与真实图像的SSM语义相似矩阵一致,作者引入了真实图像的重建,如图所示: I i ∗ I_i^* Ii∗为真实图像,首先设计一个Encoder(包含一系列卷积块)提取图像特征 H i ∗ H_i^* Hi∗,为了保证这个提取过程能够保证质量,作者将生成器设置为Decoder,并引入重构损失: L i R E C = ∥ I i ∗ − I i ∗ ∗ ∥ 1 \mathcal{L}_{i}^{R E C}=\left\|I_{i}^{*}-I_{i}^{**}\right\|_{1} LiREC=∥Ii∗−Ii∗∗∥1
2️⃣、自适应布局优化(ALR)损失
θ \theta θ和 θ ∗ \theta^* θ∗中的一些元素很容易匹配,而有些则很难匹配。硬区域是导致布局优化过程中的主要问题。因此,在训练过程中,模型应该更加注意硬区域的匹配。作者提出了自适应布局优化(ALR)损失来解决这个问题。它的构造有四个步骤:
- 计算绝对残差张量:R =Abs.(Θ∗ − Θ)
- 将R中的元素分为硬元素和软元素。我们设定一个阈值γ,ri,j < γ易于匹配则为软元素,元素ri,j≥γ难以匹配则为硬元素。
- 设计了一种自适应的特征级权重自适应机制,以调整Θ和Θ *中软和硬匹配元素的损失权重。自适应权重自适应机制的构建分为4个步骤(如3a~3d所示)
3a.保持小于γ的软元素,其余的设为0,记为 R ‘ e a s y R^`easy R‘easy
3b. R ‘ e a s y R^`easy R‘easy通过填充零,映射到与H *相同的潜空间,称为 R e a s y R_{easy} Reasy,以便后续与H *进行运算
3c.将 R e a s y R_{easy} Reasy与H∗ 做矩阵元素相乘(哈达玛乘积)得到: R easy ⊙ H ∗ R_{\text {easy }} \odot H^{*} Reasy ⊙H∗
3d.然后将其做一系列卷积和激活操作φα(·),得到 α = ϕ α ( R easy ⊙ H ∗ ) \alpha=\phi_{\alpha}\left(R_{\text {easy }} \odot H^{*}\right) α=ϕα(Reasy ⊙H∗),硬元素采用类似的的方法得到 β = ϕ β ( R hard ⊙ H ∗ ) \beta=\phi_{\beta}\left(R_{\text {hard }} \odot H^{*}\right) β=ϕβ(Rhard ⊙H∗)- 在培训过程中,更应该把重点放在最难的部分,因此,权重β应大于α。为此,我们在LALR中设计了softplus(max(α)−min(β))的正则化项来满足它。这里,y = softplus(x) = ln(1 + ex)是一个单调递增函数,通过避免负损失值来帮助数值优化。
根据步骤1-4,ALR损失定义为: L i A L R = 1 N ⋅ D ( ∥ α i ⊙ R easy i ∥ F + ∥ β i ⊙ R hard i ∥ F + ∥ softplus ( max ( α i ) − min ( β i ) ) ∥ F ) \begin{array}{l} L_{i}^{A L R}=\frac{1}{N \cdot D}\left(\left\|\alpha_{i} \odot R_{\text {easy }_{i}}\right\|_{F}+\left\|\beta_{i} \odot R_{\text {hard }_{i}}\right\|_{F}\right. \left.+\left\|\operatorname{softplus}\left(\max \left(\alpha_{i}\right)-\min \left(\beta_{i}\right)\right)\right\|_{F}\right) \end{array} LiALR=N⋅D1( αi⊙Reasy i F+∥βi⊙Rhard i∥F+∥softplus(max(αi)−min(βi))∥F)
其中,下标F代表矩阵的F-范数
3️⃣、构建文本视觉矩阵(TVM)
基于修正后的SSM语义相似矩阵,对于第K个图像子区域,词动态表示为: h i − 1 k , q i − 1 k = ∑ j = 1 T θ j , k w j h_{i-1}^{k} \text ,q_{i-1}^{k}=\sum_{j=1}^{T} \theta_{j, k} w_{j} hi−1k,qi−1k=∑j=1Tθj,kwj,因此,用于词嵌入W和图像特征Hi−1的文本-视觉矩阵(TVM)表示为 Q i − 1 Q_{i−1} Qi−1
最后将文本视觉矩阵TVM的矩阵 Q i − 1 Q_{i−1} Qi−1与图像特征 H i − 1 H_{i−1} Hi−1进行拼接,送入ResBlocks和Upsampling模块输出图像特征 H i H_i Hi
3.3、布局视觉细化(LVR)损失
在精细化布局结构的基础上,进一步增强布局区域内的视觉表现力。为此,我们提出了布局视觉细化(LVR)损失来增强布局中的纹理感知和风格信息。
LVR损失包括感知细化(PR)损失和风格细化(SR)损失。
感知细化(PR)损失: L i P R = 1 N ⋅ D ∥ M a s k Θ i ⊙ H i − Mask Θ i ∗ ⊙ H i ∗ ∥ F L_{i}^{P R}=\frac{1}{N \cdot D}\left\|M a s k_{\Theta_{i}} \odot H_{i}-\operatorname{Mask}_{\Theta_{i}^{*}} \odot H_{i}^{*}\right\|_{F} LiPR=N⋅D1 MaskΘi⊙Hi−MaskΘi∗⊙Hi∗ F
风格细化(SR)损失: L i S R = 1 N ⋅ D ∥ G ( Mask Θ i ⊙ H i ) − G ( Mask Θ i ∗ ⊙ H i ∗ ) ∥ F L_{i}^{S R}=\frac{1}{N \cdot D} \| \mathcal{G}\left(\text { Mask }_{\Theta_{i}} \odot H_{i}\right)-\mathcal{G}\left(\operatorname{Mask}_{\Theta_{i}^{*}} \odot H_{i}^{*}\right) \|_{F} LiSR=N⋅D1∥G( Mask Θi⊙Hi)−G(MaskΘi∗⊙Hi∗)∥F
四、ALR-GAN的总体损失
结合上述模块,在ALR-GAN的第i阶段,生成损失 L G i L_{G_i} LGi定义为 L G i = − 1 2 E I ^ i ∼ P G i [ log D i ( I ^ i ) ] ⏟ unconditional loss − 1 2 E I ^ i ∼ P G i [ log D i ( I ^ i , s ) ] ⏟ conditional loss , L_{G_{i}}=\underbrace{-\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log D_{i}\left(\hat{I}_{i}\right)\right]}_{\text {unconditional loss }}-\underbrace{\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log D_{i}\left(\hat{I}_{i}, s\right)\right]}_{\text {conditional loss }}, LGi=unconditional loss −21EI^i∼PGi[logDi(I^i)]−conditional loss 21EI^i∼PGi[logDi(I^i,s)],
其中,无条件损失推动合成图像更真实,以欺骗鉴别器,而条件损失驱动合成图像更好地匹配相应的文本描述。判别损失定义为:
L D i = − 1 2 E I i ∗ ∼ P data i [ log D i ( I i ∗ ) ] − 1 2 E I ^ i ∼ P G i [ log ( 1 − D i ( I ^ i ) ] ⏟ unconditional loss + − 1 2 E I i ∗ ∼ P d a t a i [ log D i ( I i ∗ , s ) ] − 1 2 E I ^ i ∼ P G i [ log ( 1 − D i ( I ^ i , s ) ] ⏟ conditional loss , \begin{aligned} L_{D_{i}}= & \underbrace{-\frac{1}{2} \mathbb{E}_{I_{i}^{*} \sim P_{\text {data }_{i}}}\left[\log D_{i}\left(I_{i}^{*}\right)\right]-\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log \left(1-D_{i}\left(\hat{I}_{i}\right)\right]\right.}_{\text {unconditional loss }}+ \\ & \underbrace{-\frac{1}{2} \mathbb{E}_{I_{i}^{*} \sim P_{d a t a_{i}}}\left[\log D_{i}\left(I_{i}^{*}, s\right)\right]-\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log \left(1-D_{i}\left(\hat{I}_{i}, s\right)\right]\right.}_{\text {conditional loss }}, \end{aligned} LDi=unconditional loss −21EIi∗∼Pdata i[logDi(Ii∗)]−21EI^i∼PGi[log(1−Di(I^i)]+conditional loss −21EIi∗∼Pdatai[logDi(Ii∗,s)]−21EI^i∼PGi[log(1−Di(I^i,s)],
其中 I I ∗ I^*_I II∗和 I ^ i \hat{I}_{i} I^i是第i个尺度图像,判别损失 L D i L_{Di} LDi从真实图像分布或合成图像分布中对输入图像采样进行分类。
生成网络最终目标函数定义为: L G = ∑ i = 0 m − 1 L G i + ∑ i = 1 m − 1 [ L i A L R + λ 1 L i R E C + L i L V R ] + λ 2 L D A M S M L_{G}=\sum_{i=0}^{m-1} L_{G_{i}}+\sum_{i=1}^{m-1}\left[L_{i}^{A L R}+\lambda_{1} L_{i}^{R E C}+L_{i}^{L V R}\right]+\lambda_{2} L_{D A M S M} LG=∑i=0m−1LGi+∑i=1m−1[LiALR+λ1LiREC+LiLVR]+λ2LDAMSM,
判别网络的最终目标函数定义为: L D = ∑ i = 0 m − 1 L D i L_{D}=\sum_{i=0}^{m-1} L_{D_{i}} LD=∑i=0m−1LDi
五、实验
5.1、实验设置
数据集:CUB-Bird、MS-COCO
Baseline: AttnGAN
评价指标:作者一共选用了四个度量指标即:Inception Score (IS↑)、Fréchet Inception Distance (FID↓)、Semantic Object Accuracy (SOA↑)、R-precision↑
5.2、实验结果
1️⃣、定量实验:
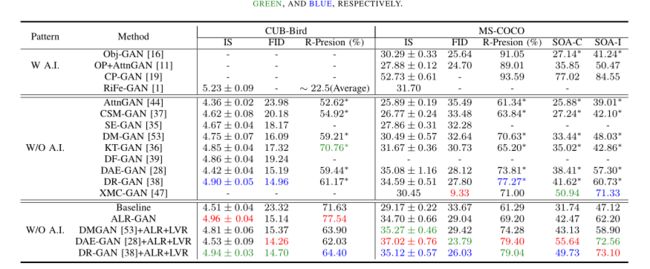
训练时间、训练周期、模型大小和测试时间:
2️⃣、视觉效果
3️⃣、细微改变后的布局变化
ALR-GAN在MS-COCO测试集上捕捉文本描述细微变化(红色短语或单词)的能力,并以合理的布局合成不同的图像。
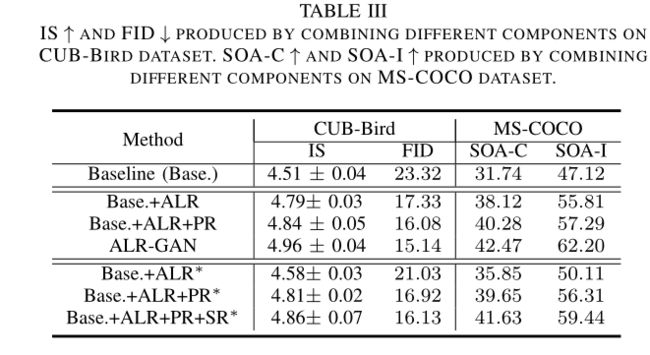
4️⃣、消融实验



六、总结
说实话这篇文章我暂时也没看很懂,原理部分还有待仔细研习,但值得一提的是,本文的实验做的非常充分,特别是消融实验,做的很严谨,建议看原文学习一下。而且在单阶段GAN大流行的情况下,这篇多阶段GAN仍然有很大的学习和借鉴价值。
这篇论文提出了一个文本到图像的生成模型:ALR-GAN,以改进合成图像的布局。ALR- GAN包括ALR模块和LVR损耗。
ALR模块结合所提出的ALR损失自适应地细化了合成图像的布局结构。LVR损失在细化布局的基础上,进一步细化布局区域内的视觉表现。实验结果和分析证明了这些方案的有效性,ALR模块和LVR损耗提高了其他基于gan的T2I方法的性能。
最后
我们已经建立了T2I研学社群,如果你还有其他疑问或者对文本生成图像很感兴趣,可以私信我加入社群。
加入社群 抱团学习:中杯可乐多加冰-深度学习T2I研习群
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言