深剖 Linux 进程地址空间
目录
-
- 传统艺能
- 内建命令
- 地址空间
- 虚拟地址
- 进程地址空间の意义
- 页表
- mm_struct
- 程序变进程
- 写时拷贝
- fork 的双返回值
- 虚拟地址空间意义
-
- 保护内存
- 功能模块解耦
- 统一视角
传统艺能
小编是双非本科大一菜鸟不赘述,欢迎大佬指点江山,qq-1319365055
此前博客点我!点我!请搜索博主 【知晓天空之蓝】
非科班转码社区诚邀您入驻
小伙伴们,打码路上一路向北,彼岸之前皆是疾苦
一个人的单打独斗不如一群人的砥砺前行
这是我和梦想合伙人组建的社区,诚邀各位有志之士的加入!!
直达: 社区链接点我
倾力打造转码社区微信公众号
 1319365055)
1319365055)

内建命令
假如我们 kill 掉 bash 进程,我们命令行中的进程就会嗝屁,所以命令行中启动的进程,父进程全部都是 bash 进程。
我们知道环境变量具有全局属性,这个全局属性的依据就是环境变量会被子进程继承下去,也就是说只要 bash 一开始就 export 了环境变量, bash 在开枝散叶后的所有子进程的环境变量都会随 bash 份子,但是本地变量不会继承。
那么问题来了,比如我定义一个本地变量,执行一个命令:
str = hello
echo $str
结果是 hello 毫无疑问,但是不是说子进程不继承本地变量吗?这里 echo 是系统指令,那么它本质上也是一个子进程,他是如何处理的本地变量呢?
其实 Linux 下大部分是通过子进程执行,但是还有一部分由 bash 自己执行,他会调用自己对应的函数来完成,这种命令我们称之为内建命令,比如 cd 命令,说白了这种命令系统可信度非常高,bash 决定自己直接执行。
地址空间
我们很早就有说过地址空间的分布,就像我们说 32 位系统下指针大小是 4 字节,因为 4 正好是 32 个比特位,刚好可以表示全 0 到全 1 ,但是地址空间不是以前的非黑即白:
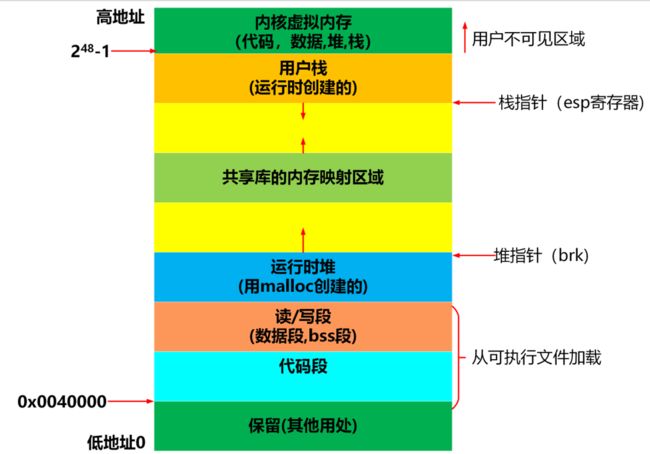
上图是地址空间区域图,之前我们接触的是除开内核的用户空间,现在我们依旧研究这里,这里的共享区可能比较陌生先暂且不谈。
你是否曾经觉得程序地址空间就是内存?不要入了C语言的坑,C语言是没办法讲清楚的,实际上而这俩并不等同,进程地址空间属于操作系统上的概念。
虚拟地址
父子进程读取同一个变量因为地址一样,但后续没有做修改时,父子进程读取的内容却不一样,在 C/C++ 中使用的地址绝对不是物理地址,他叫虚拟地址,又称为线性地址。操作系统不会让我直接看到物理地址,他怕你修改坏坏,但是内存是一个硬件他并不能阻止你去访问,但是他会被动的进行读取和写入。
进程地址空间の意义
每一个进程启动的时候,都会让操作系统给他创建一个地址空间,这个空间就是进程地址空间。
那么操作系统就一定会对这些地址空间进行管理,就会有像管理进程一样产生一个进程地址的结构体: mm_ struct ,他和 PCB 一样是内核的一个数据结构。

我们说过进程具有独立性,多线程运行时,为了独享各种资源期间互不干扰,那么他的数据和代码是独立的,数据结构也是独立的,这是如何维护的呢?
我们可以类比操作系统是一个亿万富翁,而这些进程就像他的私生子,他对每个进程都画了个大饼:进程地址空间!他为了维护进程的独立性,各自不察觉和接触其他进程,让进程觉得 “ 我就是独苗 ” 。因此,进程地址空间的最大意义就是维护进程独立性。
所谓的地址空间其实就是 OS 通过提供一个软件视角,认为自己回独占系统的所有资源(内存)。
页表
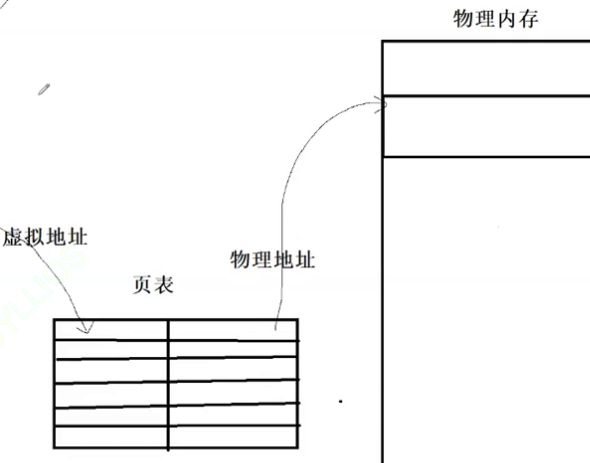
在进程的 PCB 里面,task_struct 会存在一个指针指向另一个描述进程地址空间的结构体 mm_struct,其实他最后抽象出来就是我们的地址空间区域。
当磁盘中数据传输到物理内存时,我们需要将虚拟地址空间和物理内存之间建立映射关系,程序加载到内存变成进程后,操作系统会给每一个进程构建一个页表,地址空间区域其实存的是对应的虚拟地址,虚拟地址传过来在页表中转换成物理地址然后才能找到物理内存地址。
mm_struct
阁下是否听闻传说中的三八线?三八线就是对领地进行划分,我们可以用结构体抽象出来:
struct 38-line
{
int start;
int end;
}
struct 38-line people-A = {0,50};
struct 38-line people-B = {50,100};
如果范围需要调整可以在 end 或者 strat 加上特定调整值即可。由此每个区域范围,都是可以有对应编号的,再进行分区,将每个区域以链表形式组织起来,就可以抽象出 mm_struct 结构:
struct mm_struct
{
long init_start;//全局变量
long init_end;
long uninit_start;//未初始化变量
long uninit_end;
long heap_start;//堆区
long heap_end;
long stack_start;//栈区
long stack_end;
……
}
程序变进程
程序被编译出来但是没有被加载出来,在程序内部他有没有地址?是有的;那么程序内部有没有区域呢?也是有的。
进程在这个区域的地址不是绝对地址而是相对地址,比如我要跑 100 m,但是我的起点定在起跑线前面 10 m,那么我结束就应该在 110 m 处,因此我程序内部的地址和内存中的地址是没有关系的!
磁盘中的代码每一部分在什么区域是已经确定好了的,地址编好加载到内存,起始偏移量从 0 开始由 0000~FFFF 进行编址,磁盘中的虚拟地址转换内存中是不变的,至于加载到了那个地方就由页表进行映射。但是虚拟地址空间不仅仅是操作系统在考虑,还有编译器。
写时拷贝
当父子进程其中有人发生修改时,就会发生写时拷贝去构建新的物理内存,实质虚拟地址是不发生变化的,是改变页表右侧的映射关系,也就能解释内容不一样但是地址一样的情况,通过页表将父子进程以写时拷贝方式进行分离。
不管是写入还是回收,写时拷贝都保证了进程的独立性原则。
fork 的双返回值
fork 的 pid_t id,这个变量是属于父进程栈空间中定义的变量, fork 内部 return 会执行两次,return的本质是通过寄存器将返回值写入到接收变量中。当 id = fork() 时,谁先返回谁就要发生写时拷贝,所以同一个变量会有不同值,本质是因为大家的虚拟地址是一样的,但是物理地址是不一样的!
虚拟地址空间意义
保护内存
如果没有虚拟进程空间,系统会直接加载 PCB ,然后将对应的数据与代码加载到内存中, CPU 执行进程时是没有问题的,但是一旦有 bug ,存在野指针或者越界,我们 CPU 再进行访问不但会影响自己还会影响其他代码,所以裸内存访问这种方法是不安全的!虚拟地址空间相当于一层软硬件层,可以审核转化过程,可以直接拦截非法访问。
功能模块解耦
当我们要 malloc 一段空间的话,地址空间就会帮我们先答应请求,去堆区向上移动出一段空间(这个向上移动其实就是我们 mm_struct 里面 start 和 end 加上一个特定值进行整体移动即可)但是此时他还没有去申请,我们会觉得他已经申请好了,其实是等你真正跑到需要开辟空间时,他会开到你需要的空间,此时空间中可能占有其他进程,系统会挪开其他进程来为你立刻开出这块空间,最大好处就是提高运行效率,你不用就给别人用,你要用我就给你。
内存管理压根不管你你要多大空间,他只负责开好空间,建立映射等你去访问就行了,这就实现了功能模块的解耦。

统一视角
让进程或者程序可以以统一的视角看待内存,他的附加好处就是以统一的方式来编译和加载所有可执行程序,不管什么程序,在他们眼中内存的区域都是自下而上的预留区,代码段,堆区,栈区等等。编译器就可以以统一的方式编址,我们也方便去寻址。