操作系统(第五节) --- ThreadLocal 的简单使用并深扒其实现原理
在多线程环境下, 如果想要保证每个线程都能独立于其它线程独自运行, 可以使用 ThreadLocal 来解决; ThreadLocal 就是用于提供线程局部变量的一个工具, 也就是说 ThreadLocal 可以为每个线程创建一个单独的变量副本; 其概念与同步机制正好相反, 同步机制是保证多线程环境下数据的一致性; 而 ThreadLocal 则是保证多线程环境下数据的独立性.
本文将以代码的形式展示 ThreadLocal 的简单使用方式以及一些内部方法的原理.
ThreadLocal
- 1 ThreadLocal 简单使用
- 2 ThreadLocal 的实现
-
- 2.1 set 方法
- 2.2 get 方法
- 2.3 remove 方法
- 2.4 总结
- 3 (了解) 底层原理实现
-
- 3.1 构造方法
- 3.2 存储结构
- 3.3 存储对象 Entry
- 3.4 保存键值对
- 3.5 获取 Entry 对象
- 3.6 移除指定的 Entry
- 4 关于内存泄露
1 ThreadLocal 简单使用
public static void main(String[] args) {
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
threadLocal.set("我是线程 1");
System.out.println(threadLocal.get());
try {
// 测试如果移除了线程 2 后, 线程 1 是否还能够打印
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadLocal.get());
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
threadLocal.set("我是线程 2");
System.out.println(threadLocal.get());
threadLocal.remove();
System.out.println("线程 2 移除了");
}
});
thread1.start();
thread2.start();
}
}
运行结果:
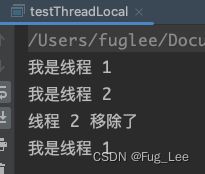
代码解读:
此代码就展示了两个线程环境下独立运行情况, 加入一个 5 s 时间的延迟是为了查看移除线程 2 后, 线程 1 是否还能够正常打印数据; 根据运行结果可以看得出两个线程互不影响.
那么 ThreadLocal 是怎样保证两个线程中的数据都是独立的呢 ¿ ?
2 ThreadLocal 的实现
要想知道 ThreadLocal 的实现原理, 首先要知道两个方法是如何实现的: set 方法, get 方法及 remove 方法.
2.1 set 方法
进入到 set 方法里面, 可以看到如下代码:

- set 方法中的步骤是先获取到当前的线程 (Thread.currentThread()), 然后再去获取到当前线程的 ThreadLocalMap;
- 判断: 如果 ThreadLocalMap 不为空, 就将值保存到 ThreadLocalMap 中, 并用当前的 ThreadLocal 作为 key (map.set(this, value));
- 如果 ThreadLocalMap 为空, 则创建一个 ThreadLocalMap 并给到当前线程, 保存 value 值;
- ThreadLocalMap 就相当于是个 HashMap, 这才是真正保存值的地方.
2.2 get 方法
进入到 get 方法, 代码如下:

- 第一步还是获取到当前的线程 (Thread.currentThread()), 然后获取到当前线程的 ThreadLocalMap;
- 判断: 如果 ThreadLocalMap 不等于空, 就取出当前 ThreadLocal 的值;
- 如果 ThreadLocalMap 为空, 则调用 setInitialValue() 方法返回初始值, 并保存到新创建的 ThreadLocalMap 中 (与 set 方法基本一致).
2.3 remove 方法

remove 方法比较简单, 也是先获取到当前线程的 ThreadLocalMap, 然后删除就可以了.
2.4 总结
- 在上面的三种方法第一步都会获取到当前的线程, 然后通过当前的线程去获取到 ThreadLocalMap, 如果 ThreadLocalMap 为空, 就会创建一个 ThreadLocalMap 并给到当前的线程. 可以看出, 每一个线程都会持有一个 ThreadLocalMap 用来维护线程本地的值.
- 在使用 ThreadLocal 类型变量进行相关操作, 都会通过当前线程获取到 ThreadLocalMap 来完成操作; 每个线程的 ThreadLocalMap 是属于线程自己的, ThreadLocalMap 中维护的值也是属于线程自己的, 这就保证了 ThreadLocal 类型的变量在每个线程中都是独立存在的, 在多线程环境下也互不影响.
3 (了解) 底层原理实现
3.1 构造方法
ThreadLocal 中当前线程的 ThreadLocalMap 为空时会使用 ThreadLocalMap 的构造方法去新建一个 ThreadLocalMap, 如下:

通过源码可以看到, 构造的时候会新建一个 Entry 类型的数组, 并将第一次需要保存的键值存储到一个数组中, 完成一些初始化操作.
3.2 存储结构
ThreadLocalMap 内部维护了一个哈希表来存储数据, 并且定义了加载因子等, 如下所示:

3.3 存储对象 Entry
Entry 用于保存一个键值对, 如下:

3.4 保存键值对
当调用 set 方法将数据保存到哈希表中;

- 首先使用 key 的 threadLocalHashCode 来计算要存储的索引位置, threadLocalHashCode 的值由 ThreadLocal 类管理, 每创建一个 ThreadLocal 对象都会自动生成一个相应的 threadLocalHashCode 值;
- 在保存数据的时候, 如果若索引位置由 Entry, 且里面的 key 为空, 就会执行清除无效的 Entry 操作, 因为 Entry 的 key 使用的是弱引用的方式, key 如果被回收, 这是就无法再访问到 key 对应的 value, 因此需要把无效的 Entry 清除掉腾出空间;
- 当然在调整 table 容量的时候也会先清除无效的 Entry 对象, 然后再根据需要进行扩容操作.
3.5 获取 Entry 对象
取值操作是直接获取到 Entry 对象, 使用 getEntry 方法, 如下:

- 先是使用指定的 key 的 HashCode 计算索引位置;
- 获取到当前位置的 Entry, 如果 Entry 不为 null 且 key 和执行的 key 相等, 则返回该 Entry; 否则就调用 getEnterAfterMiss 方法 (因为可能存在哈希冲突, key 对应的 Entry 的存储位置可能不在 key 计算出的索引位置上, 也就是说索引位置上的 Entry 不一定是 key 对应的 Entry, 所以需要调用 getEnterAfterMiss 方法获取).
3.6 移除指定的 Entry

4 关于内存泄露
在 ThreadLocal 的 get / set / remove 方法中, 都有清楚无效的 Entry 的操作, 这样做的目的就是为了降低内存泄露发生的可能.
导致内存泄露的原因:
假设 Entry 中的 key 没有使用弱引用 (弱引用就是无论空间是否充足, 都可以进行回收, 当然强引用使我们普遍使用的引用)的方式, 由于 ThreadLocalMap 的生命周期和当前线程一样长, 那么当引用 ThreadLocal 的对象被回收后, 由于 ThreadLocalMap 还持有 ThreadLocal 和对应的 value 的强引用, ThreadLocal 和对应的 value 是不会被回收的, 这就导致了内存泄露;
所以 Entry 以弱引用的方式避免了 ThreadLocal 没有被回收而导致的内存泄露, 但是此时的 value 仍然是无法回收的, 依然会导致内存泄露.
但是, ThreadLocalMap 已经考虑到了这种情况的存在, 因此在调用 get / set / remove 方法时会清除掉当前线程 ThreadLocalMap 中所有的 key 为 null 的 value; 这样就降低了内存泄露发生的概率; 所以我们在使用 ThreadLocal 的时候, 每次用完 ThreadLocal 都会调用 remove() 方法, 清除数据, 防止内存泄露.