【B站_刘二大人pytorch深度学习实践】笔记作业代码合集
一、线性模型
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
return x * w
def loss(x,y): #MSE
y_pred = forward(x)
return (y-y_pred) ** 2
w_list = []#权重
mse_list = []#对应权重损失值
for w in np.arange(0.0,4.1,0.1):
print('w=',w)
l_sum = 0
# 从x_data,y_data中取出数据,用zip拼成x_val,y_val
for x_val, y_val in zip(x_data,y_data):
y_pre_val = forward(x_val)#该变量设置目的为打印预测值
loss_val = loss(x_val, y_val)
l_sum += loss_val
print('\t',x_val, y_val, y_pre_val, loss_val)
print("MSE=",l_sum/3)
w_list.append(w)
mse_list.append(l_sum/3)
#画图
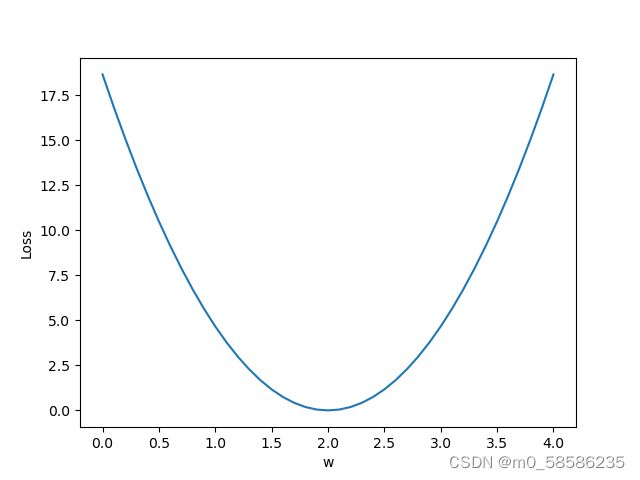
plt.plot(w_list,mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()图像效果:
作业
自定义线性模型y=x*w+b,画出loss和w,b的三维图像
此处设为 y = 2 * x + 3
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import matplotlib
matplotlib.use('TkAgg')
#y=w*x+b
#此处设为 y = 2 * x + 3
x_data = [1.0, 2.0, 3.0]
y_data = [5.0, 7.0, 9.0]
def forward(x):
return w * x + b
def loss(x,y):#MSE
y_pred = forward(x)
return (y-y_pred) ** 2
mse_list = []#对应w权重的MSE
W = np.arange(0.0,4.1,0.1)
B = np.arange(0.0,6.1,0.1)
[w,b] = np.meshgrid(W,B)# [X,Y]=np.meshgrid(x,y) 函数用两个坐标轴上的点在平面上画网格。
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pre_val = forward(x_val)
print(y_pre_val)
loss_val = loss(x_val,y_val)
l_sum += loss_val
fig = plt.figure()
ax = Axes3D(fig) #Axes3D是mpl_toolkits.mplot3d中的一个绘图函数
ax.plot_surface(w, b, l_sum/3) #画曲面图---Axes3D.plot_surface(X, Y, Z)
ax.set_xlabel("W")
ax.set_ylabel("B")
ax.set_zlabel("Cost Value")
plt.show()
图像效果:

若图像窗口显示空白,可参考我另一篇文章:小白解决Pycharm matplotlib 3D绘图显示空白
二、更新权重的方法1——梯度下降算法
普通梯度下降法
通过普通梯度下降法找w,并画出loss和训练轮数epoch的图像
导数计算:

tips:图像锯齿状->指数加权均值 ;cost函数不收敛->训练失败
import matplotlib
import matplotlib.pyplot as plt
matplotlib.get_backend()
x_data = [1.0,2.0,3.0,4.0]
y_data = [2.0,4.0,6.0,8.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x,y in zip(xs, ys):
y_pred = forward(x)
cost += (y-y_pred) ** 2
return cost/len(xs)
def gradient(xs, ys):
grad = 0
for x,y in zip(xs, ys):
grad += 2 * x * ( w * x -y)
return grad/len(xs)
print("Predict(before training)",4,forward(4))
cost_list = []
epoch_list = []
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
cost_list.append(cost_val)
epoch_list.append(epoch)
print("Epoch:",epoch," w=",w," loss=",cost_val)
print("Predict(after training)", 4, forward(4))
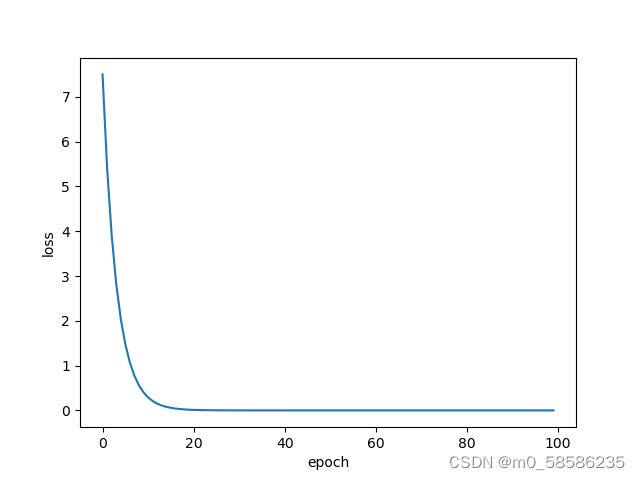
plt.plot(epoch_list,cost_list)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
训练展示:
可能出现的问题:
到达鞍点(损失函数图像上类似平台的段)后梯度为0,参数停止更新
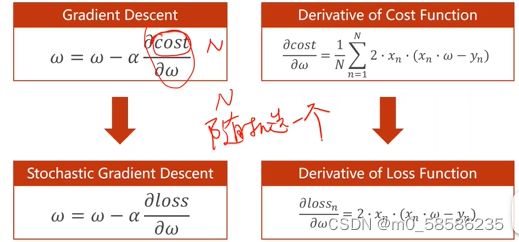
随机梯度下降法SGD
| 梯度下降 | 随机梯度下降 |
|---|---|
| 使用平均损失进行更新 | 随机选取单个样本的梯度进行更新 |
| 单个样本中的噪声可能帮助跨越鞍点 但w具有传递性,无法充分利用并行性提高计算效率 |
|
| 性能低 | 性能高 |
| 时间复杂度低 | 时间复杂度高 |
import matplotlib.pyplot as plt
x_data = [1.0,2.0,3.0,4.0]
y_data = [2.0,4.0,6.0,8.0]
w = 1.0
def forward(x):
return x * w
def loss(x,y): #区别普通梯度下降:损失函数未计算MSE均值
y_pred = forward(x)
return (y - y_pred) ** 2
def SGD(x,y): #区别普通梯度下降
return 2 * x * (w * x -y)
print('Predict(before training)',4,forward(4))
epoch_list = []
loss_list = []
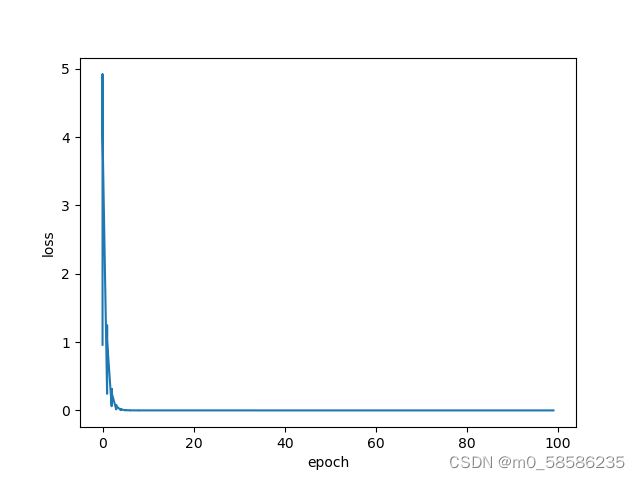
for epoch in range(10):#下左图训练100轮次,右图训练10轮次
for x,y in zip(x_data, y_data): #区别普通梯度下降
grad = SGD(x,y)
w -= 0.01 * grad
print("\tgrad:",x,y,grad)
l = loss(x,y)
epoch_list.append(epoch)
loss_list.append(l)
print('Predict(after training)',4,forward(4))
plt.plot(epoch_list,loss_list)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()训练效果:

三、更新权重的方法2——反向传播
1、当为层数较多的(全连接)神经网络时,参数量激增,无法通过一个一个的梯度计算更新参数,此时需要一种更高效的参数更新方式。
2、为什么要使用激活函数?
假设一个两层的神经网络,在将表达式经过展开整理合并后,相当于一层的神经网络,层数变得无意义。

因此每一层的结果需要经过非线性变换,才能避免上述情况发生。
3、反向传播:本质为链式求导,构建计算图,得到相应导数之后就可再进行权重更新。

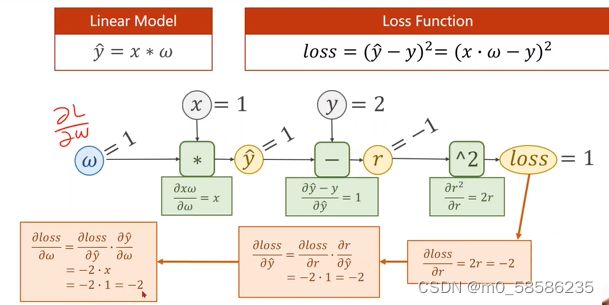
4、在pytorch中,Tensor是构建动态数据图的重要部分,它由权重和对应的梯度构成,这个梯度也是Tensor形式。
代码实现BP:
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0]) #初始权值
w.requires_grad = True #需要计算梯度,默认不更新
def forward(x):
return x * w #Tensor(x)自动类型转换将x转成Tensor
def loss(x, y): #每调用一次loss函数,动态构建一次计算图,而非进行一次乘方运算
y_pred = forward(x)
return (y_pred-y) ** 2
print("predict(before training):", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) # 前向传播计算张量,使用张量构建计算图
l.backward() # 每调用一次backward(),形成一张计算图,自动求出计算图中所有梯度,存入变量中,随即释放该计算图(Pytorch特点)
print('\tgrad:',x,y,w.grad.item()) #将梯度中的数值直接取出成为一个标量
w.data = w.data - 0.01 * w.grad.data #使用梯度的data更新权重,若直接使用梯度,则会构建计算图
w.grad.data.zero_()#梯度权重数据清零,否则下一次的权重会在新计算出的权重基础上加上上次的权重
print("progress:",epoch,l.item())
#不可sum+=l,l为张量,sum为标量,上式使计算图不断扩大可能最终耗尽内存,应为sum+=l.item()
print("predict(after training):", 4, forward(4).item())作业
模型y = ![]() ,损失函数使用MSE,数据不变
,损失函数使用MSE,数据不变
import torch
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
#y = w1 * x^2 + w2 * x +b
w1 = torch.Tensor([1.0])
w1.requires_grad = True
w2 = torch.Tensor([1.0])
w2.requires_grad = True
b = torch.Tensor([1.0])
b.requires_grad = True
def forward(x):#自动类型转换为张量间计算,取值需调用函数.item()
return w1 * x * x + w2 * x + b
def loss(x, y):#自动构建计算图
y_pred = forward(x)
return (y_pred - y) ** 2
print("predict(before training):", 4, forward(4).item())
l_list = []
epoch_list = []
for epoch in range(10):
for x, y in zip(x_data, y_data):
l = loss(x, y) #前向传播,构建计算图
l.backward() #反向传播,构建计算图,自动求出所有参数梯度存入变量后,计算图自动释放
print("\tgrad:",x,y,w1.grad.item(),w2.grad.item(),b.grad.item())
# w1.data = w1.data - 0.01 * w1.grad.item()也行
w1.data = w1.data - 0.01 * w1.grad.data
w2.data = w2.data - 0.01 * w2.grad.data
b.data = b.data - 0.01 * b.grad.data
w1.grad.data.zero_()#权重数据清零
w2.grad.data.zero_()
b.grad.data.zero_()
epoch_list.append(epoch)
l_list.append(l.item())
print("Epoch:", epoch, l.item())
print("predict(after training):", 4, forward(4).item())
plt.plot(epoch_list,l_list)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()四、使用Pytorch框架的线性回归
1、使用Pytorch框架进行神经网络训练过程
①Prepare dataset.
②Design module using class——Inherit from nn.Module
③Constract loss and optimizer——using Pytorch API
④Training cycle——forward, backward, update
2、在Pytorch中,计算图是以mini-batch的形式存在,x,y需要是3x1的Tensor。在计算过程中,使用自动广播机制,将w,b同样扩展成3x1的向量,再进行计算

3、重点:构造计算图->确定x、y维度->确定w,b维度
loss必须是标量,向量无法进行backward->loss求和(结合情况看是否求均值)
4、函数(*args,**kwargs),使用时直接以args/kargs作为变量
args:未定数量变量,以元组形式输出
kargs:未定数量变量,以词典形式输出
import torch
#Pytorch中计算图是mini-batch类型(样本结果一次性求出),X,Y均为3*1张量
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
#将模型定义为类。模型类应该从nn.Module继承,这是对于所有神经网络模型的基本类(所有神经网络的模板)
class LinearModel(torch.nn.Module):#以下两个函数必须都有且如此命名
def __init__(self):
super(LinearModel, self).__init__() #调用父类构造函数
self.linear = torch.nn.Linear(1, 1)#构造对象,可计算x*w+b。.(1,1):(输入特征维数,输出特征维数).
def forward(self, x):#前向计算函数,overwrite父类__call()__(此方法可以使类像函数一样被调用)
y_pred = self.linear(x)#可调用的对象
return y_pred
#不用定义后向传播函数:Moduel构造对象自动根据计算图实现后向
model = LinearModel() #可直接将x送进去model(x)然后被调用求出y^
#构造损失函数和优化器
criterion = torch.nn.MSELoss(size_average=False)#不求均值,默认求均值。求损失,需要y、y_pred
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)#SGD是类,需要实例化,第一个参数是指明需要优化的参数。.parameters()可将模型中需要训练的参数全都找出
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch,loss.item()) #loss是一个对象,打印时会自动调用__str__(),不会产生计算图
optimizer.zero_grad()
loss.backward()
optimizer.step()#根据梯度和学习率自动更新参数
#输出w、b
print('w=',model.linear.weight.item())#.item()显示[[]]中的数值
print('b=',model.linear.bias.item())
#测试模型
x_test = torch.Tensor([[4.0]])#1x1矩阵
y_test = model(x_test)
print('y_pred = ',y_test.data)
作业
使用不同的优化器,比较效果
五、逻辑斯蒂回归
1、使用MNIST数据集时,不能直接输出预测的数字:
图片无法映射成与之对应的大小关系。 部分图片在输入的特征空间中十分类似(如7/9),且类别之间没有数值大小的含义
2、回归输出值连续,分类输出概率
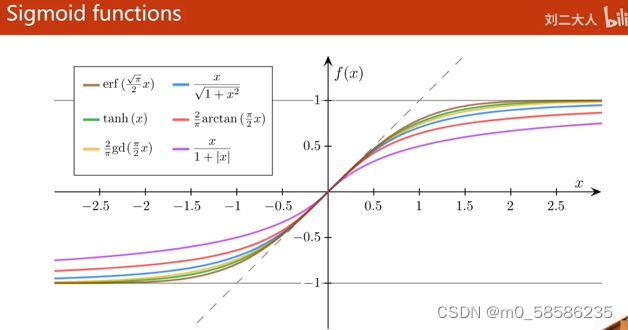
3、Logistic Function:饱和函数——达到某一值后倒数趋近于零,导函数图像类似正态分布 。默认称为Sigmoid
4、sigmoid函数:①函数值在(-1,1) ②增函数 ③饱和函数 。如下图
5、LR计算图

6、损失函数

不再是计算几何度量之间的差距(两个实数值之间的差距,然后使得差距最小化),而是比较两个分布之间的差距。
计算分布之间的差异:KL散度、交叉熵函数Cross-Entropy

此处为二分类交叉熵


代码如下:
import torch
import numpy as np
import matplotlib.pyplot as plt
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[0],[0],[1]])
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.Adam(model.parameters(),lr=0.01)
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
x = np.linspace(0, 10, 200)#0-10区间,取200个点
x_t = torch.Tensor(x).view((200,1))#.view()函数类似reshape()
y_t = model(x_t)
y = y_t.data.numpy() #得到数组
plt.title("Optimizer = SGD")
plt.plot(x, y)
plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()#设置网格线
plt.show()六、处理多维特征输入
1、使用数据集diabetes(糖尿病)如下图(此处为分类问题),将[X][Y]分别读出制成矩阵即可
如果已经安装sklearn,可通过以下路径找到该数据集
..(自己的路径)\Anaconda3\Lib\site-packages\sklearn\datasets\data
2、需要求得模型
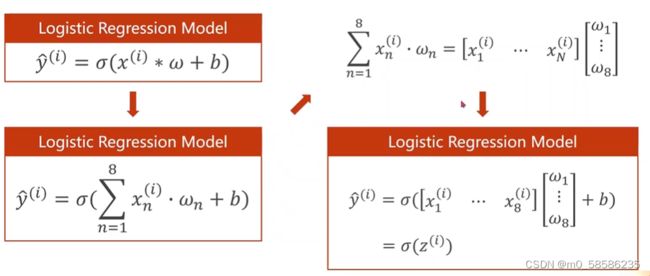
再考虑mini-batch的情况,要将输入的数组转换成矩阵,利用CPU/GPU的并行计算能力提高速度。
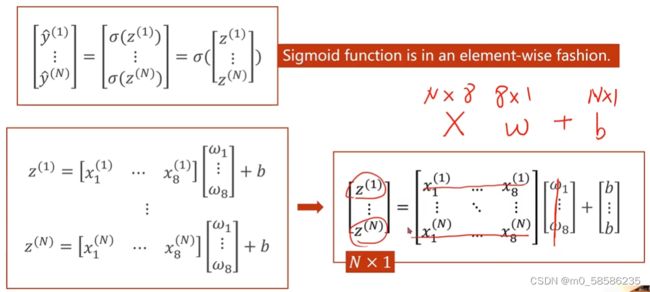
3、矩阵相当于空间变换的函数。我们的目的是将8-D空间映射到1-D空间。而隐层越多,对非线性变换的学习能力越强,但可能会出现过拟合(学习到了样本中的噪声),不利于模型泛化。(具体层次如何划分,可通过超参数搜索。)
4、我们应该具有的能力:读文档+对基本架构(硬件)的理解
5、引入数据集时使用32位float类型,因为通常只有英伟达特斯拉级别显卡支持double类型(float本题也够用)
6、读入数据时的y要以矩阵形式读入(如下左图),否则读入形式如下右图


代码如下:
import torch
import numpy as np
import matplotlib.pyplot as plt
#同目录下需要有diabetes.csv文件,分隔符用逗号,(非英伟达特斯拉等高级显卡)数据类型用float
xy = np.loadtxt('diabetes.csv',delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])#读取所有行,从第一列开始最后一列不要(读前8列x标签)
y_data = torch.from_numpy(xy[:, [-1]]) #读取所有行的最后一列,加中括号为生成矩阵
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid() #运算模块,作为一层,无参数不需要训练
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.Adam(model.parameters(),lr=0.05)
loss_list = []
epoch_list = []
for epoch in range(10000):
#Forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
#Backward
optimizer.zero_grad()
loss.backward()
#Update
optimizer.step()
loss_list.append(loss.item())#应该将标量加入数组,否则为Tensor形式
epoch_list.append(epoch)
#print(epoch_list)
#print(loss_list)
plt.plot(epoch_list, loss_list)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
优化器使用Adam, lr=0.01, epoch=10000
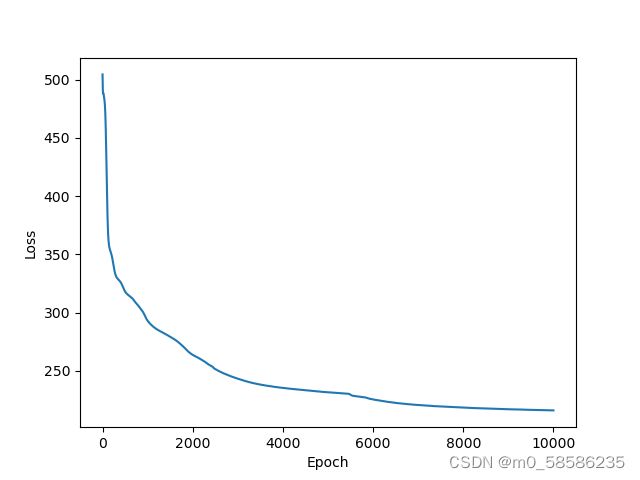
作业
换不同的激活函数(如ReLU),画图比较性能
代码如下:
import torch
import numpy as np
import matplotlib.pyplot as plt
#同目录下需要有diabetes.csv文件,分隔符用逗号,(非英伟达特斯拉等高级显卡)数据类型用float
xy = np.loadtxt('diabetes.csv',delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])#读取所有行,从第一列开始最后一列不要(读前8列x标签)
y_data = torch.from_numpy(xy[:, [-1]]) #读取所有行的最后一列,加中括号为生成矩阵
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.relu = torch.nn.ReLU()
self.sigmoid = torch.nn.Sigmoid() #运算模块,作为一层,无参数不需要训练
def forward(self, x):
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.Adagrad(model.parameters(),lr=0.02)
loss_list = []
epoch_list = []
for epoch in range(10000):
#Forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
#Backward
optimizer.zero_grad()
loss.backward()
#Update
optimizer.step()
loss_list.append(loss.item())#应该将标量加入数组,否则为Tensor形式
epoch_list.append(epoch)
plt.plot(epoch_list, loss_list)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Activation=ReLU Optimizer=Adagrad lr=0.02")
plt.show()
ReLU函数在x<0时取值为零,模型在前馈的最后一层激活函数需要更换成sigmoid
效果展示:
 效果不如激活函数使用Sigmoid
效果不如激活函数使用Sigmoid
七、加载数据集
1、
batch:最大化利用向量计算的优势,提升计算速度
SGD:可以有效跨过鞍点,但一次只送入一个数据,优化时间长
2、
Epoch:One forward pass and one backward pass of all the training examples.(整批数据跑完一次)
Batch-Size:The number of training examples in one forward backward pass.(一次参数更新(前馈、反馈、更新)传入的数据)
Iteration:Number of passes, each pass using [batch size] number of examples.
3、
Dataset
索引方式加载数据。抽象类,不能直接调用,需要先实例化。
加载数据集的方式:①将全部数据放入内存 ②当数据文件过大时,将文件名放入列表,再使用getitem()通过索引根据文件名读入数据
DataLoader
一次拿出一个Mini-batch,训练时需采用双重for循环,读入数据时可采用并行线程。
方法使用:加载数据集,..,..,读入数据集时使用的并行线程数(可以提高读取效率)
但由于windows与Linux处理多线程的库不同,需要在双重for外加上 if __name__ == '__main__' 防止报错
代码如下:
import numpy as np
import torch
from torch.utils.data import Dataset #Dataset抽象类,不能实例化,只能被其他子类继承
from torch.utils.data import DataLoader
#1.Prepars data
class DiabetesDataset(Dataset):
def __init__(self, filepath): #1.所有数据读入内存 2.数据较大,文件名放入列表,后用getitem()方法通过索引读入数据
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]#返回(N,9),取出N
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self, index):#魔法方法,支持通过下标(索引)取数的操作
return self.x_data[index],self.y_data[index] #返回元祖(x,y);分开训练更方便
def __len__(self):#魔法方法,可返回数据条数
return self.len
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)#读入数据时的并行线程数
#2.
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
if __name__ == '__main__':#Windows和Linux下处理多进程的库不同,添加避免报错
for epoch in range(100): # MiniBatch需要的双重循环
for i, data in enumerate(train_loader, 0): # enumerate()获得当前迭代次数。train_loader中拿出的(x,y)元组放入data中
# 1.Prepare data
inputs, labels = data # data拿出x[i]、y[i]放入inputs、labels时自动变成Tensor
# 2.Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3.Backward
optimizer.zero_grad()
loss.backward()
# 4.Update
optimizer.step()
八、卷积神经网络(基础)
九、卷积神经网络(高级)--GoogLeNet,ResNet
十、循环神经网络(基础)
八、循环神经网络(高级)
self-attention
1、What is output?
Each vector has a label.--Seqence Labeling(POS tagging:词性判断,字母识别)
The whole seqence has a label.(Sentiment analysis,判断说话者,判断分子性质)
Module decides the number of labels itself.(Seq2Seq)
2、Seqence Labeling I saw a saw.让机器判断两个saw意思不同-FC可以考虑上下文-window,一个窗口能覆盖一整句?
输入的每句长度不同,事先统计输入的最长句不现实
3、Self-attention Find the relevant vectors in a sequence.-->attention score:Dot-product,Additive-->Extract information based on attention scores.
DNN:Dense/Deep (实际为全连接) 气象数据输入:四天一组,前三天为输入,第四天为输出的标签
RNN:处理序列 RNN Cell:线性层,将n-D映射到m-D 重点在维度
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
#(seq, batch, features)
dataset = torch.randn(seq_len, batch_size,input_size)
hidden = torch.zeros(batch_size, hidden_size) #h0初始全0
for idx, input in enumerate(dataset):
print('=' * 20, idx, '=' * 20)
print('Input size:', input.shape)
hidden = cell(input, hidden)
print('outputs size:', hidden.shape)
print(hidden)
#out, hidden = cell(inputs, hidden) #out:h1,...,hN hidden:hN