Oracle和Mysql的区别
Oracle和Mysql的区别
一、主要区别点
1. 软件规格:
- Oracle是大型数据库,占用内存多;
- Mysql是轻量型数据库,轻量级,内存占用更小;
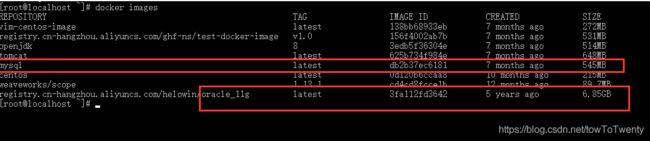
ps: 我用docker拉了一下2者的镜像,mysql大小545M,oracle11g则需要6.85G
2. 费用:
- Oracle收费的
- Mysql免费
3. 数据量
- Oracle单表数据量,可以千万,甚至上亿的规模;
- Mysql单表数据量,最好控制在百万级别;
4. 并发性
- Oracle使用行级别的锁,不依赖索引来锁定某一行,锁资源的粒度小,所以并发性高
- Mysql只有InnoDb支持行锁,而且必须依赖索引才能用到行锁,否则会使用表锁,所以并发性较低
5. 持久性
- Oracle有在线联机日志,可以恢复因为意外宕机导致的数据丢失
- Mysql如果意外宕机,假设数据还没来得及从缓存写入到磁盘,则会出现数据丢失
6. 主从复制
- Oracle支持多机容灾,在主库出现问题的时候,可以自动切换为主库
- Mysql的主从复制比较简单,主库出现问题的时候,需要重新去手动配置哪个是主库
7. 事务隔离级别
- Oracle默认的是 read commited(读已提交)的隔离级别,会有不可重复读+幻读的问题
- Mysql默认是 repeatable read(可重复度)的隔离级别,只会有幻读的问题
8. 权限
- oracle的权限,有用户组的概念;
- mysql的权限,没有用户组的概念;
9. 用法有区别
二、用法区别举例
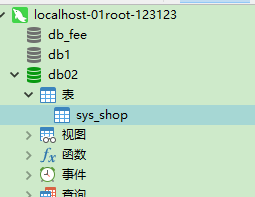
2.1数据库结构层次
- oracle的表,是创建在各个用户下面的;

- mysql的表,是创建在各个数据库下面的;
2.2字段类型
常用的字段类型不一样
- oracle常用的字段类型:数字常用Number、字符常用varchar(2)
- mysql常用的字段类型:数字常用int、double、字符常用varchar
拓展说明:
- oracle的varchar,一般不使用,那个是sql标准的类型,允许空串,oracle自己开发了个类型叫varchar2,不允许存空串,而且可以兼容以后的oracle版本
- oracle虽然有float、binary_float、binary_double,但是和number比起来,有区别:
(1)首先是这3种类型,都不允许指定scale,也就是小数的位数,我尝试了一下这几个字段,scale修改为2,navicat中一点击保存,还是变回了0;
(2)其次binary_float、binary_double,这2个,存储空间更小(number最多需要22个字节存储,而他们,分别需要5个、9个字节来存储)
时间的字段类型不一样
- oracle的时间类型,是date,或者timestamp,包含年月日时分秒
- mysql的时间类型,不但有datetime、timestamp,还有仅仅包含年月日的date,仅仅包含时分秒的time
2.3 id递增的处理
- oracle需要通过手动新建1个序列+触发器来实现;
-- 第一步:创建序列(ps: 也可以通过navicat创建)
create sequence SEQ_T_LOCALOBTMIND
-- 验证序列是否能成功取到值
select SEQ_T_LOCALOBTMIND.nextval from dual
-- 第二步:设置触发器(ps: 请确保表名、字段都是大写的,否则触发器执行会失败)
create or replace trigger T_LOCALOBTMIND_INSERT_ID
before insert on "T_LOCALOBTMIND" for each row
begin
select SEQ_T_LOCALOBTMIND.nextval into:NEW.ID from dual;
end;
-- 第三步:测试
INSERT INTO "T_LOCALOBTMIND"("DDATETIME", "OBTID", "WDIDF") VALUES (TO_DATE('2021-06-03 08:22:04', 'SYYYY-MM-DD HH24:MI:SS'), 'G1121', '11.34');
- mysql则自带自动自增的功能
2.4分页
- oracle需要用rownum 和 子查询来做;
-- 查第10-20条记录。10、20个数字表示记录的行号
select * from (
SELECT emp.*, rownum as rowno from emp
)t_target
where rowno >= 10 and rowno < 20
- mysql直接通过limit就行
-- 查第10-20条记录。第一个10表示起始下标,第二个10表示取多少条记录
SELECT * FROM `tb_user`
limit 10, 10
2.5时间处理
时间相减
- oracle对于计算前7天,时间减7就行了,计算前1个小时,时间减1/24就行了,加法同理:
select TO_DATE('2021-05-30 15:51:20', 'yyyy-mm-dd hh24:mi:ss') -7 from dual;
-- 计算前7天,结果:2021-05-23 15:51:20
select TO_DATE('2021-05-30 15:51:20', 'yyyy-mm-dd hh24:mi:ss') - 1/24 from dual;
-- 计算前1个小时,结果:2021-05-30 14:51:20
- mysql计算前7天,或者前1个小时,需要用不同的关键字:
select date_sub('2021-05-30 21:00:40' ,interval 7 day)
-- 计算前7天,结果:2021-05-23 21:00:40
select date_sub('2021-05-30 21:00:40' ,interval 1 hour)
-- 计算前1个小时,结果:2021-05-30 20:00:40
timestamp类型的时间相减
- oracle中timestamp类型的字段,相减,结果是多少天、多少小时,多少分钟,多少秒
SELECT MIN_T, MAX_T, MAX_T - MIN_T
FROM "T_TIMESTAMP"
-- 结果:2021-07-06 20:29:20.000000 2021-07-07 20:29:22.000000 +000000001 00:00:02.000000
- mysql中,2个timestamp类型的值相减,如果想要知道相差多少天、多少秒,需要借助函数
SELECT min_t, max_t, TIMESTAMPDIFF(second,min_t,max_t) FROM `t_timestamp`
-- 结果:
2021-07-03 21:01:22 2021-07-04 21:01:22 86400
2021-07-04 21:02:01 2021-07-04 21:02:06 5
2021-07-04 21:03:58 2021-07-04 21:04:01 3
字符串转时间
- oracle使用to_date()函数,示例
select TO_DATE('2021-05-30 15:51:20', 'yyyy-mm-dd hh24:mi:ss') from dual;
-- 24小时制的转换,结果:2021-05-30 15:51:20
select TO_DATE('2021-05-30 下午 11:51:20', 'yyyy-mm-dd am hh12:mi:ss') from dual;
-- 12小时制的转换,结果:2021-05-30 23:51:20
- mysql的字符串转时间,使用str_to_date()函数,示例:
select STR_TO_DATE('2021-05-30 15:51:20','%Y-%m-%d %H:%i:%s');
-- 结果:2021-05-30 15:51:20
-- tip: myql的这个格式,也不难记,Y、m、d、H、i、s,只要记住有2个字母是大写的就好了
时间转字符串
- oracle使用to_char()函数,这是一个功能比较强大的函数,能格式化时间、数字
select to_char(current_date, 'yyyy-mm-dd hh24:mi:ss') from dual;
-- 24小时制的转换,结果:2021-05-30 16:06:52
select to_char( TO_DATE('2021-05-30 15:51:20', 'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd am hh12:mi:ss') from dual;
-- 12小时制的转换,结果:2021-05-30 下午 03:51:20
- mysql使用date_format()函数
select DATE_FORMAT(current_timestamp,'%Y-%m-%d %H:%i:%s');
-- 结果:2021-05-30 16:10:14
查询当前的日期+时间
- oracle示例:
select CURRENT_TIMESTAMP from dual;
-- 结果:2021-05-30 16:19:10.640466 +08:00
select current_date from dual;
-- 结果:2021-05-30 16:16:54
select SYSDATE from dual;
-- 结果:2021-06-07 20:54:57
- mysql的话,也有current_timestamp这个查询,但是格式很友好,示例:
select CURRENT_TIMESTAMP;
-- 结果:2021-05-30 16:21:16
select now();
-- 结果:2021-05-30 16:17:41
-- 我一般用这个,比较简单,好记忆
select sysdate()
-- 结果:2021-06-07 20:55:38
2.6字符处理
引号的用法
- oracle的字符串只能用单引号包裹
select concat('%', 'G1120') from dual
-- 结果:%G1120
- mysql的字符串可以用单引号,也可以用双引号包裹
select concat("%", 'G1120')
-- 结果:%G1120
空字符串的情况
- oracle中不允许有空字符串的存在,如果update某个字段为’’,则会发现这个字段值变成null了
- mysql中,允许空字符串
大小写区分
- oracle创建表默认大写,可以设置为小写
-- 如果表名用引号包裹,则区分大小写
CREATE TABLE "TUSER"."t_localobtmind2" (
"ID" NUMBER,
"DDATETIME" DATE,
"OBTID" VARCHAR2 ( 20 ),
"WDIDF" NUMBER ( 10, 2 )
)
-- 结果:生成了一张 t_localobtmind2 的表
-- 默认生成的表名是大写的
CREATE TABLE t_localobtmind3 (
"ID" NUMBER,
"DDATETIME" DATE,
"OBTID" VARCHAR2 ( 20 ),
"WDIDF" NUMBER ( 10, 2 )
)
-- 结果:生成了一张T_LOCALOBTMIND3的表
- mysql创建表默认小写
-- 默认是小写的,无论你是否用引号包裹,生成的表名都是小写的
CREATE TABLE T_TYPE3 (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c_date` datetime DEFAULT NULL,
`c_time` time DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
-- 结果:生成了一张 t_type3 的表
CREATE TABLE `T_TYPE4` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c_date` datetime DEFAULT NULL,
`c_time` time DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
-- 结果:生成了一张t_type4的表
2.7多条件判断
tip: 虽然,网上有的地方说,oracle也有if的用法,不过那个只适用于存储过程存储函数,不适用于单条sql执行
- oracle,惯用decode()函数,另外支持case when的用法:
-- decode()函数
select DECODE(2,
1, '风速',
2, '雨量',
3, '浪高',
null)
from dual;
-- 结果:
雨量
-- case when的写法1:公式匹配
select sal, CASE
when sal >= 5000 then '高薪'
when sal >= 2000 then '中薪'
WHEN sal > 800 THEN '低薪'
ELSE '其它'
END as cn
from emp;
-- 结果:800 其它
1600 低薪
1250 低薪
2975 中薪
...
-- case when的写法2:值匹配
select sal, CASE sal
when 5000 then '高薪'
when 1600 then '中薪'
WHEN 800 THEN '低薪'
ELSE '其它'
END as cn
from emp;
-- 结果:
800 低薪
1600 中薪
1250 其它
2975 其它
...
mysql的条件判断,貌似只有case when这一种比较合适的选择
-- mysql也有decode()函数,不过是用来加密字符串的
select @savePwd:= ENCODE('admin123','diy_key');
select DECODE(@savePwd,'diy_key');
-- 结果:(BLOB) 8 bytes
-- 如果在navicat里面,选择查看-文本,能看到是 admin123
`
-- case when的写法1:公式匹配:
set @var = 2001;
select CASE
WHEN @var >= 5000 THEN '高薪'
when @var >= 2000 then '中薪'
when @var >= 800 then '低薪'
ELSE '其它'
END as cn
-- 结果:中薪
-- case when的写法2:值匹配
-- select @var := 2;
set @var = 2;
select CASE @var
WHEN 1 THEN
'一'
when 2 then
'二'
ELSE
'其它'
END as cn
-- 结果:二
-- mysql的简单条件判断
set @factory=1;
select IF(@factory=1,'风速','其它要素')
-- 结果:
风速
2.8 行号的显示
- oracle可以使用rownum来显示:
select rownum, username from all_users;
-- 结果:
1 TUSER
2 TEST
3 BI
4 PM
5 SH
6 IX
7 OE
8 HR
9 SCOTT
10 OWBSYS_AUDIT
- mysql可以使用变量来实现
SELECT
@rowno:=@rowno+1 as rowno,
t_data.*
from
user_info t_data ,
(select @rowno:=0) t_init;
-- 结果:
1 3 wanger 2 2021-01-31 22:02:18
2 5 aaa 2232 2021-01-31 22:02:17
2.9小数格式化
- oracle使用to_char()函数:
select to_char(211.125456,'99999999999990.99') from dual;
-- 需要四舍五入的情况,结果:211.13
select to_char(211.1,'99999999999990.99') from dual;
-- 小数位不够2位的情况,结果:211.10
select to_char(0,'99999999999990.99') from dual;
-- 特殊值0的情况,结果:0.00
- mysql使用format()函数:
select FORMAT(211.125,2);
-- 需要四舍五入的情况,结果:211.13
select FORMAT(211.1,2);
-- 小数位不够2位的情况,结果:211.10
select FORMAT(0,2);
-- 特殊值0的情况,结果:0.00
2.10查询语句
- oracle的查询必须带from示例:
select current_date from dual; -- 结果:2021-05-30 16:16:54 - mysql的查询,就没强制要求带from关键字,但是查询dual表也支持,示例:
select now(); -- 结果:2021-05-30 16:17:41
2.11行转列的实现
-
oracle行转列,需要借助connect by语法和regexp_substr()函数
select REGEXP_SUBSTR(codes, '[^,]+', 1, rownum) from( select 'G1120,G1121,G1122,G1123' as codes from dual ) t_base connect by rownum <= LENGTH(codes) - LENGTH(REPLACE(codes, ',', '')) + 1 -- 结果: G1120 G1121 G1122 G1123 -- 分析:regexp_substr() 这个函数,可以通过正则去截取某个字符串里面的内容。第一个参数是源字符串,第二个参数是正则表达式,也就是截取规则,第三个参数表示从第几个字符开始匹配正则表达式,第四个参数表示第几个匹配内容 -- 结果: G1120 G1121 G1122 G1123 -- 字符串正则分割 SELECT REGEXP_SUBSTR ('G1120,G1121,G1122,G1123', '[^,]+', 1,2) code from dual -- 结果: G1121 -- 返回第2次匹配到的内容 -- 生成数字序列结果集 select rownum from dual connect by rownum <= 3; -- 结果: 1 2 3 -
mysql的行转列,需要借助 join中on<的特殊用法和substring_index()函数
select SUBSTRING_INDEX(subStr,',', -1) code from( select codes, help_topic_id, SUBSTRING_INDEX(codes,',',help_topic_id + 1) subStr from ( select 'G1120,G1121,G1122,G1123' as codes ) t_base inner join mysql.help_topic t_help on t_help.help_topic_id <= LENGTH(t_base.codes) - LENGTH(REPLACE(t_base.codes,',','')) ) t_with_id -- 思路: -- 通过mysql的一张行转列的辅助表来做,tip: 那张表最多643条记录哦 -- LENGTH(REPLACE(t_code.codes,',','')表示,除去逗号,还有多少个字符 -- LENGTH(t_code.codes) - LENGTH(REPLACE(t_code.codes,',','')) 表示有多少个逗号 -- 第一个SUBSTRING_INDEX()函数,得到的内容,分别是: G1120 G1120,G1121 G1120,G1121,G1122, G1120,G1121,G1122,G1123 -- 第二个SUBSTRING_INDEX()函数,得到的内容,分别是: G1120 G1121 G1122, G1123
三、参考博客
- https://blog.csdn.net/qq_35371323/article/details/95862866(里面提到了内存、费用、隔离级别等)
- https://www.cnblogs.com/xu-cceed3w/p/8824199.html(里面提到了分页、并发性)
- https://www.cnblogs.com/bailing80/p/11440927.html(里面有提到id自增、日期的用法)
- https://zhuanlan.zhihu.com/p/39651803(里面提了数据库结构、字段类型)
- https://blog.csdn.net/andyguan01_2/article/details/86995794(里面有提到单表最佳建议)
- https://blog.csdn.net/weixin_39634067/article/details/113135429(里面有讲mysql可能会丢失数据的原因)