简单易懂又非常牛逼的Spring源码解析,推断构造与bean的实例化
简单易懂又非常牛逼的Spring源码解析,推断构造与bean的实例化
- 原理解析
-
- 实例化bean的入口
- 工厂方法实例化
- 推断构造
-
- 初次筛选
- 二次筛选
- bean的实例化
- 代码走读
-
- 实例化bean的入口
- createBeanInstance方法内部的流程
- 推断构造
-
- 初次筛选
- 二次筛选
- bean的实例化
- 总结
往期文章:
- 人人都能看懂的Spring底层原理,看完绝对不会懵逼
- 简单易懂的Spring扩展点详细解析,看不懂你来打我
- 人人都能看懂的Spring源码解析,配置解析与BeanDefinition加载注册
- 简单易懂又非常牛逼的Spring源码解析,ConfigurationClassPostProcessor的具体逻辑
上一篇文章讲到了ConfigurationClassPostProcessor的具体逻辑,至此所有的配置信息已经被解析成BeanDefinition,注册到容器中了。
下一步就是根据BeanDefinition进行非懒加载的单例bean的实例化。因此,本篇文件就要介绍非懒加载单例bean的实例化过程。
原理解析
实例化bean的入口
要研究bean的实例化,首先就要找到bean的实例化的入口。

- Spring首先会进行配置文件或者配置类的解析,然后生成BeanDefinition并注册到容器中
- 待所有的BeanDefinition都注册完毕后,会遍历每一个BeanDefinition,判断是否是非抽象、单例、非懒加载,如果是,则调用getBean(beanName)方法进行bean的预加载
- 然后会尝试从容器中获取,看是否已经初始化完成,如果没有,则进行bean的实例化
- 而bean的实例化的入口,就是createBeanInstance方法
这个createBeanInstance方法,就是我们这篇文件研究的主体。
工厂方法实例化
bean的实例化有两种方式,一种是工厂方法实例化,一种是构造器实例化。
createBeanInstance方法,首先会检查BeanDefinition中的factoryMethodName属性是否不为空,如果不为空,就会使用工厂方法进行实例化。
我们上一篇文章分析的@Bean注解修饰的方法,生成的BeanDefinition就带有factoryMethodName属性。

如果BeanDefinition中的factoryMethodName属性为空,就要通过构造器进行实例化。
推断构造
构造器实例化,先要进行构造器的挑选。
如果要通过构造器进行实例化的话,就要先挑选一个合适的构造器,因为一个类里面构造器可能有多个。

推断构造:
- 第一步初次筛选,返回一个构造器数组
- 初次筛选返回的构造器数组不为空,或者自动注入模型为构造器注入,或者我们指定了构造器参数,则进行二次筛选,挑出一个最合适的
- 否则走最简单的逻辑,使用无参构造器进行实例化

初次筛选
初次筛选的条件如下,符合条件的构造器,会放到一个数组里面返回。

二次筛选
二次筛选就是从初次筛选的结果中,再筛出一个最合适的。
这里主要就是筛选出要使用的构造器,以及构造器要使用的参数,筛选出的构造器会保存到constructorToUse变量,而构造器要使用的参数则保存到argsToUse变量。
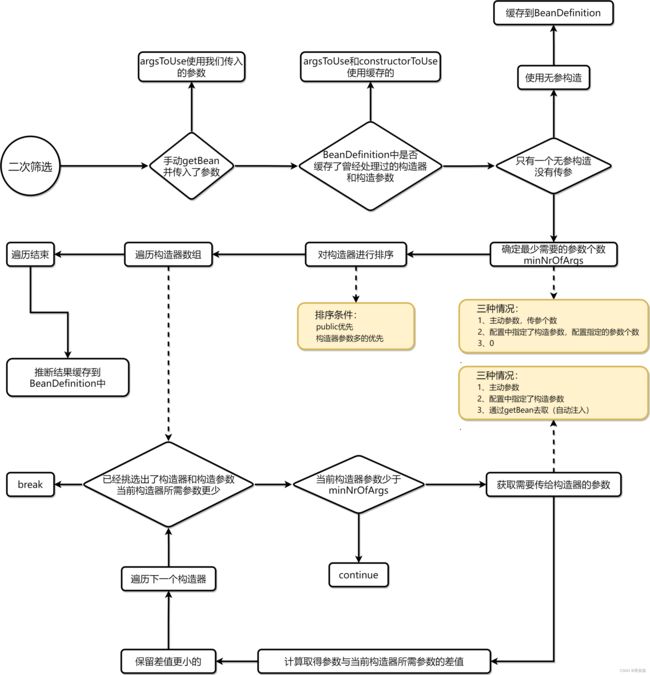
上面这张图就是推断构造二次筛选的流程,比较复杂,这里看不懂的可以忽略,非重点。
- 首先会判断我们是否手动传入了参数,如果是,则使用我们手动传的参数
- 如果我们没有手动传参,则看BeanDefinition中是否缓存了曾经筛选出的构造器和参数,如果是,则使用缓存的
- 如果BeanDefinition没有缓存,看是否只有一个无参构造器,如果是,则使用该构造器,并缓存到BeanDefinition中
- 如果有多个构造器,先确定最少需要的参数个数minNrOfArgs(取值情况看上图)
- 然后对构造器进行排序(排序条件看上图)
- 遍历构造器数组
- 如果已经挑选出最合适的构造器,当前遍历到的构造器需要的参数又更少,则break跳出循环
- 如果当前遍历到的构造器需要的参数个数,少于minNrOfArgs,continue跳过该构造器
- 没有break,也没有continue,那么就要获取当前构造器需要的参数(如何获取看上图)
- 然后计算取得的参数个数和 构造器所需参数间的差值
- 跟之前选出的构造器进行比较,保留差值更小的构造器
- 遍历结束
- 如果不是主动传参的情况,则把筛选结果缓存到BeanDefinition
bean的实例化
经过上面的步骤,现在已经挑选出合适的构造器,或者使用无参构造器。接下来就是要通过构造器,进行反射实例化。

Spring通过InstantiationStrategy(实例化策略),进行bean实例化的。
也就是说,不是直接通过构造器进行反射实例化的,而是再包了一层,提供了一定的可扩展性。我们可以实现自己的InstantiationStrategy,在bean实例化的时候做一些特殊处理。
如果我们没有做特殊处理,那么Spring就会使用SimpleInstantiationStrategy(简单实例化策略),里面才是通过构造器进行反射实例化。
然后会把实例化的bean包装在一个BeanWrapper中返回。
代码走读
上面已经对bean实例化的整个过程介绍完毕,下面是通过代码走读对上面的原理分析进行验证。
实例化bean的入口
首先是在代码中找到bean实例化的入口

验证上面的路径一路跟进去,就到了实例化bean的入口,createBeanInstance方法。

createBeanInstance方法内部的流程
进入createBeanInstance方法内部,可以看到推断构造和实例化的流程。

判断BeanDefinition的factoryMethodName属性是否不为空,如果不为空,则使用工厂方法进行实例化。

如果我们没有主动传参,并且BeanDefinition中的resolvedConstructorOrFactoryMethod为true,resolved变量置为true,表示之前已经处理过,下面不需要再进行推断构造的处理。autowireNecessary变量表示是否需要进行构造器的自动注入,也就是是否是一个有参构造。

之前已经处理过,就直接进行实例化,不需要再次进行构造器的推断。上面是带参构造的实例化,下面是无参构造的实例化。

如果之前没有处理过,就要进行推断构造。determineConstructorsFromBeanPostProcessors方法就是推断构造的初次筛选,返回一个构造器数组。
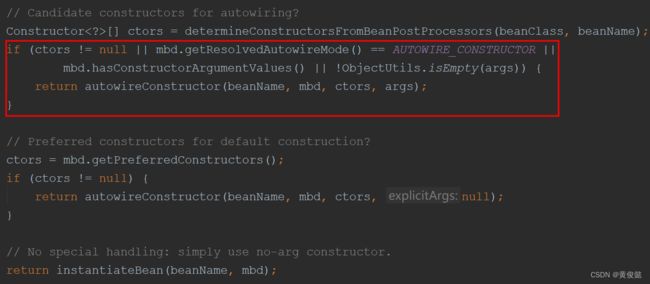
初次筛选返回构造器数组后,如果构造器数组不为空,或者当前BeanDefinition的自动注入模型是构造器注入,或者我们在配置中指定了构造器参数,或者我们主动传递了参数,只有满足这四个条件中的一个,就会调用autowireConstructor方法,里面就包含了二次筛选的逻辑。

四个条件没一个满足,就走最简单的逻辑,使用无参构造器进行实例化。

推断构造
再来看一下推断构造的代码。
初次筛选
determineConstructorsFromBeanPostProcessors方法,就是初次筛选的逻辑。

推断构造的初次筛选,是通过bean后置处理器进行的。如果我们打断点的话,会发现进入到AutowiredAnnotationBeanPostProcessor里面。

双重检测锁,检测缓存中有没有。

缓存中没有,就继续往下走。先取出所有构造器。
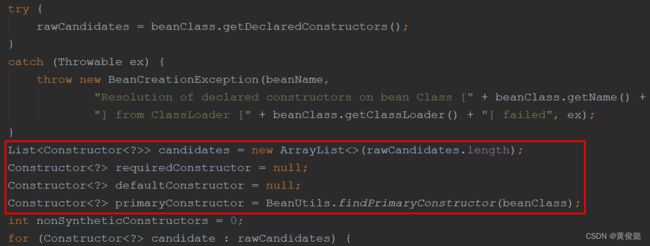
声明四个变量:
- candidates,候选构造器集合,除无参构造外,遍历到的构造器,只要不报错,都会往里面放
- requiredConstructor,@Autowired或@Autowired(required = true)注解修饰的构造器,@Autowired注解的required属性默认为true
- defaultConstructor,无参构造器
- primaryConstructor,直接忽略它,非Kotlin代码就是个null

遍历所有的构造器,寻找构造器上的@Autowired注解。

如果构造器带有@Autowired注解,但是之前已经有一个@Autowired修饰的构造器,那么直接报错。

如果构造器上的@Autowired注解的required属性是true(默认就是true),然后又有其他构造器,也直接报错。

都没有报错,代表目前为止只有为一个并且是@Autowired注解修饰的构造器,赋值给requiredConstructor遍历,并且添加到candidates中。

如果构造器没有@Autowired注解,并且是无参构造器,赋值给defaultConstructor。
然后所有构造器都遍历完毕后,进入下面的逻辑。

如果candidates集合不为空,requiredConstructor为空,defaultConstructor不为空,把defaultConstructor添加到candidates集合。也就是没有@Autowired或者@Autowired(required = true)注解修饰的构造器,只有不带@Autowired注解的构造器或者@Autowired(required = false)注解修饰的构造器,那么把无参构造器添加到candidates集合中,作为返回集。

如果只有一个构造器,并且是一个带参构造,则返回这个构造器。
下面两个else if分支必须primaryConstructor不为null才会进去,但是primaryConstructor是不可能不为null的,所以直接忽略。

剩下一个else分支,返回一个空的构造器数组。

二次筛选
autowireConstructor方法里面,包含了二次筛选的逻辑,也就是从构造器数组中,挑出一个最合适的构造器。

然后里面会new一个ConstructorResolver并调用它的autowireConstructor方法。

两个重要变量,constructorToUse(准备使用的构造器)和argsToUse(准备使用的参数)。

如果我们传递了参数,argsToUse赋值为我们传递的参数。

尝试从缓存中获取之前处理过的构造器和参数。

如果缓存中没有,看是否只有一个构造器,并且我们没有传递参数,而且配置中也没有指定构造参数。如果是,那么把无参构造和空参缓存到BeanDefinition中,然后通过无参构造器进行实例化。

minNrOfArgs,最少需要的参数个数。如果我们传递了参数,就是我们传递的参数个数,如果我们没有传递参数,那么看我们是否在配置中指定了构造器参数,如果指定了,那么就是我们指定的构造器参数个数,否则就是0。

对构造器进行排序。
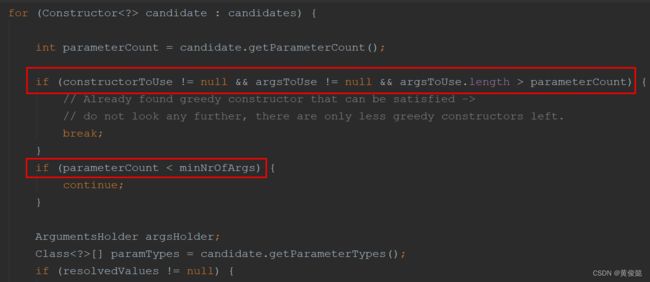
遍历构造器,如果constructorToUse(准备使用的构造器)和argsToUse(准备使用的参数)不为空,而且当前遍历到的构造器参数个数parameterCount少于argsToUse的长度,那么直接break,后面的都不用再遍历了。
如果当前构造器参数个数parameterCount少于minNrOfArgs(最少需要的参数个数),那么continue忽略当前构造器。

获取构造器所需要的参数。

计算取得的参数个数和构造器所需要的参数个数的差值typeDiffWeight,如果差值比之前的还小,就选择当前的构造器,更新constructorToUse和argsToUse,以及minTypeDiffWeight(目前找到的最小参数个数差值)。

如果我们没有传递参数,则把处理结果缓存到BeanDefinition中。然后使用推断出的构造器constructorToUse和构造参数argsToUse进行反射实例化。

bean的实例化
坚持就是胜利,剩下的就是实例化bean的逻辑!

instantiate(beanName, mbd, constructorToUse, argsToUse),使用推断出的构造器constructorToUse和构造参数argsToUse进行反射实例化。
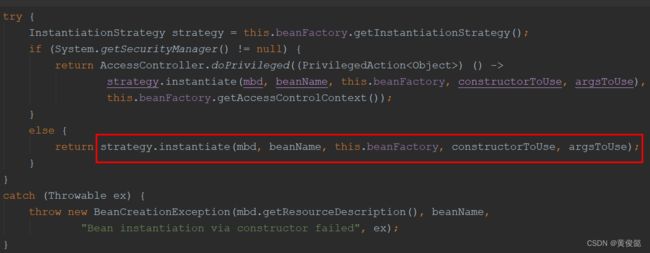
strategy.instantiate(mbd, beanName, this.beanFactory, constructorToUse, argsToUse),调用了InstantiationStrategy(实例化策略)的instantiate方法。

调用了BeanUtils工具类的instantiateClass方法。

最终通过构造器反射实例化。

还有一个使用无参构造进行实例化的方法,也是差不多的逻辑。

getInstantiationStrategy().instantiate(mbd, beanName, parent)也是通过InstantiationStrategy(实例化策略)的instantiate方法进行实例化。
然后可以看到包装成一个BeanWrapper返回。

getInstantiationStrategy().instantiate(mbd, beanName, parent)里面,也是通过BeanUtils工具类的instantiateClass方法进行实例化。

总结
以上就是推断构造与bean的实例化源码解析的所有内容,下面做一个总结。
- 推断构造首先会经过第一次筛选,筛出一个构造器数组
- 然后构造器数组不为空,或者当前BeanDefinition指定为构造器注入,或者我们在配置中指定了构造器参数,或者我们getBean的时候传递了参数,那么就会经历第二次筛选,选出一个最合适的构造器以及构造器参数
- 否则就会使用无参构造器进行实例化
- 然后会通过InstantiationStrategy(实例化策略)进行实例化,里面调用BeanUtils工具类,最终通过构造器进行反射实例化