SpringBoot瀑布流布局分页
普通分页(物理分页)
SpringBoot 通常可以使用 Mybatis的pagehelper插件来进行分页
// 当前页
private int pageNum;
// 每页个数
private int pageSize;
// 当期页的数量
private int size;
// 第几条开始
private int startRow;
// 第几条结束
private int endRow;
// 总页数
private int pages;
// 上一页
private int prePage;
// 下一页
private int nextPage;
// 是否有首页
private boolean isFirstPage;
// 是否有尾页
private boolean isLastPage;
// 是否有上一页
private boolean hasPreviousPage;
// 是否有下一页
private boolean hasNextPage;
//导航页码数
private int navigatePages;
// 页码数
private int[] navigatepageNums;
// 首页
private int navigateFirstPage;
// 尾页
private int navigateLastPage;
示例
{
"code": 200,
"message": "操作成功!",
"data": {
"total": 0,
"list": [],
"pageNum": 1,
"pageSize": 20,
"size": 0,
"startRow": 0,
"endRow": 0,
"pages": 0,
"prePage": 0,
"nextPage": 0,
"isFirstPage": true,
"isLastPage": true,
"hasPreviousPage": false,
"hasNextPage": false,
"navigatePages": 8,
"navigatepageNums": [],
"navigateFirstPage": 0,
"navigateLastPage": 0
},
"at": null
瀑布流分页(逻辑分页)
需求:
1.使用物理分页时,当数据动态加载,数据新增,原第一条数据,会移到第二页,查询结果部分数据会重复;数据减少,第二页的部分数据会移到第一页,查询结果会缺失;
2.滚动条向下滚动能加载数据,向上滚动是也需要能加载数据(类似翻页查找微信聊天记录时新消息进来时的场景)。
显然这种场景下 limit 的物理分页已经不能满足当前的需要,此时引入游标的概念,找到一个排好序的字段,用来做分页的标识,如id。第一次查询,第一页查询出默认的条数,把最后一条的id传给前端,之后前端查询后面的页数是,把这个id带回后端,后面查询时只要在这个id后查询即可
传给前端分页数据
效果
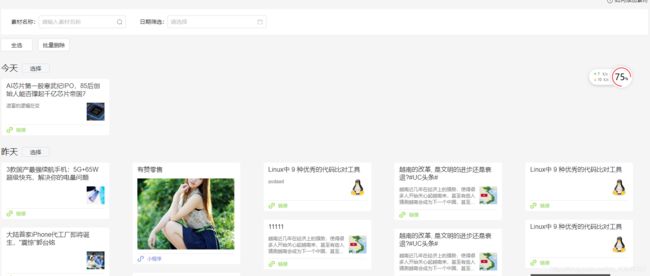
/** 查询下一页的id */
private Integer nextId;
/** 查询上一页的id */
private Integer previousId;
/** 总条数 */
private Integer total;
/** 当前页数量 */
private Integer pageSize;
/** 剩余数量 */
private Integer remain;
java代码
public WxMaterialResp wxMaterialList(String search, Date startTime, Date endTime, String comId, Integer nextId,Integer previousId) {
ArrayList arr = new ArrayList();
List res = wxMaterialGroupQueryMapper.queryMaterialList(search, startTime, endTime, comId, nextId,previousId);
if(previousId!=null){
res=res.stream().sorted(Comparator.comparing(WxMaterialGroupDto::getId).reversed()).collect(Collectors.toList());
}
LinkedHashMap> groupByDay = res.stream().collect(Collectors.groupingBy(WxMaterialGroupDto::getGroupTime, LinkedHashMap::new, Collectors.toList()));
groupByDay.forEach((k, v) -> {
WxMaterialGroupDateDto.WxMaterialGroupDateDtoBuilder builder = WxMaterialGroupDateDto.builder().time(timeFormat(k)).card(v);
v.forEach(f -> {
f.setMsgJson(JSON.parseObject(f.getContent()));
});
builder.card(v);
arr.add(builder.build());
});
WxMaterialResp resp = WxMaterialResp.builder().detail(arr).build();
if(CollectionUtils.isNotEmpty(res)){
if(previousId!=null){
resp.setPreviousId(res.get(0).getId());
}else {
resp.setNextId( res.get(res.size()-1).getId() );
}
}else {
resp.setPreviousId(null);
resp.setNextId(null);
}
/** 剩余条数 */
Integer remain = wxMaterialGroupQueryMapper.materialTotal(search, startTime, endTime,nextId, comId);
/** 总条数 */
Integer total = wxMaterialGroupQueryMapper.materialNum(search, startTime, endTime, comId);
resp.setTotal(total);
resp.setRemain(remain);
resp.setPageSize(res.size());
return resp;
}
SQL语句 (默认一页查询20条数)
// 向下翻页
AND id < #{nextId} ORDER BY id DESC LIMIT 20
// 向上翻页
AND id > #{previousId} ORDER BY id ASC LIMIT 20
// 第一次查询
ORDER BY id DESC LIMIT 20
缺点:
该分页方法只适用于特定的场景,当前排序方法是基于id的排序,(id随着时间的增大而增大),如果不是id与时间的关系这个分页就不适用了