数字集成电路设计-8-一个简单sobel图像边缘检测加速器的设计,实现,仿真与综合
引言
图像视频处理等多媒体领域是FPGA应用的最主要的方面之一,边缘检测是图像处理和计算机视觉中的基本问题,所以也是最常用的,随着数据量的不断增加以及对实时性的要求,一般软件已经不能满足实际需要,这时,就需要专门的硬件来实现加速。本小节就实现一个简单的sobel边缘检测加速器,为了便于对比,我们还编写对应的软件算法。
1,基本思想与算法
Sobel检测法通过一个叫做卷积的过程来估计每个像素点每个方向上的导数值。把中心像素点和离它最近的八个像素点每个乘以一个系数后相加。该系数通常用一个 的卷积表(convolution mask)来表示。分别用于计算x和y方向导数值的Sobel卷积表 Gx和 Gy 如下图所示。
Gx:
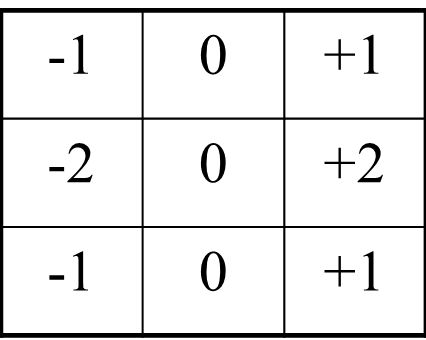 Gy:
Gy: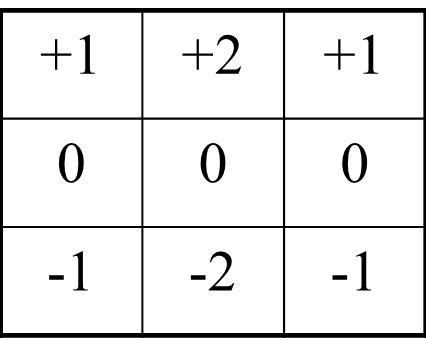
我们把每个像素值分别乘以卷积表中对应的系数,再把相乘得到的九个数相加就得到了x方向和y方向的偏导数值 Dx和 Dy。然后,利用这两个偏导数值计算中心像素
点的导数。计算公式如下:
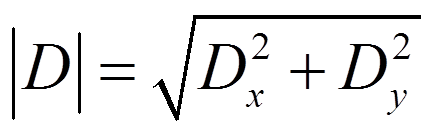
由于我们只想找到导数幅值的最大值和最小值,对上式作如下简化:
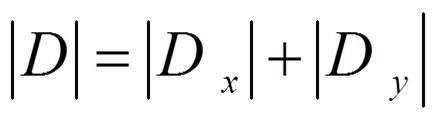
这样近似能够满足计算要求,因为开平方和平方函数都是单调的,实际计算幅度的最大值、最小值与近似以后计算的最大值、最小值发生在图像的同一个地方。并且,与计算平方和开平方相比,计算绝对值所用的硬件资源少得多。
我们需要重复地计算图像中每个像素位置的导数幅值。但是,注意到环绕图像边缘的像素点并没有一个完整的相邻像素组来计算偏导数和导数,所以我们需要对这些像素进行单独处理。最简单的方法就是把图像中边缘像素点的导数值值 |D|设置为0。这可以通过软件来完成。
我们用伪代码来表示该算法。令O[row][col] 表示原始图像的像素点,D[row][col]表示导数图像的像素点,row的范围从0到hight,col的范围从0到width。同时令Gx[i][j] 和 Gy[i][j] 表示卷积表,其中i 和 j 的范围从 -1 到 1.
for( row=1; row<=hight; row=row+1 )
{
for(col=1; col<=width; col=col+1)
{
sumx=0; sumy=0;
for( i = -1; i <= +1; i = i+1)
{
for (j = -1; j<= +1; j = j+1)
{
sumx = sumx + O[row+i][col+j] * Gx[i][j];
sumy = sumy + O[row+i][col+j] * Gx[i][j];
}
}
D[row][col] = abs(sumx) + abs(sumy)
}
}
关于算法的具体细节,我已将PPT上传:
http://download.csdn.net/detail/rill_zhen/6371787
2,硬件实现
一旦明白了sobel的实现算法,我们就可以根据算法来划分模块了,本例中将sobel分成了:addr_gen,compute,machine,sobel_salve四个不同的子模块和sobel一个顶层模块。
需要说明的是,sobel加速器最终要挂载SoC的总线上,所以需要一个统一的接口总线,本例中采用wishbone总线,关于wishbone总线的内容,请参考:http://blog.csdn.net/rill_zhen/article/details/8659788
此外,由于sobel加速器只加速核心的数据处理部分,但是,对于一张完整的图片(例如bmp)还有其文件头,所以bmp的文件头的数据需要事先去掉,当sobel处理完后也需要再加上文件头之后才能用图片阅读器打开。所以我们需要编写相应的软件程序。
下面只给出verilog代码清单:
sobel.v
`timescale 10ns/10ns
module sobel (
//master slave share i/f
clk_i,
rst_i,
dat_i,
dat_o,
//master i/f
cyc_o,
stb_o,
we_o,
adr_o,
ack_i,
//slave i/f
cyc_i,
stb_i,
we_i,
adr_i,
ack_o,
//debug i/f
prev_row_load,
curr_row_load,
next_row_load,
current_state,
int_req//interrupt
);
input clk_i;
input rst_i;
input[31:0] dat_i;
output[31:0] dat_o;
output cyc_o;
output stb_o;
output we_o;
output[21:0] adr_o;
input ack_i;
input cyc_i;
input stb_i;
input we_i;
input[21:0] adr_i;
output ack_o;
output prev_row_load;
output curr_row_load;
output next_row_load;
output[4:0] current_state;
output int_req;
wire start;
wire ack_i;
wire cyc_o;
wire stb_o;
wire we_o;
wire O_base_ce;
wire D_base_ce;
wire done_set;
wire shift_en;
wire prev_row_load;
wire curr_row_load;
wire next_row_load;
wire O_offset_cnt_en;
wire D_offset_cnt_en;
wire offset_reset;
wire[31:0] result_row;
wire[31:0] dat_i;
wire[21:0] adr_o;
wire ack_o;
wire[31:0] dat_o ;
wire[4:0] current_state;
//module sentence
compute compute(
.rst_i(rst_i),
.clk_i(clk_i),
.dat_i(dat_i),
.shift_en(shift_en),
.prev_row_load(prev_row_load),
.curr_row_load(curr_row_load),
.next_row_load(next_row_load),
.result_row(result_row)
);
addr_gen addr_gen(
.clk_i(clk_i),
.dat_i(dat_i),
.O_base_ce(O_base_ce),
.D_base_ce(D_base_ce),
.O_offset_cnt_en(O_offset_cnt_en),
.D_offset_cnt_en(D_offset_cnt_en),
.offset_reset(offset_reset),
.prev_row_load(prev_row_load),
.curr_row_load(curr_row_load),
.next_row_load(next_row_load),
.adr_o(adr_o)
);
machine machine(
.clk_i(clk_i),
.rst_i(rst_i),
.ack_i(ack_i),
.start(start),
.offset_reset(offset_reset),
.O_offset_cnt_en(O_offset_cnt_en),
.D_offset_cnt_en(D_offset_cnt_en),
.prev_row_load(prev_row_load),
.curr_row_load(curr_row_load),
.next_row_load(next_row_load),
.shift_en(shift_en),
.cyc_o(cyc_o),
.we_o(we_o),
.stb_o(stb_o),
.current_state(current_state),
.done_set(done_set)
);
sobel_slave sobel_slave(
.clk_i(clk_i),
.rst_i(rst_i),
.dat_i(dat_i),
.dat_o(dat_o),
.cyc_i(cyc_i),
.stb_i(stb_i),
.we_i(we_i),
.adr_i(adr_i),
.ack_o(ack_o),
.start(start),
.O_base_ce(O_base_ce),
.D_base_ce(D_base_ce),
.int_req(int_req),
.done_set(done_set),
.result_row(result_row)
);
endmodule
addr_gen.v
`timescale 10ns/10ns
module addr_gen(
//input
clk_i,
dat_i,
O_base_ce,
D_base_ce,
O_offset_cnt_en,
D_offset_cnt_en,
offset_reset,
prev_row_load,
curr_row_load,
next_row_load,
//output
adr_o
);
input clk_i;
input[31:0] dat_i;
input O_base_ce;
input D_base_ce;
input O_offset_cnt_en;
input D_offset_cnt_en;
input offset_reset ;
input prev_row_load;
input curr_row_load;
input next_row_load;
output[21:0] adr_o ;
parameter WIDTH = 1024;
reg[19:0] O_base ;
reg[19:0] D_base ;
reg[18:0] O_offset;
reg[18:0] D_offset;
wire[19:0] O_prev_addr;
wire[19:0] O_curr_addr;
wire[19:0] O_next_addr;
wire[19:0] D_addr;
/*******************************************************/
always @(posedge clk_i) //original data offset
if(O_base_ce)
O_base <= dat_i[21:2];
always @(posedge clk_i) //original data offset cnt
if(offset_reset)
O_offset <= 0;
else
if(O_offset_cnt_en)
O_offset <= O_offset+1;
/*******************************************************/
assign O_prev_addr = O_base + O_offset;
assign O_curr_addr = O_prev_addr + WIDTH/4;
assign O_next_addr = O_prev_addr + 2*WIDTH/4;
/*******************************************************/
always @(posedge clk_i) //destination data offset
if(D_base_ce)
D_base <=dat_i[21:2];
always @(posedge clk_i) //destination data offset cnt
if(offset_reset)
D_offset <= 0;
else
if(D_offset_cnt_en)
D_offset <= D_offset+1;
/*******************************************************/
assign D_addr = D_base +D_offset;
/*******************************************************/
assign adr_o[21:2] = prev_row_load ? O_prev_addr :
curr_row_load ? O_curr_addr :
next_row_load ? O_next_addr :
D_addr;
assign adr_o[1:0] = 2'b00;
endmodule
compute.v
`timescale 1000ns/10ns
module compute(
//input
clk_i,
dat_i,
rst_i,
shift_en,
prev_row_load,
curr_row_load,
next_row_load,
//output
result_row
);
input clk_i;
input rst_i;
input[31:0] dat_i;
input shift_en;
input prev_row_load;
input curr_row_load;
input next_row_load;
wire [7:0] D1 ;
output[31:0] result_row ;
reg [31:0] prev_row=0, curr_row=0, next_row=0;
reg [7:0] O[-1:1][-1:1];
reg signed [10:0] Dx=0, Dy=0;
reg [7:0] abs_D = 0 ;
reg [31:0] result_row =0 ;
always@(posedge clk_i)
if(prev_row_load)
prev_row <= dat_i;
else
if(shift_en)
prev_row[31:8] <= prev_row[23:0];
always@(posedge clk_i)
if(curr_row_load)
curr_row<= dat_i;
else
if(shift_en )
curr_row [31:8]<=curr_row[23:0];
always@(posedge clk_i)
if(next_row_load)
next_row<=dat_i;
else
if(shift_en )
next_row [31:8]<=next_row[23:0];
function [10:0] abs ( input signed [10:0] x);
abs = x >=0 ? x : -x ;
endfunction
//comput pipeline
always @(posedge clk_i)
if(rst_i)
begin
O[-1][-1]<=0;
O[-1][ 0]<=0;
O[-1][+1]<=0;
O[ 0][-1]<=0;
O[ 0][ 0]<=0;
O[ 0][+1]<=0;
O[+1][-1]<=0;
O[+1][ 0]<=0;
O[+1][+1]<=0;
end
else
if ( shift_en )
begin
abs_D <= (abs(Dx) + abs(Dy))>>3 ;
Dx <= -$signed({3'b000, O[-1][-1]}) //-1* O[-1][-1]
+$signed({3'b000, O[-1][+1]}) //+1* O[-1][+1]
-($signed({3'b000, O[ 0][-1]}) //-2* O[ 0][-1]
<<1)
+($signed({3'b000, O[ 0][+1]}) //+2* O[ 0][+1]
<<1)
-$signed({3'b000, O[+1][-1]}) //-1* O[+1][-1]
+$signed({3'b000, O[+1][+1]}); //+1* O[+1][+1]
Dy <= $signed({3'b000, O[-1][-1]}) //+1* O[-1][-1]
+($signed({3'b000, O[-1][ 0]}) //+2* O[-1][0]
<<1)
+$signed({3'b000, O[-1][+1]}) //+1* O[-1][+1]
-$signed({3'b000, O[+1][-1]}) //-1* O[+1][-1]
-($signed({3'b000, O[+1][ 0]}) //-2* O[+1][ 0]
<<1)
-$signed({3'b000, O[+1][+1]}); //-1* O[+1][+1]
O[-1][-1] <= O[-1][0];
O[-1][ 0] <= O[-1][+1];
O[-1][+1] <= prev_row[31:24];
O[ 0][-1] <= O[0][0];
O[ 0][ 0] <= O[0][+1];
O[ 0][+1] <= curr_row[31:24];
O[+1][-1] <= O[+1][0];
O[+1][ 0] <= O[+1][+1];
O[+1][+1] <= next_row[31:24];
end
/***********************��ֵ����***********************/
//assign D1 = abs_D < 60 ? 0 : abs_D ;(����ijЩͼ�����б�Ҫʱ�����ã���ֵ60�ǿ��Ը��ĵģ��������ͼ��������)
/*****************************************************/
always @(posedge clk_i)
if(shift_en)
result_row <= { result_row[23:0],/*D1*/abs_D};
endmodule
machine.v
`timescale 10ns/10ns
/*****************FSM***********************/
module machine(
//input
clk_i,
rst_i,
ack_i,
start,
//output
offset_reset,
O_offset_cnt_en,
D_offset_cnt_en,
prev_row_load,
curr_row_load,
next_row_load,
shift_en,
cyc_o,
we_o,
stb_o,
current_state,
done_set
);
input clk_i;
input rst_i;
input ack_i;
input start;
output offset_reset;
output O_offset_cnt_en;
output D_offset_cnt_en;
output prev_row_load;
output curr_row_load;
output next_row_load;
output shift_en;
output cyc_o;
output we_o;
output stb_o;
output[4:0] current_state;
output done_set;
parameter WIDTH = 1024;
parameter HEIGHT = 768;
parameter [4:0] idle =5'b00000,
read_prev_0 =5'b00001,
read_curr_0 =5'b00010,
read_next_0 =5'b00011,
comp1_0 =5'b00100,
comp2_0 =5'b00101,
comp3_0 =5'b00110,
comp4_0 =5'b00111,
read_prev =5'b01000,
read_curr =5'b01001,
read_next =5'b01010,
comp1 =5'b01011,
comp2 =5'b01100,
comp3 =5'b01101,
comp4 =5'b01110,
write_result =5'b01111,
write_158 =5'b10000,
comp1_159 =5'b10001,
comp2_159 =5'b10010,
comp3_159 =5'b10011,
comp4_159 =5'b10100,
write_159 =5'b10101;
reg [4:0] current_state,next_state;
reg [10:0] row; //0 ~ 477;
reg [8:0] col; //0 ~ 159;
wire start;
wire stb_o;
reg offset_reset,row_reset,col_reset;
reg prev_row_load, curr_row_load, next_row_load;
reg shift_en;
reg cyc_o,we_o;
reg row_cnt_en, col_cnt_en;
reg O_offset_cnt_en, D_offset_cnt_en;
reg int_en, done_set, done;
always @(posedge clk_i) //Row counter
if (row_reset)
row <= 0;
else
if (row_cnt_en)
row <= row + 1;
always @(posedge clk_i) //Column counter
if (col_reset)
col <= 0;
else
if (col_cnt_en)
col<= col+1;
//fsm
always @(posedge clk_i) //State register
if (rst_i)
current_state<= idle;
else
current_state<= next_state;
always @*
begin
offset_reset =1'b0;
row_reset =1'b0;
col_reset =1'b0;
row_cnt_en =1'b0;
col_cnt_en =1'b0;
O_offset_cnt_en =1'b0;
D_offset_cnt_en =1'b0;
prev_row_load =1'b0;
curr_row_load =1'b0;
next_row_load =1'b0;
shift_en =1'b0;
cyc_o =1'b0;
we_o =1'b0;
done_set =1'b0;
case (current_state)
idle: begin
cyc_o =1'b0;
we_o =1'b0;
done_set=1'b0;
D_offset_cnt_en =1'b0;
offset_reset =1'b1;
row_reset =1'b1;
col_reset = 1'b1;
if (start)
next_state = read_prev_0;
else
next_state = idle;
end
/*************************************************************/
read_prev_0: begin
offset_reset =1'b0;
row_reset =1'b0;
we_o =1'b0;
row_cnt_en =1'b0;
D_offset_cnt_en =1'b0;
col_reset = 1'b1;
prev_row_load = 1'b1;
cyc_o = 1'b1;
if (ack_i)
next_state = read_curr_0;
else
next_state = read_prev_0;
end
/***********************************************************************/
read_curr_0: begin
col_reset = 1'b0;
prev_row_load = 1'b0;
curr_row_load =1'b1;
cyc_o =1'b1;
if (ack_i) //read mem
next_state = read_next_0;
else
next_state = read_curr_0;
end
/*********************************************************************/
read_next_0: begin
curr_row_load =1'b0;
next_row_load =1'b1;
cyc_o =1'b1;
if (ack_i) //read mem��cnt+=1
begin
O_offset_cnt_en =1'b1;
next_state =comp1_0;
end
else
next_state = read_next_0;
end
/********************************************************************/
comp1_0: begin
next_row_load =1'b0;
cyc_o =1'b0;
O_offset_cnt_en =1'b0;
shift_en =1'b1;
next_state =comp2_0;
end
comp2_0: begin
shift_en =1'b1;
next_state =comp3_0;
end
comp3_0: begin
shift_en =1'b1;
next_state =comp4_0;
end
comp4_0: begin
shift_en =1'b1;
next_state =read_prev;
end
/**************************************************************/
read_prev: begin
shift_en =1'b0;
we_o =1'b0;
col_cnt_en =1'b0;
D_offset_cnt_en =1'b0;
prev_row_load = 1'b1;
cyc_o = 1'b1;
if (ack_i)
next_state = read_curr;
else
next_state = read_prev;
end
read_curr: begin
prev_row_load = 1'b0;
curr_row_load = 1'b1;
cyc_o = 1'b1;
if (ack_i)
next_state = read_next;
else
next_state = read_curr;
end
read_next: begin
curr_row_load = 1'b0;
next_row_load =1'b1;
cyc_o = 1'b1;
if (ack_i)
begin
O_offset_cnt_en =1'b1;
next_state = comp1;
end
else
next_state = read_next;
end
/************************************************************/
comp1: begin
next_row_load =1'b0;
O_offset_cnt_en =1'b0;
cyc_o =1'b0;
shift_en =1'b1;
next_state =comp2;
end
comp2: begin
shift_en =1'b1;
next_state =comp3;
end
comp3: begin
shift_en =1'b1;
next_state =comp4;
end
comp4: begin
shift_en =1'b1;
if (col ==(WIDTH/4-2))
next_state = write_158;
else
next_state = write_result;
end
/********************************************************/
write_result: begin
shift_en =1'b0;
cyc_o =1'b1;
we_o =1'b1;
if(ack_i)
begin
col_cnt_en =1'b1;
D_offset_cnt_en =1'b1;
next_state =read_prev;
end
else
next_state = write_result;
end
write_158: begin
shift_en =1'b0;
cyc_o =1'b1;
we_o =1'b1;
if(ack_i)
begin
col_cnt_en =1'b1;
D_offset_cnt_en =1'b1;
next_state =comp1_159;
end
else
next_state =write_158;
end
/***************************************************************/
comp1_159: begin //pipeline output stage
col_cnt_en =1'b0;
D_offset_cnt_en =1'b0;
cyc_o =1'b0;
we_o =1'b0;
shift_en =1'b1;
next_state =comp2_159;
end
comp2_159: begin
shift_en =1'b1;
next_state =comp3_159;
end
comp3_159: begin
shift_en =1'b1;
next_state =comp4_159;
end
comp4_159: begin
shift_en =1'b1;
next_state =write_159;
end
write_159: begin
shift_en =1'b0;
cyc_o =1'b1;
we_o =1'b1;
if(ack_i)
begin
D_offset_cnt_en =1'b1;
if (row == HEIGHT-3) //sobel done
begin
done_set =1'b1;
next_state = idle;
end
else
begin
row_cnt_en =1'b1;
next_state =read_prev_0;
end
end
else
next_state = write_159;
end
endcase
end
/*******************************************************************/
assign stb_o = cyc_o;
endmodule
sobel_slave.v
`timescale 10ns/10ns
module sobel_slave(
//master slave share i/f
clk_i,
rst_i,
dat_i,
dat_o,
//slave i/f
cyc_i,
stb_i,
we_i,
adr_i,
ack_o,
//output
start,
O_base_ce,
D_base_ce,
int_req,
//input
done_set,
result_row
);
input clk_i;
input rst_i;
input[31:0] dat_i;
output[31:0] dat_o;
input cyc_i;
input stb_i;
input we_i;
input[21:0] adr_i;
output ack_o;
output start;
output O_base_ce;
output D_base_ce;
output int_req;
input done_set;
input[31:0] result_row;
reg int_en;
reg done;
reg ack_o;
reg[31:0] dat_o ;
/*****************************************************************/
assign start = cyc_i && stb_i && we_i && adr_i[3:2] ==2'b01;//adr_i[3:2]
assign O_base_ce = cyc_i && stb_i && we_i && adr_i[3:2] ==2'b10;
assign D_base_ce = cyc_i && stb_i && we_i && adr_i[3:2] ==2'b11;
/*************************************************************/
// Wishbone slave i/f
always @(posedge clk_i)//interrupt reg
if (rst_i)
int_en <= 1'b0;
else
if (cyc_i && stb_i && we_i && adr_i[3:2] ==2'b00)
int_en <= dat_i[0];
/*****************************************************************************/
always @(posedge clk_i) //status reg
if (rst_i)
done <=1'b0;
else
if (done_set)
// This occurs when last write is acknowledged,
// and so cannot coincide with a read of the
// status register
done <=1'b1;
else
if (cyc_i && stb_i && !we_i && adr_i[3:2] ==2'b00 && ack_o)
done <=1'b0;
/********************************************************************/
assign int_req = int_en && done;
/*********************************************************************/
always @(posedge clk_i)
ack_o <= cyc_i && stb_i && !ack_o;
/*********************************************************************/
always @*
if (cyc_i && stb_i && !we_i)
if (adr_i[3:2] == 2'b00)
dat_o = {31'b0,done};// status register read
else
dat_o = 32'b0; // other registers read as 0
else
dat_o = result_row; // for master write
endmodule
3,硬件的功能仿真
在进行仿真之前,我们需要编写相应的仿真模型和相应的图片预处理,后处理程序。
为了便于使用,我已将所有程序上传:
http://download.csdn.net/detail/rill_zhen/6371771
下面是前仿真的结果:从中我们可以看出硬件的执行时间是23562270个cycle,约23.56ms。
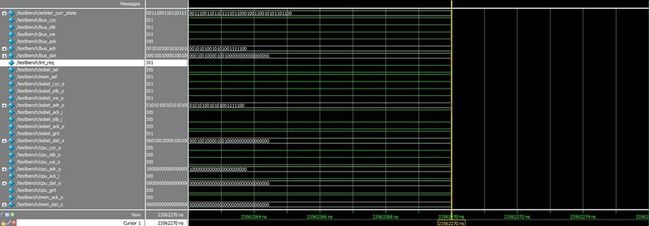
在做功能仿真时,我们就可以得到一个处理结果了,原图和sobel处理结果对比如下:

功能仿真的具体操作步骤,请参考bmp_post目录下的README文件。内容如下:
/* * Rill create * rillzhen@gmail.com */ 1,保证原图为1024x768的8-bit的sobel.bmp 2,运行read_bmp.exe,生成bmp_dat.txt 3,将bmp_dat.txt复制到verilog工作目录,运行仿真,生成post_process_dat.txt 4,将post_process_dat.txt复制到本目录,先运行bmp_process.exe,保持bmp_process.exe运行状态,再执行bmp_bin.exe,最终生成sobel_rst1.bmp,为最终处理结果。
需要注意的是,本例中处理的图片为1024x768的8-bit的bmp文件,如果想处理其他尺寸的bmp文件,需要修改一下testbench.v中的相关内容即可,如果想处理其他格式的图片,则需要重新编写对应的图片预处理,后处理程序。
4,硬件的时序仿真
在最终在FPGA上运行之前,我们还需要做一下时序仿真(后仿),这时就需要用quartusII在综合时生成包含延迟信息的文件(*.vo),还需要quartusII的库。
我们用quartusII将sobel模块的所用可综合文件进行综合,会生成sobel.vo文件和其它vo文件,比如sobel_min_1200mv_0c_fast.vo。
在后仿时,用到的quartus的库文件有:cycloneive_atoms.v , altera_primitives.v。
当然,还需要仿真模型文件:testbench.v ,cpu.v,memory.v,arbiter.v。
经过近半个小时的仿真,结果终于出来了,按照前仿真的步骤,也能得到相同的处理结果。
这里需要注意的是,如果用sobel.vo做后仿时出现hold/setup时序不满足的问题,可以使用sobel_min_1200mv_0c_fast.vo来做后仿。
后仿真的工程,我也已上传:
http://download.csdn.net/detail/rill_zhen/6371857
5,软件实现
为了便于对比硬件的加速效果,我们需要编写相应的软件程序,然后在openrisc上运行,得到运行时间。
下面是C语言实现代码:
bmp.c:
#include <string.h>
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <sys/timeb.h>
#include <time.h>
typedef struct {
double real;
double img;
} COMPLEX;
typedef struct
{
long tv_sec;
long tv_usec;
} timeval;
typedef unsigned char BYTE;
typedef unsigned short WORD;
typedef unsigned long DWORD;
typedef long LONG;
//位图文件头信息结构定义
//其中不包含文件类型信息(由于结构体的内存结构决定,要是加了的话将不能正确读取文件信息)
typedef struct tagBITMAPFILEHEADER {
DWORD bfSize; //文件大小
WORD bfReserved1; //保留字,不考虑
WORD bfReserved2; //保留字,同上
DWORD bfOffBits; //实际位图数据的偏移字节数,即前三个部分长度之和
} BITMAPFILEHEADER;
//信息头BITMAPINFOHEADER,也是一个结构,其定义如下:
typedef struct tagBITMAPINFOHEADER{
DWORD biSize; //指定此结构体的长度,为40
LONG biWidth; //位图宽
LONG biHeight; //位图高
WORD biPlanes; //平面数,为1
WORD biBitCount; //采用颜色位数,可以是1,2,4,8,16,24,新的可以是32
DWORD biCompression; //压缩方式,可以是0,1,2,其中0表示不压缩
DWORD biSizeImage; //实际位图数据占用的字节数
LONG biXPelsPerMeter; //X方向分辨率
LONG biYPelsPerMeter; //Y方向分辨率
DWORD biClrUsed; //使用的颜色数,如果为0,则表示默认值(2^颜色位数)
DWORD biClrImportant; //重要颜色数,如果为0,则表示所有颜色都是重要的
} BITMAPINFOHEADER;
//调色板Palette,当然,这里是对那些需要调色板的位图文件而言的。24位和32位是不需要调色板的。
//(似乎是调色板结构体个数等于使用的颜色数。)
typedef struct tagRGBQUAD {
BYTE rgbBlue; //该颜色的蓝色分量
BYTE rgbGreen; //该颜色的绿色分量
BYTE rgbRed; //该颜色的红色分量
BYTE rgbReserved; //保留值
} RGBQUAD;
void showBmpHead(BITMAPFILEHEADER* pBmpHead)
{
printf("bmp file head:\n");
printf("size:%d\n",pBmpHead->bfSize);
printf("reserved byte1:%d\n",pBmpHead->bfReserved1);
printf("reserved byte2:%d\n",pBmpHead->bfReserved2);
printf("offbit:%d\n",pBmpHead->bfOffBits);
}
void showBmpInforHead(BITMAPINFOHEADER* pBmpInforHead)
{
printf("bmp info head:\n");
printf("structure size:%d\n",pBmpInforHead->biSize);
printf("width:%d\n",pBmpInforHead->biWidth);
printf("height:%d\n",pBmpInforHead->biHeight);
printf("biPlanes:%d\n",pBmpInforHead->biPlanes);
printf("biBitCount:%d\n",pBmpInforHead->biBitCount);
printf("compress type:%d\n",pBmpInforHead->biCompression);
printf("biSizeImage:%d\n",pBmpInforHead->biSizeImage);
printf("X:%d\n",pBmpInforHead->biXPelsPerMeter);
printf("Y:%d\n",pBmpInforHead->biYPelsPerMeter);
printf("colour used:%d\n",pBmpInforHead->biClrUsed);
printf("imp colour:%d\n",pBmpInforHead->biClrImportant);
}
void showRgbQuan(RGBQUAD* pRGB)
{
printf("(%-3d,%-3d,%-3d) ",pRGB->rgbRed,pRGB->rgbGreen,pRGB->rgbBlue);
}
void sobelEdge(BYTE* pColorData, int width,BYTE* lineone,BYTE* linetwo,BYTE* linethree);
int main()
{
timeval tpstart, tpend;
double timeuse;
BITMAPFILEHEADER bitHead;
BITMAPINFOHEADER bitInfoHead;
FILE* pfile;
WORD fileType;
gettimeofday(&tpstart,NULL);
pfile = fopen("./aa.bmp","rb");//打开文件
if(pfile!=NULL)
{
printf("file bkwood.bmp open success.\n");
//读取位图文件头信息
fread(&fileType,1,sizeof(WORD),pfile);
if(fileType != 0x424d/* 0x4d42*/)
{
printf("file is not a bmp file!");
//return 0;
}
fread(&bitHead,1,sizeof(BITMAPFILEHEADER),pfile);
showBmpHead(&bitHead);
printf("\n\n");
//读取位图信息头信息
fread(&bitInfoHead,1,sizeof(BITMAPINFOHEADER),pfile);
showBmpInforHead(&bitInfoHead);
printf("\n");
}
else
{
printf("file open fail!\n");
return 0;
}
if((bitInfoHead.biBitCount!=0x800) && (bitInfoHead.biBitCount!=0x8))
{
printf("not 256 colour bmp error!");
// return 0;
}
FILE *pwrite=NULL;//写sobel之后的图像
pwrite=fopen("Sobel.bmp","wb");
if(pwrite==NULL)
{
printf("new file fail!");
}
fwrite(&fileType,sizeof(WORD),1,pwrite);
fwrite(&bitHead,sizeof(BITMAPFILEHEADER),1,pwrite);
fwrite(&bitInfoHead,sizeof(BITMAPINFOHEADER),1,pwrite);
//读取调色盘结信息
RGBQUAD *pRgb ;
int i;
int rgb2gray;
long nPlantNum = (long)pow(2,(double)8/*bitInfoHead.biBitCount*/);// Mix color Plant Number;
pRgb=(RGBQUAD *)malloc(sizeof(RGBQUAD));
for(i=0;i<=nPlantNum;i++)
{
memset(pRgb,0,sizeof(RGBQUAD));
int num = fread(pRgb,4,1,pfile);
rgb2gray=(300* pRgb->rgbRed+590*pRgb->rgbGreen+110*pRgb->rgbBlue)/1000;
pRgb->rgbRed=rgb2gray;
pRgb->rgbGreen=rgb2gray;
pRgb->rgbBlue=rgb2gray;
fwrite(pRgb,4,1,pwrite);
}
int width = 1024;//bitInfoHead.biWidth;
int height = 768;//bitInfoHead.biHeight;
BYTE *pColorData=(BYTE *)malloc(width); //ad
memset(pColorData,0,width);//ad
BYTE lineone[1024];
BYTE linetwo[1024];
BYTE linethree[1024];
int num=0;
int j=0;
for(num=0;num<height;num++)
{
fread(pColorData,1,width,pfile);
if(num==0)
{
for(j=0;j<width;j++)
{
linethree[j]=pColorData[j];
pColorData[j]=0;
}
fwrite(pColorData,1,width,pwrite);
}
if(num==1)
{
for(j=0;j<width;j++)
{
linetwo[j]=linethree[j];
linethree[j]=pColorData[j];
}
}
if(num==height-1)
for(j=0;j<width;j++)
{
pColorData[j]=0;
fwrite(pColorData,1,width,pwrite);
}
else
{
for(j=0;j<width;j++)
{
lineone[j]=linetwo[j];
linetwo[j]=linethree[j];
linethree[j]=pColorData[j];
}
sobelEdge(pColorData,width,lineone,linetwo,linethree);
fwrite(pColorData,1,width,pwrite);
}
}
fclose(pwrite);
fclose(pfile);
if (bitInfoHead.biBitCount<24)
{
free(pRgb);
}
free(pColorData);
gettimeofday(&tpend,NULL);
timeuse=1000000*(tpend.tv_sec-tpstart.tv_sec)+tpend.tv_usec-tpstart.tv_usec;
printf("sobel_soft Used Time us:%lf\n",timeuse);
return 1;
}
void sobelEdge(BYTE* pColorData, int width,BYTE* lineone,BYTE* linetwo,BYTE* linethree)
{
BYTE area[3][1024];
int i=0;
int j=0;
for(i=0;i<3;i++)
for(j=0;j<width;j++)
{
if(i==0)
area[i][j]=lineone[j];
if(i==1)
area[i][j]=linetwo[j];
if(i==2)
area[i][j]=linethree[j];
}
int temp1=0;
int temp2=0;
int temp=0;
int *tempM=(int *)malloc(3*width*sizeof(int));
memset(tempM,0,3*width);
int m=0;
int n=0;
for(m=0;m<2;m++)
for(n=0;n<width;n++)
{
if((m==1)&&(n!=width-1)&&(n!=0))
{
temp1=area[m+1][n-1]
+2*area[m+1][n]
+area[m+1][n+1]
-area[m-1][n-1]
-2*area[m-1][n]
-area[m-1][n+1];
temp2=area[m-1][n+1]
+2*area[m][n+1]
+area[m+1][n+1]
-area[m-1][n-1]
-2*area[m][n-1]
-area[m+1][n-1];
// temp=(int)((double)sqrt((double)(temp1*temp1))+(double)sqrt((double)(temp2*temp2)));
temp = (int)(abs(temp1) + abs(temp2));
if(temp>255)
{
temp=255;
}
if(temp<0)
{
temp=0;
}
tempM[m*width+n]=(BYTE)temp;
}
else
{
area[m][n]=0;
temp=area[m][n];
}
}
for(n=0; n<width; n++)
{
pColorData[n]=tempM[1*width+n];
}
free(tempM);
return;
}
在虚拟机下编译:or32-linux-gcc bmp.c -o sobel
copy到开发板上执行,得到打印结果如下:从中可以看出,软件执行时间为17972.718ms。时间对比=762.76倍。硬件加速效果明显。当然,实际情况比较复杂,不可能会达到这么多。
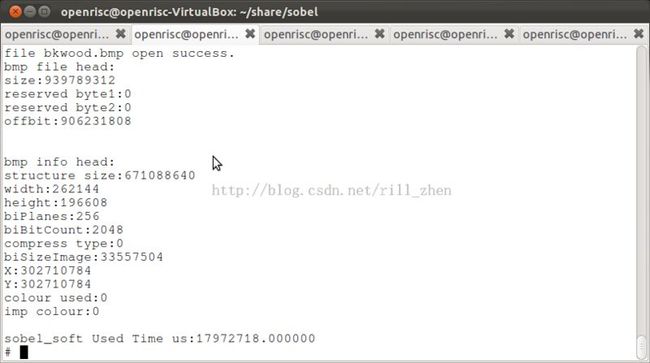
软件处理结果:与硬件处理结果有所差别,原因是处理算法和预处理有所区别,但区别不大。

6,小结
本小节设计实现了一个简单的sobel减速器,并编写了相应的软件,与之对比,加速效果明显。