【网络编程系列_01 】Linux内核启动与收包分析
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第1天,点击查看活动详情
前言:
1. 最近在学习netty,由于源码中有很多和网络连接,读取数据等这些和网络编程密切相关的东西(因为netty本身定位就是网络编程框架)。 我自认为如果不去一探究竟,可能会对以后或者当前的学习造成障碍,同时我也深知,对底层实现理解的越深,上层的框架分析起来其实 就很简单了,有种 “透视” 的感觉。我觉得“透视” 这个词用在这里真的是在恰当不过了! 2. 因为Linux源码太多,所以在涉及到源码时,我们将去繁化简,紧抓要点,旁枝末节不再过多讨论(但是源码注释我一般都保留,同时文件路径我也会给出,这样方便查找)。 3. 本文对应的Linux源码版本为 Linux-3.10.1 4. 本文采用总分总的方式来展开,如此: 准备+概览 -> 展开 -> 理论+实际演示 -> 总结 。 5. 由于避免让字数过于长,代码片段占比过大,所以很多贴出来的代码是删减后的,只保留了和我们相关的, 想下载完整版本请移步 https://github.com/torvalds/linux 进行下载学习。
一、开篇前的准备工作
由于本文将是一篇很长的文章,而且内容比较多,比较杂,为了不使读者发懵,我们先做一下开篇前的准备工作
本文将结合linux源代码和几篇大佬的博客,来做分析。因为时间&技术有限,很难去真实的一行行调试linux源码,所以本篇不是一篇实战型文章,更多的,我们将从理论+源码的方式,来分析内核启动,以及收包的流程。
问题与一些说明
为了避免开篇显得很唐突,我们在这里先放出两个问题(注意:这俩问题会贯穿整个文章)以及几张图,好知道我们接下来大概要说个什么。 1. 问题1: 在收发数据包之前,底层系统做了哪些准备工作? 1. 问题2: 接收到数据包后,内核是如何处理的?又是如何向上给到应用层的?其实对应的就是下图 (一张自己画的tcp工作示意图) 里边的 节点R!!! (注:R代表receive) 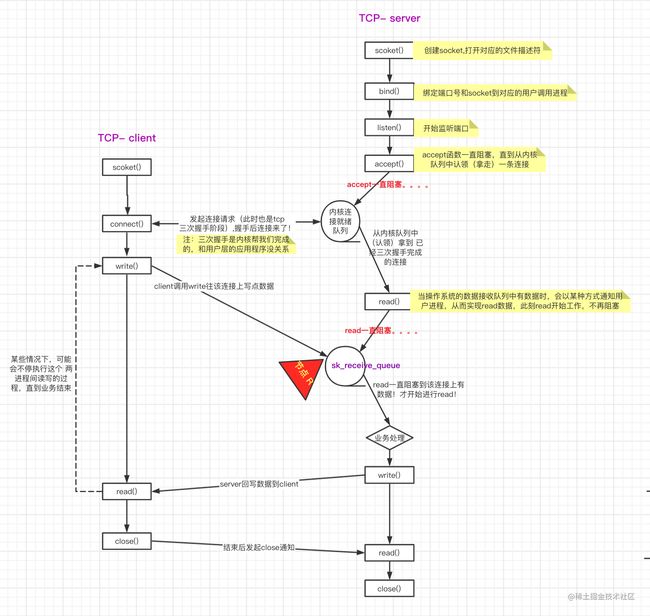 1. 说明: 系统分层与网络抽象模型(OSI)对应关系:
1. 说明: 系统分层与网络抽象模型(OSI)对应关系: 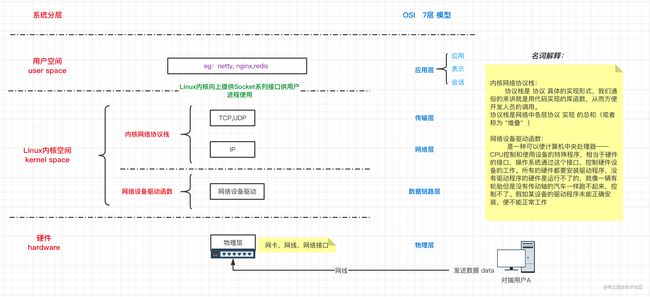
二、Linux收包总览
一些说明:
- 在Linux的源码中,网络设备驱动对应的逻辑位于
drivers/net/ethernet, 其中intel系列的网卡驱动在drivers/net/ethernet/intel目录下。协议栈模块代码位于kernel和net目录。 当设备上有数据到达的时候,先通过DMA将数据放到内存中,然后给CPU的相关引脚上触发一个电压变化(其实就是发出硬中断通知),以通知CPU来处理数据。对于网络模块来说,由于处理过程比较复杂和耗时,如果在中断函数中完成所有的处理,将会导致中断处理函数(优先级过高)将过度占据CPU,将导致CPU无法响应其它设备,例如鼠标和键盘的消息。因此Linux中断处理函数是分上半部和下半部的。上半部是只进行最简单的工作,快速处理然后释放CPU,接着CPU就可以允许其它中断进来。剩下将绝大部分的工作都放到下半部中,可以慢慢从容处理。2.4以后的内核版本采用的下半部实现方式是软中断,由ksoftirqd内核线程全权处理。和硬中断不同的是,硬中断是通过给CPU物理引脚施加电压变化,而软中断是通过给内存中的一个变量的二进制值以通知软中断处理程序 (该程序是内核初始化时候就注册了的)。
何为中断,有哪几种类型?
- 何为中断: CPU 通过时分复用来处理很多任务,这其中包括一些硬件任务,例如磁盘读写、键盘输入,也包括一些软件任务,例如网络包处理。 在任意时刻,一个 CPU 只能处理一个任务。 当某个硬件或软件任务此刻没有被执行,但它希望 CPU 来立即处理时,就会给 CPU 发送一个中断请求 —— 希望 CPU 停下手头的工作,优先服务“我”。
中断是以事件的方式通知 CPU 的,因此我们常看到 “XX 条件下会触发 XX 中断事件” 的表述。- 两种中断类型: 中断分为硬中断和软中断。 硬中断:(外部或硬件产生的中断,例如键盘按键,cpu引脚的电压变化等)。软中断:(软件产生的中断(比如标记一个变量值,有轮询函数去检测该值,符合某种条件后做一定的处理))
Linux收包总览【示意图】重要
下边我们画一张示意图,来概览一下数据是如何从(物理层)网卡到我们的用户空间的(或者说linux的收包过程) 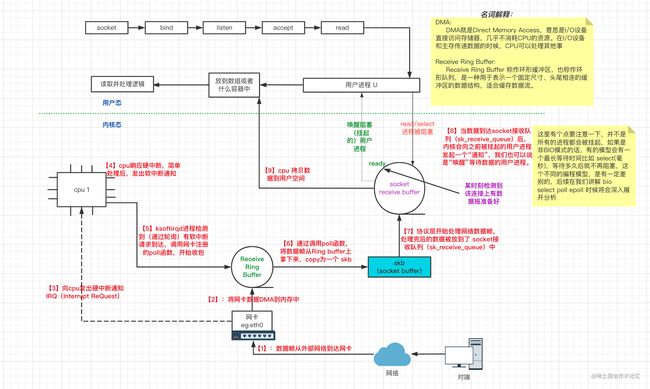
我们对上图做个简单的解释(其实图中已经很详细了) 1. 当网卡上收到数据以后,内核中第一个工作的模块是网络驱动。网络驱动会以DMA的方式把网卡上收到的帧写到内存里,对应图中 【1】【2】。 1. 再向CPU发起一个中断,以通知CPU有数据到达。 对应图中 【3】。 1. 当CPU收到中断请求后,会去调用网络驱动注册的中断处理函数。网卡的中断处理函数并不做过多工作,只是发出软中断请求,然后尽快释放CPU 对应图中 【4】。 1. ksoftirqd 轮询进程检测到有软中断请求到达,调用poll开始轮询收包,并将收到的数据包封装为skb 对应图中 【5】【6】 , 1. 收到后交由各级协议栈处理。对于TCP包来说,会被放到用户socket的接收队列中对应图中 【7】。 1. 如果用户进程是阻塞(同步i/o模型)的方式调用内核函数,此刻将检测到接收队列有数据,于是唤醒阻塞的进程,cpu开始copy数据到用户进程。如果用户是阻塞(i/o多路复用)方式调用内核函数,那么当数据报准备好时,内核将返回用户进程一个可读条件(本质上也是一个唤醒操作),随后进行cpoy操作。如果用户是以阻塞(信号驱动)方式调用的内核函数,那么当数据报准备好时,内核将给用户进程递交一个信号量 SIGIO(其实也是唤醒操作),随后进行copy操作.(关于几种io模型请参见我的另一篇文章【Netty系列_1】Netty简介与I/O&线程模型 此步骤对应图中【8】 1. 之后用户进程开始对copy到用户空间的数据(一般都放到了数组(如netty的ByteBuffer),或者链表中等等)进行读取和处理 (注意这个过程会伴随这一次进程状态切换,即从内核态切换为用户态), 此步骤对应图中【9】
到此,我们的准备工作和概览基本就差不多了,有了这些准备工作,我想在后续的学习中,会更加容易一些。因为linux内核真的是太复杂了,如果开篇直述,可能很多人都不知道说了个啥。 ps: 概览图是很重要的,将图牢牢记住,对学习这些东西将会事半功倍。
在下边的文章中,我们将围绕上边目录
【问题与一些说明】中的【问题1】和【问题2】来展开。过于细节的我们直接略过,不再纠缠。
接下来,让我们带着【问题与一些说明】中的【问题1】来展开本章节的内容!
三、Linux内核启动与初始化
Linux在收包之前,需要启动和初始化一些模块包括以下几个: - 初始化/启动一些基本函数或者线程(如 ksoftirqd 内核线程 ) - 注册各协议对应的处理函数 - 网络子系统初始化 - 网卡启动
上边只是列了个主要,事实上准备工作远不止这些,在以上几个流程都走完后,Linux才可以进行收包。紧接着我们对上边这几项做一个展开。
内核启动入口总览
首先我们找到Linux内核启动入口函数 start_kernel 该函数里边有100多个方法调用,是一个初始化大杂烩 源代码有点长,我这里挑几个看一下:
```c 文件路径: /linux-3.10.1/init/main.c
asmlinkage void init startkernel(void) { char * commandline; extern const struct kernelparam _startparam[], stopparam[] /* * Need to run as early as possible, to initialize the * lockdep hash: / lockdep_init(); smp_setup_processor_id(); debug_objects_early_init(); / * Set up the the initial canary ASAP: / boot_init_stack_canary(); cgroup_init_early(); boot_cpu_init(); ... page_address_init(); pr_notice("%s", linux_banner); setup_arch(&command_line); mm_init(); sched_init(); local_irq_disable(); console_init(); early_boot_irqs_disabled = true; / init some links before initISAirqs() / early_irq_init(); init_IRQ(); tick_init(); init_timers(); hrtimers_init(); softirq_init(); timekeeping_init(); time_init(); ... vfs_caches_init(totalram_pages); / Do the rest non-_init'ed, we're now alive */ restinit(); } ``` 捡几个函数进行简单说明: - (setuparch:系统架构初始化函数) - (mminit:内存初始化函数) - (schedinit:内核系统调度器) - (initIRQ:中断初始化函数) - (consoleinit:终端打印函数初始化) - (vfscachesinit:虚拟文件系统初始化) - (restinit:fork 出用户进程) - .....
完成内核本身的各方面设置,目的是最终建立起基本完整的 Linux 内核环境
创建 ksoftirqd 内核线程
首先我们要说明,ksoftirqd函数非常重要(因为他是软中断的核心逻辑)
小提示:每个处理器都有自己的内核线程,名字叫做
ksoftirqd/n,n是处理器的编号
内核初始化的入口是从start_kernel开始的,文字描述不太直观,让我们直接看一个示意图来一览ksoftirqd内核线程是如何创建的吧。 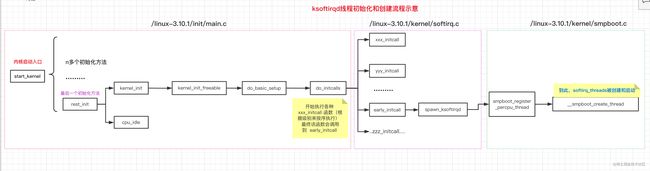
- 顺着上图,我们来简单看下源码:(源码绝对路径在上图中可以找到)
```c
linux-3.10.1/init/main.c asmlinkage void init startkernel(void) { char * commandline; extern const struct kernelparam _startparam[], stopparam[]; ..... /* Do the rest non-_init'ed, we're now alive */ restinit(); } ```
```c linux-3.10.1/init/main.c
static noinline void _initrefok restinit(void) { int pid; rcuschedulerstarting(); kernelthread(kernelinit, NULL, CLONEFS | CLONE_SIGHAND); ... } ```
```c linux-3.10.1/init/main.c
static int _ref kernelinit(void *unused) { kernelinitfreeable(); asyncsynchronizefull(); ... panic("No init found. Try passing init= option to kernel. " "See Linux Documentation/init.txt for guidance."); } ```
```c linux-3.10.1/init/main.c
static noinline void _init kernelinitfreeable(void) { waitforcompletion(&kthreadddone); ... dobasicsetup(); if (sysopen((const char _user *) "/dev/console", ORDWR, 0) < 0) prerr("Warning: unable to open an initial console.\n");
}
```
```c linux-3.10.1/init/main.c
/* * Ok, the machine is now initialized. None of the devices * have been touched yet, but the CPU subsystem is up and * running, and memory and process management works. * * Now we can finally start doing some real work.. / static void __init do_basic_setup(void) { cpuset_init_smp(); usermodehelper_init(); shmem_init(); driver_init(); init_irq_proc(); do_ctors(); usermodehelper_enable(); do_initcalls(); } c static struct smp_hotplug_thread softirq_threads = { .store = &ksoftirqd, .thread_should_run = ksoftirqd_should_run, .thread_fn = run_ksoftirqd, .thread_comm = "ksoftirqd/%u", }; static __init int spawn_ksoftirqd(void) { register_cpu_notifier(&cpu_nfb); BUG_ON(smpboot_register_percpu_thread(&softirq_threads)); return 0; } early_initcall(spawn_ksoftirqd); **小疑问:+重点:** 为甚么从`do_initcalls`就能直接调到`early_initcall`? 是因为内核中有这么一段代码,他将会遍历这个数组,并将其值拼接到initcall上(***注意:这个逻辑很重要,他是linux内核初始化各个模块的初始方法!``***),然后执行拼接后的函数 **(我们将拼接函数名然后挨个执行拼接后的函数的逻辑用logic A `来表示,后边我们可能会用到 )*,(ps:我个人感觉这有点像java中的反射)
c static char *initcall_level_names[] __initdata = { "early", "core", "postcore", "arch", "subsys", "fs", "device", "late", };
注意:上边的 logic A 是一个重点:比如初始化网络子系统就调用 subsys_initcall, 初始化协议栈就进入 fs_initcall, 一些最基本的东西就调用 early_initcall(比如我们本小节ksoftirqd线程的创建就是在early_initcall中进行的) 等等, 事实上,我们可以根据这些单词,知道对应的 xxxinitcall 大概是做啥的!在下边的章节中,我们还会提到这个 xxxinitcall 所以这里需要重点关注一下!!!
...下边创建线程的逻辑不贴了 ,要不代码占用篇幅太多了
到这里看下我本机上的这些
ksoftirqd线程:(可见每个cpu对应一个ksoftirqd线程! )
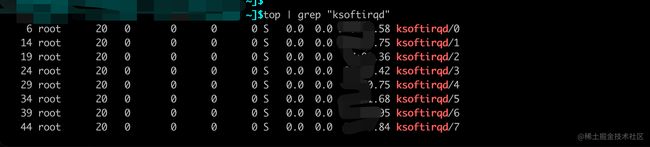
小贴士: 当ksoftirqd被创建出来以后,它就会进入自己的线程循环函数
run_ksoftirqd了 (当然前提是ksoftirqd_should_run返回true )。run_ksoftirqd中有个do while循环,他将会不停地判断有没有软中断需要被处理。这里需要注意的一点是,软中断不仅仅只有网络软中断,还有其它类型。 如下:
```c
文件位置:include/linux/interrupt.h /* PLEASE, avoid to allocate new softirqs, if you need not really high frequency threaded job scheduling. For almost all the purposes tasklets are more than enough. F.e. all serial device BHs et al. should be converted to tasklets, not to softirqs. / enum { HI_SOFTIRQ=0, TIMER_SOFTIRQ, NET_TX_SOFTIRQ, NET_RX_SOFTIRQ, BLOCK_SOFTIRQ, BLOCK_IOPOLL_SOFTIRQ, TASKLET_SOFTIRQ, SCHED_SOFTIRQ, HRTIMER_SOFTIRQ, RCU_SOFTIRQ, / Preferable RCU should always be the last softirq */
NR_SOFTIRQS}; ```
总之到这里,我们心中已经有个大体流程了:原来ksoftirqd线程是这么个创建时机和流程!
同时: 我们要明白,ksoftirqd线程被创建后, 就启动了循环函数run_ksoftirqd了 ,这个函数挺重要的,是处理软中断通知的入口。ps:(其实我感觉可以这个循环函数和Netty中的NioEventLoop的run()函数很像有没有?)
我们看下软中断处理相关入口代码:(这里我们不做过多的展开,后续在收包过程中,会重温下边这块的代码逻辑)
```c /Users/hzz/myselfproject/linuxsource_code/linux-3.10.1/kernel/softirq.c
static void runksoftirqd(unsigned int cpu) { localirqdisable(); if (localsoftirqpending()) { //软中断逻辑入口 _dosoftirq(); rcunotecontextswitch(cpu); localirqenable(); condresched(); return; } localirqenable(); } //重要的一个函数 是软中断处理逻辑的入口 asmlinkage void _dosoftirq(void) { pending = localsoftirqpending(); accountirqentertime(current); /* Reset the pending bitmask before enabling irqs */ setsoftirqpending(0); localirqenable(); h = softirqvec; do { if (pending & 1) { kstatincrsoftirqsthiscpu(vecnr); tracesoftirqentry(vecnr); h->action(h); tracesoftirqexit(vecnr); if (unlikely(prevcount != preemptcount())) { printk(KERNERR "huh, entered softirq %u %s %p" "with preemptcount %08x," " exited with %08x?\n", vecnr, softirqtoname[vecnr], h->action, prevcount, preemptcount()); preemptcount() = prevcount; } rcubhqs(cpu); } h++; pending >>= 1; } while (pending); localirqdisable(); ... _localbhenable(SOFTIRQOFFSET); tskrestoreflags(current, oldflags, PFMEMALLOC); } ```
网络子系统初始化
实际上网络子系统初始化是有很多的工作的,我们在这个环节只关注以下两点 - 注册软中断处理函数 - 注册poll函数的引用到 softnet_data的 poll_list 
说起网络子系统初始化,我们在上边 logic A 处也提到过,就是在 subsys_initcall函数中进行的。接着我们看下subsys_initcall做了些什么,也就是网络子系统初始化时候做了哪些事,(ps:这里我们只看我们关心的,其他的不做过多展开)
```c /Users/hzz/myselfproject/linuxsource_code/linux-3.10.1/net/core/dev.c
/* * Initialize the DEV module. At boot time this walks the device list and * unhooks any devices that fail to initialise (normally hardware not * present) and leaves us with a valid list of present and active devices. * This is called single threaded during boot, so no need * to take the rtnl semaphore. / static int __init net_dev_init(void) { int i, rc = -ENOMEM; BUG_ON(!dev_boot_phase); if (dev_proc_init()) goto out; if (netdev_kobject_init()) goto out; INIT_LIST_HEAD(&ptype_all); for (i = 0; i < PTYPE_HASH_SIZE; i++) INIT_LIST_HEAD(&ptype_base[i]); INIT_LIST_HEAD(&offload_base); if (register_pernet_subsys(&netdev_net_ops)) goto out; / * Initialise the packet receive queues. //初始化网络数据包接收队列 / for_each_possible_cpu(i) { //为当前循环中的cpu声请 softnet_data 类型的数据结构 struct softnet_data *sd = &per_cpu(softnet_data, i); memset(sd, 0, sizeof(sd)); skbqueueheadinit(&sd->inputpktqueue); skbqueueheadinit(&sd->processqueue); sd->completionqueue = NULL; INITLISTHEAD(&sd->polllist); sd->outputqueue = NULL; sd->outputqueuetailp = &sd->output_queue;
ifdef CONFIG_RPS
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->csd.flags = 0;
sd->cpu = i;endif
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
sd->backlog.gro_list = NULL;
sd->backlog.gro_count = 0;
}
dev_boot_phase = 0;
/* The loopback device is special if any other network devices
* is present in a network namespace the loopback device must
* be present. Since we now dynamically allocate and free the
* loopback device ensure this invariant is maintained by
* keeping the loopback device as the first device on the
* list of network devices. Ensuring the loopback devices
* is the first device that appears and the last network device
* that disappears.
*/
if (register_pernet_device(&loopback_net_ops))
goto out;
if (register_pernet_device(&default_device_ops))
goto out;
//注册 NET_TX_SOFTIRQ 类型的软中断 和注册 NET_RX_SOFTIRQ类型的软中断 NET_RX_SOFTIRQ其实就是收包
//(也就是和本文对应的)时候的软中断, 其中 net_tx_action 和 net_rx_action
// 分别是发包时候和收包时候的软中断处理逻辑!!!
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
hotcpu_notifier(dev_cpu_callback, 0);
dst_init();
rc = 0;out: return rc; } subsysinitcall(netdev_init); ```
来说下上边这段逻辑的大致:
在上边这个 subsys_initcall对应的 net_dev_init 函数里,会为每个CPU都申请一个softnet_data数据结构,在这个数据结构里的poll_list是等待驱动程序将其poll函数注册进来(poll_list里边保存的其实可以理解为poll函数的引用),稍后网卡驱动初始化的时候我们可以看到这一过程。
另外opensoftirq是为每一种软中断都注册一个处理函数。NET_TX_SOFTIRQ类型的软中断处理函数为net_tx_action,NETRX_SOFTIRQ 类型的软中断的处理函数是net_rx_action。继续跟踪open_softirq后发现这个注册的方式是记录在softirq_vec变量里的。后面ksoftirqd线程收到软中断的时候,也会使用这个变量来找到每一种软中断对应的处理函数。代码示意如下:
```c /Users/hzz/myselfproject/linuxsource_code/linux-3.10.1/kernel/softirq.c
void opensoftirq(int nr, void (*action)(struct softirqaction *)) { softirq_vec[nr].action = action; } ```
说白了,这小节的网络子系统初始化,有两件事我们需要关注
- 第一件事: 为收发包类型的软中断注册了 各自对应的处理函数,好在后边接收到这种(出去 or 进来的)软中断通知时,来从数组(
softirq_vec)中拿到对应的函数的引用,来调用对应软中断处理函数来执行对应的软中断逻辑! - 第二件事: 为每个CPU都申请一个
softnet_data数据结构,在这个数据结构里的poll_list作用是:等待各种类型的驱动程序将其poll函数注册进来用于后续使用,(poll函数用于拉取RingBuffer上的数据报(不记得的话看开篇中的那个内核收包示意图。)
协议栈注册

说起协议栈初始化,我们在上边 logic A 处也提到过,就是在 fs_initcall函数中进行的。
内核实现了网络层的ip协议,也实现了传输层的tcp协议和udp协议。这些协议对应的实现函数分别是iprcv(),tcpv4rcv()和udprcv()。和我们平时写代码的方式不一样的是,内核是通过注册的方式来实现的。Linux内核中的fs_initcall和subsys_initcall类似,也是初始化模块的入口只不过fs_initcall是为了协议栈 而 subsys_initcall是初始化网络子系统 。fs_initcall调用inet_init后开始网络协议栈注册。通过inet_init,将这些函数的引用保存到了inet_protos和ptype_base数据结构中去,以便后续需要时拿来使用。
如下是初始化协议栈的相关代码: ```c 文件路径:/linux-3.10.1/net/ipv4/af_inet.c
static int _init inetinit(void) { ... if (!sysctllocalreservedports) goto out; rc = protoregister(&tcpprot, 1); if (rc) goto outfreereservedports; rc = protoregister(&udpprot, 1); if (rc) goto outunregistertcpproto; rc = protoregister(&rawprot, 1); if (rc) goto outunregisterudpproto; rc = protoregister(&pingprot, 1); if (rc) goto outunregisterrawproto; /* * Tell SOCKET that we are alive... */ (void)sockregister(&inetfamilyops);
ifdef CONFIG_SYSCTL
ip_static_sysctl_init();endif
tcp_prot.sysctl_mem = init_net.ipv4.sysctl_tcp_mem;
/*
* Add all the base protocols. 添加基础协议 icmp tcp udp
*/
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);ifdef CONFIGIPMULTICAST
if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0)
pr_crit("%s: Cannot add IGMP protocol\n", __func__);endif
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
/*
* Set the ARP module up --- ARP协议
*/
arp_init();
/*
* Set the IP module up --- IP协议
*/
ip_init();
tcp_v4_init(); --- TCP协议
/* Setup TCP slab cache for open requests. */
tcp_init();
/* Setup UDP memory threshold */ --- UDP协议
udp_init();
/* Add UDP-Lite (RFC 3828) */
udplite4_register();
ping_init();
/*
* Set the ICMP layer up
*/
if (icmp_init() < 0)
panic("Failed to create the ICMP control socket.\n");
/*
* Initialise the multicast router
*/if defined(CONFIGIPMROUTE)
if (ip_mr_init())
pr_crit("%s: Cannot init ipv4 mroute\n", __func__);endif
/*
* Initialise per-cpu ipv4 mibs
*/
if (init_ipv4_mibs())
pr_crit("%s: Cannot init ipv4 mibs\n", __func__);
ipv4_proc_init();
ipfrag_init();
dev_add_pack(&ip_packet_type);
rc = 0;out: ... } fsinitcall(inetinit); `` 从上可以看出,这里初始化了IPARPICMPTCPUDP`等等协议
我们这里关注下tcp是咋搞的 其他协议略过。tcp如下: ```c 文件路径:/linux-3.10.1/net/ipv4/protocol.c
/* * Add a protocol handler to the hash tables // 翻译: 将协议处理程序添加到哈希表 */ int inetaddprotocol(const struct netprotocol *prot, unsigned char protocol) { if (!prot->netnsok) { pr_err("Protocol %u is not namespace aware, cannot register.n", protocol); return -EINVAL; }
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol],
NULL, prot) ? 0 : -1;} EXPORTSYMBOL(inetadd_protocol); ```
我们也顺便看下这些协议(也就是调用 inetaddprotocol 方法时传入的第一个参数)里边都有哪些东西: ```c
/linux-3.10.1/net/ipv4/af_inet.c
static const struct netprotocol icmpprotocol = { .handler = icmprcv, (传输层)icmp类型的处理函数(其实他是一个回调函数) .errhandler = icmperr, .nopolicy = 1, .netns_ok = 1, };
static const struct netprotocol tcpprotocol = { .earlydemux = tcpv4earlydemux, .handler = tcpv4rcv, (传输层)tcp类型的处理函数(其实他是一个回调函数) .errhandler = tcpv4err, .nopolicy = 1, .netns_ok = 1, };
static const struct netprotocol udpprotocol = { .handler = udprcv, (传输层)udp类型的处理函数(其实他是一个回调函数) .errhandler = udperr, .nopolicy = 1, .netns_ok = 1, }; ```
从上边代码和方法的注释(Add a protocol handler to the hash tables)不难看出, inet_add_protocol函数将tcp,udp, icmp 这些协议的处理函数都注册到了inetprotos (hash结构的) hash表中了。 这里我们需要记住inetprotos记录着icmp,udp,tcp的处理函数地址
注册了传输层的各个协议栈的实现( icmprcv, ucprcv , tcprcv)后,网络层的协议栈(ip暂且我们只关注他)也得注册下吧? 不然怎么玩呢?这里我们直接给出答案: 网络层协议ip的处理函数是在
inet_add_protocol里的dev_add_pack(&ip_packet_type);函数中进行的。下边我们简单看下 devadd_pack函数以及其入参都是些啥。
```c /linux-3.10.1/net/ipv4/af_inet.c
void devaddpack(struct packettype *pt) { struct listhead *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);}
static inline struct listhead *ptypehead(const struct packettype *pt) { if (pt->type == htons(ETHPALL)) return &ptypeall; else //将iprcv函数引用 保存到ptypebase 表中 return &ptypebase[ntohs(pt->type) & PTYPEHASH_MASK]; }
补充:devaddpack函数入参: static struct packettype ippackettype _readmostly = { .type = cputobe16(0x0800), .func = iprcv, (网络层)ip协议的处理函数 //是一个钩子函数 }; `` 可以看出该函数就是将ip协议对应的处理函数和类型 即 (ip_packet_type) ,保存到了ptype_head中了。用于后续根据type取出对应的处理函数 如ip_rcv`进行ip层的协议包处理
而ptype_head里会把ip_packet_type保存到ptype_base哈希表中,ip_packet_type存储着ip_rcv()函数的处理地址。在后面,我们会看到软中断中会通过ptypebase找到ippackettype中的iprcv函数地址,进而将ip包正确地送到iprcv()中执行。在iprcv中将会通过inetprotos找到tcp或者udp的处理函数,再而把包转发给udprcv()或tcpv4rcv()函数。
提示:inet_init这个函数中的工作可远远不止上边说的那些内容。这里我们不再展开,感兴趣自行阅读相关文章
网卡初始化与启动
网卡初始化
注意:在本文,我们将以igb网卡举例
igb网卡初始化入口对应源码: ```c /Users/hzz/myselfproject/linuxsourcecode/linux-3.10.1/drivers/net/ethernet/intel/igb/igbmain.c
/* * igb_init_module - Driver Registration Routine * * igb_init_module is the first routine called when the driver is * loaded. All it does is register with the PCI subsystem. */ static int _init igbinitmodule(void) { int ret; prinfo("%s - version %sn", igbdriverstring, igbdriverversion);
pr_info("%s\n", igb_copyright);ifdef CONFIGIGBDCA
dca_register_notify(&dca_notifier);endif
ret = pci_register_driver(&igb_driver);
return ret;}
moduleinit(igbinit_module);
static struct pcidriver igbdriver = { .name = igbdrivername, .idtable = igbpcitbl, .probe = igbprobe, // 初始化时将会执行这个方法 重要 .remove = igb_remove,
ifdef CONFIG_PM
.driver.pm = &igb_pm_ops,endif
.shutdown = igb_shutdown,
.sriov_configure = igb_pci_sriov_configure,
.err_handler = &igb_err_handler}; ```
上边这段代码中里边有一个至关重要的函数 pci_register_driver 其负责 注册设备驱动到PCI总线的设备队列上 至于pci 我们这里不做展开说明,请自行查阅 示例:
内核启动过程中,会为设备寻找驱动其实就是调用其 probe() 方法。 probe() 做的事情因厂商和设备而异,总体来说这个过程涉及到的东西都非常多, 最终目标也都是使设备 ready。典型过程包括:
- 获取网卡地址
- DMA初始化,设置 DMA 掩码
- 注册设备驱动支持的
ethtool方法 - 注册各种网卡启动时需要的函数
- 注册
NAPI poll方法 - 使得设备达到
ready状态
我们简单看下 probe相关源码(其余我们略过,只看注册启动函数和poll函数) ```c /Users/hzz/myselfproject/linuxsourcecode/linux-3.10.1/drivers/net/ethernet/intel/igb/igbmain.c
/* * igb_probe - Device Initialization Routine * @pdev: PCI device information struct * @ent: entry in igb_pci_tbl * * Returns 0 on success, negative on failure * * igb_probe initializes an adapter identified by a pci_dev structure. * The OS initialization, configuring of the adapter private structure, * and a hardware reset occur. */
static int igbprobe(struct pcidev *pdev, const struct pcideviceid *ent) { struct netdevice *netdev; struct igbadapter *adapter; struct e1000_hw *hw;
...
netdev->netdev_ops = &igb_netdev_ops;//驱动向内核注册了 net_device_ops 变量
...}
static const struct netdeviceops igbnetdevops = { .ndoopen = igbopen, //该函数在网卡被启动的时候会被调用 .ndostop = igbclose, .ndostartxmit = igbxmitframe, .ndogetstats64 = igbgetstats64, .ndosetrxmode = igbsetrxmode, .ndosetmacaddress = igbsetmac, .ndochangemtu = igbchangemtu, .ndodoioctl = igbioctl, .ndotxtimeout = igbtxtimeout, .ndovalidateaddr = ethvalidateaddr, .ndovlanrxaddvid = igbvlanrxaddvid, .ndovlanrxkillvid = igbvlanrxkillvid, .ndosetvfmac = igbndosetvfmac, .ndosetvfvlan = igbndosetvfvlan, .ndosetvftxrate = igbndosetvfbw, .ndosetvfspoofchk = igbndosetvfspoofchk, .ndogetvfconfig = igbndogetvfconfig,
ifdef CONFIGNETPOLL_CONTROLLER
.ndo_poll_controller = igb_netpoll,endif
.ndo_fix_features = igb_fix_features,
.ndo_set_features = igb_set_features,};
`` 其中igb_open`是网卡启动时候需要调用的函数。
另外 在igb_probe初始化过程中,还调用到了igb_alloc_q_vector。他注册了一个NAPI机制所必须的poll函数,对于igb网卡驱动来说,这个函数就是igb_poll,如下代码所示
```c
linux-3.10.1/drivers/net/ethernet/intel/igb/igb_main.c
igballocq_vector函数中的代码片段:
/* initialize NAPI */ netifnapiadd(adapter->netdev, &qvector->napi, igbpoll, 64);
igb的poll函数: /* * igb_poll - NAPI Rx polling callback * @napi: napi polling structure * @budget: count of how many packets we should handle */ static int igbpoll(struct napistruct *napi, int budget) { struct igbqvector *qvector = containerof(napi, struct igbqvector, napi); bool clean_complete = true;
ifdef CONFIGIGBDCA
if (q_vector->adapter->flags & IGB_FLAG_DCA_ENABLED)
igb_update_dca(q_vector);endif
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector);
if (q_vector->rx.ring)
clean_complete &= igb_clean_rx_irq(q_vector, budget);
/* If all work not completed, return budget and keep polling */
if (!clean_complete)
return budget;
/* If not enough Rx work done, exit the polling mode */
napi_complete(napi);
igb_ring_irq_enable(q_vector);
return 0;}
```
到此,网卡的初始化就完成了,由于网卡初始化时工作太多,我们没对上边网卡初始化进行过度展开,只是挑两个后续我们会说到的(igb_open, igb_poll)来简单说明一下。
网卡启动
当上面的初始化都完成以后,就可以启动网卡了。在前面网卡驱动初始化时,我们提到了驱动向内核注册了 net_device_ops 变量,它包含着网卡启用、发包、设置mac 地址等回调函数(函数指针)。当启用一个网卡时(例如,通过 ifconfig eth0 up),它通常会做以下事
- 启动网卡
- 调用
net_device_ops注册的open函数 如igb_open - 分配RX TX队列所需的内存
- 注册中断处理函数
- 打开硬中断,开始准备收包。
我们简单看下源码
```c /linux-3.10.1/drivers/net/ethernet/intel/igb/igb_main.c
static const struct netdeviceops igbnetdevops = { .ndoopen = igbopen, .ndostop = igbclose, .ndostartxmit = igbxmitframe, .ndogetstats64 = igbgetstats64, .ndosetrxmode = igbsetrxmode, .ndosetmacaddress = igbsetmac, .ndochangemtu = igbchangemtu, .ndodoioctl = igbioctl, .ndotxtimeout = igbtxtimeout, .ndovalidateaddr = ethvalidateaddr, .ndovlanrxaddvid = igbvlanrxaddvid, .ndovlanrxkillvid = igbvlanrxkillvid, .ndosetvfmac = igbndosetvfmac, .ndosetvfvlan = igbndosetvfvlan, .ndosetvftxrate = igbndosetvfbw, .ndosetvfspoofchk = igbndosetvfspoofchk, .ndogetvfconfig = igbndogetvfconfig,
ifdef CONFIGNETPOLL_CONTROLLER
.ndo_poll_controller = igb_netpoll,endif
.ndo_fix_features = igb_fix_features,
.ndo_set_features = igb_set_features,};
static int igbopen(struct netdevice *netdev) { return _igbopen(netdev, false); }
/* * igb_open - Called when a network interface is made active * @netdev: network interface device structure * * Returns 0 on success, negative value on failure * * The open entry point is called when a network interface is made * active by the system (IFF_UP). At this point all resources needed * for transmit and receive operations are allocated, the interrupt * handler is registered with the OS, the watchdog timer is started, * and the stack is notified that the interface is ready. */ static int _igbopen(struct netdevice *netdev, bool resuming) { struct igbadapter *adapter = netdev_priv(netdev);
/* 给发送队列分配资源 */
err = igb_setup_all_tx_resources(adapter);
if (err)
goto err_setup_tx;
/* 给接队列分配资源 */
err = igb_setup_all_rx_resources(adapter);
if (err)
goto err_setup_rx;
//注册硬中断处理函数
err = igb_request_irq(adapter);
if (err)
goto err_req_irq;
...
/* From here on the code is the same as igb_up() */
clear_bit(__IGB_DOWN, &adapter->state);
//开启 NAPI模式
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi));
...
/* Clear any pending interrupts. */
rd32(E1000_ICR);
igb_irq_enable(adapter);
....
return err;}
```
__igb_open函数调用了igb_setup_all_tx_resources和igb_setup_all_rx_resources。在igb_setup_all_rx_resources这一步操作中,为每个网卡都分配了RingBuffer,并建立内存和Receive队列的映射关系。 igbsetupalltxresources这个暂时我们不管,不在本文讨论之内。
下边我们看下硬中断函数是如何注册的:
```c /linux-3.10.1/drivers/net/ethernet/intel/igb/igb_main.c
注册硬中断处理函数 /* * igb_request_irq - initialize interrupts * @adapter: board private structure to initialize * * Attempts to configure interrupts using the best available * capabilities of the hardware and kernel. */ static int igbrequestirq(struct igbadapter *adapter) { struct netdevice *netdev = adapter->netdev; struct pci_dev *pdev = adapter->pdev; int err = 0;
if (adapter->msix_entries) {
//注册以及设置中断通知方式为 msi-x
err = igb_request_msix(adapter);
if (!err)
goto request_done;
...
igb_setup_all_tx_resources(adapter);
igb_setup_all_rx_resources(adapter);
igb_configure(adapter);
}
...
return err;}
真正注册硬中断处理函数 和设置中断通知的方式 static int igbrequestmsix(struct igbadapter *adapter) { ... for (i = 0; i < adapter->numqvectors; i++) { struct igbqvector *qvector = adapter->qvector[i]; vector++; qvector->itrregister = hw->hwaddr + E1000EITR(vector); if (qvector->rx.ring && qvector->tx.ring) sprintf(qvector->name, "%s-TxRx-%u", netdev->name, qvector->rx.ring->queueindex); else if (qvector->tx.ring) sprintf(qvector->name, "%s-tx-%u", netdev->name, qvector->tx.ring->queueindex); else if (qvector->rx.ring) sprintf(qvector->name, "%s-rx-%u", netdev->name, qvector->rx.ring->queueindex); else sprintf(qvector->name, "%s-unused", netdev->name); // 注册中断处理函数,并且设置触发中断的方式为 MSI-X err = requestirq(adapter->msixentries[vector].vector, igbmsixring, 0, qvector->name, qvector); if (err) goto errfree; } } ```
在上面的代码中用, __igb_open -> igb_request_irq -> igb_request_msix, 在igb_request_msix中我们看到了,对于多队列的网卡,为每一个队列(通过for循环)都注册了硬中断,其对应的中断处理函数是igb_msix_ring。
igb网卡 使用的硬中断方式是 MSI-X。 当一个数据帧通过 DMA 写到内核内存 ringbuffer 后,网卡通过硬件中断(IRQ)通知其他系统。 他有多种方式触发一个中断,分别是:
MSI-X MSI legacy interrupts 三种 设备驱动的实现也因此而不同。驱动必须判断出设备支持哪种中断方式,然后注册相应的硬中断处理函数,这些函数在硬中断发生的时候会被执行。 - MSI-X 中断是比较推荐的方式 也是本文示例【igb】网卡所支持的,尤其是对于支持多队列的网卡。 另外提一句: 多队列模式下的同一个网卡的中断信号可以被不同的 CPU 处理(通过调整irqbalance,或者修改/proc/irq/IRQ_NUMBER/smp_affinity的方式) 更多见 此文 。这样的话,从网卡硬件中断的层面就可以设置让收到的包被不同的CPU处理,从而避免某个cpu负载过重的情况出现。 - 如果不支持 MSI-X,那 MSI 相比于传统中断方式仍然有一些优势,驱动仍然会优先考虑它。 关于MSI和MSI-X 更多参阅: wiki
在网卡启动完成并注册好硬中断处理函数后,该网卡就可以开始收包了!
至此 开篇时的
问题与一些说明小节中的问题1我们就讲完了。
下边,我们带着开篇时候的 问题与一些说明 小节中的 问题2 进行接下来的 收包 分析。
四、收包分析
这里我们把第二节的 Linux收包总览中的示意图拿出来重温一遍(这张图很重要)
将数据帧DMA到RingBuffer (接收环中)
在数据帧从外部网络到达网卡后,第一步是 1. 网卡在分配给自己的RingBuffer(分配资源的函数是上边 _igbopen中 提到的:igb_setup_all_rx_resources(adapter); )中寻找可用的内存位置 1. 找到后DMA引擎会把数据DMA到网卡之前关联的内存里 1. 向cpu发出硬中断通知(告知cpu,你先停下其他的,抓紧处理下我的这个请求吧!)
关于DMA的解释: 一句话概况: 为RAM和IO设备开辟一条直接传输数据的通道,无需cpu参与,网卡数据即可直接到达内存。 更多请见:wiki : 什么是DMA?
说明: 1 和 2 CPU都是无感知的! 也就是说是硬件的直接行为! 这个设计通过DMA方式,大大减少了cpu的压力(尤其是网络这种高频,处理逻辑复杂的场景) ps: 最初时,可能是来一个请求cpu就停下手头工作去处理收数据包和处理相关逻辑,DMA这种方式,给了cpu缓冲的时间,减少了网络高峰期时cpu的压力。
当然,RingBuffer也不是无限长度的,他是一个环形队列,当达到阈值时,将会把新来的数据包丢掉 此时,我们通过ifconfig查看网卡的时候可以看到里边有 overruns的值不为0的话,代表出现了丢包现象,而此时,我们可以通过ethtool来调整环形队列(RingBufer)的大小

向cpu发起硬中断通知以及cpu处理硬中断
- 在将数据帧DMA到内存后,网卡将会发起一个硬中断,来通知cpu
- 随后cpu将会调用网卡启动时该网卡注册的硬中断处理函数也就是上边说的(
igb_request_irq),开始处理硬中断,从这里我们可以得知,硬中断里边干了什么事,是根据设备不同而有差异的(但是,一般硬中断里边的逻辑都比较简单,而把一些复杂的逻辑都放到处理软中断的逻辑中去,这样便于减少cpu压力,提高其吞吐性能,因为硬中断的优先级是很高的,大量,耗时的硬中断处理,可能会导致cpu繁忙,效率下降,吞吐降低)。
至于硬中断都做了什么,我们这里通过源码看下igb网卡的硬中断是咋搞的(其实硬中断只是超级简单的逻辑,大部分收包的逻辑都在后边呢)
```c static irqreturnt igbmsixring(int irq, void *data) { struct igbqvector *qvector = data; /* Write the ITR value calculated from the previous interrupt. */ igbwriteitr(qvector); napischedule(&qvector->napi); return IRQHANDLED; }
/** * _napischedule - schedule for receive * @n: entry to schedule * * The entry's receive function will be scheduled to run */ void _napischedule(struct napi_struct *n) { unsigned long flags;
local_irq_save(flags);
____napi_schedule(&__get_cpu_var(softnet_data), n);
local_irq_restore(flags);} EXPORTSYMBOL(napischedule);
/* Called with irq disabled */ static inline void _napischedule(struct softnetdata *sd, struct napistruct *napi) { //将polllist添加进链表中(具体做什么我们这里不做过多展开) listaddtail(&napi->polllist, &sd->polllist); //触发软中断 ! _raisesoftirqirqoff(NETRXSOFTIRQ); }
void _raisesoftirqirqoff(unsigned int nr) { //真正 触发软中断! tracesoftirqraise(nr); //修改软中断标志 orsoftirq_pending(1UL << nr); } ```
发起软中断通知
其实,就是这段代码 c void __raise_softirq_irqoff(unsigned int nr) { //真正 触发软中断! trace_softirq_raise(nr); //修改软中断标志 or_softirq_pending(1UL << nr); }
那么发出软中断通知后,由谁来处理对应的逻辑呢? 这个就是我们前边说的ksoftirqd线程中的循环函数run_ksoftirqd了!
```c static void runksoftirqd(unsigned int cpu) { localirqdisable(); if (localsoftirqpending()) { //软中断对应的处理逻辑 _dosoftirq(); rcunotecontextswitch(cpu); localirqenable(); condresched(); return; } localirq_enable(); }
asmlinkage void dosoftirq(void) { //检测是否有软中断标志 ,其实就是读取上边 _raisesoftirqirqoff //函数中 orsoftirqpending(1UL << nr);设置的软中断标记 pending = localsoftirqpending();//读取软中断标记 accountirqentertime(current); _localbhdisable((unsigned long)builtinreturnaddress(0), SOFTIRQOFFSET); lockdepsoftirqenter(); cpu = smpprocessorid(); restart: /* Reset the pending bitmask before enabling irqs */ setsoftirqpending(0); localirqenable(); h = softirqvec; do { //如果有软中断需要处理,将进行处理 if (pending & 1) { unsigned int vecnr = h - softirqvec; int prevcount = preemptcount(); kstatincrsoftirqsthiscpu(vecnr); tracesoftirqentry(vecnr); h->action(h); tracesoftirqexit(vecnr); if (unlikely(prevcount != preemptcount())) { printk(KERNERR "huh, entered softirq %u %s %p" "with preemptcount %08x," " exited with %08x?n", vecnr, softirqtoname[vecnr], h->action, prevcount, preemptcount()); preemptcount() = prevcount; } rcubhqs(cpu); } h++; pending >>= 1; } while (pending); tskrestoreflags(current, oldflags, PF_MEMALLOC); } ```
说明:其实软中断的设置和读取,都是有一个主体的,也就是某个cpu来进行的, 设置软中断标记的cpu和读取软中断标记的cpu是同一个, 通过下段代码中的: smpprocessorid (获取当前cpu_id) 我们可以看出来
c /* arch independent irq_stat fields */ #define local_softirq_pending() \ __IRQ_STAT(smp_processor_id(), __softirq_pending)
在上段代码的 h->action(h) 处 , 最终会调用到 net_rx_action中来,这才是真正的软中断的处理逻辑!
```c /linux-3.10.1/net/core/dev.c
static void netrxaction(struct softirqaction *h) { struct softnetdata sd = &__get_cpu_var(softnet_data); unsigned long time_limit = jiffies + 2; int budget = netdev_budget; void *have; local_irq_disable(); //遍历 poll_list ,拿到poll函数的引用,在while中执行poll函数, //poll函数的逻辑一句话概况就是(从RingBuffer环形队列上获取数据帧) while (!list_empty(&sd->poll_list)) { struct napi_struct *n; int work, weight; / If softirq window is exhuasted then punt. * Allow this to run for 2 jiffies since which will allow * an average latency of 1.5/HZ. / if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit))) goto softnet_break; local_irq_enable(); / Even though interrupts have been re-enabled, this * access is safe because interrupts can only add new * entries to the tail of this list, and only ->poll() * calls can remove this head entry from the list. / n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list); have = netpoll_poll_lock(n); weight = n->weight; / This NAPISTATESCHED test is for avoiding a race * with netpoll's pollnapi(). Only the entity which * obtains the lock and sees NAPISTATESCHED set will * actually make the ->poll() call. Therefore we avoid * accidentally calling ->poll() when NAPI is not scheduled. */ work = 0; if (testbit(NAPISTATESCHED, &n->state)) { work = n->poll(n, weight); //触发poll函数(是在网卡初始化时候说过的,网卡会把poll函数的引用注册到polllist中) tracenapipoll(n); } WARNONONCE(work > weight); budget -= work; localirqdisable(); /* Drivers must not modify the NAPI state if they * consume the entire weight. In such cases this code * still "owns" the NAPI instance and therefore can * move the instance around on the list at-will. */ if (unlikely(work == weight)) { if (unlikely(napidisablepending(n))) { localirqenable(); napicomplete(n); localirqdisable(); } else { if (n->grolist) { /* flush too old packets * If HZ < 1000, flush all packets. */ localirqenable(); napigroflush(n, HZ >= 1000); localirqdisable(); } listmovetail(&n->polllist, &sd->polllist); } } netpollpollunlock(have); } out: netrpsactionandirqenable(sd);
ifdef CONFIGNETDMA
/*
* There may not be any more sk_buffs coming right now, so push
* any pending DMA copies to hardware
*/
dma_issue_pending_all();endif
return;softnetbreak: sd->timesqueeze++; _raisesoftirqirqoff(NETRX_SOFTIRQ); goto out; } ```
而我们本文以igb网卡举例,所以我们看下igb网卡对应的poll函数的逻辑
igb_poll函数的处理逻辑:
```c
linux-3.10.1/drivers/net/ethernet/intel/igb/igb_main.c
/* * igb_poll - NAPI Rx polling callback * @napi: napi polling structure * @budget: count of how many packets we should handle */ static int igbpoll(struct napistruct *napi, int budget) { ...
ifdef CONFIGIGBDCA
if (q_vector->adapter->flags & IGB_FLAG_DCA_ENABLED)
igb_update_dca(q_vector);endif
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector);
if (q_vector->rx.ring)
//收包时候的poll逻辑
clean_complete &= igb_clean_rx_irq(q_vector, budget);
/* If all work not completed, return budget and keep polling */
if (!clean_complete)
return budget;
/* If not enough Rx work done, exit the polling mode */
napi_complete(napi);
igb_ring_irq_enable(q_vector);
return 0;}
static bool igbcleanrxirq(struct igbqvector *qvector, const int budget) { do { ... /* retrieve a buffer from the ring / // 从RingBuffer上拉取buffer (数据帧) skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb); cleaned_count++; / fetch next buffer in frame if non-eop / if (igb_is_non_eop(rx_ring, rx_desc)) continue; //一些校验 / verify the packet layout is correct / if (igb_cleanup_headers(rx_ring, rx_desc, skb)) { skb = NULL; continue; } / probably a little skewed due to removing CRC / total_bytes += skb->len; / populate checksum, timestamp, VLAN, and protocol */ igbprocessskbfields(rxring, rx_desc, skb);
napi_gro_receive(&q_vector->napi, skb);
/* reset skb pointer */
skb = NULL;
/* update budget accounting */
total_packets++;
} while (likely(total_packets < budget));
if (cleaned_count)
igb_alloc_rx_buffers(rx_ring, cleaned_count);
return (total_packets < budget);} ```
上边函数虽然比较多,但是流程还是很清晰的,大概就是 1. 在循环中调用igb_fetch_rx_buffer 来从RingBuffer中拉取数据帧 2. 如果RingBuffer没有数据帧可拉取,就跳出,否则就把刚拿到的数据,做一些校验工作 3. 随后进入 napi_gro_receive这个逻辑中,接下来我们看下这个逻辑(其实根据我们第四节开头的 **收包示意图** 也大概知道了,就是将拉取的数据包保存到skb中去)
```c
groresultt napigroreceive(struct napistruct *napi, struct skbuff *skb) { skbgroreset_offset(skb);
return napi_skb_finish(dev_gro_receive(napi, skb), skb);} EXPORTSYMBOL(napigro_receive);
// static groresultt napiskbfinish(groresultt ret, struct skbuff *skb) { switch (ret) { case GRONORMAL: //接收skb if (netifreceiveskb(skb)) ret = GRODROP; break; case GRODROP: kfreeskb(skb); break; case GROMERGEDFREE: if (NAPIGROCB(skb)->free == NAPIGROFREESTOLENHEAD) kmemcachefree(skbuffheadcache, skb); else _kfreeskb(skb); break; case GROHELD: case GRO_MERGED: break; } return ret; }
static int _netifreceiveskb(struct skbuff *skb) { int ret;
if (sk_memalloc_socks() && skb_pfmemalloc(skb)) {
unsigned long pflags = current->flags;
/*
* PFMEMALLOC skbs are special, they should
* - be delivered to SOCK_MEMALLOC sockets only
* - stay away from userspace
* - have bounded memory usage
*
* Use PF_MEMALLOC as this saves us from propagating the allocation
* context down to all allocation sites.
*/
current->flags |= PF_MEMALLOC;
// 标记A
ret = __netif_receive_skb_core(skb, true);
tsk_restore_flags(current, pflags, PF_MEMALLOC);
} else
ret = __netif_receive_skb_core(skb, false);
return ret;} ```
由于代码调用链有点长,我们不继续深跟,这里只给出关键的一步,也就是 上段代码 标记A : __netif_receive_skb_core 函数中的(看下图:)
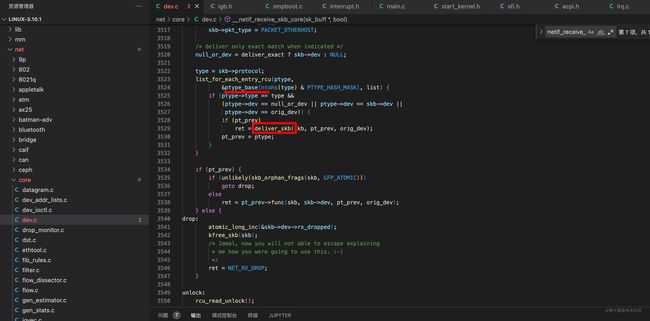
这块代码中的 ptype_base中的内容 其实就是ip协议的处理方法: ip_rcv() 的函数引用!(不记得可以去第三节的 协议栈注册中找下) 而deliver_skb里边是做什么我们应该从函数名就可以看出来(递交skb)至于递交给谁,我们应该可以猜出来,就是我们在协议栈注册小节中讲到的 ip_rcv()函数。 (ps:由于我们本文不关注 网络层的arp 协议,所以我们这里只讨论 ip_rcv 而不去关注arp_rcv)。
协议栈处理数据包(skb)
注意:本质上 Linux内核似乎并没有严格的网络层,传输层之分(分层概念是OSI模型里边讲的:OSI , 而Linux 他只是根据packet_type 来区分是ip协议 还是tcp / ucp / icmp 协议的。
网络层处理(IP协议举例)
我们接着上一节来说,上一节我们说到从RingBuffer环形环上扒到 数据后封装成skb(socket buffer) , 通过 deliver_skb函数 来传递给了ip_rcv, 所以我们看下ip_rcv里边是个什么逻辑
```c linux-3.10.1/net/ipv4/ip_input.c
/* * Main IP Receive routine. / int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev) { ... IP_UPD_PO_STATS_BH(dev_net(dev), IPSTATS_MIB_IN, skb->len); //一些检查 ... ... / Remove any debris in the socket control block / memset(IPCB(skb), 0, sizeof(struct inet_skb_parm)); / Must drop socket now because of tproxy. */ skborphan(skb); return NFHOOK(NFPROTOIPV4, NFINETPREROUTING, skb, dev, NULL, iprcvfinish);//iprcvfinish是主要的处理逻辑 csumerror: IPINCSTATSBH(devnet(dev), IPSTATSMIBCSUMERRORS); inhdrerror: IPINCSTATSBH(devnet(dev), IPSTATSMIBINHDRERRORS); drop: kfreeskb(skb); out: return NETRXDROP; } `` 从上边可以看到在iprcv`中做了这些工作:
检查报文首部和ip协议版本号, 检查ip首部的校验和,以及ip数据包的总长度,校验通过后, 数据包进入PREROUTING链,如果通过该链(说明一定通过了防火墙了),则将数据包传递给ip_rcv_finish处理
PREROUTING的作用是 : 目的地 地址转换,要把别人的公网IP换成你们内部的IP,才可以访问到你们内部受防火墙保护的机器
接下来我们看下 ip_rcv_finish
```c linux-3.10.1/net/ipv4/ip_input.c
static int iprcvfinish(struct skbuff *skb) { const struct iphdr *iph = iphdr(skb); ... /* * Initialise the virtual path cache for the packet. It describes * how the packet travels inside Linux networking. //初始化数据包的虚拟路径缓存。 它描述了 //数据包如何在 Linux 网络中传输。 */ if (!skbdst(skb)) { //通过路由子系统 查询路由函数 ,在下边的 dstoutput函数其实就是执行的 : //iplocaldeliver(可以看下图:) int err = iprouteinputnoref(skb, iph->daddr, iph->saddr, iph->tos, skb->dev); if (unlikely(err)) { if (err == -EXDEV) NETINCSTATSBH(devnet(skb->dev), LINUXMIB_IPRPFILTER); goto drop; } }
ifdef CONFIGIPROUTE_CLASSID
...endif
if (iph->ihl > 5 && ip_rcv_options(skb))
goto drop;
rt = skb_rtable(skb);
if (rt->rt_type == RTN_MULTICAST) {
IP_UPD_PO_STATS_BH(dev_net(rt->dst.dev), IPSTATS_MIB_INMCAST,
skb->len);
} else if (rt->rt_type == RTN_BROADCAST)
IP_UPD_PO_STATS_BH(dev_net(rt->dst.dev), IPSTATS_MIB_INBCAST,
skb->len);
//分发流转数据包, 这里边会决定是转发,还是递交给上层 (即传输层)。
return dst_input(skb);drop: kfreeskb(skb); return NETRX_DROP; } ```
下图:(可以看到路由子系统(ip_route_input_noref)中, 最终调的函数是 ip_route_input_mc, 它里边可以看到 上段代码的 分发逻辑:dst_output其实是 执行的 ip_local_deliver 里的逻辑)

在上边代码的 dst_input(skb) 处, 数据包将会进行转发,或者向上层(传输层)传递。 c /* Input packet from network to transport. */ // 从网络层输入数据包到传输层!!! static inline int dst_input(struct sk_buff *skb) { return skb_dst(skb)->input(skb); } 由于在上边我们说了,dst_input其实是执行的ip_local_deliver里的逻辑,所以我们看下这个里边都是怎么处理的。
(注意:由于
dst_input里可能是转发到其他机器,也可能是递交给传输层处理(也就是本机处理),在这里我们不对转发逻辑展开 (转发其实就不是ip_local_deliver了而是ip_forward了),只讨论向传输层递交的逻辑)
接下来我们直接进入ip_local_deliver的逻辑,看看都做了哪些工作
```c /linux-3.10.1/net/ipv4/ip_input.c
/* * Deliver IP Packets to the higher protocol layers. * 将 IP 数据包传送到更高的协议层!!! / int ip_local_deliver(struct sk_buff *skb) { / * Reassemble IP fragments. */
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);} `` 可以从上边这个函数的注释看到,这个函数的作用就是**向上层递交数据包**!(这里的上层就是**传输层**) 但其实真正的逻辑是在这里边iplocaldeliver_finish` 源码如下:
```c linux-3.10.1/net/ipv4/ip_input.c
static int iplocaldeliverfinish(struct skbuff *skb) { struct net *net = dev_net(skb->dev);
__skb_pull(skb, ip_hdrlen(skb));
/* Point into the IP datagram, just past the header. */
skb_reset_transport_header(skb);
rcu_read_lock();
{
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
int raw;
resubmit:
raw = raw_local_deliver(skb, protocol);
//从这里我们可以看到,他会根据协议找到对应的函数引用,然后来执行对应的函数
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot != NULL) {
int ret;
if (!ipprot->no_policy) {
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
kfree_skb(skb);
goto out;
}
nf_reset(skb);
}
ret = ipprot->handler(skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}
IP_INC_STATS_BH(net, IPSTATS_MIB_INDELIVERS);
} else {
...
}
}out: rcureadunlock(); return 0; } ```
上边这个函数通过 ipprot = rcu_dereference(inet_protos[protocol]);,这段代码,来从 inet_protos 找到对应的协议栈的函数引用(关于inet_protos我们在协议栈注册那一节说过,忘记的可以翻翻,本质上他是一个哈希表,里边保存的是各个传输层协议(udp tcp icmp)的协议处理方法(udp_rcv() 或 tcp_v4_rcv() 或 icmp_rcv() )的引用) 之后开始执行找到的方法即 ret = ipprot->handler(skb); 这段代码。 由此,数据包完成了从网络层到传输层的流转工作,接下来的工作就是传输层的了!
传输层处理(TCP 协议举例)
这里我们将选择tcp来进行传输层处理数据包的讲解
由于在上边 网络层处理 结尾时,我们说到tcp是以tcpv4rcv()来处理数据包的。所以我们看下这个函数的内容,源码如下:
```c
/* * From tcpinput.c */ int tcpv4rcv(struct skbuff skb) { const struct iphdr *iph; const struct tcphdr *th; struct sock *sk; int ret; struct net *net = dev_net(skb->dev); if (skb->pkt_type != PACKET_HOST) goto discard_it; //一些校验工作 / Count it even if it's bad */ TCPINCSTATSBH(net, TCPMIB_INSEGS);
if (!pskb_may_pull(skb, sizeof(struct tcphdr)))
goto discard_it;
th = tcp_hdr(skb);
if (th->doff < sizeof(struct tcphdr) / 4)
goto bad_packet;
if (!pskb_may_pull(skb, th->doff * 4))
goto discard_it;
/* An explanation is required here, I think.
* Packet length and doff are validated by header prediction,
* provided case of th->doff==0 is eliminated.
* So, we defer the checks. */
if (!skb_csum_unnecessary(skb) && tcp_v4_checksum_init(skb))
goto csum_error;
th = tcp_hdr(skb);
iph = ip_hdr(skb);
//设置TCP_CB
TCP_SKB_CB(skb)->seq = ntohl(th->seq);
TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin +
skb->len - th->doff * 4);
TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
TCP_SKB_CB(skb)->when = 0;
TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph);
TCP_SKB_CB(skb)->sacked = 0;
//根据数据包 header 中的 ip、端口信息查找到对应的socket, 也就是 查找连接信息
sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest);
if (!sk)
goto no_tcp_socket;process: //根据上一步找到的socket连接的状态,来进行不同的处理逻辑
//TIME_WAIT 状态的处理
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;//time_wait的真正实现
if (unlikely(iph->ttl < inet_sk(sk)->min_ttl)) {
NET_INC_STATS_BH(net, LINUX_MIB_TCPMINTTLDROP);
goto discard_and_relse;
}
if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb))
goto discard_and_relse;
nf_reset(skb);
if (sk_filter(sk, skb))
goto discard_and_relse;
skb->dev = NULL;
bh_lock_sock_nested(sk);
ret = 0;
if (!sock_owned_by_user(sk)) {ifdef CONFIGNETDMA
struct tcp_sock *tp = tcp_sk(sk);
if (!tp->ucopy.dma_chan && tp->ucopy.pinned_list)
tp->ucopy.dma_chan = net_dma_find_channel();
if (tp->ucopy.dma_chan)
//非time_wait 的逻辑,里边会有 ESTABLISHED 和 LISTEN 状态的对应处理逻辑
ret = tcp_v4_do_rcv(sk, skb);
elseendif
{
if (!tcp_prequeue(sk, skb))
ret = tcp_v4_do_rcv(sk, skb);
}
} else if (unlikely(sk_add_backlog(sk, skb,
sk->sk_rcvbuf + sk->sk_sndbuf))) {
bh_unlock_sock(sk);
NET_INC_STATS_BH(net, LINUX_MIB_TCPBACKLOGDROP);
goto discard_and_relse;
}
bh_unlock_sock(sk);
sock_put(sk);
return ret;notcpsocket: //不是socket的情况处理 if (!xfrm4policycheck(NULL, XFRMPOLICYIN, skb)) goto discardit; if (skb->len < (th->doff << 2) || tcpchecksumcomplete(skb)) { csumerror: TCPINCSTATSBH(net, TCPMIBCSUMERRORS); badpacket: TCPINCSTATSBH(net, TCPMIBINERRS); } else { tcpv4sendreset(NULL, skb); }
discardit: /* Discard frame. */ 丢弃掉数据帧 kfreeskb(skb); return 0; discardandrelse: sockput(sk); goto discardit; dotimewait: //进行timewait相关处理 if (!xfrm4policycheck(NULL, XFRMPOLICYIN, skb)) { inettwskput(inettwsk(sk)); goto discardit; } if (skb->len < (th->doff << 2)) { inettwskput(inettwsk(sk)); goto badpacket; } if (tcpchecksumcomplete(skb)) { inettwskput(inettwsk(sk)); goto csumerror; } switch (tcptimewaitstateprocess(inettwsk(sk), skb, th)) { case TCPTWSYN: { struct sock *sk2 = inetlookuplistener(devnet(skb->dev), &tcphashinfo, iph->saddr, th->source, iph->daddr, th->dest, inetiif(skb)); if (sk2) { inettwskdeschedule(inettwsk(sk), &tcpdeathrow); inettwskput(inettwsk(sk)); sk = sk2; goto process; } /* Fall through to ACK */ } case TCPTWACK: tcpv4timewaitack(sk, skb); break; case TCPTWRST: goto notcpsocket; case TCPTWSUCCESS:; } goto discardit; } ```
从上源码可以看到,tcp_rcv函数大概流程为: 1. 一些校验 2. 根据数据包 header 中的 ip、端口信息查找到对应的socket信息(连接信息) 3. 根据上一步找到的socket连接的状态,来进行不同的处理逻辑 4. time_wait状态下的处理逻辑,是在tcp_rcv中处理的, ESTABLISHED 和 LISTEN 状态的对应处理逻辑 是在 tcp_v4_do_rcv中进行的
在这里,我们对其他状态的处理逻辑不做过多研究,只看ESTABLISHED和LISTEN下的处理是什么样的 于是找到tcp_v4_do_rcv的源码, 如下: ```c linux-3.10.1/net/ipv4/tcp_input.c
/* The socket must have it's spinlock held when we get * here. * * We have a potential double-lock case here, so even when * doing backlog processing we use the BH locking scheme. * This is because we cannot sleep with the original spinlock * held. */ int tcpv4dorcv(struct sock *sk, struct skbuff *skb) { struct sock *rsk;
ifdef CONFIGTCPMD5SIG
//一些校验
if (tcp_v4_inbound_md5_hash(sk, skb))
goto discard;endif
// 当前tcp连接状态是 ESTABLISHED 的处理逻辑
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
struct dst_entry *dst = sk->sk_rx_dst;
sock_rps_save_rxhash(sk, skb);
if (dst) {
if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif ||
dst->ops->check(dst, 0) == NULL) {
dst_release(dst);
sk->sk_rx_dst = NULL;
}
}
//ESTABLISHED状态下 会进入此函数
if (tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
return 0;
}
if (skb->len < tcp_hdrlen(skb) || tcp_checksum_complete(skb))
goto csum_err;
//当前tcp连接状态是 LISTEN 的处理逻辑
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_hnd_req(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
sock_rps_save_rxhash(nsk, skb);
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
}} EXPORTSYMBOL(tcpv4dorcv); `` 从上边我们可以看出,ESTABLISHED状态下进入的函数是:tcprcvestablished`
我们找下 tcp_rcv_established 的源码:
注意:由于
tcp_rcv_established这里边的代码太多 我们把其他不关注的一律都删掉(但是我们尽量把注释留下,这样可能对理解代码逻辑起到一定帮助作用) ```c /* * TCP receive function for the ESTABLISHED state. * * It is split into a fast path and a slow path. The fast path is * disabled when: * - A zero window was announced from us - zero window probing * is only handled properly in the slow path. * - Out of order segments arrived. * - Urgent data is expected. * - There is no buffer space left * - Unexpected TCP flags/window values/header lengths are received * (detected by checking the TCP header against predflags) * - Data is sent in both directions. Fast path only supports pure senders * or pure receivers (this means either the sequence number or the ack * value must stay constant) * - Unexpected TCP option. * * When these conditions are not satisfied it drops into a standard * receive procedure patterned after RFC793 to handle all cases. * The first three cases are guaranteed by proper predflags setting, * the rest is checked inline. Fast processing is turned on in * tcpdataqueue when everything is OK. / int tcp_rcv_established(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, unsigned int len) { struct tcp_sock *tp = tcp_sk(sk); if (unlikely(sk->sk_rx_dst == NULL)) inet_csk(sk)->icsk_af_ops->sk_rx_dst_set(sk, skb); / * Header prediction. * The code loosely follows the one in the famous * "30 instruction TCP receive" Van Jacobson mail. * * Van's trick is to deposit buffers into socket queue * on a device interrupt, to call tcprecv function * on the receive process context and checksum and copy * the buffer to user space. smart... * * Our current scheme is not silly either but we take the * extra cost of the netbh soft interrupt processing... * We do checksum and copy also but from device to kernel. / tp->rx_opt.saw_tstamp = 0; / predflags is 0xS?10 << 16 + sndwnd * if headerprediction is to be made * 'S' will always be tp->tcpheaderlen >> 2 * '?' will be 0 for the fast path, otherwise predflags is 0 to * turn it off (when there are holes in the receive * space for instance) * PSH flag is ignored. */ if ((tcpflagword(th) & TCPHPBITS) == tp->predflags && TCPSKBCB(skb)->seq == tp->rcvnxt && !after(TCPSKBCB(skb)->ackseq, tp->sndnxt)) { int tcpheaderlen = tp->tcpheaderlen; ......ifdef CONFIGNETDMA
....endif
if (
.........
/* Bulk data transfer: receiver */
//接收数据到队列中 !!! 重要的一个环节
eaten = tcp_queue_rcv(sk, skb, tcp_header_len,
&fragstolen);
}
tcp_event_data_recv(sk, skb);
if (TCP_SKB_CB(skb)->ack_seq != tp->snd_una) {
/* Well, only one small jumplet in fast path... */
tcp_ack(sk, skb, FLAG_DATA);
tcp_data_snd_check(sk);
if (!inet_csk_ack_scheduled(sk))
goto no_ack;
}
if (!copied_early || tp->rcv_nxt != tp->rcv_wup)
__tcp_ack_snd_check(sk, 0);
...endif
if (eaten)
kfree_skb_partial(skb, fragstolen);
//该条socket连接上的数据已经准备好(或者说有数据就绪),
//则唤醒 socket 上阻塞掉的用户进程 !!也是重要的一步
sk->sk_data_ready(sk, 0);
return 0;
}
}csumerror: TCPINCSTATSBH(socknet(sk), TCPMIBCSUMERRORS); TCPINCSTATSBH(socknet(sk), TCPMIBINERRS); discard: _kfreeskb(skb); return 0; } `` 从上边的tcprcvestablished可以看出来,该函数内做了两个我们关注的事情 1. 接收数据到队列(skreceivequeue)中, 通过tcpqueue_rcv函数 2. 该条socket`连接上的数据已经准备好(或者说有数据就绪),则唤醒在该socket上阻塞的用户进程 !
注意:唤醒用户进程后,还伴随着一次进程状态的切换
另外,唤醒阻塞的用户进程后的工作也有很多,但是我们在这里不准备展开,而是准备在后续的tcp详解时,做对应的展开分析。
到这里,内核收包的理论工作基本就差不多了,下边我们用个小例子,把理论和实际结合一下
上边讲的理论与实际结合
在本小节,我为了结合实际,所以做个小demo,将我们前几个小节讲的: 1. 网卡收包 1. DMA到RingBuffer 2. 发出硬中断通知 3. 处理硬中断后发出软中断 4. 处理软中断(调用网卡初始化时候注册的poll函数从RingBuffer上获取数据包) 5. 将获取到的数据包copy成skb 6. 调用iprcv()进行ip层的处理 7. ip层处理完后传递给传输层处理通过tcpv4rcv 8. tcp层校验通过后将数据包放入skreceive_queue接收队列 9. 内核唤醒等待(阻塞)的用户进程,之后进行数据copy到用户空间同时进行进程状态切换
这些东西和实际编码结合起来!
BIOServer 源码如下: java /** * @Author: hzz * @Date: 2022/10/15 20:05:27 * @Description: */ public class BioServer { public static void main(String[] args) throws IOException { // 创建ServerSocket并且监听6666端口 ServerSocket serverSocket = new ServerSocket(6666); while (true) { // 监听---一直等待客户端连接 Socket socket = serverSocket.accept(); System.out.println("有客户端连接来了,此时已经是三次握手完成状态"+socket.toString()); try { // 获取客户端发送过来的输入流 InputStream inputStream = socket.getInputStream(); byte[] bytes = new byte[1024]; int read = inputStream.read(bytes); System.out.println("有数据报来了 read:"+read); // 读取发送过来的信息并打印 if (read != -1) { System.out.println(new String(bytes, 0, read)); } } catch (IOException e) { e.printStackTrace(); } finally { // 断开通讯 try { socket.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
第一步:启动BIOServer
debug 启动main方法,没什么好说的,略。
第二步:telnet与本地 6666端口建立一条tcp连接
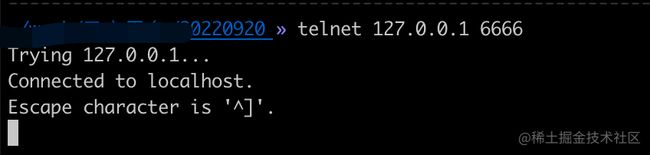
第三步:阻塞在了socket.getInputStream().read()方法
由于连接已经建立,所以accept不再阻塞,走到 int read = inputStream.read(bytes);这行代码后,阻塞在了read方法, 见下图: 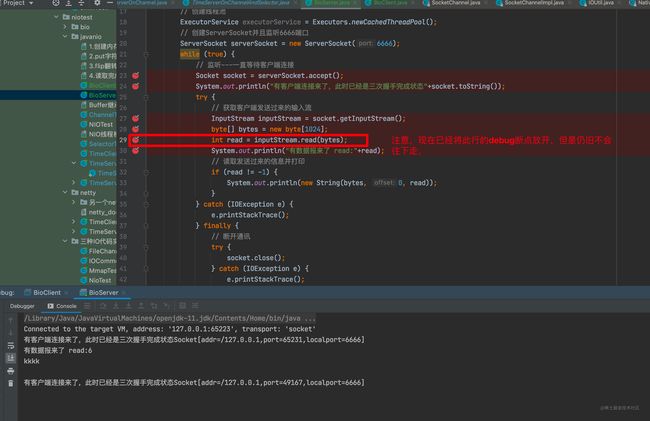
第四步:(客户端)输入点什么,然后回车,使得数据发送到本机服务端
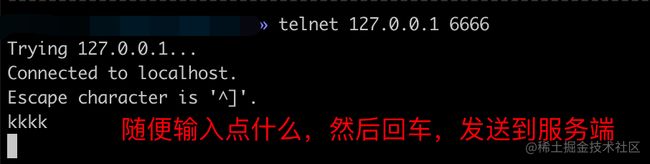
第五步:内核处理(收包分析章节的理论内容)
第五步是最关键的一步,也是我们上边讲了那么多的理论和实际(本demo)结合的一步。
注意:实际上,第五步整个的过程,在我们开发编码时,都是无感知的。可见写内核的大佬们是多么的煞费苦心 第五步细节如下:
- 网卡收到数据包
- 通过DMA将数据包保存到RingBuffer环形队列中去
- 向cpu发出硬中断通知
- 处理硬中断后发出软中断
- 处理软中断(调用网卡初始化时候注册的poll函数从RingBuffer上获取数据包)
- 将获取到的数据包copy成skb
- 调用ip_rcv()进行ip层的处理
- ip层处理完后传递给传输层
- 传输层通过tcpv4rcv对包进行处理:校验通过后将数据包放入skreceivequeue接收队列
- 内核唤醒等待(阻塞)的用户进程(对应本demo的话就是调用read方法阻塞的main-java进程),之后进行数据copy到用户空间同时进行进程状态切换为用户态
在第10步骤完成后,inputStream.read(bytes) 方法将退出阻塞状态,返回读到的字节长度!于是我们来到了下边的第六步,如下:
第六步:可以看到服务端的read不再阻塞,而是到了下一行,即打印了一句话,见下图:
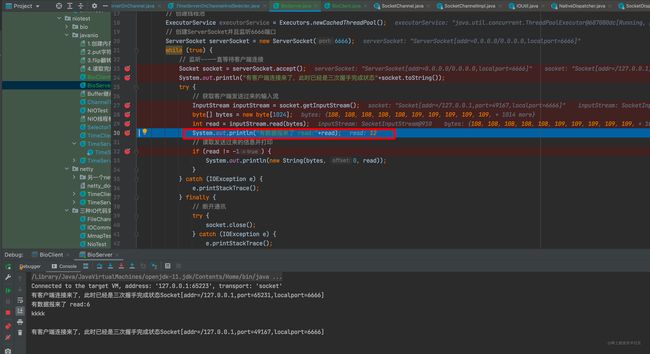
第七步:读到数据后,进行业务处理
do somthing .....
到此,我们第四节的收包分析就完成了。在本节最后,我们用了一个小demo,来将本节收包分析的理论内容和实际编码做了一个结合,希望此举措对理解本文有所帮助。
五、总结
到此,本文开篇中的两个问题:
- 问题1: 在收发数据包之前,底层系统做了哪些准备工作?
- 问题2: 接收到数据包后,内核是如何处理的?又是如何向上给到应用层的?
就算讲完了,问题1 对应的解答是第三小节(Linux内核启动与初始化);问题2 对应的解答是在第四节(收包分析)
下边,我们来总结一下本文所讲的内容:
内核启动和初始化总结:
注意:真正的内核初始化和启动工作远远不止我们下边总结的这些,我们关注的只是本文所涉及到的。 1. 内核初始化 - 内核初始化和启动的总入口是
start_kernel,在这个函数中会启动各个模块(大约100多个),以此来构建出最基础的内核环境。 - 在初始化内核这个环节,与本文联系密切的ksoftirqd内核线程被创建和启动 3. 网络子系统初始化 - 第一件事: 为收发包类型的软中断注册了 各自对应的处理函数,好在后边接收到这种(出去 or 进来的)软中断通知时,来从数组(softirq_vec)中拿到对应的函数的引用,来调用对应软中断处理函数来执行对应的软中断逻辑! - 第二件事: 为每个CPU都申请一个softnet_data数据结构,在这个数据结构里的poll_list作用是:等待各种类型的驱动程序将其poll函数注册进来用于后续使用,(poll函数用于拉取RingBuffer上的数据包5. 协议栈注册 - linux实现了很多协议,比如arp,icmp,ip,udp,tcp,每一个协议都会将自己的处理函数注册一下(如网络层是存到了:ip_packet_type,传输层协议是存到了:inet_protos中),方便包来了迅速找到对应的处理函数来执行。 7. 网卡初始化 - 在网卡初始化过程中,逻辑其实很复杂,我们这里只关注他注册的两个函数igb_open和igb_poll,因为igb_open是网卡启动的入口,igb_poll是从RingBuffer上获取数据包的关键! 9. 网卡启动 - 给发送/接收队列分配资源 - 开启NAPI机制 - 为不同网卡注册了硬中断处理函数 和设置硬中断通知的方式
到此,内核初始化和启动完成,可以收包了!
收包总结:
收包总结的话,我想下边这张图,会更直观,印象更深:
但是我们还是用文字简单来解释一下上图的流程: 1. 网卡收到数据包 1. 通过DMA将数据包保存到RingBuffer环形队列中去 2. 向cpu发出硬中断通知 3. 处理硬中断(网卡启动时注册的)后发出软中断 4. 处理软中断(调用网卡初始化时候注册的poll函数从RingBuffer上获取数据包) 5. 将获取到的数据包copy成skb 6. 调用iprcv()进行ip层的处理 7. ip层处理完后传递给传输层 8. 传输层通过tcpv4rcv对包进行处理:校验通过后将数据包放入skreceive_queue接收队列 9. 内核唤醒等待(阻塞)的用户进程,之后进行数据copy到用户空间同时将进程状态切换为用户态
站在巨人的肩膀,才能看的更远!
本篇文章部分参考:参考1
参考2到此,本文完,如有建议或指正欢迎留言,一起学习进步,扎实基础!