Flink读取HDFS上的Parquet文件生成DataSet
首先打开Flink的官方网站,查看一下DataSet已支持的数据源。
- File-based
readTextFile(path) / TextInputFormat - Reads files line wise and returns them as Strings.
readTextFileWithValue(path) / TextValueInputFormat - Reads files line wise and returns them as StringValues. StringValues are mutable strings.
readCsvFile(path) / CsvInputFormat - Parses files of comma (or another char) delimited fields. Returns a DataSet of tuples or POJOs. Supports the basic java types and their Value counterparts as field types.
readFileOfPrimitives(path, Class) / PrimitiveInputFormat - Parses files of new-line (or another char sequence) delimited primitive data types such as String or Integer.
readFileOfPrimitives(path, delimiter, Class) / PrimitiveInputFormat - Parses files of new-line (or another char sequence) delimited primitive data types such as String or Integer using the given delimiter.
- Collection-based
fromCollection(Collection) - Creates a data set from a Java.util.Collection. All elements in the collection must be of the same type.
fromCollection(Iterator, Class) - Creates a data set from an iterator. The class specifies the data type of the elements returned by the iterator.
fromElements(T ...) - Creates a data set from the given sequence of objects. All objects must be of the same type.
fromParallelCollection(SplittableIterator, Class) - Creates a data set from an iterator, in parallel. The class specifies the data type of the elements returned by the iterator.
generateSequence(from, to) - Generates the sequence of numbers in the given interval, in parallel.
- Generic
readFile(inputFormat, path) / FileInputFormat - Accepts a file input format.
createInput(inputFormat) / InputFormat - Accepts a generic input format.
显然,Parquet的读写是第3种–泛型模式,其关键是构建好InputFormat接口的Parquet实现类。
Github上clone下flink的源码,IDEA打开并找到InputFormat接口,查看其继承关系。
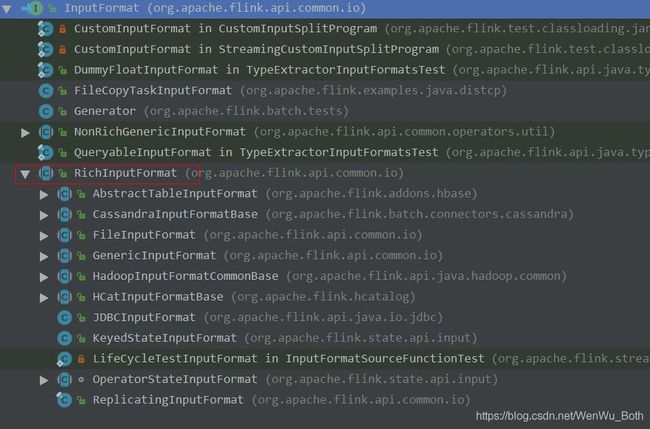
RichInputFormat是InputFormat接口的关键实现类,它是一个抽象类,其主要在接口上增加了Flink的运行上下文。
接着打开RichInputFormat抽象类的继承关系:

很明显,FileInputFormat里的ParquetInputFormat就是我们想要的。
可以看到,FileInputFormat除了支持Parquet,还支持了Avro、Orc等格式。
接着往下跟:
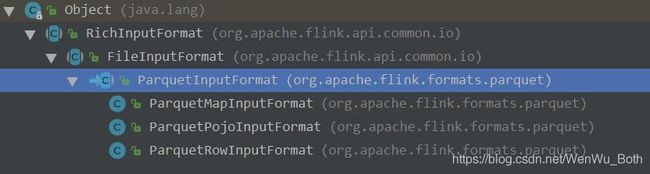
ParquetInputFormat支持Map、Pojo、Row类型,分别对应嵌套、简单实体类、列表,这里选常用的ParquetPojoInputFormat进去看一下:
/**
* An implementation of {@link ParquetInputFormat} to read POJO records from Parquet files.
*/
public class ParquetPojoInputFormat extends ParquetInputFormat {
private static final Logger LOG = LoggerFactory.getLogger(ParquetPojoInputFormat.class);
private final Class pojoTypeClass;
private final TypeSerializer typeSerializer;
private transient Field[] pojoFields;
public ParquetPojoInputFormat(Path filePath, MessageType messageType, PojoTypeInfo pojoTypeInfo) {
super(filePath, messageType);
this.pojoTypeClass = pojoTypeInfo.getTypeClass();
this.typeSerializer = pojoTypeInfo.createSerializer(new ExecutionConfig());
final Map fieldMap = new HashMap<>();
findAllFields(pojoTypeClass, fieldMap);
selectFields(fieldMap.keySet().toArray(new String[0]));
}
...
}
构造函数需要传入3个参数:
- Path filePath
文件路径,传入路径字符串pathString,然后new Path(pathString)即可。
- MessageType messageType
Parquet文件的Schema,这个有点难搞,后面我们主要讲这个参数如何构建。
- PojoTypeInfo pojoTypeInfo
简单实体类的TypeInfo,直接PojoTypeInfo.of(E.class)即可。
要获取Parquet文件的Schema,主要有3种方法:
- 通过Schema字符串构建
/**
* @description 根据schema字符串创建MessageType
*
* @param schema
* @return org.apache.parquet.schema.MessageType
*/
public static MessageType build(String schema){
return MessageTypeParser.parseMessageType(schema);
}
该种方法需要我们为每个实体类均提前构建好schema字符串,不方便,不用。
- 根据已有parquet文件构建
讲解这种方式前,大家需要了解下Parquet的文件结构:
一个Parquet文件是由一个header以及一个或多个block块组成,以一个footer结尾。header中只包含一个4个字节的数字PAR1用来识别整个Parquet文件格式。文件中所有的metadata都存在于footer中。footer中的metadata包含了格式的版本信息,schema信息、key-value paris以及所有block中的metadata信息。footer中最后两个字段为一个以4个字节长度的footer的metadata,以及同header中包含的一样的PAR1。
读取一个Parquet文件时,需要完全读取Footer的meatadata,Parquet格式文件不需要读取sync markers这样的标记分割查找,因为所有block的边界都存储于footer的metadata中。
所以,只需要读取目标目录中的任何一个Parquet文件即可拿到footer信息,解析footer即可得到Schema。
/**
* @description 根据Parquet文件创建schema
*
* @param parquetFilePath
* @return org.apache.parquet.schema.MessageType
*/
public static MessageType buildFromFile(Path parquetFilePath) throws Exception {
Configuration configuration = new Configuration();
ParquetMetadata readFooter = null;
readFooter = ParquetFileReader.readFooter(configuration,
parquetFilePath, ParquetMetadataConverter.NO_FILTER);
MessageType schema =readFooter.getFileMetaData().getSchema();
return schema;
}
/**
* @description 根据Parquet文件创建schema
*
* @param pathUrl
* @return org.apache.parquet.schema.MessageType
*/
public static MessageType buildFromFile(String pathUrl) throws Exception {
Path parquetFilePath = new Path(pathUrl);
return buildFromFile(parquetFilePath);
}
该方法勉强满足我们的需求,但每次读取parquet目录,需要先取一个文件拿来"解剖"拿到Schema才能读取全部文件,听起来就不够优雅,不用。
- 反射
基本思想是通过反射得到实体类各个字段的类型,然后对应成Parquet Schema里的类型。
下面为简单示例:
/**
* @description 根据类信息动态解析成MessageType
*
* @param clazz
* @param messageName
* @return org.apache.parquet.schema.MessageType
*/
public static MessageType build(Class clazz, String messageName){
Field[] fields = clazz.getDeclaredFields();
Types.MessageTypeBuilder builder = Types.buildMessage();
for(Field field: fields){
field.setAccessible(true);
String[] fieldTypes = field.getType().toString().toLowerCase().split("\\.");
String fieldType = fieldTypes[fieldTypes.length-1];
String fieldName = field.getName();
if("string".equals(fieldType)){
builder.required(PrimitiveType.PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named(fieldName);
}else if("int".equals(fieldType) || "integer".equals(fieldType) || "short".equals(fieldType)){
builder.required(PrimitiveType.PrimitiveTypeName.INT32).named(fieldName);
}else if("long".equals(fieldType)){
builder.required(PrimitiveType.PrimitiveTypeName.INT64).named(fieldName);
}else if("float".equals(fieldType)){
builder.required(PrimitiveType.PrimitiveTypeName.FLOAT).named(fieldName);
}else if("double".equals(fieldType)){
builder.required(PrimitiveType.PrimitiveTypeName.DOUBLE).named(fieldName);
}else if("boolean".equals(fieldType)){
builder.required(PrimitiveType.PrimitiveTypeName.BOOLEAN).named(fieldName);
}else {
builder.required(PrimitiveType.PrimitiveTypeName.BINARY).named(fieldName);
}
}
return builder.named(messageName);
}
/**
* @description 根据类信息动态解析成MessageType
*
* @param clazz
* @return org.apache.parquet.schema.MessageType
*/
public static MessageType build(Class clazz){
String className = clazz.getName();
return build(clazz, className);
}
上面的代码勉强可以应付大部分的实体类,但当实体类的字段为Timestamp、Date、List、Map等非基础类型时,则需要继续丰富上述代码,同时还需要考虑字符编码等各类问题才能使上述方法变得健壮。
我,当然可以手动撸一个出来,不怂!!!
但是,太麻烦,肯定有现成的轮子了,何不拿来直接用一下。
回想之前DataStream持久化Parquet文件的时候,曾经用过反射来生成Parquet的Schema,去瞅一眼:
// ParquetAvroWriters.java
public static ParquetWriterFactory forReflectRecord(Class type) {
// 基于类反射拿到Avro的Schema
final String schemaString = ReflectData.get().getSchema(type).toString();
final ParquetBuilder builder = (out) -> createAvroParquetWriter(schemaString, ReflectData.get(), out);
return new ParquetWriterFactory<>(builder);
}
怎么又扯出来Avro了,其实就是用了下Avro的相关转换类来完成Parquet文件Schema的生成。
基本逻辑就是,Avro工具类基于实体类的Class通过反射生成Avro文件Schema,然后Avro工具类再将Avro文件Schema转化成Parquet文件的Schema。
跟踪一下Avro的相关代码,一通乱点,盲猜到上述Avro工具类为AvroSchemaConverter。
点进去看一下其主要方法:

哈哈哈哈哈哈,果然是你,ok,大功告成,调用AvroSchemaConverter工具类的convert方法即可将Avro的Schema转化为Parquet的Schema,即MessageType。
public MessageType convert(Schema avroSchema) {
if (!avroSchema.getType().equals(Type.RECORD)) {
throw new IllegalArgumentException("Avro schema must be a record.");
} else {
return new MessageType(avroSchema.getFullName(), this.convertFields(avroSchema.getFields()));
}
}
将其封装成1个方法:
public class MessageTypeBuilderByAvro{
public static MessageType build(Class tClass){
Schema avroSchema = ReflectData.get().getSchema(tClass);
MessageType messageType = new AvroSchemaConverter().convert(avroSchema);
return messageType;
}
}
自此,ParquetPojoInputFormat的3个参数均完美构建,下面就可以在Flink中愉快的读取HDFS上的Parquet文件并生成DataSet了,美滋滋!!!
DataSource PojoDataSource = env.createInput(new ParquetPojoInputFormat(
new Path(pathString),
MessageTypeBuilderByAvro.build(E.class),
(PojoTypeInfo) PojoTypeInfo.of(E.class)
));