【Apache Phoenix简介、存储结构、基本操作、安装】
Apache Phoenix简介、存储结构、基本操作、安装(附安装包)
- 1. 简介、概述
-
- 1.1 phoenix 特点
- 1.2 存储结构
- 1.3 Phoenix 与 Hbase 之间的表映射关系
- 1.4 Phoenix数据类型
- 2. 基于CDH6.3.2离线安装 Phoenix Parcel 5.0.0-2.0(附安装包)
- 3. Phoenix 常用命令、基本操作
- 4. 补充
1. 简介、概述

Phoenix 最早是 saleforce 的一个开源项目,后来成为 Apache 的顶级项目。
Phoenix 构建在 HBase 之上的开源 SQL 层。能够让我们使用标准的 JDBC API 去建表,插入数据和查询 HBase 中的数据,从而可以避免使用 HBase 的客户端 API。
Apache Phoenix 通过结合两个方面的优点,在Hadoop中为低延迟应用提供了OLTP和运营分析:
-
具有完全ACID事务功能的标准SQL和JDBC api的强大功能
-
通过利用HBase作为后台存储,从NoSQL获得后期绑定的、读时模式功能的灵活性
Apache Phoenix与Spark、Hive、Pig、Flume、Map Reduce等Hadoop产品完全集成。
通过定义良好的行业标准api,成为OLTP和Hadoop操作分析的可信数据平台。
在我们的应用和 HBase 之间添加了 Phoenix,并不会降低性能,而且我们也少写了很多代码。
1.1 phoenix 特点
-
将 SQL 查询编译为 HBase 扫描
-
完美支持 HBase 二级索引创建
-
支持完整的ACID事务、UDF、分页查询
-
确定扫描 Rowkey 的最佳开始和结束位置、扫描并行执行
-
将 where 子句推送到服务器端的过滤器
-
通过协处理器进行聚合操作
-
DML 命令以及通过 DDL 命令创建和操作表和版本化增量更改。
-
容易集成:如Spark,Hive,Pig,Flume 和 Map Reduce。
-
支持java、python的Driver
1.2 存储结构
HBase 的数据模型映射为关系型数据模型
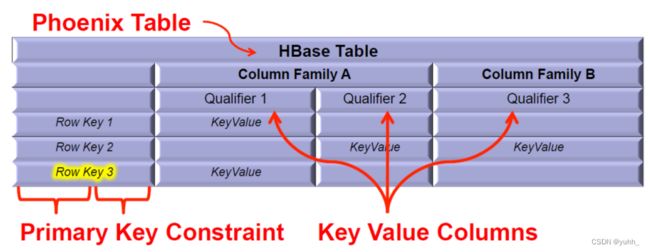
对于Phoenix来说,HBase的rowkey会被转换成primary key,column family如果不指定则为0否则字段名会带上,qualifier转换成表的字段名
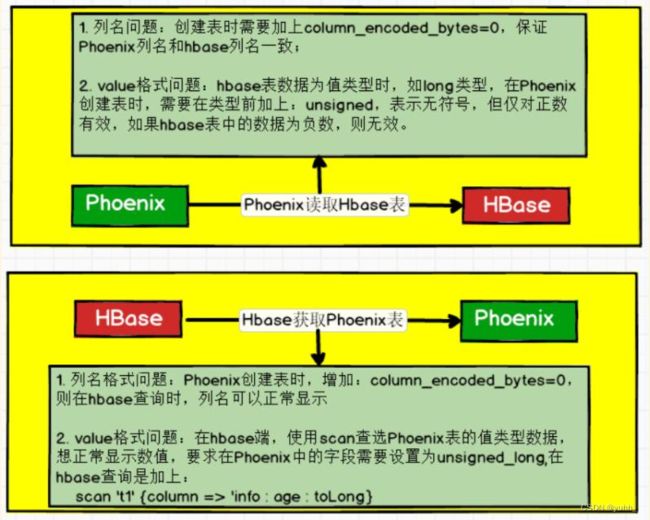
1.3 Phoenix 与 Hbase 之间的表映射关系
1.4 Phoenix数据类型
| 数据类型 | Java Map | 占用大小 (byte) |
|---|---|---|
| INTEGER | java.lang.Integer | 4 |
| UNSIGNED_INT | java.lang.Integer | 4 |
| BIGINT | java.lang.Long | 8 |
| UNSIGNED_LONG | java.lang.Long | 8 |
| TINYINT | java.lang.Byte | 1 |
| UNSIGNED_TINYINT | java.lang.Byte | 1 |
| SMALLINT | java.lang.Short | 2 |
| UNSIGNED_SMALLINT | java.lang.Short | 2 |
| FLOAT | java.lang.Float | 4 |
| UNSIGNED_FLOAT | java.lang.Float | 4 |
| DOUBLE | java.lang.Double | 8 |
| UNSIGNED_DOUBLE | java.lang.Double | |
| DECIMAL | java.math.BigDecimal | DECIMAL(p.,s) |
| BOOLEAN | java.lang.Boolean | |
| TIME | java.sql.Time | |
| DATE | java.sql.Date | 8 |
| TIMESTAMP | java.sql.Timestamp | 12 |
| UNSIGNED_TIME | java.sql.Time | 8 |
| UNSIGNED_DATE | java.sql.Date | 8 |
| UNSIGNED_TIMESTAMP | java.sql.Timestamp | 12 |
| VARCHAR | java.lang.String | VARCHAR(n) |
| CHAR | java.lang.String | CHAR(n) |
| BINARY | byte[] | BINARY(n) |
| VARBINARY | byte[] | VARBINARY |
2. 基于CDH6.3.2离线安装 Phoenix Parcel 5.0.0-2.0(附安装包)
# 本安装方式为Linux http源离线安装方式,不需要可跳过此步骤
CDH6.3.2 phoenix5.0.0-2.0 百度网盘 parcel安装包下载地址
链接:https://pan.baidu.com/s/1VpNYiZKToHAdeBKUylgQsQ
提取码:qstv
1.提前下载下面几个文件并放置在cdh主节点的/var/www/html下,PHOENIX-1.0.jar放置在/opt/cloudera/csd下
manifest.json
PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el6.parcel
PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el6.parcel.sha
PHOENIX-1.0.jar
2.启动httpd
systemctl start httpd
如果已启动则不需要再启动,访问主节点ip/phoenix看是否启动成功,若出现下面的界面则成功。
如果没有httpd就使用yum安装一下:
yum install -y httpd
3.使用parcel安装Phoenix5
在CM中选择主机->Parcel–>配置.如果有未安装的parcel包,可以直接看到,选择它然后点击保存,点击’分配’–>‘激活’.


4.CM中添加Phoenix服务
确定CSD配置目录/opt/cloudera/csd,在CM中选择管理–>设置,搜索csd对路径配置

把下载的PHOENIX-1.0.jar已经放置在了/opt/cloudera/csd,直接重启CM服务.
# Cloudera-UI不生效,需使用命令重新启动
systemctl restart cloudera-scm-server
重新登录CM,重启Cloudera Management Service过期配置服务。
此时可以看到Phoenix已经出现在CM的管理页面:

5.配置HBASE
phoenix是在hbase上实现了SQL接口,并且手工安装开源版phoenix的时候也需要在hbase节点的lib目录下放置phoenix的jar包,通过CM安装就免去这些手工的工作。
在Hbase–>配置 中搜索hbase-site,然后在"hbase-site.xml 的 HBase 服务高级配置代码段" 中配置如下内容。
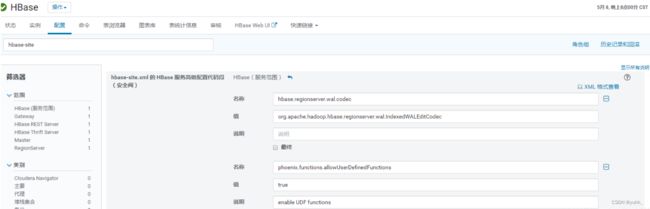
或点击以XML格式查看,输入下面的代码:
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>phoenix.functions.allowUserDefinedFunctions</name>
<value>true</value>
<description>enable UDF functions</description>
</property>
修改完成后重启hbase服务。
6.启动Phoenix验证
/opt/cloudera/parcels/PHOENIX/bin/phoenix-sqlline hbase1,hbase2,hbase3
或
phoenix-sqlline
3. Phoenix 常用命令、基本操作
# 启动phoenix shell
phoenix-sqlline
# 退出
!quit
# 查看所有表
!tables
# 查询表
select * from "test";
# 查看表描述
!desc 表名
# 删除表
drop table "test";
# 使用视图view映射Hbase中表
view只可进行查询,且在删除表时不删除Hbase中源表,只删除当前view映射
view名称需与表名一致,view列名和hbase列族名的列限定符一致
create view "test" (id varchar primary key,"info"."createtime" UNSIGNED_DATE,"info1"."age" UNSIGNED_LONG)column_encoded_bytes=0;
# 使用Table映射Hbase中表
对phoenix中Table进行CRUD时,Hbase中表也会发生变化。
drop table 时 也会删除Hbase中表。
create table "test" ("ROW" varbinary primary key,"info"."createtime" varbinary,"info1"."age" varbinary)column_encoded_bytes=0;
# 插入数据
put 'test','1001','info:createtime',Bytes.toBytes(1602237645881)
put 'test','1001','info1:age',Bytes.toBytes(16)
4. 补充
- 类型前添加:unsigned_ 表示无符号,但仅对正数有效,如果hbase中的数据为负数则无效(unsigned_*类型)
- column_encoded_bytes=0 表示与Hbase中字段相同
Apache pheonix 官方地址:https://phoenix.apache.org/