NLP词向量模型总结:从Elmo到GPT,再到Bert
词向量历史概述
提到NLP,总离开不了词向量,也就是我们经常说的embedding,因为我们需要把文字符号转化为模型输入可接受的数字向量,进而输入模型,完成训练任务。这就不得不说这个转化的历史了。
起初用于把文字转化向量,用的是最基础的词袋模型,类似于one-hot,不得不说,这种做法很简单粗暴,现在也还在用,但是维度过高,并且有些词出现多次一般来说更重要,而这种词袋模型无法表示,于是出现了以频率为权重的词袋模型,这种词袋模型认为频率高的词有着更高的重要度,但是出现多次的词并不一定是更重要的词,比如一些停用词,出现次数极多,却是无关紧要的,于是出现了TF-IDT,该模型用词频和逆文档词频来来综合衡量一个词的重要程度,然而,也有问题,TF-IDF无法表示出文本中的顺序信息,“我爱钱美娟”和“钱美娟爱我”完全是两个意思,为了解决这个问题,于是出现了N-gram,N-gram模型能够表示词与词之间的顺序关系,但是还有问题,其无法识别同义词,不能够表示词的相近关系,于是在2013年,谷歌提出了word2vec,word2vec当时红极一时,用word2vec训练出来的词向量,可以很好的表示出词向量之间的相似关系,效果很好。然而,长江后浪推前浪,前浪还是被拍死在沙滩上,再好的模型,总是有不足之处,总会有后续更好的模型出现。word2vec的不足之处在于其是一个静态的训练模型,无法表示出一词多义,你说“苹果”是指苹果公司呢,还是水果呢?我也不知道,但是上下文语境知道啊,于是出现了后续更为强大的预训练模型,诸如Elmo、GPT、Bert之类,后面会详解。
从上面我们知道, 文本表征的向量表示一直在进步,后一代的工具方法针对前一代的不足进行优化。对于NLP而言,普通的机器学习模型有着天然的短板,诸如lr,beiyes,svm此类的模型,无法学习到文本序列信息,其跟深度学习模型相比,效果不免差强人意,于是出现了lstm,gru,其适用于短文本,能学习到上文信息,但是无法学习到下文信息,所以呢,聪明的人类对其进行了改造,出现了bilstm,bigru,这样上下文信息都学习到了,但是啊,模型在学习的时候没有重点,特别在机器翻译中,效果不好,于是出现了attention机制,嗯嗯,效果确实好了一点。但是在RNN体系中,由于其结构特点,在反向传播的时候无法用硬件加速,训练速度太慢了,于是谷歌爸爸站起来了:提出了transform结构,不仅效果好,还可以并行,速度快。说了这么多,历史就扯到这里吧,下面重点讲解一下Elmo、GPT、Bert这三个方面的内容。
ELMO详解
从上文我们知道了word2vec无法解决一词多义的问题,其本质上是个静态的训练方式,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的Word Embedding不会跟着上下文场景的变化而改变,所以对于比如Bank这个词,它事先学好的Word Embedding中混合了几种语义 ,在应用中来了个新句子,即使从上下文中(比如句子包含money等词)明显可以看出它代表的是“银行”的含义,但是对应的Word Embedding内容也不会变,它还是混合了多种语义。这是为何说它是静态的,这也是问题所在。为了缓解或者说是解决这个问题,出现了ELMO,ELMO的本质思想是:我事先用语言模型学好一个单词的Word Embedding,此时多义词无法区分(可能混合多种词义),不过这没关系。在我实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。ELMO采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练,模型结构如下图所示:
第一阶段
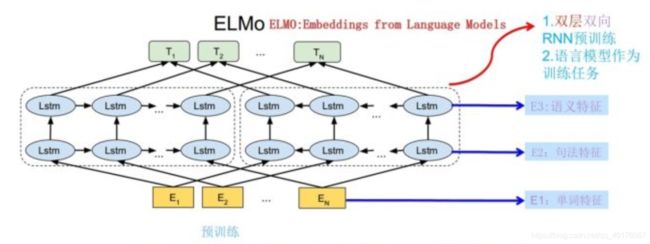
图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外 的上文Context-before;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文Context-after;每个编码器的深度都是两层LSTM叠加。这个网络结构其实在NLP中是很常用的。使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子 ,句子中每个单词都能得到对应的三个Embedding:最底层是单词的Word Embedding,往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。也就是说,ELMO的预训练过程不仅仅学会单词的Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。
从数学的角度来说,原理如下:
前向语言模型lstm的似然概率如下:
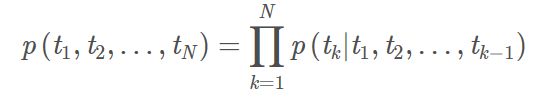
前向语言模型lstm的似然概率如下:

前向语言模型和后向语言模型进行结合,直接最大化前向和后向语言模型的对数概率,即:

其中 Θ x \Theta_{x} Θx和 Θ s \Theta_{s} Θs分别表示词向量矩阵和softmat层的参数,在前向和后向LSTM中都是共享的。在训练完biLM后,假设biLM有L层,则对于每一个词汇 t k t_{k} tk,总共会有2L+1个输出向量,因为每一层LSTM都会有前向和后向两个向量输出,而每个词汇自己有embedding层的向量,因此总共是2L+1,表示如下:

对于具体的NLP任务,ELMo会训练一个权重向量对每一个词汇的输出向量进行线性加权,表示如下:

其中 s t a s k s^{task} stask是softmax规范化后的权重向量, γ t a s k \gamma^{task} γtask是一个放缩参数。由于biLM每一层的向量输出分布可能不同,因此,在进行线性加权之前,也可以考虑对每个向量进行Layer Normalization。
第二阶段
对于第一阶段已经预训练好的ELMO模型,下面进入第二阶段,如何在具体的nlp任务场景中使用,假如我们的下游任务是QA问题,此时对于问句X,我们可以先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding(假如是双层网络),之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
ELMO的不足之处
- 特征抽取器使用的还是传统的lstm,其特征抽取能力和训练速度都远远弱于Transformer;
- 拼接方式双向融合特征融合能力偏弱,ELMo在模型层上就是一个stacked bi-lstm(严格来说是训练了两个单向的stacked lstm),ELMo有用双向RNN来做encoding,但是这两个方向的RNN其实是分开训练的,只是在最后在loss层做了个简单相加。这样就导致对于每个方向上的单词来说,在被encoding的时候始终是看不到它另一侧的单词的。而显然句子中有的单词的语义会同时依赖于它左右两侧的某些词,仅仅从单方向做encoding是不能描述清楚的。
GPT详解
上文中我们讲到,ELMO的一个不足之处在于其特征抽取能力比较弱,用的是LSTM,而不是Transformer,于是出现了Generative Pre-Training, 简称GPT,从名字看其含义是指的生成式的预训练。GPT也采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过Fine-tuning的模式解决下游任务。GPT的结构如下图所示:
第一阶段

上图展示了GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:首先,特征抽取器不是用的RNN,而是用的Transformer,上面提到过它的特征抽取能力要强于RNN,这个选择很明显是很明智的;其次,GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓“单向”的含义是指:语言模型训练的任务目标是根据 W i W_i Wi单词的上下文去正确预测单词 W i W_i Wi , W i W_i Wi 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。ELMO在做语言模型预训练的时候,预测单词 W i W_i Wi同时使用了上文和下文,而GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文。这个选择现在看不是个太好的选择,原因很简单,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果,比如阅读理解这种任务,在做任务的时候是可以允许同时看到上文和下文一起做决策的。如果预训练时候不把单词的下文嵌入到Word Embedding中,是很吃亏的,白白丢掉了很多信息。
第二阶段
首先,对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向GPT的网络结构看齐,把任务的网络结构改造成和GPT的网络结构是一样的。然后,在做下游任务的时候,利用第一步预训练好的参数初始化GPT的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来了,这是个非常好的事情。再次,你可以用手头的任务去训练这个网络,对网络参数进行Fine-tuning,使得这个网络更适合解决手头的问题。
但是,对于NLP各种花样的不同任务,怎么改造才能靠近GPT的网络结构呢?这里有一份“武林秘籍”,可以参照修炼,如下图所示:

GPT论文给了一个改造施工图如上,其实也很简单:对于分类问题,不用怎么动,加上一个起始和终结符号即可;对于句子关系判断问题,比如Entailment,两个句子中间再加个分隔符即可;对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可。
GPT的不足之处
那么站在现在的时间节点看,GPT有什么值得改进的地方呢?其实最主要的就是那个单向语言模型,如果改造成双向的语言模型任务。效果应该更上一层楼。当然,即使如此GPT也是非常非常好的一个学术研究 。
Bert详解
从上文中我们已经知道,ELMO的不足之处在于特征抽取能力弱以及不是严格意义上的双向语言模型,GPT的虽然有着强悍的特征抽取能力,但是确实单向语言模型。
为什么不做真正的双向语言模型呢?
传统的语言模型是以预测下一个词为训练目标的,然而如果做了双向encoding的话,那不就表示要预测的词已经看到了么,这样的预测当然没有意义了。所以,在BERT中,提出了使用一种新的任务来训练监督任务中的那种真正可以双向encoding的模型,这个任务称为Masked Language Model (Masked LM)。
Masked LM
顾名思义,Masked LM就是说,我们不是像传统LM那样给定已经出现过的词,去预测下一个词,而是直接把整个句子的一部分词(随机选择)盖住(make it masked),这样模型不就可以放心的去做双向encoding了嘛,然后就可以放心的让模型去预测这些盖住的词是啥,是不是有点类似于我们中学时做的完形填空?本质上是一样的。
这个方式看似巧妙,但是会导致一些问题,虽然可以放心的双向encoding了,但是这样在encoding时把这些盖住的标记也给encoding进去了,而这些mask标记在下游任务中是不存在,那怎么办呢?对此,为了尽可能的把模型调教的忽略这些标记的影响,作者通过如下方式来告诉模型“这些是噪声是噪声!靠不住的!忽略它们吧!”,对于一个被盖住的单词:
- 有80%的概率用“[mask]”标记来替换
- 有10%的概率用随机采样的一个单词来替换
- 有10%的概率不做替换(虽然不做替换,但是还是要预测哈)
Encoder
在encoder的选择上,作者并没有用烂大街的bi-lstm,而是使用了可以做的更深、具有更好并行性的Transformer encoder来做。这样每个词位的词都可以无视方向和距离的直接把句子中的每个词都有机会encoding进来。另一方面我主观的感觉Transformer相比lstm更容易免受mask标记的影响,毕竟self-attention的过程完全可以把mask标记针对性的削弱匹配权重,但是lstm中的输入门是如何看待mask标记的那就不得而知了。
注意,直接用Transformer encoder显然不就丢失位置信息了嘛?难道作者这里也像Transformer原论文中那样搞了个让人怕怕的sin、cos函数编码位置?并木有,作者这里很简单粗暴的直接去训练了一个position embedding ╮( ̄▽ ̄””)╭ 这里就是说,比如我把句子截断到50的长度,那么我们就有50个位置嘛,所以就有50个表征位置的单词,即从位置0一直到位置49。。。然后给每个位置词一个随机初始化的词向量,再随他们训练去吧(很想说这特喵的也能work?太简单粗暴了吧。。。)。另外,position embedding和word embedding的结合方式上,BERT里选择了直接相加。
学习句子与句对关系表示
在很多任务中,仅仅靠encoding是不足以完成任务的(这个只是学到了一堆token级的特征),还需要捕捉一些句子级的模式,来完成SLI、QA、dialogue等需要句子表示、句间交互与匹配的任务。对此,BERT又引入了另一个极其重要却又极其轻量级的任务,来试图把这种模式也学习到,称为Next Sentence Prediction,用了负采样的方法。
句子级负采样
了解word2vec的都知道,word2vec的一个精髓是引入了一个优雅的负采样任务来学习词向量(word-level representation)嘛。那么如果我们把这个负采样的过程给generalize到sentence-level呢?这便是BERT学习sentence-level representation的关键啦。BERT这里跟word2vec做法类似,不过构造的是一个句子级的分类任务。即首先给定的一个句子(相当于word2vec中给定context),它下一个句子即为正例(相当于word2vec的中心词),随机采样一个句子作为负例(相当于word2vec中随机采样的词),然后在该sentence-level上来做二分类(即判断句子是当前句子的下一句还是噪声)。通过这个简单的句子级负采样任务,BERT就可以像word2vec学习词表示那样轻松学到句子表示啦,那么怎么表示的呢,看下面。
句子级表示
BERT这里并没有像下游监督任务中的普遍做法一样,在encoding的基础上再搞个全局池化之类的,它首先在每个sequence(对于句子对任务来说是两个拼起来的句子,对于其他任务来说是一个句子)前面加了一个特殊的token,记为[CLS],如图
![]()
然后让encoder对[CLS]进行深度encoding,深度encoding的最高隐层即为整个句子/句对的表示啦。这个做法乍一看有点费解,不过别忘了,Transformer是可以无视空间和距离的把全局信息encoding进每个位置的,而[CLS]作为句子/句对的表示是直接跟分类器的输出层连接的,因此其作为梯度反传路径上的“关卡”,当然会想办法学习到分类相关的上层特征啦。
另外,为了让模型能够区分里面的每个词是属于“左句子”还是“右句子”,作者这里引入了“segment embedding”的概念来区分句子。对于句对来说,就用embedding A和embedding B来分别代表左句子和右句子;而对于句子来说,就只有embedding A啦。这个embedding A和B也是随模型训练出来的。
所以最终BERT每个token的表示由token原始的词向量token embedding、前文提到的position embedding和这里的segment embedding三部分相加而成,如图:

Bert和GPT一样,也分两个阶段,第一阶段:预训练过程,第二阶段:适应具体业务场景,进行结构改造。改造示意图如下图:

其实,为每个NLP任务去深度定制泛化能力极差的复杂模型结构其实是非常不明智的,走偏了方向的。既然ELMo相比word2vec会有这么大的提升,这就说明预训练模型的潜力远不止为下游任务提供一份精准的词向量,所以我们可不可以直接预训练一个龙骨级的模型呢?如果它里面已经充分的描述了字符级、词级、句子级甚至句间关系的特征,那么在不同的NLP任务中,只需要去为任务定制一个非常轻量级的输出层(比如一个单层MLP)就好了,毕竟模型骨架都已经做好了嘛,而Bert就是做了这样的一件事,而且效果还不错。那么是怎么做的呢,是其轻量级的接口设计。
简洁到过分的下游任务接口
真正体现出BERT这个模型是龙骨级模型而不再是词向量的,就是其到各个下游任务的接口设计了,或者换个更洋气的词叫迁移策略。
首先,既然句子和句子对的上层表示都得到了,那么当然对于文本分类任务和文本匹配任务(文本匹配其实也是一种文本分类任务,只不过输入是文本对)来说,只需要用得到的表示(即encoder在[CLS]词位的顶层输出)加上一层MLP就好了呀~

既然文本都被深度双向encoding了,那么做序列标注任务就只需要加softmax输出层就好了呀,连CRF都不用了呀~

到这里,ELMO、GPT、Bert,都讲的差不多了,现在来看这三个模型之间千丝万缕的联系。

从上图可见,Bert其实和ELMO及GPT存在千丝万缕的关系,比如如果我们把GPT预训练阶段换成双向语言模型,那么就得到了Bert;而如果我们把ELMO的特征抽取器换成Transformer,那么我们也会得到Bert。所以你可以看出:Bert最关键两点,一点是特征抽取器采用Transformer;第二点是预训练的时候采用双向语言模型,当然还借鉴了word2vec的负采样思想。
另外,我们应该弄清楚预训练这个过程本质上是在做什么事情,本质上预训练是通过设计好一个网络结构来做语言模型任务,然后把大量甚至是无穷尽的无标注的自然语言文本利用起来,预训练任务把大量语言学知识抽取出来编码到网络结构中,当手头任务带有标注信息的数据有限时,这些先验的语言学特征当然会对手头任务有极大的特征补充作用,因为当数据有限的时候,很多语言学现象是覆盖不到的,泛化能力就弱,集成尽量通用的语言学知识自然会加强模型的泛化能力。如何引入先验的语言学知识其实一直是NLP尤其是深度学习场景下的NLP的主要目标之一,不过一直没有太好的解决办法,而ELMO/GPT/Bert的这种两阶段模式看起来无疑是解决这个问题自然又简洁的方法,这也是这些方法的主要价值所在。