Pytorch-搭建网络框架(四)——学习率调整策略
Hello
学习率/LR:控制参数更新的步长
梯度下降:
![]()
学习率调整策略:前期大,后期小
pytorch中有6中学习率调整策略,但都是基于class_LRScheduler类
class_LRScheduler
基本属性:
optimizer:学习率所关联的优化器
last_epoch:记录epoch数,即学习率的调整是以epoch为周期的
base_lrs:记录初始学习率
主要方法:
step():更新下一个epoch的学习率
get_lr():虚函数,需要override,计算下一个epoch的学习率
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
#在epoch循环中
scheduler.step() # 循环最后,更新学习率
1、StepLR
lr_scheduler(optimizer,step_size,gamma=0.1,last_epoch=-1)
功能:等间隔调整学习率
主要参数:
step_size:调整间隔数
gamma:调整系数
调整方式:lr = lr*gamma
2、MultiStepLR
lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.1)
功能:按给定间隔调整学习率
主要参数:
milestones:设定调整时刻
gamma:调整系数
公式:lr = lr*gamma
milestones = [50,125,160] # 学习率调整时刻,无需等间隔,自定义即可
scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.1)
3、ExponentialLR
lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
功能:按指数衰减调整学习率
主要参数:
gamma:指数的底
调整方式:lr = lr*gamma**epoch
gamma = 0.95
scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
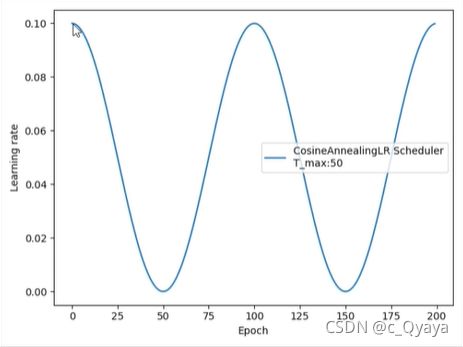
4、CosineAnnealingLR
lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
功能:余弦周期调整学习率
主要参数:
T_max:下降周期,即三角函数周期的一半
eta_min:学习率下限,即学习率可以下降的最低点
t_max = 50 # 即50个epoch后学习率下降到最低点
scheduler_lr = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=t_max, eta_min=0)
5、 ReduceLRonPlateau
lr_scheduler.ReduceLROnPlateau(optimizer, mode=‘min’, factor=0.1, patience=10, verbose=False,threshold=0.0001, threshold_mode=‘rel’, cooldown=0, min_lr=0, eps=1e-08)
功能:监控某个指标,当指标不再变化则调整,如loss,accuracy
主要参数:
mode:min/max 两种模式,min:当监控的指标不下降就调整(loss),max:当监控的指标不上升就调整(accuarcy)
factor:调整系数,类似之前的gamma
patience:“耐心 ”,接受指标连续几次不变化
cooldown:“冷却时间”,调整完loss之后,停止监控一段时间
verbose:布尔变量,是否打印日志
min_lr:学习率下限
eps:学习率衰减最小值
loss_value = 0.5
accuray = 0.9
factor = 0.1
mode = "min"
patience = 10
cooldown = 10
min_lr = 1e-4
verbose = True
scheduler_lr = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=factor, mode=mode, patience=patience,
cooldown=cooldown, min_lr=min_lr, verbose=verbose)
#epoch循环中
scheduler_lr.step(loss_value) # 监控loss_value
6、LambdaLR
lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
功能:自定义调整策略
主要参数:
lr_lambda:function or list,list的时候,其中每个元素也必须是function
weights_1 = torch.randn((6, 3, 5, 5))
weights_2 = torch.ones((5, 5))
optimizer = optim.SGD([{'params': [weights_1]},{'params': [weights_2]}], lr=lr_init)
lambda1 = lambda epoch: 0.1 ** (epoch // 20)
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
#在epoch循环中
scheduler.step()
学习率初始化:
设置较小的学习率:0.01,0.001,0.0001