这就是神经网络 15:深度学习-人脸检测-MTCNN
概述
MTCNN是一个基于级联卷积神经网络的人脸检测和人脸对齐算法。其英文题目《Joint Face Detection and Alignment using
Multi-task Cascaded Convolutional Networks》。
本文原始的创意来自《A Convolutional Neural Network Cascade for Face Detection》,有人称它为 Cascade CNN。作者的修改体现在以下三点:
-
MTCNN的级联思想和主要网络结构都源自Cascade CNN,但是作者增加了网络深度、减少每层的滤波器数量、把5x5改为3x3卷积,在减少计算量的同时增加了网络的表征提取能力。
-
除了上述网络结构修改,作者同时加入了人脸关键点的预测。作者认为通过多任务联合训练,对人脸检测是有好处的(我认为这相当于加入了更多的先验知识,告诉网络人有这几个部位)。作者在论文里也通过实验证实了自己的猜想。
-
online hard sample mining。怎么翻译呢,难道是"在线高难度样本挖掘"?意思就是每个batch只利用分类loss前70%的样本进行梯度回传。因为那些容易的样本对训练的贡献本来就不大,就忽略掉了。这可以加速网络收敛,提高最终性能。作者在论文里也有对比测试证明自己。
网络结构

MTCNN由3个网络级联而成,每个图片依次经过三个网络,最终输出结果。前面网络输出的结果作为后面网络的输入。
stage1: P-Net
全称Proposal Network,只有四层卷积,运行很快,用于快速生成大量候选区域(candidates)。NMS过滤输出结果。
P-Net是一个全卷积网络,所以可以用在任意图片大小(大于12x12就行)上,这也是后面推理的时候需要用到的特点。
stage2: R-Net
全称Refine Network,用于对上一步生成的候选区域进行调整,同时拒绝大量假阳性候选区域。对这些候选根据IOU值进行非极大值抑制(NMS)筛选掉一大部分候选。注意这个网络是有全连接的,不是一个全卷积网络,只能输入24x24的图片。
stage3:O-Net
全称Output Network,作用和stage2类似,最终输出人脸框的回归值和关键点的位置。NMS筛选最后输出的结果。
上图可以看到,3个阶段输出内容类似,都包括的三部分:人脸二分类概率、bbox偏移回归值和人脸关键点定位值。其中前两个阶段的关键点定位置在推理的时候并不需要,仅仅是为了训练时提高检测的性能。最后一个阶段的关键点定位值在推理时是需要的。
推理过程
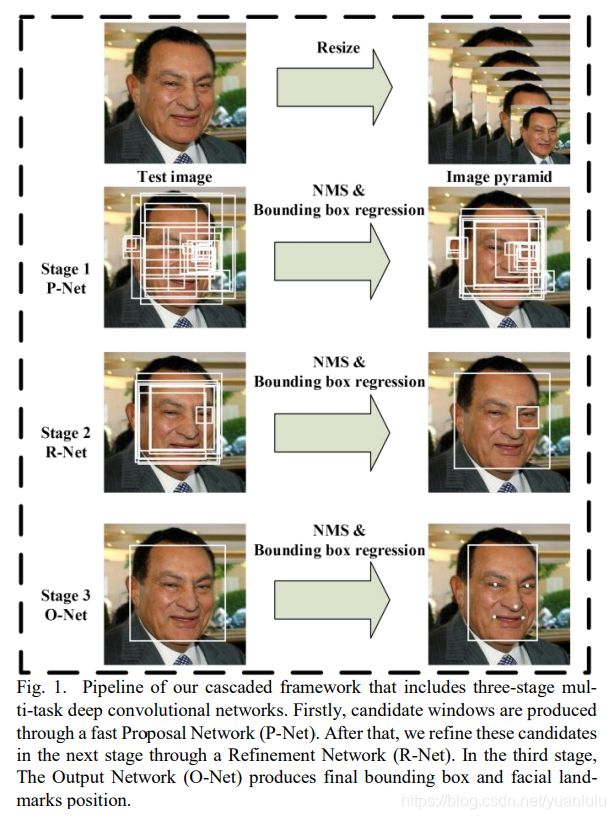
上面这张图大家应该非常熟悉,几乎成了介绍MTCNN文章的一种标配。下面分解介绍。
准备:生成图片金字塔
将输入的原始图片,按照指定的resize_factor(基本在0.70-0.80之间会比较合适,设的比较大,容易延长推理时间,小了容易漏掉一些中小型人脸)。这样子你会得到原图、原图xresize_factor、原图xresize_factor^2 以及原图xresize_factor^n(注,最后一个的图片大小会大等于12)这些不同大小的图片。这些图片要一张张输入到P-Net网络中。
P-Net
首先,P-Net是全卷积网络,所以推理的时候可能输入任意大小的图片。其次,P-Net只有一个最大池化,其它三次卷积都是padding为0的,输出特征图每个元素的感知野是12x12。P-Net的输出特征长宽大约是输入图片的一半。
P-Net最后输出的特征图是16通道的,每个1x1x16,其中两个用于人脸二分类,4个用于bbox偏移回归,10个用于人脸关键点的定位。
P-Net输出的bbox回归,是相对于感知野范围的偏移量(相对感知野尺寸做了归一化)。所以MTCNN很神奇的利用感知野实现了anchor框的效果。
利用偏移量和感知野位置计算片出的位置就是P-Net预测的人脸位置,IOU-NMS之后,用最大边长去原图上截取相应的正方形(避免形变和保留更多细节),resize到24x24,作为下一阶段的输入。
R-Net
根据上一阶段预测的大量人脸的位置,去原图上截取,resize到24x24,作为本阶段的输入。上一阶段的输入是图片金字塔里的整张图片,这里的输入只能是24x24的截图。
这个阶段输出的bbox偏移量是相对于输入的截图来说的,根据截图在原图的坐标和预测的偏移量,可以计算得到本阶段预测的人脸bbox在原图的位置和大小。
R-Net针对每个小图片最后输出的是1x1x16的特征,其含义和之前一样。再次重复P-net所述的IOU NMS干掉大部分的候选,根据bbox的坐标再去原图截出图片输入到Onet。
O-Net
整体流程P-Net类似。输出结果经过分类筛选、框调整后的NMS筛选,最终得到人脸bbox及关键点位置。
训练
数据
这里摘抄《人脸检测–MTCNN从头到尾的详解》里的一段文字。
每个网络的输入我们会有4种训练数据输入:
- Positive face数据:图片左上右下坐标和label的IOU>0.65的图片
- part face数据:图片左上右下坐标和label的0.65>IOU>0.4的图片
- negative face 数据:图片左上右下坐标和lable的IOU<0.3的图片
- landmark face数据:图片带有landmark label的图片
使用方法:
- 网络做人脸分类的时候,使用postives 和negatives的图片来做,为什么只用这两种?因为这两种数据分得开,中间隔着个part face+0.1 IOU的距离,容易使模型收敛;
- 网络做人脸bbox的偏移量回归的时候,使用positives 和parts的数据,为什么不用neg数据?论文里面没提,个人认为是因为neg的数据几乎没有人脸,用这个数据来训练人脸框offset的回归挺不靠谱的,相反pos和part的数据里面人脸部分比较大,用来做回归,网络还能够看到鼻子、眼睛、耳朵啥的来进行乖乖的回归;
- 网络做人脸landmark 回归的时候,就只使用landmark face数据了。
(如何做到不同的数据用于不同的训练呢,下面会讲到loss计算公式中有一个系数开关)
Pnet使用的是12*12大小的图片,这个图片怎么得到的呢?嗯,很简单,去WIDER和CelebA随机截取,这个时候大家会问,随机截取怎么截取?就是字面上的意思,不过有点点技巧。首先,如果真的随机截取的话,如果图片里面人头只有一个,很多都会截取到非pos甚至非part的图片,所以为了得到足够多的pos、part数据,真正的随机截取是基于图片实际label进行上下左右微调来截取,进而保障pos、part数据的足够。
Pnet在前述数据的情况下进行训练并完成训练,我们将所有的WIDER数据和CelebA数据输入到Pnet,会得到很多的候选,去原图截图,计算截图和label的IOU,按照上述四种数据的分类标准分别区分开,同时label标注方法和上述标注方法一致。我们经过Pnet就可以得到Rnet所需的24*24大小的训练数据了。
最后训练O-Net,其输入来自R-Net输出。可以看到三个子网络依次分三个阶段训练完毕。
损失函数
人脸分类
使用交叉熵:
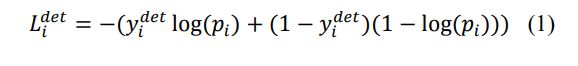
边界框回归
通过欧氏距离计算回归损失。带尖的y为通过网络预测得到,不带尖的y为实际的真实的背景坐标。y为一个(左上角x,左上角y,长,宽)组成的四元组。

关键点定位
同样也是欧式距离。

LOSS开关

- alpha是表示不同网络结构det、box、landmark的损失函数的权重不一,由于Onet要输出landmark,所以Onet的landmark损失权重会比前面两个网络要大。

- Beta的用于控制不同类型的数据是否参与LOSS计算,请参考上一小节‘数据’
- Hard Sample mining:只对分类损失进行hard sample mining,具体意思是在一个batch里面的图片数据,只取分类损失(det loss)的前70%的训练数据(这个比例是提前设好的)backprop回去。其余两类损失不做这样的hard sample mining
训练和推理的异同
训练的时候,P-Net输入的是12x12的随机裁剪图片,推理的时候输入的是图片金字塔的整张图片(每个图片被resize成不同的大小输入多次)。
而后面两个阶段输入是一致的。
测试效果
在当时是SOTA级的效果。

论文
论文地址:Joint Face Detection and Alignment using
Multi-task Cascaded Convolutional Networks
作者网站:https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html
官方matlab源码:https://github.com/kpzhang93/MTCNN_face_detection_alignment
代码
MTCNN部署全平台实现,包括C++、python、ncnn和tensorflow,还有加速版本和opencv直接加载版本,是所有版本中的集大成者:https://github.com/imistyrain/MTCNN
快速版本实现:https://github.com/szad670401/Fast-MTCNN
github: AITTSMD/MTCNN-Tensorflow
github: davidsandberg/facenet
MTCNN训练代码合集:https://blog.csdn.net/minstyrain/article/details/82292074
参考资料
人脸检测–MTCNN从头到尾的详解
MTCNN(Multi-task convolutional neural networks)人脸对齐
mtcnn论文翻译
基于mtcnn和facenet的实时人脸检测与识别系统开发
MTCNN优化和另类用法
MTCNN算法提速应用(ARM测试结果评估)
SPL2016_MTCNN