用PyTorch构建基于卷积神经网络的手写数字识别模型
本文参加新星计划人工智能(Pytorch)赛道:https://bbs.csdn.net/topics/613989052
目录
一、MINST数据集介绍与分析
二、卷积神经网络
三、基于卷积神经网络的手写数字识别
一、MINST数据集介绍与分析
MINST数据库是机器学习领域非常经典的一个数据集,其由Yann提供的手写数字数据集构成,包含了0-9共10类手写数字图片,每张图片都做了尺寸归一化,都是28x28大小的灰度图。每张图片中像素值大小在0-255之间,其中0是黑色背景,255是白色前景。
编写程序导入数据集并展示如下所示:
from sklearn.datasets import fetch_mldata
from matplotlib import pyplot as plt
mnist = fetch_mldata('MNIST original', data_home='./dataset')
X, y = mnist["data"], mnist["target"]
print("MNIST数据集大小为:{}".format(X.shape))
for i in range(25):
digit = X[i * 2500]
# 将图片重新resize到28*28大小
digit_image = digit.reshape(28, 28)
plt.subplot(5, 5, i + 1)
# 隐藏坐标轴
plt.axis('off')
# 按灰度图绘制图片
plt.imshow(digit_image, cmap='gray')
plt.show()在控制台可以看到的输出为:MNIST数据集大小为:(70000, 784)。一共有70000张数字,且784=28*28,即每一张手写数字图片存成了一维的数据格式。
可视化前25张图片以及中间的数据可得如图所示:

手写数字的识别是一个多分类任务,一张手写数字图片的特征提取任务也需要我们自己实现,将28*28的图片直接序列化为784维的向量也是一种特征提取的方式,但经过一些处理,可以获得更反映出图片内容的信息,例如使用在原图中使用sift、surf等算子后的特征,或者使用最新的一些深度学习预训练模型来提取特征。MNIST数据集样例数目较多且为图片信息,近些年随着深度学习技术的发展,对于大多数视觉任务,通过构造并训练卷积神经网络可以获得更高的准确率,本项目将基于PyTorch框架完成网络的训练以及识别的任务。
二、卷积神经网络
卷积神经网络(CNN)是深度神经网络中的一种,其受生物视觉认知机制启发而来,神经元之间使用类似动物视觉皮层组织的链接方式,大多数情况下用于处理计算机视觉相关的任务,例如分类、分割、检测等。与传统方法相比较,卷积神经网络不需要利用先验知识进行特征设计,预处理步骤较少,在大多数视觉相关任务上获得了不错的效果。卷积神经网络最先出现于20世纪80年代到90年代,LeCun提出了LeNet用于解决手写数字识别的问题,随着深度学习理论的不断完善,计算机硬件水平的提高,卷积神经网络也随之快速发展。
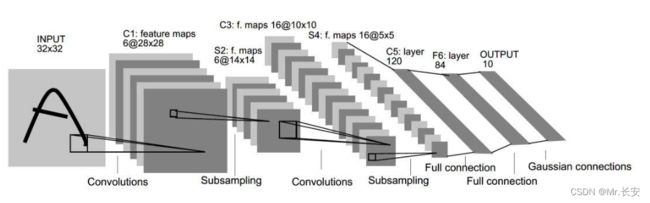
卷积神经网络通常由一个输入层(Input Layer)和一个输出层(Output Layer)以及多个隐藏层组成。隐藏包括卷积层(Convolutional Layer)、激活层(Activation Layer)、池化层(Pooling Layer)以及全连接层(Fully-connected Layer)等。如上图所示为一个LeNet神经网络的结构,目前大多数研究者针对于不同任务对层或网络结构进行设置,从而获得更优的效果。
卷积神经网络的输入层可以对多维数据进行处理,常见的二维卷积神经网络可以接受二维或三维数据作为输入,对于图片类任务,一张RGB图片作为输入的大小可写为C×H×W,C为通道数,H为长,W为宽。对于视频识别类任务,一段视频作为输入的大小可写为T×C×H×W,T为视频帧的数目,对于三维重建任务,一个三维体素模型,其作为输入的大小可写为1×H×L×W,H、L、W分别为模型的高、长、宽。与其他神经网络算法相似,在训练时会使用梯度下降法对参数进行更新,因此所有的输入都需要进行在通道或时间维度归一化或标准化的预处理过程。归一化是通过计算极值将所有样本的特征值映射到之间。而标准化是通过计算均值、方差将数据分布转化为标准正态分布,本项目中所有的数据预处理均使用标准化的方法。

卷积层是卷积神经网络所特有的一种子结构,一个卷积层包含多个卷积核,卷积核在输入数据上进行卷积计算从而提取得到特征。在前向传播中,如图11-13所示,中间为一个3×3的卷积核,卷积核在输入上进行滑动,每次滑动都计算逐像素相乘再相加的结果,作为输出特征上某一点的值,一个卷积操作一般由四个超参数组成,卷积核大小F(kernel size),步长S(stride),填充P(padding),以及卷积核数目C(number ofnels),具体来说,假设输入的特征大小为N×W×H,则输出特征的维度W'、H'以及N'为:

激活层有Sigmoid、ReLU、Tanh等常用的激活函数可供使用, 如下图所示:

池化层一般包括两种,一种是平均池化层(Average Pooling)、另一种是最大值池化(Max Pooling),池化层可以起到保留主要特征,减少下一层的参数量和计算量的作用,从而防止过拟合风险。
全连接层一般用于分类网络最后面,起到类似于“分类器”的作用,将数据的特征映射到样本标记特征,相比卷积层的某一位置的输出仅与上一层中相邻位置有关,全连接层中每一个神经元都会与前一层的所有神经元有关,因此全连接层的层数量也是很大的。
归一化层包括了BatchNorm, LayerNorm, InstanceNorm, GroupNorm等方法,本项目仅使用了BatchNorm。BatchNorm在batch的维度上进行归一化,使得深度网络中间卷积的结果也满足正态分布,整个训练过程更快,网络更容易收敛。
前面介绍的这些部件组合起来就能构成一个深度学习的分类器,基于大量的训练集从而在某些任务上可以获得与人类相当准确性,科学家们也在不断实践如何去构建一个深度学习的网络,如何设计并搭配这些部件,从而获得更优异的分类性能,下面是较为经典的一些网络结构,甚至其中有一些依旧活跃在科研的一线。
LeNet卷积神经网络由LeCun在1998年提出,这个网络仅由两个卷积层、两个池化层以及两个全连接层组成,在当时用以解决手写数字识别的任务,也是早期最具有代表性的卷积神经网络之一,同时也奠定了卷积神经网络的基础架构,包含了卷积层、池化层、全连接层。
2012年,Alex提出的Alexnet在ImageNet比赛上取得了冠军,其正确率远超第二名。AlexNet成功使用Relu作为激活函数,并验证了在较深的网络上,Relu效果好于Sigmoid,同时成功实现在GPU上加速卷积神经网络的训练过程。另外Alex在训练中使用了dropout和数据扩增以防止过拟合的发生,这些处理成为后续许多工作的基本流程。为从而开启了深度学习在计算机视觉领域的新一轮爆发。
GoogleNet,2014年ImageNet比赛的冠军模型,证明了使用更多的卷积层可以得到更好的结果。其巧妙地在不同的深度增加了两个损失函数来保证梯度在反向传播时不会消失。
VGGNet是牛津大学计算机视觉组和Google DeepMind公司的研究员一起研发的深度卷积神经网络。他探索了卷积神经网络的性能与深度的关系,通过不断叠加3×3的卷积核与2×2的最大池化层,从而成功构建了一个16到19层深的卷积神经网络,并大幅下降了错误率。虽然VGGNet简化了卷积神经网络的结构,但训练中的需要更新的参数量依旧非常巨大。
虽然卷积深度的不断上升会带来效果的提升,但当深度超过一定数目后又会引入新的问题,即梯度消失的现象出现的越来越明显,反而导致无法提升网络的效果。ResNet提出了残差模块来解决这一问题,允许原始信息可以直接输入到后面的层之中。传统的卷积层或全连接层在进行信息传递时,每一层只能接受其上一层的信息,导致可能会存在信息丢失的问题,ResNet在一定程度上缓解了该问题,通过残差的方式,提供了让信息从输入传到输出的途径,保证了信息的完整性。
使用深度模型时需要注意的一点在于由于模型参数较多,因此要求数据集也不能太小,否则会出现过拟合的现象,还有一种使用深度模型的方法是,使用在ImageNet上预训练好的模型,固定除了全连接层外所有的参数,只在当前数据集下训练全连接层参数,这种方式可以大大减小训练的参数量,使深度模型在较小的数据集上也能得到应用。
三、基于卷积神经网络的手写数字识别
前面已经介绍了几种经典的卷积神经网络模型,MNIST数据集中图片的尺寸仅为28*28,相比ImageNet中224*224的图片尺寸显得十分小,因此在模型的选取上,不能选择太过于复杂,参数量过多的模型,否则会带来过拟合的风险,本项目自定义了一个仅包含2个卷积层的卷积神经网络以及经过一些调整的AlexNet。首先是定义网络的类,该类在mnist_models.py内,继承了torch.nn.Module类,并需要重新实现forword函数,即一张图作为输入,如何通过卷积层得到最后的输出。
class ConvNet(torch.nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 10, 5, 1, 1),
torch.nn.MaxPool2d(2),
torch.nn.ReLU(),
torch.nn.BatchNorm2d(10)
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(10, 20, 5, 1, 1),
torch.nn.MaxPool2d(2),
torch.nn.ReLU(),
torch.nn.BatchNorm2d(20)
)
self.fc1 = torch.nn.Sequential(
torch.nn.Linear(500, 60),
torch.nn.Dropout(0.5),
torch.nn.ReLU()
)
self.fc2 = torch.nn.Sequential(
torch.nn.Linear(60, 20),
torch.nn.Dropout(0.5),
torch.nn.ReLU()
)
self.fc3 = torch.nn.Linear(20, 10)如上面的代码块所示,在构造函数中,定义了网络的结构,主要包含了两个卷积层以及三个全连接层的参数设置。
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(-1, 500)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x接下来在forward函数中x为该网络的输入,经过前面定义的网络结构按顺序进行计算后,返回结果。同样,可以定义AlexNet的网络结构以及forword函数如下所示:
class AlexNet(torch.nn.Module):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
self.features = torch.nn.Sequential(
torch.nn.Conv2d(1, 64, kernel_size=5, stride=1, padding=2),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=3, stride=1),
torch.nn.Conv2d(64, 192, kernel_size=3, padding=2),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=3, stride=2),
torch.nn.Conv2d(192, 384, kernel_size=3, padding=1),
torch.nn.ReLU(inplace=True),
torch.nn.Conv2d(384, 256, kernel_size=3, padding=1),
torch.nn.ReLU(inplace=True),
torch.nn.Conv2d(256, 256, kernel_size=3, padding=1),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = torch.nn.Sequential(
torch.nn.Dropout(),
torch.nn.Linear(256 * 6 * 6, 4096),
torch.nn.ReLU(inplace=True),
torch.nn.Dropout(),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x定义完网络结构后,新建一个新的.py脚本完成网络训练和预测的过程。一般来说一个Pytorch项目主要包含几大模块,数据集加载、模型定义及加载、损失函数以及优化方法设置,训练模型,打印训练中间结果,测试模型。对于MNIST这样小型的项目,可以将除了数据集加载和模型定义外所有的代码使用一个函数实现。首先是加载相应的包以及设置超参数,EPOCHS指在数据集上训练多少个轮次,而SAVE_PATH指中间以及最终模型保存的路径。
import torch
from torchvision.datasets import mnist
from mnist_models import AlexNet, ConvNet
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from torch.autograd import Variable
# 设置模型超参数
EPOCHS = 50
SAVE_PATH = './models'核心训练函数以模型、训练集、测试集作为输入。首先定义损失函数为交叉熵函数以及优化方法选取了SGD,初始学习率为1E-2。
def train_net(net, train_data, test_data):
losses = []
acces = []
# 测试集上Loss变化记录
eval_losses = []
eval_acces = []
# 损失函数设置为交叉熵函数
criterion = torch.nn.CrossEntropyLoss()
# 优化方法选用SGD,初始学习率为1e-2
optimizer = torch.optim.SGD(net.parameters(), 1e-2)接下来,一共有50个训练轮次,使用for循环实现,在训练过程中记录在训练集以及测试集上Loss以及Acc的变化情况。在训练过程中,net.train()是指将网络前向传播的过程设为训练状态,在类似Droupout以及归一化层中,对于训练和测试的处理过程是不一样的,因此每次进行训练或测试时,最好显式的进行设置,防止出现一些意料之外的错误。
for e in range(EPOCHS):
train_loss = 0
train_acc = 0
# 将网络设置为训练模型
net.train()
for image, label in train_data:
image = Variable(image)
label = Variable(label)
# 前向传播
out = net(image)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.data
# 计算分类的准确率
_, pred = out.max(1)
num_correct = (np.array(pred, dtype=np.int) == np.array(label, dtype=np.int)).sum()
acc = num_correct / image.shape[0]
train_acc += acc
losses.append(train_loss / len(train_data))
acces.append(train_acc / len(train_data))
# 在测试集上检验效果
eval_loss = 0
eval_acc = 0
net.eval() # 将模型改为预测模式
for image, label in test_data:
image = Variable(image)
label = Variable(label)
out = net(image)
loss = criterion(out, label)
# 记录误差
eval_loss += loss.data
# 记录准确率
_, pred = out.max(1)
num_correct = (np.array(pred, dtype=np.int) == np.array(label, dtype=np.int)).sum()
acc = num_correct / image.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_data))
eval_acces.append(eval_acc / len(test_data))
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'
.format(e, train_loss / len(train_data), train_acc / len(train_data),
eval_loss / len(test_data), eval_acc / len(test_data)))
torch.save(net.state_dict(), SAVE_PATH + '/Alex_model_epoch' + str(e) + '.pkl')
return eval_losses, eval_acces在训练集上训练完一个轮次之后,在测试集上进行验证,并记录结果,保存模型参数,并打印数据,方便后续进行调参。训练完成后返回测试集上Acc和Loss的变化情况。
最后完成Loss和Acc变化曲线的绘制函数以及主函数main如下所示:
if __name__ == "__main__":
train_set = mnist.MNIST('./data', train=True, download=True, transform=transforms.ToTensor())
test_set = mnist.MNIST('./data', train=False, download=True, transform=transforms.ToTensor())
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
test_data = DataLoader(test_set, batch_size=64, shuffle=False)
a, a_label = next(iter(train_data))
net = AlexNet()
eval_losses, eval_acces = train_net(net, train_data, test_data)
draw_result(eval_losses, eval_acces)
def draw_result(eval_losses, eval_acces):
x = range(1, EPOCHS + 1)
fig, left_axis = plt.subplots()
p1, = left_axis.plot(x, eval_losses, 'ro-')
right_axis = left_axis.twinx()
p2, = right_axis.plot(x, eval_acces, 'bo-')
plt.xticks(x, rotation=0)
# 设置左坐标轴以及右坐标轴的范围、精度
left_axis.set_ylim(0, 0.5)
left_axis.set_yticks(np.arange(0, 0.5, 0.1))
right_axis.set_ylim(0.9, 1.01)
right_axis.set_yticks(np.arange(0.9, 1.01, 0.02))
# 设置坐标及标题的大小、颜色
left_axis.set_xlabel('Labels')
left_axis.set_ylabel('Loss', color='r')
left_axis.tick_params(axis='y', colors='r')
right_axis.set_ylabel('Accuracy', color='b')
right_axis.tick_params(axis='y', colors='b')
plt.show()运行脚本,等待控制台逐渐输出训练过程的中间结果如下图所示,随着训练的进行,可以发现在测试集上分类的正确率不断上升且Loss稳步下降,到第20轮左右后,正确率基本不再变化,网络收敛。
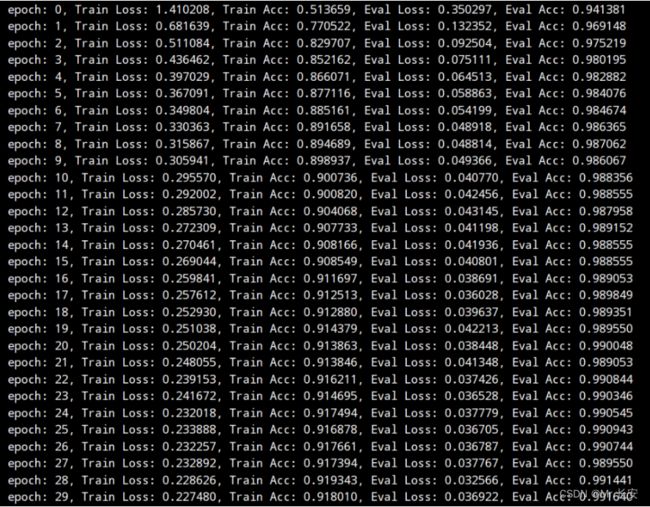
【小技巧】在进行深度学习方法进行训练时,一定要将中间结果打印出来,因为模型训练往往会比较慢,如果中间感到哪里不对时可以及时停止,节省时间,另外,训练的中间模型一定要保存下来!
等待程序运行结束,可以得到绘制结果如下图所示,最终分类正确率可达99.1%左右。
