flink实时数仓
目录
- 电商常识
- 实时数仓架构
- 对所用到的表进行解析
- 完成数据源和数据采集
- 完成ODS层
- 完成DIM层
-
- 分析表结构
- 使用代码导入数据并checkpoint
-
- 将相同部分的代码进行封装
- 完成DWD层
- 完成ADS层
电商常识
由于这个项目是基于电商数据所完成的项目,所以这里对电商的一些常识做一个简单普及
SKU和SPU
SKU:一台银色、128G内存的、支持联通网络的iPhoneX
SPU:iPhoneX
Tm_id:品牌Id苹果,包括IPHONE,耳机,mac等
订单表跟订单详情表区别?
订单表的订单状态会变化,订单详情表不会,因为没有订单状态。
订单表记录user_id,订单id订单编号,订单的总金额order_status,支付方式,订单状态等。
订单详情表记录user_id,商品sku_id ,具体的商品信息(商品名称sku_name,价格order_price,数量sku_num)
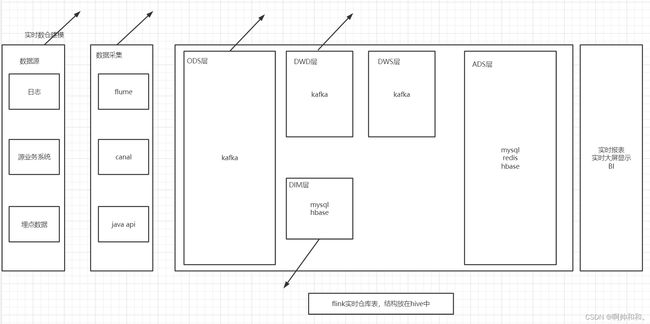
实时数仓架构
整体的架构和离线数仓的架构并没有太大的差别,整体的架构相比较离线的项目,光看图也能看出来差不多,只是中间的转换是通过Flink来操作的,更多的是Flinksal,剩余的内容(表),更多的是存在于Kafka中
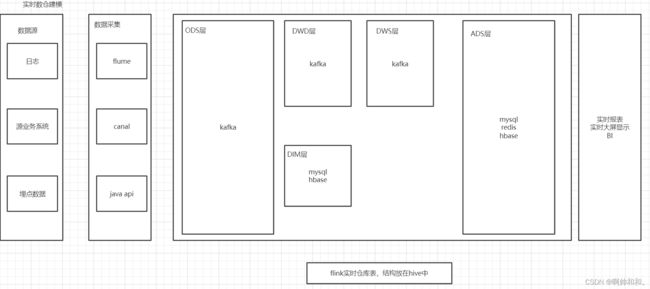
对所用到的表进行解析
表中涉及到敏感字段的id都已经进行了脱敏
1、一级分类表
DROP TABLE IF EXISTS `base_category1`;
CREATE TABLE `base_category1` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`name` varchar(10) NOT NULL COMMENT '分类名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8 COMMENT='一级分类表';

整体的数据类型是一个大的分类
2、二级分类表
DROP TABLE IF EXISTS `base_category2`;
CREATE TABLE `base_category2` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`name` varchar(200) NOT NULL COMMENT '二级分类名称',
`category1_id` bigint(20) DEFAULT NULL COMMENT '一级分类编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=126 DEFAULT CHARSET=utf8 COMMENT='二级分类表';

所对应的就是一级分类表下面的细分了,第三个字段表示的是一级分类表的类别
3、三级分类表
DROP TABLE IF EXISTS `base_category3`;
CREATE TABLE `base_category3` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`name` varchar(200) NOT NULL COMMENT '三级分类名称',
`category2_id` bigint(20) DEFAULT NULL COMMENT '二级分类编号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1150 DEFAULT CHARSET=utf8 COMMENT='三级分类表';

三级分类表更加的具体,第三个字段对应的是二级分类表的字段id
4、省份表
DROP TABLE IF EXISTS `base_province`;
CREATE TABLE `base_province` (
`id` int(20) DEFAULT NULL COMMENT 'id',
`name` varchar(20) DEFAULT NULL COMMENT '省名称',
`region_id` int(20) DEFAULT NULL COMMENT '大区id',
`area_code` varchar(20) DEFAULT NULL COMMENT '行政区位码'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

对应的是大区的省份和相应的id
5、地区表
DROP TABLE IF EXISTS `base_region`;
CREATE TABLE `base_region` (
`id` int(20) NOT NULL COMMENT '大区id',
`region_name` varchar(20) DEFAULT NULL COMMENT '大区名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

地区编号和地区名称
6、品牌表
DROP TABLE IF EXISTS `base_trademark`;
CREATE TABLE `base_trademark` (
`tm_id` varchar(20) DEFAULT NULL COMMENT '品牌id',
`tm_name` varchar(20) DEFAULT NULL COMMENT '品牌名称'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

一些id所对应的品牌
7、时间纬度表
DROP TABLE IF EXISTS `date_info`;
CREATE TABLE `date_info` (
`date_id` int(11) NOT NULL,
`week_id` int(11) DEFAULT NULL,
`week_day` int(11) DEFAULT NULL,
`day` int(11) DEFAULT NULL,
`month` int(11) DEFAULT NULL,
`quarter` int(11) DEFAULT NULL,
`year` int(11) DEFAULT NULL,
`is_workday` int(11) DEFAULT NULL,
`holiday_id` int(11) DEFAULT NULL,
PRIMARY KEY (`date_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

8、节假日期表
DROP TABLE IF EXISTS `holiday_info`;
CREATE TABLE `holiday_info` (
`holiday_id` int(11) NOT NULL,
`holiday_name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`holiday_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

一些对应的节假日
9、节假日的一个时间范围
DROP TABLE IF EXISTS `holiday_year`;
CREATE TABLE `holiday_year` (
`year_id` int(11) DEFAULT NULL,
`holiday_id` int(11) DEFAULT NULL,
`start_date_id` int(11) DEFAULT NULL,
`end_date_id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

10、订单明细表
DROP TABLE IF EXISTS `order_detail`;
CREATE TABLE `order_detail` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`order_id` bigint(20) DEFAULT NULL COMMENT '订单编号',
`sku_id` bigint(20) DEFAULT NULL COMMENT 'sku_id',
`sku_name` varchar(200) DEFAULT NULL COMMENT 'sku名称(冗余)',
`img_url` varchar(200) DEFAULT NULL COMMENT '图片名称(冗余)',
`order_price` decimal(10,2) DEFAULT NULL COMMENT '购买价格(下单时sku价格)',
`sku_num` varchar(200) DEFAULT NULL COMMENT '购买个数',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1054 DEFAULT CHARSET=utf8 COMMENT='订单明细表';

订单明细表中包含了订单的许多属性,不会做一个改变
11、订单表
DROP TABLE IF EXISTS `order_info`;
CREATE TABLE `order_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`consignee` varchar(100) DEFAULT NULL COMMENT '收货人',
`consignee_tel` varchar(20) DEFAULT NULL COMMENT '收件人电话',
`total_amount` decimal(10,2) DEFAULT NULL COMMENT '总金额',
`order_status` varchar(20) DEFAULT NULL COMMENT '订单状态',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户id',
`payment_way` varchar(20) DEFAULT NULL COMMENT '付款方式',
`delivery_address` varchar(1000) DEFAULT NULL COMMENT '送货地址',
`order_comment` varchar(200) DEFAULT NULL COMMENT '订单备注',
`out_trade_no` varchar(50) DEFAULT NULL COMMENT '订单交易编号(第三方支付用)',
`trade_body` varchar(200) DEFAULT NULL COMMENT '订单描述(第三方支付用)',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`operate_time` datetime DEFAULT NULL COMMENT '操作时间',
`expire_time` datetime DEFAULT NULL COMMENT '失效时间',
`tracking_no` varchar(100) DEFAULT NULL COMMENT '物流单编号',
`parent_order_id` bigint(20) DEFAULT NULL COMMENT '父订单编号',
`img_url` varchar(200) DEFAULT NULL COMMENT '图片路径',
`province_id` int(20) DEFAULT NULL COMMENT '地区',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=371 DEFAULT CHARSET=utf8 COMMENT='订单表 订单表';

12、订单状态表
DROP TABLE IF EXISTS `order_status_log`;
CREATE TABLE `order_status_log` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`order_id` int(11) DEFAULT NULL,
`order_status` int(11) DEFAULT NULL,
`operate_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=43 DEFAULT CHARSET=utf8;

13、支付流水表
DROP TABLE IF EXISTS `payment_info`;
CREATE TABLE `payment_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`out_trade_no` varchar(20) DEFAULT NULL COMMENT '对外业务编号',
`order_id` varchar(20) DEFAULT NULL COMMENT '订单编号',
`user_id` varchar(20) DEFAULT NULL COMMENT '用户编号',
`alipay_trade_no` varchar(20) DEFAULT NULL COMMENT '支付宝交易流水编号',
`total_amount` decimal(16,2) DEFAULT NULL COMMENT '支付金额',
`subject` varchar(20) DEFAULT NULL COMMENT '交易内容',
`payment_type` varchar(20) DEFAULT NULL COMMENT '支付方式',
`payment_time` varchar(20) DEFAULT NULL COMMENT '支付时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8 COMMENT='支付流水表';
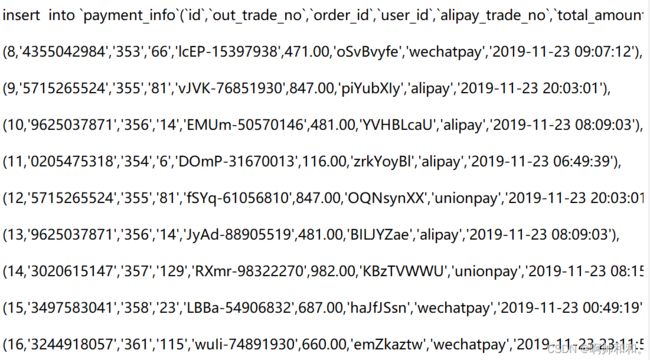
14、库存单元表
DROP TABLE IF EXISTS `sku_info`;
CREATE TABLE `sku_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'skuid(itemID)',
`spu_id` bigint(20) DEFAULT NULL COMMENT 'spuid',
`price` decimal(10,0) DEFAULT NULL COMMENT '价格',
`sku_name` varchar(200) DEFAULT NULL COMMENT 'sku名称',
`sku_desc` varchar(2000) DEFAULT NULL COMMENT '商品规格描述',
`weight` decimal(10,2) DEFAULT NULL COMMENT '重量',
`tm_id` bigint(20) DEFAULT NULL COMMENT '品牌(冗余)',
`category3_id` bigint(20) DEFAULT NULL COMMENT '三级分类id(冗余)',
`sku_default_img` varchar(200) DEFAULT NULL COMMENT '默认显示图片(冗余)',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8 COMMENT='库存单元表';

库存货物的数据
15、用户表
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '编号',
`login_name` varchar(200) DEFAULT NULL COMMENT '用户名称',
`nick_name` varchar(200) DEFAULT NULL COMMENT '用户昵称',
`passwd` varchar(200) DEFAULT NULL COMMENT '用户密码',
`name` varchar(200) DEFAULT NULL COMMENT '用户姓名',
`phone_num` varchar(200) DEFAULT NULL COMMENT '手机号',
`email` varchar(200) DEFAULT NULL COMMENT '邮箱',
`head_img` varchar(200) DEFAULT NULL COMMENT '头像',
`user_level` varchar(200) DEFAULT NULL COMMENT '用户级别',
`birthday` date DEFAULT NULL COMMENT '用户生日',
`gender` varchar(1) DEFAULT NULL COMMENT '性别 M男,F女',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=153 DEFAULT CHARSET=utf8 COMMENT='用户表';

存储了用户数据
完成数据源和数据采集
到这里就已经完成了数据源和数据采集

完成ODS层
这是之前的操作:
开启hadoop
开启zookeeper
开启kafka
开启canal cd /usr/losql/soft/canal/bin ./startup.sh
开启flinksql客户端sql-client.sh embedded
切换catalog
use catalog myhive
在flink中创建数据库,每一层对应一个库,表是放在flink的库中的,读取的是kafka的数据源,kafka的数据源是监控MySQL的数据
到这里就已经完成了数据源和数据采集,以及ODS层,ODS层的数据库表是在flinksql中建的表,读取的数据是通过kafka接入的,所有的数据也都已经进入了表中,MySQL的原表中的数据进行了修改之后,这里的数据也会发生相应的变化;离线数仓的数据可以通过datax等采集工具导入,只能运行T+1时间的数据,实时数仓的数据是可以动态进行变化和改变的
到了这里,这些东西就已经都完成了
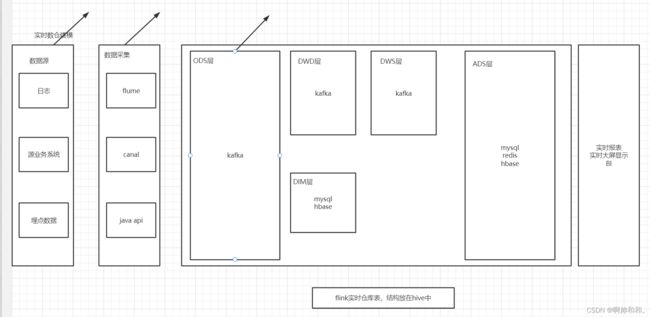
完成DIM层
这里我们DIM层的数据是放在MySQL中的,源业务系统的数据也是放在MySQL中,这也是不得已而为之,一般的情况不会将这两个放在同一种数据库中,我们这里也只是为了模拟一个结果出来

分析表结构
-- flink中创建地区维度表
CREATE TABLE gma_dim.dim_region_info(
id BIGINT,
name STRING,
area_code STRING,
region_name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/gma_dim?useUnicode=true&characterEncoding=utf-8',
'table-name' = 'dim_region_info',
'username' = 'root',
'password' ='123456'
);
-- mysql中创建接收表
CREATE TABLE `dim_region_info` (
`id` bigint(20) NOT NULL COMMENT 'id',
`name` varchar(20) DEFAULT NULL COMMENT '省名称',
`area_code` varchar(20) DEFAULT NULL COMMENT '行政区位码',
`region_name` varchar(20) DEFAULT NULL COMMENT '大区名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 创建mysql -cdc 表
--cdc 先做一次全量扫描,再增量监控binlog读取数据
-- mysql-cdc 只能用于读取数据
CREATE TABLE gma_dim.dim_region_info_cdc(
id BIGINT,
name STRING,
area_code STRING,
region_name STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'master',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'gma_dim',
'table-name' = 'dim_region_info'
);
1、首先要在flink中创建一个最终会写入MySQL的表
2、在MySQL中创建一个接收表(不过这里在MySQL中给了DIM一个新的库用来放数据)
3、后面最终我们要创建的是mysql-cdc这样的表,是为了最终我们能够增量的监控日志数据
4、将数据导入到MySQL中的gma_dim库中(这里导入数据,我们一开始是直接用SQL导入的,但是无法checkpoint,所以我们可以放入代码实现)
这里的任务是7*24小时一直在运行的,不存在资源调度这一回事
但是我们这里会有一个问题,就是任务是一直在运行的,难免会遇到中途失败的情况,但是我们又承担不起全部重新运行的代价,所以我们这里要做一个checkpoint,让任务即使失败了,也有地方可以重新运行,但是SQL中我们又没办法进行checkpoint,所以我们去代码中实现
到这里就已经完成了数据源和数据采集,以及ODS层,和DIM层

使用代码导入数据并checkpoint
package com.shujia.gma0
import org.apache.flink.configuration.Configuration
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.runtime.state.StateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.catalog.hive.HiveCatalog
object DimRegionInfo {
def main(args: Array[String]): Unit = {
//flinksql的环境
val bsEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* 开启checkpoint
*/
// 每 1000ms 开始一次 checkpoint
bsEnv.enableCheckpointing(10000)
// 高级选项:
// 设置模式为精确一次 (这是默认值)
bsEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 确认 checkpoints 之间的时间会进行 500 ms
bsEnv.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
bsEnv.getCheckpointConfig.setCheckpointTimeout(60000)
// 同一时间只允许一个 checkpoint 进行
bsEnv.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
val config: CheckpointConfig = bsEnv.getCheckpointConfig
//任务失败后自动保留最新的checkpoint文件
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//设置状态后端,保存状态的位置
val stateBackend: StateBackend = new RocksDBStateBackend("hdfs://master:9000/flink/checkpoint", true)
bsEnv.setStateBackend(stateBackend)
val bsSettings: EnvironmentSettings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() //使用blink的计划器
.inStreamingMode() //使用流处理模型
.build()
val configuration: Configuration = new Configuration()
configuration.setString("table.exec.sink.not-null-enforcer","drop")
configuration.setString("table.dynamic-table-options.enabled","true")
//创建table的环境
val bsTableEnv: StreamTableEnvironment = StreamTableEnvironment.create(bsEnv, bsSettings)
bsTableEnv.getConfig.addConfiguration(configuration)
/**
* 注册hive的元数据
*
* 可以直接读取hive中的表
*
*/
val name = "myhive"
val defaultDatabase = "gma_dim"
val hiveConfDir = "/usr/local/soft/hive-1.2.1/conf"
val hive = new HiveCatalog(name, defaultDatabase, hiveConfDir)
//注册catalog
bsTableEnv.registerCatalog("myhive", hive)
// 切换catalog
bsTableEnv.useCatalog("myhive")
bsTableEnv.executeSql(
"""
|insert into gma_dim.dim_region_info
|select a.id as id,name,area_code,region_name from
|gma_ods.ods_mysql_kafka_base_province /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as a
|join
|gma_ods.ods_mysql_kafka_base_region /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as b
|on a.region_id = b.id
""".stripMargin)
}
}
将相同部分的代码进行封装
1、将共有的代码放进一起
package com.shujia.common
import org.apache.flink.configuration.Configuration
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.runtime.state.StateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.catalog.hive.HiveCatalog
abstract class FlinkTool {
var bsEnv :StreamExecutionEnvironment = _
var bsTableEnv: StreamTableEnvironment = _
def main(args: Array[String]): Unit = {
//flinksql的环境
bsEnv= StreamExecutionEnvironment.getExecutionEnvironment
/**
* 开启checkpoint
*/
// 每 1000ms 开始一次 checkpoint
bsEnv.enableCheckpointing(10000)
// 高级选项:
// 设置模式为精确一次 (这是默认值)
bsEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 确认 checkpoints 之间的时间会进行 500 ms
bsEnv.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
bsEnv.getCheckpointConfig.setCheckpointTimeout(60000)
// 同一时间只允许一个 checkpoint 进行
bsEnv.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
val config: CheckpointConfig = bsEnv.getCheckpointConfig
//任务失败后自动保留最新的checkpoint文件
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//设置状态后端,保存状态的位置
val stateBackend: StateBackend = new RocksDBStateBackend("hdfs://master:9000/flink/checkpoint", true)
bsEnv.setStateBackend(stateBackend)
val bsSettings: EnvironmentSettings = EnvironmentSettings
.newInstance()
.useBlinkPlanner() //使用blink的计划器
.inStreamingMode() //使用流处理模型
.build()
val configuration: Configuration = new Configuration()
configuration.setString("table.exec.sink.not-null-enforcer","drop")
configuration.setString("table.dynamic-table-options.enabled","true")
//创建table的环境
bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings)
bsTableEnv.getConfig.addConfiguration(configuration)
/**
* 注册hive的元数据
*
* 可以直接读取hive中的表
*
*/
val name = "myhive"
val defaultDatabase = "gma_dim"
val hiveConfDir = "/usr/local/soft/hive-1.2.1/conf"
val hive = new HiveCatalog(name, defaultDatabase, hiveConfDir)
//注册catalog
bsTableEnv.registerCatalog("myhive", hive)
// 切换catalog
bsTableEnv.useCatalog("myhive")
this.run(args)
}
def run(args: Array[String])
}
写代码的时候,只要直接写SQL就行了
package com.shujia.gma0
import com.shujia.common.FlinkTool
object DimRegionInfo extends FlinkTool{
override def run(args: Array[String]): Unit = {
bsTableEnv.executeSql(
"""
|insert into gma_dim.dim_region_info
|select a.id as id,name,area_code,region_name from
|gma_ods.ods_mysql_kafka_base_province /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as a
|join
|gma_ods.ods_mysql_kafka_base_region /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ as b
|on a.region_id = b.id
""".stripMargin)
}
}
2、将代码省去,直接只在内容里写SQL,然后运行SQL文件
将代码写在一个地方,执行的SQL写在一个地方,发现可以正常的解析

将执行sql文件的代码直接拎出来
package com.shujia.common
import scala.io.Source
object DimRegionInfo extends FlinkTool{
override def run(args: Array[String]): Unit = {
if (args.length==0){
println("请指定sql文件路径")
return
}
val sqlFilePath = args(0)
val sql: String = Source.fromFile(sqlFilePath)
.getLines()
.toList
.mkString("\n")
println("*" * 50+"正在执行的sql"+"*" * 50)
println(sql)
println("*" * 100)
bsTableEnv.executeSql(sql)
}
}

这里再运行sql的时候
就可以直接只执行程序,将sql文件作为参数传进去,如果不传的话就会提示你sql文件路径要传(这是自己写的)
这里加上sql文件路径就可以稳定运行了

这里任务哪怕中间失败了,我们也可以根据ID号重新回到原来状态


这里再给上hdfs的路径就可了

3、再将一些常量写进配置文件,写一个Config方法,给出一个方法用来传递参数
package com.shujia.common
import java.io.InputStream
import java.util.Properties
object Config {
//读取配置文件
val inputStream: InputStream = this.getClass
.getClassLoader
.getResourceAsStream("config.properties")
private val properties = new Properties()
properties.load(inputStream)
def getString(key: String): String = {
properties.getProperty(key)
}
def getLong(key: String): Long = {
properties.getProperty(key).toLong
}
}

原本的函数里面就可以使用这样的方式传递参数了

将这些文件都完成之后,DIM层也就完成了
完成DWD层
这一层的数据仍然放进kafka中,最后我们的format依然是changelog格式,否则无法更改数据,到这里都是读kafka,写kafka
flinksql中创建表
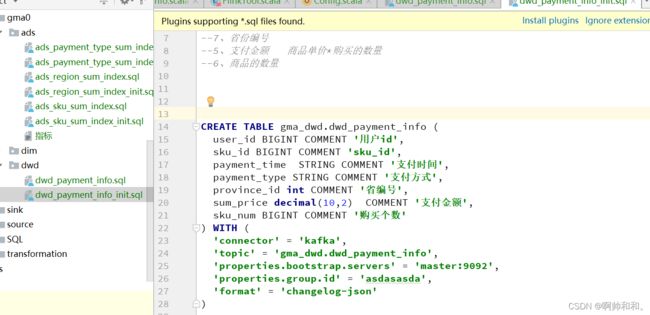
集群中提交任务插入数据

这里已经监控到了ods层的数据
到了这里DWD层也已经完成了
其实我们这里是一个实时的项目,所以在这里,DWS做不做的意义都不大,我们这里省略了DWS层,直接到ADS层
完成ADS层
ADS层的数据最终落地到MySQL,所以这里需要在flink的库中,以及MySQL的库中建立表,将数据最终落地到MySQL中

将数据导入到MySQL中

执行sql计算指标便可
![]()
过程中所有的数据都是在flink中可以监控到的
感谢阅读,我是啊帅和和,一位大数据专业大四学生,祝你快乐。