交叉编译详解
交叉编译详解
Note:为什么我要了解交叉编译并转载这篇博客呢?
原因是最近在使用vosk实现语音转写,但是项目是在
intel7 x86处理器,ubuntu18.04上开发的,而客户想要的是在飞腾2000+ arm64处理器,kylin系统上离线部署(真不省心),这就会导致项目在通过docker镜像移植到新系统、新CPU上存在问题,问题详见:vosk on riscv,官方给出的解决方案是在vosk.travis下构建docker镜像,即在intelx86 CPU上执行bash build-dockercross.sh实现交叉编译。(alphacep/dockcross-linux-armv7镜像一直拉取超时,最好只能放弃)
文章目录
- 交叉编译详解
-
- 第 1 章 交叉编译简介
-
- 1.1 什么是交叉编译
- 1.2 为什么会有交叉编译
- 1.3 为什么交叉编译比较困难
- 第 2 章 交叉编译链
-
- 2.1 什么是交叉编译链
- 2.2 交叉编译链的命名规则
- 第 3 章 包含的工具
-
- 3.1 Binutils
- 3.2 GCC
- 3.3 GLibc
- 3.4 GDB
- 第 4 章 如何得到交叉编译链
-
- 4.1 下载已经做好的交叉编译链
- 4.2 使用工具定制交叉编译链
- 4.3 从零开始构建交叉编译链
- 4.4 对比两种构建方式
- 参考资料
第 1 章 交叉编译简介
1.1 什么是交叉编译
对于没有做过嵌入式编程的人,可能不太理解交叉编译的概念,那么什么是交叉编译?它有什么作用?
在解释什么是交叉编译之前,先要明白什么是本地编译。
本地编译
本地编译可以理解为,在当前编译平台下,编译出来的程序只能放到当前平台下运行。平时我们常见的软件开发,都是属于本地编译:
比如,我们在 x86 平台上,编写程序并编译成可执行程序。这种方式下,我们使用 x86 平台上的工具,开发针对 x86 平台本身的可执行程序,这个编译过程称为本地编译。
交叉编译
交叉编译可以理解为,在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序:
比如,我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的,必须放到 ARM 平台上才能运行。
1.2 为什么会有交叉编译
之所以要有交叉编译,主要原因是:
Speed: 目标平台的运行速度往往比主机慢得多,许多专用的嵌入式硬件被设计为低成本和低功耗,没有太高的性能
Capability: 整个编译过程是非常消耗资源的,嵌入式系统往往没有足够的内存或磁盘空间
Availability: 即使目标平台资源很充足,可以本地编译,但是第一个在目标平台上运行的本地编译器总需要通过交叉编译获得
Flexibility: 一个完整的Linux编译环境需要很多支持包,交叉编译使我们不需要花时间将各种支持包移植到目标板上
1.3 为什么交叉编译比较困难
交叉编译的困难点在于两个方面:
不同的体系架构拥有不同的机器特性
Word size: 是64位还是32位系统
Endianness: 是大端还是小端系统
Alignment: 是否必修按照4字节对齐方式进行访问
Default signedness: 默认数据类型是有符号还是无符号
NOMMU: 是否支持MMU
交叉编译时的主机环境与目标环境不同
Configuration issues:
HOSTCC vs TARGETCC:
Toolchain Leaks:
Libraries:
Testing:
详细的对比可以参看这篇文章,已经写的很详细了,在这就不细说了:Introduction to cross-compiling for Linux
第 2 章 交叉编译链
2.1 什么是交叉编译链
明白了什么是交叉编译,那我们来看看什么是交叉编译链。
首先编译过程是按照不同的子功能,依照先后顺序组成的一个复杂的流程,如下图:
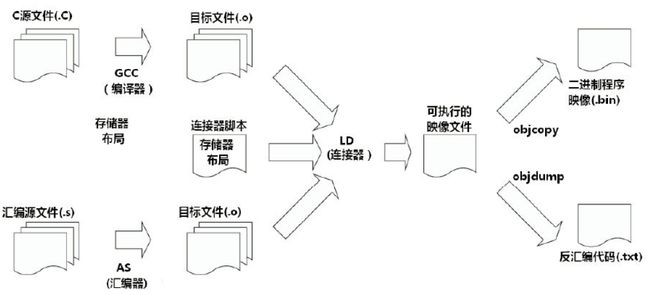
那么编译过程包括了预处理、编译、汇编、链接等功能(Note:源代码经过编译得到汇编代码(中间代码),汇编代码经过汇编得到机器代码)。既然有不同的子功能,那每个子功能都是一个单独的工具来实现,它们合在一起形成了一个完整的工具集。
同时编译过程又是一个有先后顺序的流程,它必然牵涉到工具的使用顺序,每个工具按照先后关系串联在一起,这就形成了一个链式结构。
因此,交叉编译链就是为了编译跨平台体系结构的程序代码而形成的由多个子工具构成的一套完整的工具集。同时,它隐藏了预处理、编译、汇编、链接等细节,当我们指定了源文件(.c)时,它会自动按照编译流程调用不同的子工具,自动生成最终的二进制程序映像(.bin)。
注意:严格意义上来说,交叉编译器,只是指交叉编译的gcc,但是实际上为了方便,我们常说的交叉编译器就是交叉工具链。本文对这两个概念不加以区分,都是指编译链
2.2 交叉编译链的命名规则
我们使用交叉编译链时,常常会看到这样的名字:
arm-none-linux-gnueabi-gcc
arm-cortex_a8-linux-gnueabi-gcc
mips-malta-linux-gnu-gcc
其中,对应的前缀为:
arm-none-linux-gnueabi-
arm-cortex_a8-linux-gnueabi-
mips-malta-linux-gnu-
这些交叉编译链的命名规则似乎是通用的,有一定的规则:
arch-core-kernel-system
- arch: 用于哪个目标平台。
- core: 使用的是哪个CPU Core,如Cortex A8,但是这一组命名好像比较灵活,在其它厂家提供的交叉编译链中,有以厂家名称命名的,也有以开发板命名的,或者直接是none或cross的。
- kernel: 所运行的OS,见过的有Linux,uclinux,bare(无OS)。
- systen:交叉编译链所选择的库函数和目标映像的规范,如gnu,gnueabi等。其中gnu等价于glibc+oabi;gnueabi等价于glibc+eabi。
注意:这个规则是一个猜测,并没有在哪份官方资料上看到过。而且有些编译链的命名确实没有按照这个规则,也不清楚这是不是历史原因造成的。如果有谁在资料上见到过此规则的详细描述,欢迎指出错误。
第 3 章 包含的工具
3.1 Binutils
Binutils是GNU工具之一,它包括链接器、汇编器和其他用于目标文件和档案的工具,它是二进制代码的处理维护工具。
Binutils工具包含的子程序如下:
- ld :GNU连接器the GNU linker.
- as :GNU汇编器the GNU assembler.
- addr2line :把地址转换成文件名和所在的行数
- ar :A utility for creating, modifying and extracting from archives.
- c++filt :Filter to demangle encoded C++ symbols.
- dlltool : Creates files for building and using DLLs.
- gold : A new, faster, ELF only linker, still in beta test.
- gprof :Displays profiling information.
- nlmconv :Converts object code into an NLM.
- nm :Lists symbols from object files.
- objcopy :Copys and translates object files.
- objdump :Displays information from object files.
- ranlib :Generates an index to the contents of an archive.
- readelf :Displays information from any ELF format object file.
- size :Lists the section sizes of an object or archive file.
- strings: Lists printable strings from files.
- strip :Discards symbols
binutils介绍
3.2 GCC
GNU编译器套件,支持C, C++, Java, Ada, Fortran, Objective-C等众多语言。
3.3 GLibc
Linux上通常使用的C函数库为glibc。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。glibc除了封装linux操作系统所提供的系统服务外,它本身也提供了许多其它一些必要功能服务的实现。
glibc 各个库作用介绍
因为嵌入式环境的资源及其紧张,所以现在除了glibc外,还有uClibc和eglibc可以选择,三者的关系可以参见这两篇文章:
uclibc eglibc glibc之间的区别和联系
Glibc vs uClibc Differences
3.4 GDB
GDB用于调试程序
第 4 章 如何得到交叉编译链
既然明白了交叉编译链的功能,那么在针对嵌入式系统开发时,我们需要的交叉编译链从哪儿得到?
主要有三个方式可以获取
4.1 下载已经做好的交叉编译链
使用其他人针对某些CPU平台已经编译好的交叉编译链。我们只需要找到合适的,下载下来使用即可。
常见的交叉编译链下载地址:
在 http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/ 下载已经编译好的交叉编译链
在 http://www.denx.de/en/Software/WebHome 下载已经编译好的交叉编译链
在 https://launchpad.net/gcc-arm-embedded 下载已经编译好的交叉编译链
一些制作交叉编译链的工具中,包含了已经制作好的交叉编译链,可以直接拿来使用。如crosstool-NG
如果购买了某个芯片或开发板,一般厂商会提供对应的整套开发软件,其中就包含了交叉编译链。
厂家提供的工具一般是经过了严格的测试,并打入了一些必要的补丁,所以这种方式往往是最可靠的工具来源。
4.2 使用工具定制交叉编译链
使用现存的制作工具,以简化制作交叉编译链这个事情的复杂度。我们只需要了解有哪些工具可以实现,并选个合适的工具,搞懂它的操作步骤即可。
- crosstool-NG
- Buildroot
- Embedded Linux Development Kit (ELDK)
工具还有很多,各有各的优势和劣势,大家可以慢慢研究,在这就不细说了。
4.3 从零开始构建交叉编译链
这个是最困难也最耗时间的,毕竟制作交叉编译链这样的事情,需要对嵌入式的编译原理了解的比较透彻,至少要知道出了问题要往哪个方面去翻阅资料。而且,也是最考耐心和细心的地方,配错一个选项或是一个步骤,都可能出现以前从来没见过的问题,而且这些问题往往还无法和这个选项或步骤直接联系起来。
当然如果搭建出来,肯定也是收获最大的,至少对于编译的流程和依赖都比较清楚了,细节上的东西可能还需要去翻看相应的协议或标准,但至少骨架会比较清楚。
详细的搭建过程可以参看后续的文章,这里面有详细的参数和步骤:
交叉编译详解 二 从零制作交叉编译链
为了方便大家搭建交叉编译链,我写了一个一键生成的脚本(包括源码下载和自动编译)。如果大家自己一直搭建不成功,不妨试试这个脚本,然后对比下自己的流程是否一致,参数是否有差异,也许能帮大家迈过这个障碍:
交叉编译详解 三 使用脚本自动生成交叉编译链
4.4 对比两种构建方式
| 项目 | 使用已有交叉编译链 | 自己制作交叉编译链 |
|---|---|---|
| 安装 | 一般提供压缩包 | 需要自己打包 |
| 源码版本 | 一般使用较老的稳定版本,对于一些新的GCC特性不支持 | 可以使用自己需要的GCC特性的版本 |
| 补丁 | 一般都会打上修复补丁 | 普通开发者很难辨别需要打上哪些补丁,资深开发者可以针对自己的需求合入补丁 |
| 源码溯源 | 可能不清楚源码版本和补丁情况 | 一切都可以定制 |
| 升级 | 一般不会升级 | 可以随时升级 |
| 优化 | 一般已经针对特定CPU特性和性能进行优化 | 一般无法做到比厂家优化的更好,除非自己设计的CPU |
| 技术支持 | 可以通过FAE进行支持,可能需要收费 | 只能通过社区支持,免费 |
| 可靠性验证 | 已经通过了完善的验证 | 自己验证,肯定没有专业人士验证的齐全 |
参考资料
[1] Introduction to cross-compiling for Linux
[2] binutils介绍
[3] glibc 各个库作用介绍
[4] uclibc eglibc glibc之间的区别和联系
[5] Glibc vs uClibc Differences
[6] 交叉编译链下载地址
- http://ftp.arm.linux.org.uk/pub/armlinux/toolchain/
- http://www.denx.de/en/Software/WebHome
- https://launchpad.net/gcc-arm-embedded