Hadoop 完全分布式搭建(超详细)
Hadoop 完全分布式搭建
-
-
-
- 1. 虚拟机安装
-
- 系统安装
- 网络设置
- 2. 安装 Hadoop 完全分布式
-
- 前置环境设置
- 免密登录设置
- 集群安装规划
- 开始安装
-
- 1.上传安装包 和 JDK1.8
- 2.解压文件
- 3.配置环境变量
- 4. 配置 Hadoop-env.sh 文件
- 5. 配置 Hadoop 重要文件
- 6.配置 workers/slaves 文件
- 7.文件分发
- 8.启动集群
-
-
前言:本文中使用的 Hadoop 版本为 hadoop-3.1.3,系统为 CentOS 7。
集群其它生态安装与配置:
-
Hive 搭建(将 MySQL 作为元数据库)
-
Spark 集群搭建(多种方式)
-
Sqoop 安装配置(超详细)
-
Hudi 0.12.0 搭建——集成 Hive3.1 与 Spark3.2
1. 虚拟机安装
在学习过程中,一般情况下我们都是在本机通过安装虚拟机来完成 Hadoop 完全分布式的安装。在安装完虚拟机后,我们来设置虚拟机,安装镜像等操作。
系统安装
第一步:点击左上角文件—— 新建虚拟机
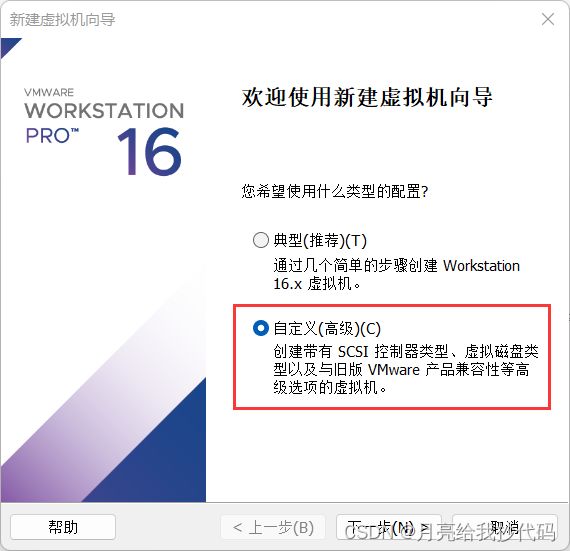
选择自定义,点击下一步。
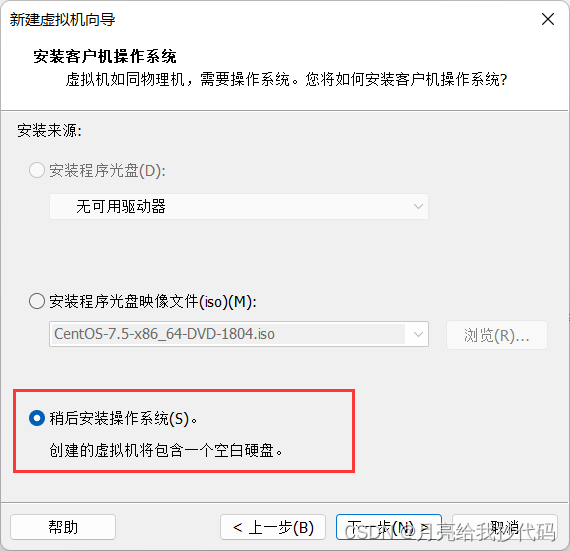
选择稍后安装操作系统,点击下一步。
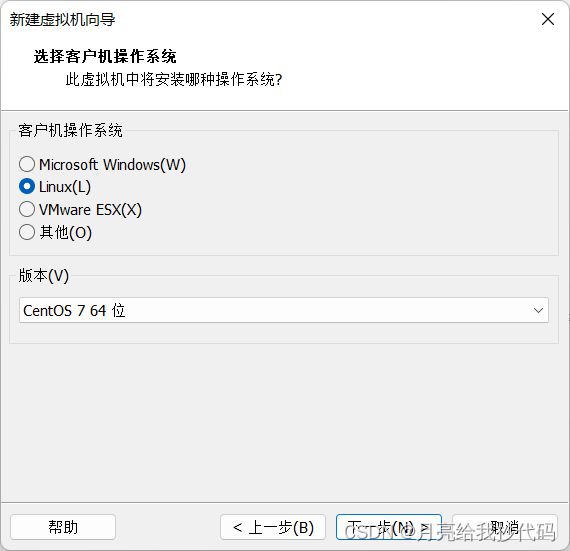
选择虚拟机的版本(我使用的是 CentOS 7),点击下一步。
点击下一步,设置虚拟机名称和安装位置。

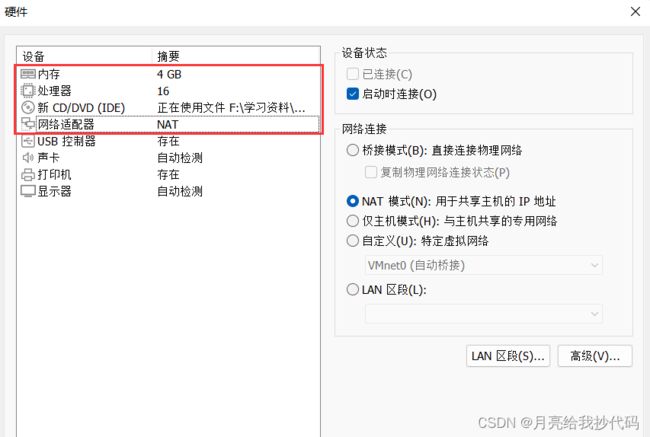
点击下一步,设置系统参数。请结合自身电脑的性能来进行设置(在任务管理器中的性能一栏中查看):
- 内存:因为我们要搭建完全分布式(一台主机两台从机),所以我们将内存总容量除 4 得到的就是每台虚拟机可设置的内存容量。我的内存是 16 G,所以在这里设置为 4G。
- 处理器:设置为和本机数量一致,不能大于。
- 网络适配器:设置为 NAT 模式。
一直点击下一步,设置虚拟机磁盘容量,根据自身的实际情况来,建议设置为 50G,避免其它应用安装不了。并不是给多少就会在本地占用多少硬盘,而是用多少占用多少。
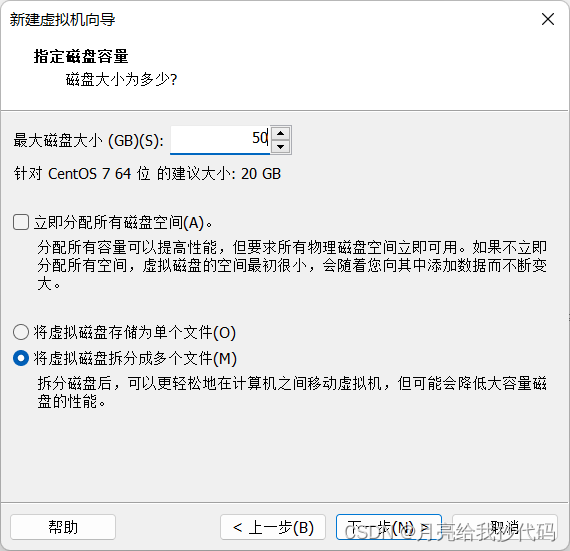
一直点击下一步,直到完成。编辑虚拟机,为其添加镜像文件
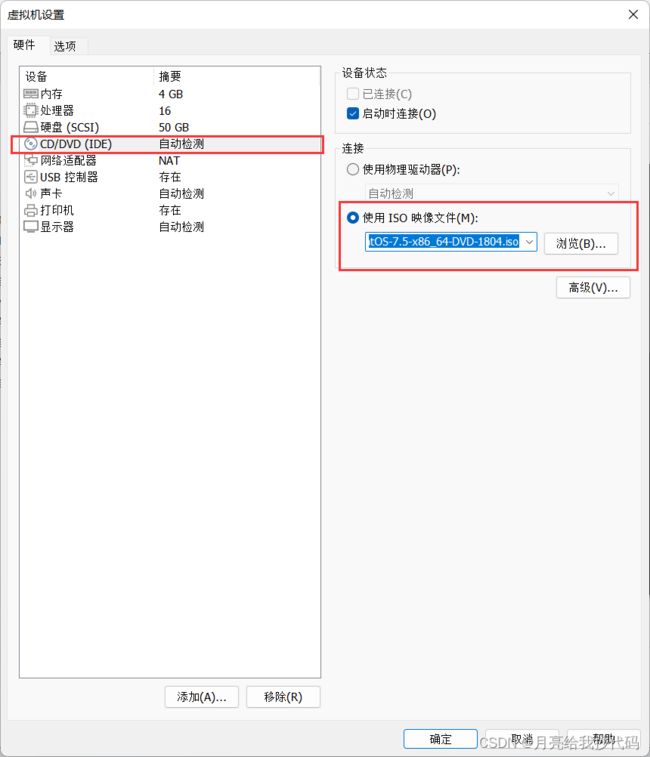
点击确定,我们就可以开启虚拟机,等待安装完成。
在安装过程中需要我们对系统进行一些安装配置,首先下拉菜单将语言修改为简体中文。
点击软件选择,勾选桌面那一栏,点击完成退出。

点击安装位置,选择我要配置分区。

点击完成,进入分区配置界面,切换成标准分区。
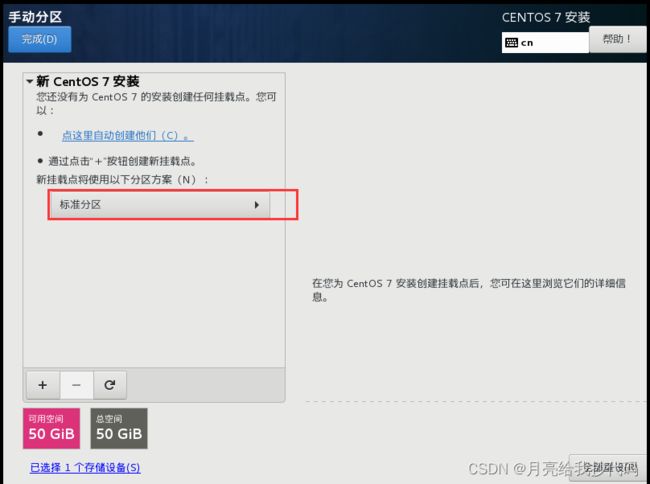
点击左下角 + 号添加分区,点击下拉列表框,选择 /boot,分配 1G 空间,点击添加,添加完成后修改文件系统为 ext4。
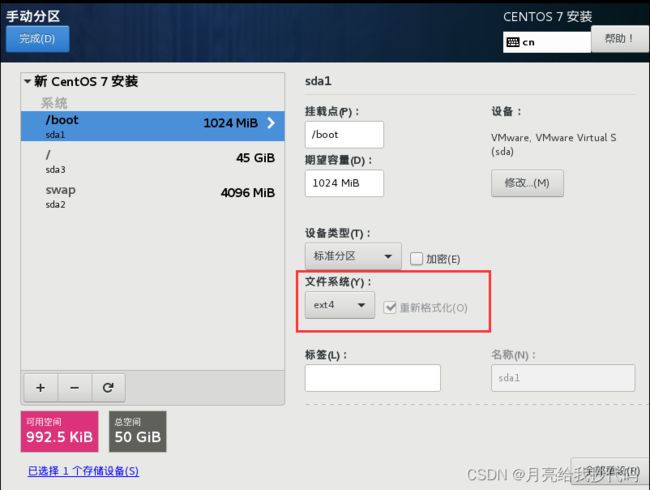
点击左下角 + 号添加分区,点击下拉列表框,选择 swap 交换分区,分配 4G 空间。将剩余的空间全部给主目录 /。
我这里分配完成后如下所示:

点击完成接受更改,保存退出。
关闭 KDUMP
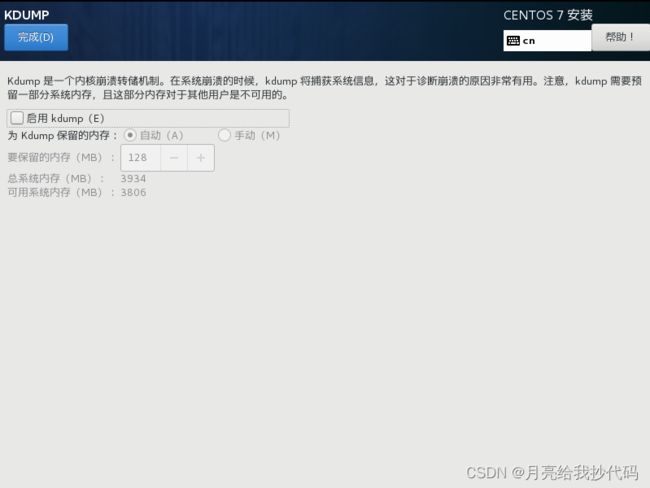
开启网络

上述设置完成后,点击开始安装,设置 ROOT 密码,顺便添加一个用户,等待系统安装完成。
网络设置
系统安装完成后,我们来设置虚拟机的网络,点击左上角编辑——虚拟网络编辑器
设置网络基础信息
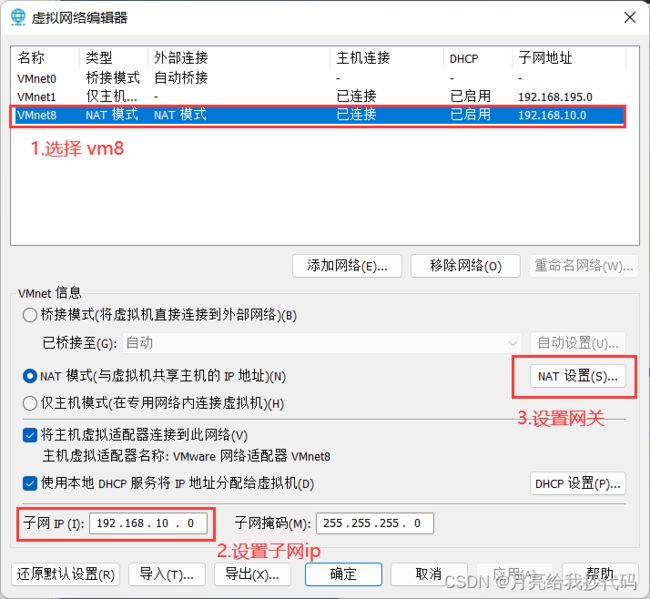
设置网关
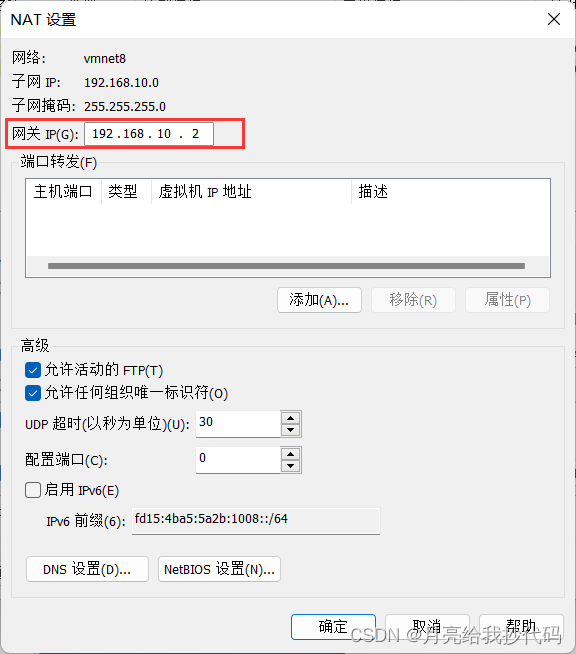
点击确定,保存退出。
设置本地网络,点击控制面板,进入网络适配器界面,选择 vm8

右击,选择属性,修改 ipv4。

注意:需要和虚拟机中设置的网络信息保持一致。
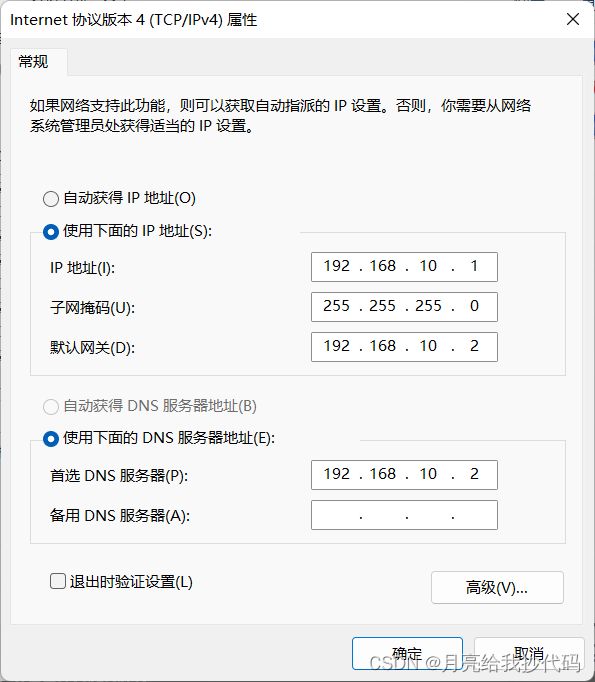
进入到系统中,打开终端,设置为静态 ip ,添加 ip 地址、网关和域名。
vi /etc/sysconfig/network-scripts/ifcfg-ens33
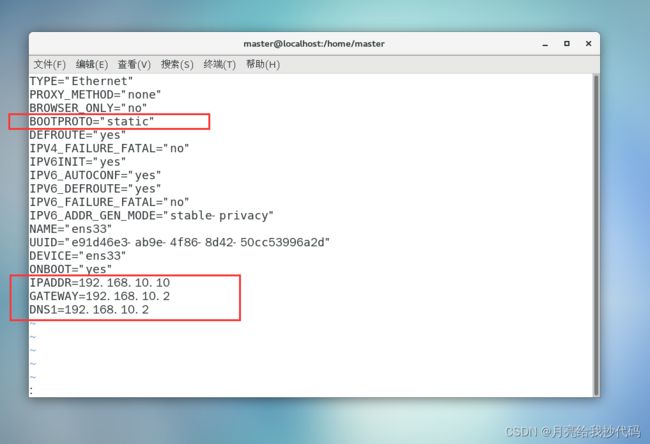
重启网络服务
systemctl restart network
使用 ifconfig 命令检查是否设置成功。
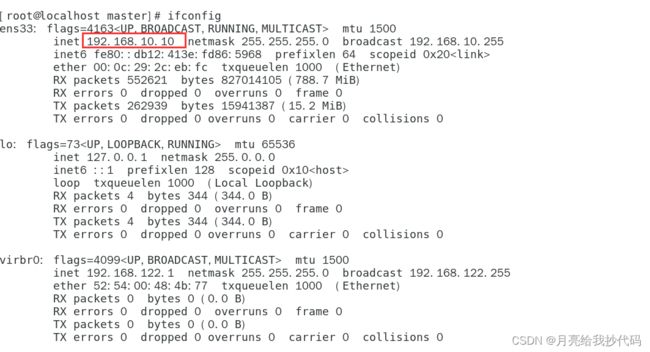
到此为止,我们的虚拟机网络设置完成。
2. 安装 Hadoop 完全分布式
前置环境设置
1.修改主机名称为 “master” (你可以取其它的名字)与 hosts 文件,方便后去集群之间的映射。
# 修改主机名称
vi /etc/hostname
# 或者
hostnamectl set-hostname master
修改 hosts 文件,提前添加映射,注意保存退出。
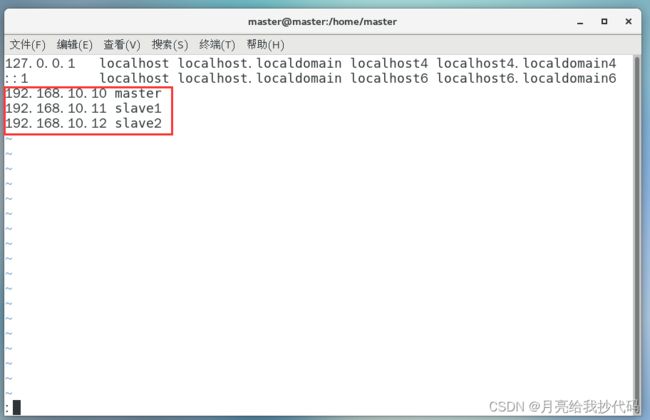
2.关闭防火墙
# 临时关闭防火墙
systemctl stop firewalld
# 永久关闭防火墙
systemctl disable firewalld
3.安装相关软件
# 安装下载库
yum install -y epel-release
如果是最小化安装,还需安装以下工具:
# net-tool:工具包集合,包含ifconfig等命令
yum install -y net-tools
# vim:编辑器(可选)
yum install -y vim
4.卸载原生 JDK,最小化安装的无需操作。
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
5.克隆两台虚拟机,作为从机使用。
右击创建好的虚拟机,选择管理——克隆——点击下一页,完整克隆。
克隆完成后,启动两台克隆机器。打开终端,修改主机名称,设置为静态 ip ,添加 ip 地址、网关和域名,注意与主节点 master 中的 hosts 文件保持一致。设置完成后,重启网络,检查是否设置成功。
免密登录设置
为了后期使用方便,我们为集群机器之间设置免密登录,这里使用 Xshell 工具使用远程登录连接操作,可以在官网免费下载 Xshell 官网,顺便也下载 Xftp 工具,方便后期传输文件和安装包。
打开 Xshell 工具,点击左上角文件——新建,在弹出框中设置名称和 ip 地址,然后点击连接,随后输入 ROOT 账号密码完成连接。
如果连接不上请检查你的虚拟机是否启动或者 ip 地址是否填写有误。

三台机子都连接成功之后,开始设置免密登录。我这里给出 master 主节点免密登录其它两台从机的示例,从机免密登录主机就照葫芦画瓢吧。
# 生成公钥与私钥(三次回车)
ssh-keygen
# 向目标主机发送公钥(输入密码)
ssh-copy-id slave1
ssh-copy-id slave2
# 也需要对自己设置免密哦
ssh-copy-id master
# 免密登录,输入 exit 退出登录
ssh slave1
...
为其它两台从机设置好免密登录。
集群安装规划
为了合理的分配资源,我们需要对集群进行节点规划。
| master | slave1 | slave2 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
节点解析
| 名称 | 作用 |
|---|---|
| NameNode | 也称为 nn,管理文件系统的命名空间,维护文件系统树以及整个树上所有文件和目录,负责协调集群中的数据存储。 |
| SecondaryNameNode | 帮助 NameNode 缓解压力,合并编辑日志,减少 NameNode 启动时间。 |
| ResourceManager | 一个仲裁整个集群可用资源的主节点,帮助 YARN 系统管理其上的分布式应用。 |
| NodeManager | YARN 中单节点的代理,它管理 Hadoop 集群中单个计算节点。 |
| DataNode | 负责真正存储数据的节点,提供来自文件系统客户端的读写请求。 |
开始安装
1.上传安装包 和 JDK1.8
我这里的 Hadoop 安装包是 hadoop-3.1.3 版本,根据自身需求来。在主节点 master 中的 /opt 目录下新建两个文件夹 module(存放数据) 和 sofeware (存放安装包)。使用 Xftp 工具将 Hadoop 安装包 和 JDK上传到 sofeware 文件夹下,便于后期管理。

2.解压文件
解压文件到 /opt/module 中。
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
3.配置环境变量
vi /etc/profile
# 在文件末尾添加,将路径更改为你的安装路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出后执行命令 source /etc/profile ,使用配置的环境变量立即生效。
输入命令 java -version 验证 JDK 是否安装成功:

4. 配置 Hadoop-env.sh 文件
该位于 $HADOOP_HOME/etc/hadoop 目录下,是一个配置 Hadoop 环境变量的文件,我们只需要在其中指定 Java 安装目录即可。
export JAVA_HOME=/opt/module/jdk1.8.0_212
5. 配置 Hadoop 重要文件
在 Hadoop 中有四个重要的配置文件,位于 $HADOOP_HOME/etc/hadoop 目录下,分别是:
-
核心配置文件 —— core-site.xml
-
HDFS 配置文件 —— hdfs-site.xml
-
YARN 配置文件 —— yarn-site.xml
-
MapReduce 配置文件 —— mapred-site.xml
根据集群规划,配置文件:
1.core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop-3.1.3/datavalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>mastervalue>
property>
configuration>
2.hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-addressname>
<value>master:9870value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>slave2:9868value>
property>
configuration>
3.yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>slave1value>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://master:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
4.mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
property>
ha
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
property>
configuration>
6.配置 workers/slaves 文件
在 Hadoop 的 2.x 版本中 workers 叫 slaves。
该文件位于 $HADOOP_HOME/etc/hadoop 目录下,用于记录集群运行的所有主机。
vi $HADOOP_HOME/etc/hadoop/workers
# 添加你的主机
master
slave1
slave2
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
7.文件分发
我们上面的操作都只是在主节点 master 中进行,现在我们需要把所有文件分发给从机 slave1 和 slave2。
# 分发环境变量
rsync -r /etc/profile slave1:/etc/profile
rsync -r /etc/profile slave2:/etc/profile
# 分发 JDK 和 Hadoop
scp -r /opt/module slave1:/opt
scp -r /opt/module slave2:/opt
分发完成后,进入两台从机使分发的环境变量立即生效。
source /etc/profile
8.启动集群
如果集群是第一次启动,则需要先格式化 NameNode 节点。
hdfs namenode -format
格式化正确则如下所示:

格式化完成后,启动集群:
# 在主节点中运行
start-dfs.sh
# 在 ResourceManager 节点中运行
start-yarn.sh
# 或者
# 在主节点中运行
start-all.sh
# 在 ResourceManager 节点中运行
start-yarn.sh
启动时如果发生如下错误:
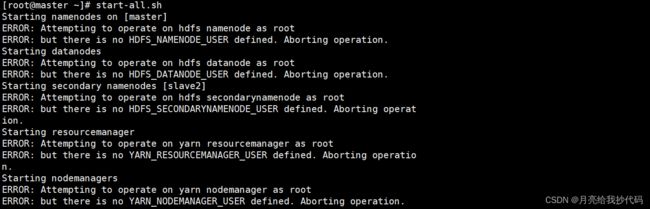
请在 /etc/profile 文件末尾添加如下参数
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
添加完成后分发到其它节点,并使其立即生效。
启动完成后,输入 jps 命令检查各节点是否正常:
master 主节点

slave1 节点

slave2 节点

在本地浏览器中查看 Hadoop web 界面:192.168.10.10:9870
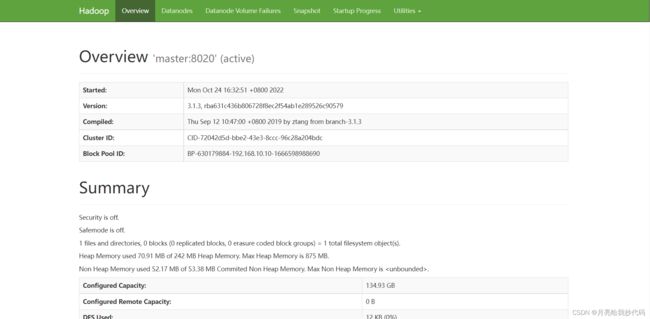
到此为止,我们的 Hadoop 完全分布式就已经搭建完成啦!