XGBOOST算法Python实现(保姆级)
摘要
XGBoost算法(eXtreme Gradient Boosting)在目前的Kaggle、数学建模和大数据应用等竞赛中非常流行。本文将会从XGBOOST算法原理、Python实现、敏感性分析和实际应用进行详细说明。
目录
0 绪论
一、材料准备
二、算法原理
三、算法Python实现
3.1 数据加载
3.2 将目标变量的定类数据分类编码
3.3 将数据分为训练数据和测试数据
3.4训练XGBOOST模型
3.5 测试模型
3.6 输出模型的预测混淆矩阵(结果矩阵)
3.7 输出模型准确率
3.8 绘制混淆矩阵图
3.9 完整实现代码
3.10 结果输出示例
四、 XGBOOST算法的敏感性分析和实际应用
4.1 敏感性分析
4.2 算法应用
五、结论
六、备注
0 绪论
数据挖掘和数学建模等比赛中,除了算法的实现,还需要对数据进行较为合理的预处理,包括缺失值处理、异常值处理、定类数据特征编码和冗余特征的删除等等,本文默认读者的数据均已完成数据预处理,如有需要,后续会将数据预处理的方法也进行发布。
一、材料准备
Python编译器:Pycharm社区版或个人版等
训练数据集:此处使用2022年数维杯国际大学生数学建模竞赛C题的附件数据为例。
数据处理:经过初步数据清洗和相关性分析等操作得到初步的特征,并利用决策树进行特征重要性分析,完成二次特征降维,得到'CDRSB_bl', 'PIB_bl', 'FBB_bl'三个自变量特征,DX_bl为分类特征。
二、算法原理
XGBOOST算法基于决策树的集成方法,主要采用了Boosting的思想,是Gradient Boosting算法的扩展,并使用梯度提升技术来提高模型的准确性和泛化能力。
首先将基分类器层层叠加,然后每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重,XGBOOST的目标函数为:

(1)
其中,![]() 为损失函数;
为损失函数;![]() 为正则项,用于控制树的复杂度;
为正则项,用于控制树的复杂度;![]() 为常数项,
为常数项,![]() 为新树的预测值
为新树的预测值![]() ,它是将树的个数的结果进行求和。
,它是将树的个数的结果进行求和。
三、算法Python实现
3.1 数据加载
此处导入本文所需数据,DataX为自变量数据,DataY为目标变量数据(DX_bl)。
import pandas as pd
X = pd.DataFrame(pd.read_excel('DataX.xlsx')).values # 输入特征
y = pd.DataFrame(pd.read_excel('DataY.xlsx')).values # 目标变量3.2 将目标变量的定类数据分类编码
此处仅用0-4来代替五类数据,因为此处仅做预测,并不涉及相关性分析等其他操作,所以普通的分类编码就可以。如果需要用来做相关性分析或其他计算型操作,建议使用独热编码(OneHot- Encoding)。
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
label_mapping = {0: 'AD', 1: 'CN', 2: 'EMCI', 3: 'LMCI', 4: 'SMC'}
#此处为了后续输出混淆矩阵时,用原始数据输出3.3 将数据分为训练数据和测试数据
本文将原始样本数据通过随机洗牌,并将70%的样本数据作为训练数据,30%的样本数据作为测试数据。这是一个较为常见的拆分方法,读者可通过不同的拆分测试最佳准确率和F1-score。
from sklearn.model_selection import train_test_split
# 将数据分为训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, train_size=0.7, random_state=42)3.4训练XGBOOST模型
基于70%的样本数据进行训练建模,python有XGBOOST算法的库,所以很方便就可以调用。
import xgboost as xgb
# 训练XGBoost分类器
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
#xgb.plot_tree(model)3.5 测试模型
利用另外的30%样本数据进行测试模型准确率、精确率、召回率和F1度量值。
# 使用测试数据预测类别
y_pred = model.predict(X_test)3.6 输出模型的预测混淆矩阵(结果矩阵)
此处输出混淆矩阵的方法和之前的随机森林、KNN算法都有点不同,因为随机森拉算法不需要将定类数据进行分类编码就可以直接调用随机森林算法模型。
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
cm = confusion_matrix(y_test, y_pred)
# 输出混淆矩阵
for i, true_label in enumerate(label_mapping.values()):
row = ''
for j, pred_label in enumerate(label_mapping.values()):
row += f'{cm[i, j]} ({pred_label})\t'
print(f'{row} | {true_label}')
# 输出混淆矩阵
print(classification_report(y_test, y_pred,target_names=['AD', 'CN', 'EMCI', 'LMCI', 'SMC'])) # 输出混淆矩阵3.7 输出模型准确率
#此处的导库在上一个代码段中已引入
print("Accuracy:")
print(accuracy_score(y_test, y_pred))3.8 绘制混淆矩阵图
将混淆矩阵结果图绘制并输出,可以将这一结果图放在论文中,提升论文美感和信服度。
import matplotlib.pyplot as plt
import numpy as np
label_names = ['AD', 'CN', 'EMCI', 'LMCI', 'SMC']
cm = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵图
fig, ax = plt.subplots()
im = ax.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
ax.figure.colorbar(im, ax=ax)
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
xticklabels=label_names, yticklabels=label_names,
title='Confusion matrix',
ylabel='True label',
xlabel='Predicted label')
# 在矩阵图中显示数字标签
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], 'd'),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
fig.tight_layout()
#plt.show()
plt.savefig('XGBoost_Conclusion.png', dpi=300)上面的代码首先计算混淆矩阵,然后使用 matplotlib 库中的 imshow 函数将混淆矩阵可视化,最后通过 text 函数在混淆矩阵上添加数字,并使用 show/savefig 函数显示图像,结果输出如图3.1所示。
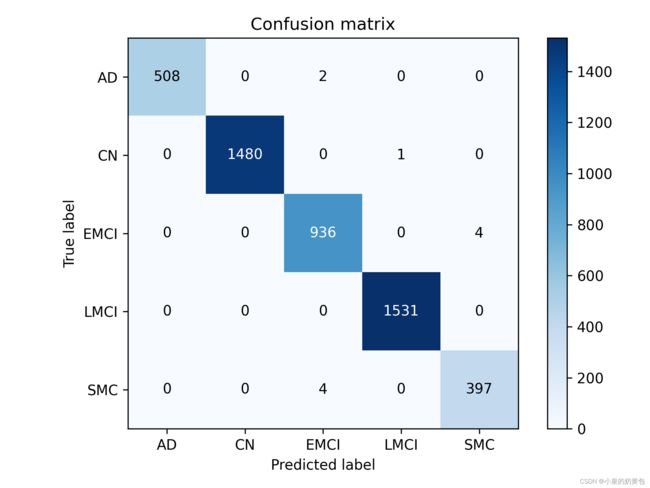
图3.1 混淆矩阵结果图
3.9 完整实现代码
# 导入需要的库
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
import numpy as np
le = LabelEncoder()
label_mapping = {0: 'AD', 1: 'CN', 2: 'EMCI', 3: 'LMCI', 4: 'SMC'}
X = pd.DataFrame(pd.read_excel('DataX.xlsx')).values # 输入特征
y = pd.DataFrame(pd.read_excel('DataY.xlsx')).values # 目标变量
y = le.fit_transform(y)
# 将数据分为训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, train_size=0.7, random_state=42)
# 训练XGBoost分类器
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
#xgb.plot_tree(model)
# 使用测试数据预测类别
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
# 输出混淆矩阵
for i, true_label in enumerate(label_mapping.values()):
row = ''
for j, pred_label in enumerate(label_mapping.values()):
row += f'{cm[i, j]} ({pred_label})\t'
print(f'{row} | {true_label}')
# 输出混淆矩阵
print(classification_report(y_test, y_pred,target_names=['AD', 'CN', 'EMCI', 'LMCI', 'SMC'])) # 输出混淆矩阵
print("Accuracy:")
print(accuracy_score(y_test, y_pred))
# label_names 是分类变量的取值名称列表
label_names = ['AD', 'CN', 'EMCI', 'LMCI', 'SMC']
cm = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵图
fig, ax = plt.subplots()
im = ax.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
ax.figure.colorbar(im, ax=ax)
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
xticklabels=label_names, yticklabels=label_names,
title='Confusion matrix',
ylabel='True label',
xlabel='Predicted label')
# 在矩阵图中显示数字标签
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], 'd'),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
fig.tight_layout()
#plt.show()
plt.savefig('XGBoost_Conclusion.png', dpi=300)
# 上面的代码首先计算混淆矩阵,然后使用 matplotlib 库中的 imshow 函数将混淆矩阵可视化,最后通过 text 函数在混淆矩阵上添加数字,并使用 show/savefig 函数显示图像。3.10 结果输出示例
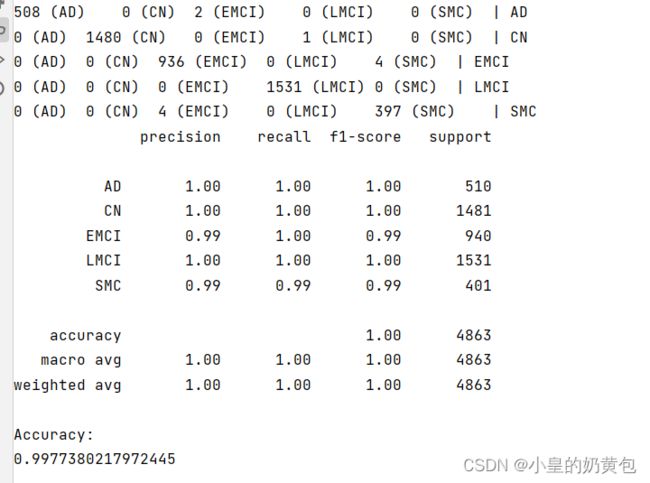
图3.2 结果输出示例
四、 XGBOOST算法的敏感性分析和实际应用
4.1 敏感性分析
敏感性分析也叫做稳定性分析,可以基于统计学思想,通过百次测试,记录其准确率、精确率、召回率和F1-Score的数据,统计其中位数、平均值、最大值和最小值等数据,从而进行对应的敏感性分析。结果表明符合原模型成立,则通过了敏感性分析。前面的随机森林算法和KNN算法也是如此。
4.2 算法应用
XGBOOST算法可应用于大数据分析、预测等方面,尤其是大数据竞赛(Kaggle、阿里天池等竞赛中)特别常用,也是本人目前认为最好用的一个算法。
五、结论
本文基于XGBOOST算法,从数据预处理、算法原理、算法实现、敏感性分析和算法应用都做了具体的分析,可适用于大部分机器学习算法初学者。
六、备注
本文为原创文章,禁止转载,违者必究。如需原始数据,可点赞+收藏,然后私聊作者或在评论区中留下你的邮箱,即可获得训练数据一份。