第9步 Xgboost
文章目录
- 前言
- 一、导入库与数据
- 二、数据集切分与特征缩放
- 三、数据训练与预测
-
- 3.1 安装Xgboost
- 3.2 训练Xgboost
- 3.3 预测测试集结果
-
- 保姆级解说
- 3.4 模型评估
- 总结
前言
机器学习领域经常会举行各种大数据竞赛,就是给出一个数据集,大家设计算法去做分类,谁构建的模型性能优异谁获胜。而Xgboost就是竞赛江湖中的屠龙刀和大杀器,近年来一统江湖。
上一步我们介绍了集成学习,其中提到了一种boosting方法叫作GBDT,也就是“每一次的计算是都为了减少上一次的残差”的那个模型。Xgboost则是它的增强版本,是一种把速度和效率发挥到极致的GBDT,所以叫作eXtreme Gradient Boosting。那么两者有何区别:
(1)Xgboost可以使用正则项来控制模型的复杂度,防止过拟合;
(2)Xgboost可以使用多种类型的基础分类器;
(3)Xgboost在每轮迭代时,支持对数据进行随机采样(类似RF);
(4)Xgboost支持缺失值处理。
以上就是Xgboost有的,GBDT没有。
不知道大家有没有一种感觉,就是在Xgboost身上看到了很多ML模型的影子,一种终极融合进化的感觉。
介绍完了,用SUV开始进行实战:
一、导入库与数据
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 导入数据集
dataset = pd.read_csv('Day 4 Social_Network_Ads.csv')
X = dataset.iloc[:, [1, 2, 3]].values
Y = dataset.iloc[:, 4].values
# 性别转化为数字
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
二、数据集切分与特征缩放
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size=0.25, random_state=0)
# 特征缩放
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
三、数据训练与预测
3.1 安装Xgboost
Sklearn并没有包含Xgboost,所以得自己安装,步骤如下:
① 官方说明中写了在windows中pip安装xgboost可能会有问题,所以最好自己下载安装。
② 登陆这个网址https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost,找到 xgboost,这里有适用于 python3.8、3.9(64、32位),选好适合自己的版本。还记得怎么看python版本不?打开Spyder就有:

我的是python 3.9,所以下载3.9版本(cp39)的Xgboost,系统是64位。
 ③ 复制粘贴到***\Anaconda3\Scripts目录下面,不通电脑路径估计不同,比如我的是C:\ProgramData\Anaconda3\Scripts,但是后面\Anaconda3\Scripts肯定是一样的:
③ 复制粘贴到***\Anaconda3\Scripts目录下面,不通电脑路径估计不同,比如我的是C:\ProgramData\Anaconda3\Scripts,但是后面\Anaconda3\Scripts肯定是一样的:

④ 打开运行,输入cmd,回车,调出控制台:


⑤ 敲入代码:cd C:\ProgramData\Anaconda3\Scripts切到目录(Xgboost安装文件复制粘贴在这里了),敲入pip install xgboost-1.6.1-cp39-cp39-win_amd64.whl,回车安装:


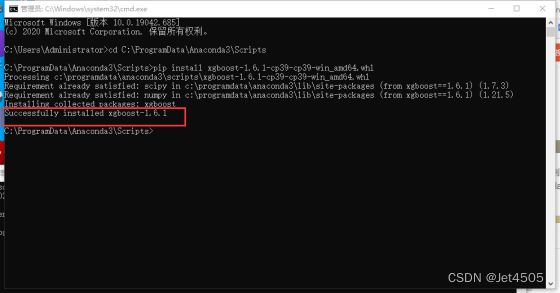
⑥ 打开Spyder,输入import xgboost,导入成功。

3.2 训练Xgboost
import xgboost as xgb
boost = xgb.XGBClassifier(n_estimators=200, max_depth=9, min_child_weight=3, subsample=0.9, colsample_bytree=0.9, scale_pos_weight=1, gamma=0.1, reg_alpha=7)
boost.fit(X_train, y_train)
3.3 预测测试集结果
y_pred = boost.predict(X_test)
保姆级解说
1、Xgboost的参数可以分为三类:通用参数,用于宏观控制函数;Booster参数,用于控制每一步的booster(tree/regression)。调参很大程度上都是在调整booster参数。学习目标参数,用于控制训练目标的表现。下面只介绍重要参数(因为太多了):
1.1、通用参数
① booster: 指定要使用的基础模型,默认gbtree。可以输入gbtree,gblinear或dart。输入的评估器不同,使用的参数也不同,每种评估器都有自己的参数列表。评估器必须于自身的参数相匹配,否则报错。
gbtree:即是论文中主要讨论的树模型,推荐使用;
gblinear:是线性模型,表现很差,接近一个LASSO;
dart:抛弃提升树,在建树的过程中会抛弃一部分树,比梯度提升树有更好的防过拟合功能。
② silent:是否为静默模式,默认0。都不推荐使用
③ verbosity:打印模型构建过程信息的详细程度,默认1。可选值为0(静默)、1(警告)、2(信息)、3(调试)。
④ nthread:使用线程数,一般我们设置成-1,使用所有线程。
1.2、Booster参数
① n_estimator:表示集成的基础模型的个数。跟随机森林的一样。
② learning_rate:每一步迭代的步长,也叫学习率,默认0.3。
③ gamma:指定了节点分裂所需的最小损失函数下降值,值越大,算法越保守,默认为0。
④ subsample:每棵树随机采样的比例。减小这个值,算法会更加保守,避免过拟合,默认为1。
⑤ colsample_bytree:控制构建每棵树时随机抽样的特征占所有特征的比例,默认为1。
⑥ colsample_bylevel:控制树在每一层分支时随机抽样出的特征占所有特征的比例,默认为1。
⑦ max_depth:树的最大深度,用来控制过拟合,默认为6。
⑧ max_delta_step:树的权重估计中允许的单次最大增量,默认为0。
⑨ lambda:L2正则化项,默认为0。
⑩ alpha:L1正则化项,默认为0。
⑪ scale_pos_weight:在样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负样本的数目与正样本数目的比值。
⑫ min_child_weight:定义一个子集的所有观察值的最小权重之和,同样是为了减少过拟合的参数,但是也不宜调得过高。
1.3、学习目标参数
① objective:默认reg:linear。
reg:linear – 线性回归;
reg:logistic – 逻辑回归;
binary:logistic – 二分类逻辑回归,输出为概率;
binary:logitraw – 二分类逻辑回归,输出的结果为wTx;
count:poisson – 计数问题的poisson回归,输出结果为poisson分布。
multi:softmax – 设置 XGBoost 使用softmax目标函数做多分类,需要设置参数num_class(类别个数)。
multi:softprob – 如同softmax,但是输出结果为ndata*nclass的向量,其中的值是每个数据分为每个类的概率。
② eval_metric:默认为通过目标函数选择。
rmse: 均方根误差;
mae: 平均绝对值误差;
logloss: negative log-likelihood
error: 二分类错误率。其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。
merror: 多分类错误率,计算公式为(wrong cases)/(all cases)。
mlogloss: 多分类log损失
auc: 曲线下的面积
ndcg: Normalized Discounted Cumulative Gain
map: 平均正确率
2、可以看到Xgboost的参数是真的很多,它的调参也是一门学问。后面会单独示范,这一步我就随便设置了几个参数,大家先看看分类效果如何。
3.4 模型评估
模型预测,使用混淆矩阵评估:
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
print(cm)
输出的结果:

混淆矩阵可视化:

总结
不出意外,大杀器的性能还是可以的。分类错误的仅仅只有6(2+4)个,大家可以考古一下之前的ML模型的性能,我印象中都是8或者9。当然,之前的模型也没有调参,所以严格来说还不能下结论,我只是口嗨而已。