【学习笔记】《深入浅出Pandas》第16章:可视化
文章目录
- 16.1 plot方法
-
- 16.1.1 plot概述
- 16.1.2 plot基础方法
- 16.1.3 图形类型
- 16.1.4 x轴和y轴
- 16.1.5 图形标题
- 16.1.6 字体大小
- 16.1.7 线条样式
- 16.1.8 背景辅助线
- 16.1.9 图例
- 16.1.10 图形大小
- 16.1.11 色系
- 16.1.12 绘图引擎
- 16.1.14 图形叠加
- 16.1.15 颜色的表示
- 16.1.16 解决图形中的中文乱码问题
- 16.2 常用可视化图形
-
- 16.2.1 折线图plot.line
- 16.2.2 饼图plot.pie
- 16.2.3 柱状图plot.bar
- 16.2.4 直方图plot.hist
- 16.2.5 箱型图plot.box
- 16.2.6 面积图plot.area
- 16.2.7 散点图plot.scatter
- 16.2.8 六边形分箱图plot.hexbin
16.1 plot方法
Pandas提供的plot()方法 可以将Series和DataFrame中的数据可视化,它是对matplotlib.axes.Axes.plot 的封装,执行完会生成一张可视化图形,直接显示在Jupyter Notebook上。
16.1.1 plot概述
plot默认是折线图,x轴为索引,y轴为数据。
(1)对于DataFrame,会将所有数字列以多条折线的形式显示在图形中。
# Series调用
s.plot()
# DataFrame调用
df.plot()

(2)其他图形:
df.plot.line() # 折线的全写方式
df.plot.bar() # 柱状图
df.plot.barh() # 横向柱状图(条形图)
df.plot.hist() # 直方图
df.plot.box() # 箱型图
df.plot.kde() # 核密度估计图
df.plot.density() # 同上
df.plot.area() # 面积图
df.plot.pie() # 饼图
df.plot.scatter() # 散点图
df.plot.hexbin() # 六边形图
16.1.2 plot基础方法
(1)Series数据调用plot方法,它的索引信息会显示在x轴,y轴则是x轴上的索引对应的具体数据值。
ts = pd.Series(list(range(5))+list(range(5)),
index=pd.date_range('1/1/2020', periods=10))
"""
2020-01-01 0
2020-01-02 1
2020-01-03 2
2020-01-04 3
2020-01-05 4
2020-01-06 0
2020-01-07 1
2020-01-08 2
2020-01-09 3
2020-01-10 4
Freq: D, dtype: int64
"""
# 绘图
ts.plot()

(2)DataFrame数据:
①调用plot时,x轴为DataFrame的索引,y轴将显示多列的多条折线数据。
df = pd.DataFrame(np.random.randn(6, 4),
index=pd.date_range('1/1/2020', periods=6),
columns=list('ABCD'))
"""
A B C D
2020-01-01 -0.494067 -1.326726 1.017270 0.969768
2020-01-02 -1.094762 -1.035891 1.572841 -0.310795
2020-01-03 0.282873 -0.000758 -0.176886 0.880761
2020-01-04 -0.131953 -1.828849 -0.578733 1.138348
2020-01-05 0.327931 0.793914 0.251315 0.348714
2020-01-06 2.165683 1.044589 0.312085 -0.335197
"""
# 绘图
df.plot()

②DataFrame在绘图时,可以指定x轴和y轴的列。
df.plot(x='A', y='B')
③如果y轴需要多个值,可以传入列表:
# y轴指定两列
df.plot(x='A', y=['B', 'C'])
16.1.3 图形类型
(1)kind参数,可以指定图形的类型:
ts.plot(kind='pie')
 (2)kind支持的参数如下:
(2)kind支持的参数如下:
- line:折线图,默认;
- pie:饼图;
- bar:柱形图;
- barh:横向柱状图;
- hist:直方图;
- kde、density:核密度估计图;
- box:箱型图;
- area:面积图;
- scatter:散点图;
- hexbin:六边形分箱图。
16.1.4 x轴和y轴
如果是Series,则索引是x轴,无须传入y轴的值。
# 可以不写参数名,直接按位置传入
df[:5].plot('name', 'Q1')
df[:5].plot.bar('name', ['Q1', 'Q2'])
df[:5].plot.barh(x='name', y='Q4')
df[:5].plot.area('name', ['Q1', 'Q2'])
df[:5].plot.scatter('name', 'Q3') # 散点图只允许有一个y值
16.1.5 图形标题
用title参数来指定图形标题,标题会显示在图形顶部。
df.head(5).plot.bar(title='前5位学生成绩分布图')

16.1.6 字体大小
fontsize指定轴上的字体大小,单位是pt(磅)。
# 指定轴上的字体大小
df.set_index('name')[:5].plot(fontsize=20)
16.1.7 线条样式
style可指定图的线条样式,并组合使用:
df[:5].plot(style=':') # 虚线
df[:5].plot(style='-.') # 虚实相间
df[:5].plot(style='--') # 长虚线
df[:5].plot(style='-') # 实线,默认
df[:5].plot(style='.') # 点
df[:5].plot(style='*-') # 实线,数值为星星
df[:5].plot(style='^-') # 实线,数值为三角形
16.1.8 背景辅助线
grid会给x方向和y方向增加背景辅助线:
df.set_index('name').head().plot(grid=True)
16.1.9 图例
(1)plot默认显示图例,传入参数legend=False 可隐藏。
df.set_index('name').head().plot(legend=False)
(2)将图例倒排(与之前的顺序相反)。
df.set_index('name').head().plot(legend='reverse')
16.1.10 图形大小
figsize参数传入一个元组,可以指定图形的宽、高(单位为英寸)。
df.set_index('name').head().plot.bar(figsize=(10.5, 5))
全局默认的图形大小:
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (15.0, 8.0) # 固定显示大小
16.1.11 色系
colormap指定图形配色。
df.set_index('name').head().plot.barh(colormap='rainbow')
16.1.12 绘图引擎
backend参数可以指定一个新的绘图引擎,默认是Matplotlib。
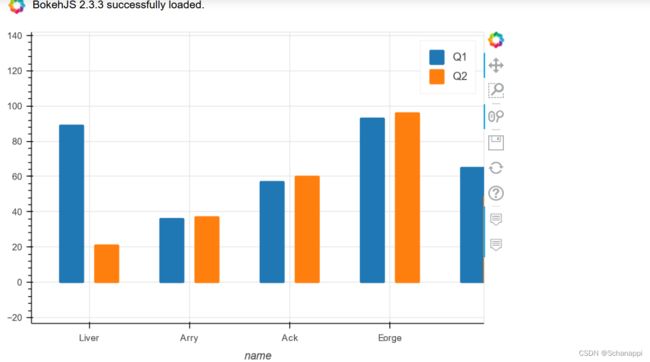
(1)将绘图引擎更换成bokeh,它是一个优秀的可交互的Python可视化绘图库。
import pandas_bokeh
pandas_bokeh.output_notebook() # Notebook展示
df.head().plot.bar('name', ['Q1', 'Q2'], backend='pandas_bokeh')
以上代码执行后,会先加载bokeh的JavaScript等静态资源,然后显示交互式图形。可以点击页面上的各种操作按钮对数据进行探索。
 (2)Pandas支持以下绘图引擎:
(2)Pandas支持以下绘图引擎:
- Matplotlib(默认)
- hvplot 0.5.1版本及以上
- holoviews
- pandas_bokeh
- plotly 4.8版本及以上
- Altair
16.1.14 图形叠加
为了实现两种类型的图形叠加,可以将两个图形的绘图语句组成一个元组或者列表。
(
df['Q1'].head().plot.bar(),
df.mean(1).head().plot(color='r')
)

16.1.15 颜色的表示
在可视化中颜色与CSS的表示方法相同,可以用CSS颜色名和CSS合法颜色值表示。
(1)17种标准颜色名称:aqua、black、blue、fuchsia、gray、green、lime、maroon、navy、olive、orange、purple、red、silver、teal、white、yellow。
(2)合法颜色值,在HTML和CSS中使用3位元素,共6个十六进制的数字表示一种颜色,每位元素的取值从00到FF,相当于十进制数字的0到255。按此顺序,前两位是红色的值,中间两位是绿色的值,最后两位是蓝色的值。
(3)rgb(red, green, blue)格式:如rgb(37,37,37)。
16.1.16 解决图形中的中文乱码问题
(1)临时方案
# Jupyter Notebooks plt 图表配置
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (15.0, 8.0) # 固定显示大小
plt.rcParams['font.family'] = ['sans-serif'] # 显示中文问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文问题
plt.rcParams['axes.unicode_minus'] = False # 显示负号
(2)永久方案:在配置文件中增加指定的中文字体。
16.2 常用可视化图形
本节将介绍plot()方法适配的几个最为常用的图形绘制方法,不需要额外的参数就能快速将数据可视化。
16.2.1 折线图plot.line
plot的默认图形是折线图,因此对于折线图,可以省略df.plot.line()中的line方法。
(1)DataFrame可以直接调用plot生成折线图。
①x轴为索引,其他数字类型的列为y轴上的线条。
df.plot()
df.plot.line()
②如果希望指定的列作为x轴,可以先将其设为索引。
(
df.head()
.set_index('name')
.plot()
)
(2)Series索引作为x轴,值为y轴,如果值非数字则报错:
(
df.set_index('name')
.head()
.Q1 # Series
.plot()
)
(3)可以指定x轴和y轴:
df.plot(x='name', y='Q1')
df.plot(x='name', y=['Q1', 'Q2']) # 指定多条
(4)如果一个折线图中有多条线,可以使用subplots将它们区分,形成多张子图。
df.head().plot.line(subplots=True)
16.2.2 饼图plot.pie
饼图可以表示不同分类的数据在总体中的占比情况,将一个完整的圆形划分为若干个小饼,占比大小体现在弧度大小上。
如果数据中有NaN值,会自动将其填充为0;如果数据中有负值,则会引发ValueError错误。
(1)对于Series:
s = pd.Series(3 * np.random.rand(4),
index=['a', 'b', 'c', 'd'], name='数列')
"""
a 0.423434
b 1.308394
c 0.100264
d 0.858464
Name: 数列, dtype: float64
"""
s.plot.pie()

(2)对于DataFrame,需要指定y值。
df1 = pd.DataFrame(3 * np.random.rand(4, 2),
index=['a', 'b', 'c', 'd'],
columns=['x', 'y'])
"""
x y
a 2.354850 1.666088
b 1.526937 1.883375
c 1.164212 2.745225
d 2.479957 2.440313
"""
df1.plot.pie(y='x')

(3)如果数据总和小于1.0,则会绘制一个扇形。
(4)DataFrame可以传入subplots=True创建子图矩阵。
df1.plot.pie(subplots=True, figsize=(8, 4))
 (5)默认是有图例的,但是可以通过传入参数legend=False来设置。
(5)默认是有图例的,但是可以通过传入参数legend=False来设置。
(6)其他常用参数:
s.plot.pie(labels=['AA', 'BB', 'CC', 'DD'], # 标签,指定项目名称
colors=['r', 'g', 'b', 'c'], # 指定颜色
autopct='%.2f', # 数字格式
fontsize=20, # 字体大小
figsize=(6, 6) # 图大小
)
16.2.3 柱状图plot.bar
(1)DataFrame直接调用plot.bar生成柱状图。
①x轴为索引,其他数字类型的列为y轴上的条形:
df1.plot.bar()
df1.plot.barh() # 横向
df[:5].plot.bar(x='name', y='Q4') # 指定x、y轴
②如果想将指定的列显示在x轴,可以将其设置为索引:
(
df.head()
.set_index('name')
.plot
.bar()
)
(2)Series索引为x轴,值为y轴,有值为非数字的时候会报错。
①如果数据中有负值,则0刻度会在x轴上,不会在图形底边:
(
df.assign(Q1=df.Q1 - 70)
.loc[:6]
.set_index('name')
.plot
.bar()
)
 ②将同一索引的多个数据堆叠起来:
②将同一索引的多个数据堆叠起来:
(
df.loc[:6]
.set_index('name')
.plot
.bar(stacked=True)
)

(3)柱状图同样支持子图,使用subplots=True。
16.2.4 直方图plot.hist
直方图又称质量分布图,由一系列高度不等的纵向条纹或线段表示数据分布情况。一般用横轴表示数据类型,纵轴表示分布情况。
直方图描述的是数据在不同区间内的分布情况,描述的数据量一般比较大。分组数据字段(统计结果)映射到横轴的位置,频数字段(统计结果)映射到矩形的高度,可以对分类数据设置颜色以增加分类的区分度。
(1)在下例中,随机生成三列数,每列1000个,其中一个在随机数上加一,一个减一,然后绘制直方图,默认分箱数为10个(bins=10),alpha为颜色的透明度(范围0~1):
df2 = pd.DataFrame({'a': np.random.randn(1000) + 1,
'b': np.random.randn(1000),
'c': np.random.randn(1000) - 1},
columns=['a', 'b', 'c'])
df2.plot.hist(alpha=0.5)
(2)Series为单直方图:
# 单直方图
df2.a.plot.hist()
 (3)堆叠并指定分箱数量:
(3)堆叠并指定分箱数量:
df2.plot.hist(stacked=True, bins=20)

(4)直接使用df.hist(alpha=0.5)来绘制子图:
df2.hist(alpha=0.5)
 (5)可以单独绘制子图,指定分箱数量:
(5)可以单独绘制子图,指定分箱数量:
df2.a.hist(bins=20, alpha=0.5)
df2.hist('a', bins=20, alpha=0.5) # 同上
 (6)by参数可用来分组,生成分组后的子图:
(6)by参数可用来分组,生成分组后的子图:
df.Q1.hist(by=df.team)

16.2.5 箱型图plot.box
箱型图又称盒形图、盒式图或箱线图,用来显示一组数据分布情况的统计图。
Series.plot.box()、DataFrame.plot.box() 和DataFrame.boxplot() 都可以绘制箱型图。
df.plot.box()无法使用,找不到原因
(1)箱型图可以观察到:
- 一组数据的关键值,如中位数、最大值、最小值;
- 数据集中是否存在异常值以及异常值的具体数值;
- 数据是不是对称;
- 数据分布是否密集;
- 数据是否扭曲,即是否具有偏向性
(2)使用方法
df.plot.box() # 所有列 Fail
(3)其他方法:
df.A.plot.box() # 单列 Fail
df.boxplot()
df.boxplot('Q1')
(4)使用vert=False将图形设置为横向,用position控制位置:
# 横向+位置调整
df.plot.box(vert=False, positions=[1, 2, 5, 6])
16.2.6 面积图plot.area
面积图又叫区域图,将折线图中折线与自变量坐标轴之间的区域使用颜色或纹理填充,这样填充区域就叫做面积。填充颜色可以更好突出趋势信息。
默认情况下,面积图是堆叠的。
要生成堆积面积图,每列必须全部为正值或全部为负值。
当输入数据包含NaN时,它将被填充为0。
如果要删除或填充不同的值,需要在调用图之前使用DataFrame.dropna()或DataFrame.fillna()。
Series.plot.area() 和 **DataFrame.plot.area()**是面积图的基本操作,默认情况下,x轴为索引,y轴为值或者所有数据列。
(1)单列:
df4 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df4.a.plot.area() # 单列
 (2)所有数据列:
(2)所有数据列:
df4.plot.area()

(3)生成未堆积、有一定透明度的图,传入stack=False,Alpha默认为0.5:
 (4)指定x轴和y轴:
(4)指定x轴和y轴:
df4.plot.area(y='a')
df4.plot.area(y=['b', 'c'])
df4.plot.area(x='a') # y轴为b、c、d
16.2.7 散点图plot.scatter
散点图也叫x-y图,它将所有数据以点的形式展现在直角坐标系上,以显示变量之间的相互影响程度,点的位置由变量的数值决定。
(1)可以使用DataFrame.plot.scatter()方法绘制散点图。散点图要求x轴和y轴为数字列,这些可以通过x和y关键字指定。
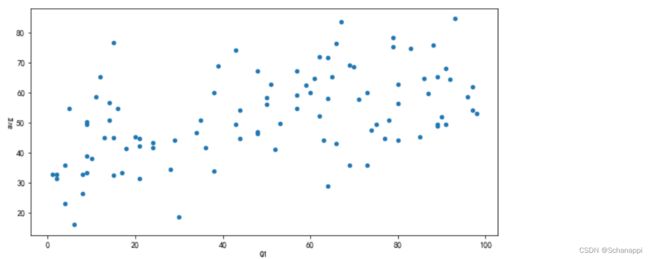
(
df.assign(avg=df.mean(1))
.plot
.scatter(x='Q1', y='avg')
)
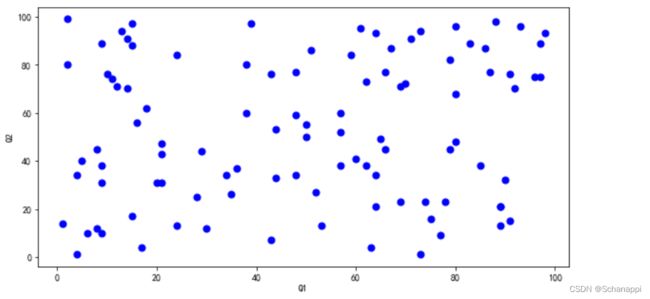
(2)使用c参数指定点的颜色:
df.plot.scatter(x='Q1', y='Q2', c='b', s=50)
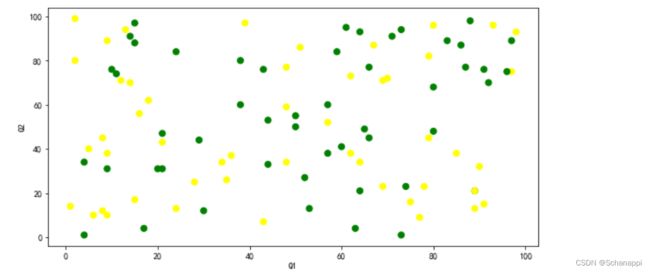
c可以取如下值:
- 字符,RGB或RGBA码,如red、#a98d19;
- 序列,颜色列表,对应每个点的颜色;
- 列名称或位置;
df.plot.scatter(x='Q1', y='Q2', c=['green', 'yellow']*50, s=50)
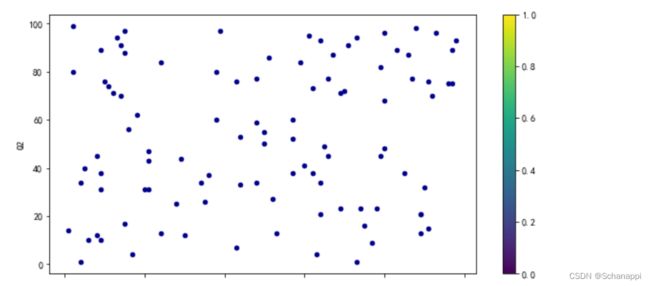
 (3)参数colorbar=True会在当前坐标区或者图的右侧显示一个垂直颜色栏,显示当前颜色图并指示数值到颜色图的映射。
(3)参数colorbar=True会在当前坐标区或者图的右侧显示一个垂直颜色栏,显示当前颜色图并指示数值到颜色图的映射。
df.plot.scatter(x='Q1', y='Q2', c='DarkBlue', colorbar=True)
(4)参数s用于指定点的大小。
16.2.8 六边形分箱图plot.hexbin
六边形分箱图也称六边形箱体图,它是一种以六边形为主要元素的统计图表。它既是散点图的延伸,又兼具直方图和热力图的特征。
df.plot.hexbin()无法使用,找不到原因
使用**DataFrame.plot.hexbin()**创建六边形图。如果数据过于密集,而无法单独绘制每个点,就可以使用六边形图。
# Fail
df = pd.DataFrame(np.random.randn(1000, 2), columns=['a', 'b'])
df['b'] = df['b'] + np.arange(1000)
df.plot.hexbin(x='a', y='b', gridsize=25)