【Redis】Redis集群架构剖析(5):复制与故障转移
在前一篇Redis集群架构剖析中,我们了解了一个集群在槽位转移时,集群的处理动作。这个是针对数据的,其实更多场景下需要考虑的是集群节点,或者自己的分布式集群,节点异常了,集群该如何处理。redis集群对节点的异常就是通过备份,也就是通过复制一个从节点(slave)来备着主节点(master)。在讲解之前,依旧可以先思考下面的问题:
- 集群如何创建一个从节点,备着主节点?
- 集群怎么知道主节点挂了?
- 集群怎么知道从节点的主节点替代成为新的主节点?
- 集群如何存储从节点的信息?
从节点的作用
redis集群中的节点分为主节点(master)和从节点(slave),其中主节点用于处理槽,而从节点则用于复制某个主节点,并在被复制到的主节点下线时,替代下线主节点继续处理请求命令。
举个例子,我们往之前的集群6370,6371,6372添加2个节点6373,6374,并将这个两个节点设置为6371的从节点。
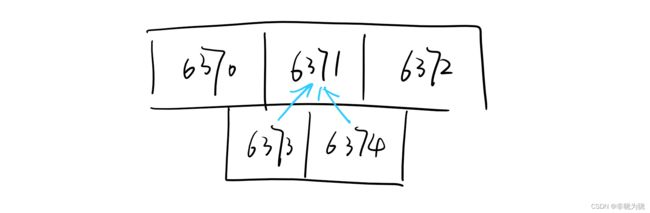
如果此时6371的进入下线状态,那么集群中其他正在运作的节点会从两个从节点中,挑选一个新的节点来接替6371,负责原来6371负责的槽位和数据,并继续处理客户发送的命令请求。
如果节点6374被选为新的主节点,6373也会跟着改成复制节点6374,而不是原来的6371。
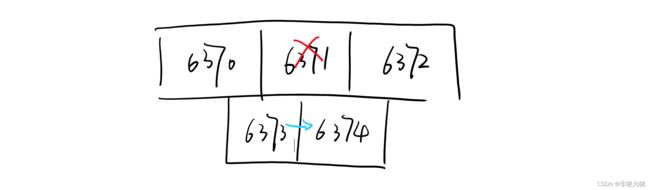
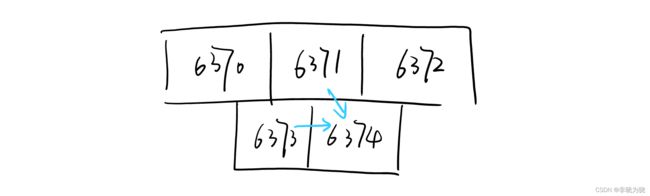
如果在故障转移完之后,下线的节点6371又回来了,那也不能变成主节点,而是成为6374的从节点。
设置从节点
了解了从节点在集群中的运作,那就开始看看从节点的一些细节,首先就是集群如何设置从节点,命令及数据结构。
命令很简单,就是 CLUSTER REPLICATE ,需要注意的是,在哪个节点上面执行这个指令,就表示成为指定node-id所对应节点的从节点。在接收到命令之后,就开始对主节点进行复制:
-
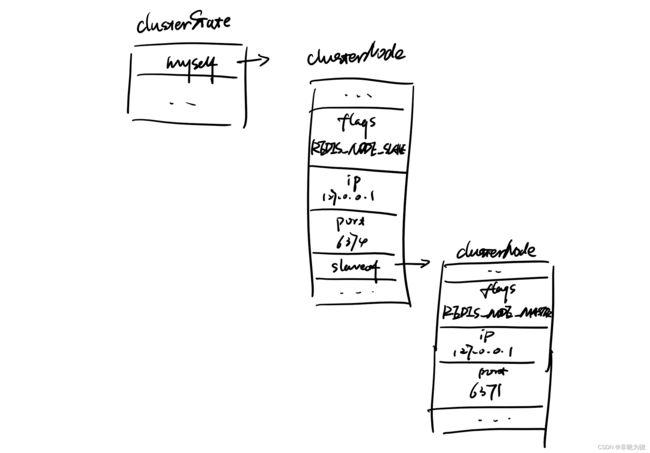
接收到该命令的节点首先会在自己的
clusterState.nodes字典找到对应的node-id的clusterNode,然后把自己的clusterState.myself.slaveof指针指向这个clusterNode,来表示正在复制的主节点struct clusterNode { //... //如果这是一个从节点,那么指向主节点 struct clusterNode *slaveof; //... } -
接着修改该节点的
clusterState.myself.flags的属性,由REDIS_NODE_MASTER(刚加入集群的节点都是这个标识),改为REDIS_NODE_SLAVE -
最后该节点开始调用复制代码,根据
clusterState.myself.slaveof指向的clusterNode结构所保存的IP地址和端口号,对主节点进行复制。
已上面的6374为例:
通知集群有个从节点
从节点的信息,肯定不能只有复制的主节点知道,肯定需要让整个集群都知道,不然在故障时选择主节点的时候,都没有从节点可以选。一个节点成为从节点,并开始复制某个主节点这一信息会通过消息发送给集群中的其他节点,最终集群中的所有节点都会知道某个从节点正在复制某个主节点。
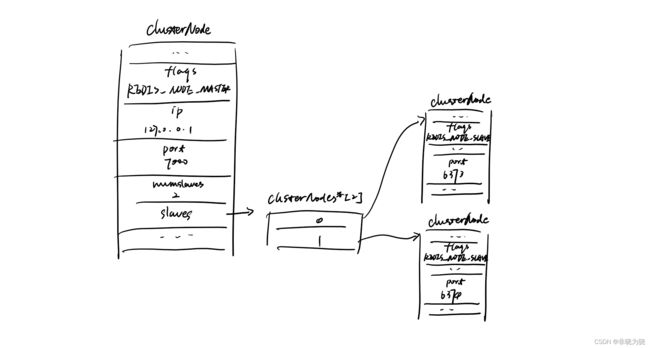
集群中的所有节点都会在clusterState中找到对应clusertNode为这个主节点的结构,并设置其中的slaves和numslaves属性。
struct clusterNode {
//...
//正在复制这个主节点的从节点数量
int numslaves;
// 每个数组项指向一个正在复制这个主节点的从节点的clusterNode结构
struct clusterNode **slaves;
}
还是以上面的例子为例,6373和6374成为6371的从节点,那我们看下6371的clusterNode会是什么样:
故障检测
如何检测集群中的某个主节点下线了呢?最普遍的办法或许就是,过一段就问下,还在不,还在不。如果不在了,就认为它是下线了。看起来很简单,但我们看下redis集群里面是怎么做的。
集群中的每个几点都会定期向集群中的其他节点发送PING消息,以此来检测对方是否在线,如果接受PING消息的节点没有在规定改的时间内,向发送PING消息的节点返回PONG消息,那么发送PING消息的节点就会将接收PING消息的节点标记为疑似下线。
假设说6371向6372发PING消息,6372没有返回PONG消息,那么6371会在clusterState里面找到对应的6372的clusterNode,并把flags改成REDIS_NODE_PFAIL & REDIS_NODE_MASTER。
注意,这里是疑似下线,不是直接就认为是下线了,那怎么算是真的下线了呢?首先我们得先看下,如何让整个集群都知道6372疑似下线了。在之前我们了解到,集群之间节点的状态或者一些数据情况是通过节点之间的消息互通得知的。因此,6370会收到6371发来的消息,6372疑似下线了。那么此时的6370节点会在clusterState中找到6372的clusterNode,并往fail_reports链表加入6372的下线报告。
struct clusterNode{
//...
// 一个链表,记录了所有其他节点对该节点的下线报告
list *fail_reports;
//...
}
每个下线报告的数据结构是:
struct clusterNodeFailReport {
//报告目标节点已经下线的节点
struct clusterNode *node;
//最后一次从node节点收到下线报告的时间,也就是6731
//程序会使用这个时间,来当做下线报告是否过期的时间,因为与当前时间差太多的话,这个下线报告会被删除
mstime_t time;
} typedef clusterNodeFailReport;
通过上面例子可以看一下下线日志是如何记录的,假设6370收到了6371和6374发过来的6372的下线报告,6370的clusterState对应的6372 clusterNode会记录什么数据:
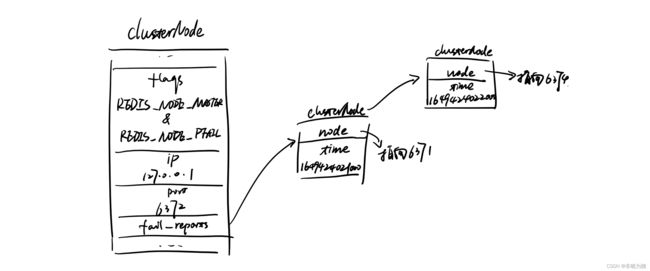
6372的clusterNode的fail_reports就会记录6371和6374发来的下线日志。
了解过分布式算法的朋友应该知道,当集群里面超过半数以上的决策,那么就认为某个结论成立,reids集群认定节点下线也是如此。如果一个集群里面,半数以上负责处理槽的主节点都将某个主节点报告为疑似下线,那么这个主节点将被标记为已下线(FAIL),将该主节点标记为已下线的节点会向集群广播一条关于该主节点下线的FAIL消息,所有收到这条消息的节点就会把该主节点标记为已下线。
故障转移
发现了有故障了,就得转移呀,从节点得用起来呀。
当一个从节点发现自己复制的主节点变成已下线状态后,从节点开始对下线主节点进行故障转移,以下是执行步骤:
这里不细讲是如何从从节点选取一个新的主节点,算法就是Raft算法
- 从下线主节点的从节点里面选一个成为新的主节点;
- 被选中的从节点会执行
SLAVEOF no one命令,成为新的主节点; - 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽位指派给自己;
- 新的主节点会向集群广播一条PONG消息,这条PONG消息可以让集群中的其他节点知道这个节点已经从从节点变为主节点了,并且接管了原来下线节点的槽位。
- 新的主节点开始接收和自己负责处理的槽相关的命令请求,此时故障转移成功。
这篇文档,了解到集群如何给master添加一个slave节点,通过固定间隔时间的PING来探测节点是否存活,如果检测到节点下线后,又通过故障转移的操作让从节点成为新的主节点。可见,集群节点之间的消息传递是何等重要,自己在设计集群的时候,探活方式,故障转移的方式也及其之重要。至此,redis的系列文章已经完结,欢迎留言探讨,之后还会出一些其他的关于redis或者其他架构的系列文章,感谢所有的读者。
系列文章:
- 【Redis】Redis集群架构剖析(1):认识cluster
- 【Redis】Redis集群架构剖析(2):槽位
- 【Redis】Redis集群架构剖析(3):集群处理redis-cli指令
- 【Redis】Redis集群架构剖析(4):槽位迁移,重新分配