详解带头双向循环链表(精美图示哦)

全文目录
- 引言
- 带头双向循环链表
- 接口实现
-
- 链表的创建与销毁
-
- 创建
- 销毁
- 链表的打印
- 链表的头插与头删
-
- 头插
- 头删
- 链表的尾插与尾删
-
- 尾插
- 尾删
- 链表的查找
- 链表在pos位置插入/删除
-
- 插入
- 删除
- 总结
引言
之前我们了解了顺序表与单链表的相关知识,实现了使用它们进行对数据的管理,并且了解了它们在管理数据时的异同:
戳我看顺序表详解哦
戳我看单链表详解哦
虽然单链表相对于顺序表来说,管理数据时会更加高效,但是也存在着一些缺陷:单链表不能从后向前访问数据,使要在pos位置增删数据时不方便;单链表没有头节点,链表为空时的判断与赋值会比较麻烦,需要传二级指针;单链表找尾结点需要遍历等。
在这篇文章中将介绍一种复杂的链表:带头双向循环链表。并且实现带头双向循环链表对数据的管理。这种链表可以解决上面说的单链表的一些缺陷。掌握之后,就可以理解各种链表的类型了:
带头双向循环链表
在学习链表时,我们就知道链表分为单向和双向、带头和不带头、循环和非循环等。将它们排列组合后,一共可以有8种不同的链表类型,其中最简单的即无头单向非循环链表(单链表),最复杂的就是带头双向循环链表:
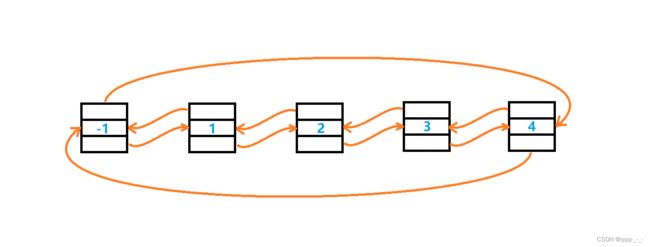
它的每一个结点有三个成员:包括一个人成员存放数据,两个结构体指针存放前一个结点的指针与后一个结点的指针:
typedef int LTDataType;
typedef struct ListNode
{
LTDataType _data;
struct ListNode* _next;
struct ListNode* _prev;
}ListNode;
第一个结点是头结点,它不用来存储有效数据。它的_prev成员指向链表的最后一个结点;
最后一个结点的_next成员指向头节点:
在了解带头双向循环链表的结构后,就可以尝试实现一下使用带头双向循环链表对数据进行管理:
接口实现
链表的创建与销毁
创建
头结点的结构与链表中的其他结构是相同的,所以我们先来实现这个动态申请结点的函数,这个函数的参数x为该结点将要赋的值:
首先我们需要动态开辟一块大小为结构体大小的空间,并断言是否成功开辟:
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
assert(newnode);
然后对开辟的空间初始化。即将_data成员初始化为x;然后将结点中的两个指针成员全部初始化为NULL;最后返回创建好的结点的指针:
// 动态申请一个节点
ListNode* BuySListNode(LTDataType x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
assert(newnode);
newnode->_data = x;
newnode->_next = NULL;
newnode->_prev = NULL;
return newnode;
}
对于带头双向循环链表,我们不仅需要创建每一个存储数据的结点,还需要再创建一个哨兵位的头节点。
所以在创建存储数据的结点之外,我们还需要创建一个哨兵位的头节点,并将其初始化:
首先使用上面的创建结点函数,创建一个值为-1的结点,我们需要让这个头节点的_prev成员指向它自己;_next成员也指向它本身。
然后返回头结点的地址:
// 创建返回链表的头结点.
ListNode* ListCreate()
{
ListNode* pHead = BuySListNode(-1);
pHead->_prev = pHead;
pHead->_next = pHead;
return pHead;
}
销毁
销毁双向带头循环链表时,由于它可以比较容易的访问到前一个结点,所以在销毁每一个结点时会比较方便:
while循环,cur初始化为pHead->_next结点,每次循环销毁cur->_prev指向的结点即可,当cur与哨兵位的头节点相等时即由最后一个结点访问到了头节点,结束循环。
但是由于结束循环时,链表的最后一个结点还没有被释放,且已经不能通过头节点访问最后一个结点。所以先使用一个指针存储最后一个结点的位置,循环结束后单独释放即可:

// 双向链表销毁
void ListDestory(ListNode* pHead)
{
ListNode* cur = pHead->_next;
ListNode* tail = pHead->_prev;
while (cur != pHead)
{
free(cur->_prev);
cur = cur->_next;
}
free(tail);
}
链表的打印
打印时,与单链表相同,只需要遍历整个链表并打印每一个结点的数据即可。但是循环结束的条件与单链表不同:当cur指针等于pHead时,即已经遍历一圈结束,循环结束:
// 双向链表打印
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->_next;
while (cur != pHead)
{
printf("%d ", cur->_data);
cur = cur->_next;
}
printf("\n");
}
链表的头插与头删
头插
双向带头链表头插时,在创建新结点后,需要改变4个指针的指向:
第二个结点的_prev成员、新结点的_next与_prev成员、头结点的_next成员。但是由于如果先改变头节点的_next成员后,就不能访问到第二个结点,所以这一步要放在最后。
我们先将pHead->_next->_prev 改为 newnode,即连接原第二个结点与新结点;然后将newnode->_next 改为pHead->_next,即连接新结点与原第二个结点;然后将newnode->_prev 改为 pHead,即连接新结点与头节点;最后将pHead->_next 改为newnode,即连接头结点与新结点:
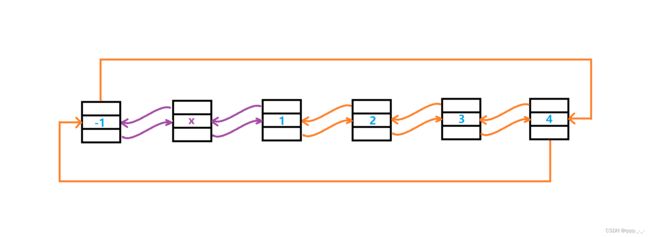
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x)
{
ListNode* newnode = BuySListNode(x);
pHead->_next->_prev = newnode;
newnode->_next = pHead->_next;
newnode->_prev = pHead;
pHead->_next = newnode;
}
头删
头删时,只需要将pHead->_next->_next->_prev 改为 pHead,即让第三个结点的_prev指向头结点;然后将pHead->_next 改为 pHead->_next->_next,即头节点的_next成员指向第三个结点即可。
但是由于改动了头结点的_next成员后,就不能访问到第二个元素了来释放它了,所以我们可以先将第二个结点的指针存下来,方便改动后进行释放:
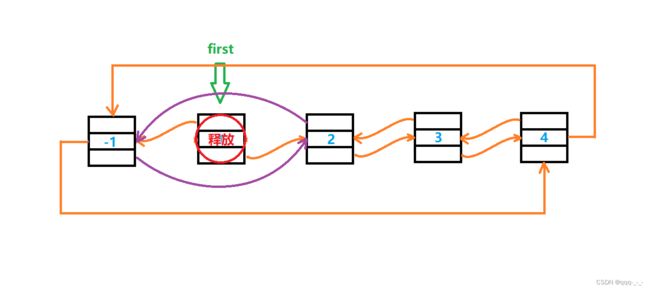
// 双向链表头删
void ListPopFront(ListNode* pHead)
{
if (pHead->_prev == pHead)
{
return;
}
ListNode* first = pHead->_next;
pHead->_next->_next->_prev = pHead;
pHead->_next = pHead->_next->_next;
free(first);
}
链表的尾插与尾删
单链表尾插尾删时,需要遍历找到尾结点。但是双向带头循环链表可以由头结点访问到末尾的结点,实现起来也更加容易:
尾插
尾插时,在创建新结点后,也需要改变4个指针的指向:
尾结点的_next成员、新结点的_next与_prev成员、头结点的_prev成员。但是由于如果先改变头节点的_prev成员后,就不能访问到最后一个结点,所以这一步要放在最后。
我们先将pHead->_prev->_next 改为 newnode,即连接原尾结点与新结点;然后将newnode->_prev 改为 pHead->_prev,即连接新结点与原尾结点;然后将newnode->_next 改为 pHead,即连接头结点与新结点;最后将pHead->_prev 改为 newnode,即连接头结点与新结点:
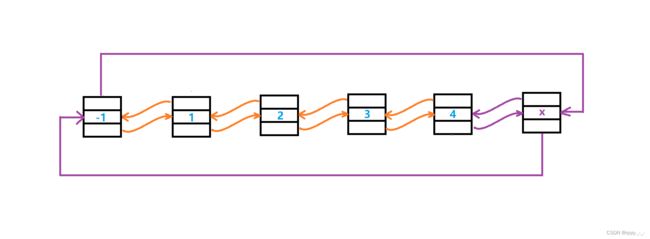
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* newnode = BuySListNode(x);
pHead->_prev->_next = newnode;
newnode->_prev = pHead->_prev;
newnode->_next = pHead;
pHead->_prev = newnode;
}
尾删
尾删时,只需要将pHead->_prev->_prev->_next 改为 pHead,即倒数第二个元素的_next成员改为头节点;然后将pHead->_prev 改为 pHead->_prev->_prev,即头节点的_prev成员改为倒数第二个结点即可。
但是由于改变头节点的_prev成员后,就不能访问并释放最后一个结点了。所以在改变之前先将尾结点的地址存储,最后free释放即可:

// 双向链表尾删
void ListPopBack(ListNode* pHead)
{
if (pHead->_prev == pHead)
{
return;
}
pHead->_prev->_prev->_next = pHead;
ListNode* tail = pHead->_prev;
pHead->_prev = pHead->_prev->_prev;
free(tail);
}
链表的查找
之后,我们就会想到要删除链表中指定的结点。
在删除指定的结点之前,我们首先需要实现一个算法,通过结点中的_data成员找到这个节点的位置。并返回这个节点的指针。
只需要遍历链表,将结构体指针cur依次后移即可。当cur->_data的值为x时,返回cur。
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
ListNode* cur = pHead->_next;
while (cur != pHead)
{
if (cur->_data == x)
{
return cur;
}
cur = cur->_next;
}
return NULL;
}
链表在pos位置插入/删除
在获取到了pos后,我们就能实现在pos位置进行插入或删除。
由于单链表中不能由pos访问到前一个结点的地址,所以想要实现在pos位置插入或删除,就需要再从头遍历找到pos位置前面的结点。
但是双向带头循环链表可以由pos访问到前一个结点,这就让在pos位置插入或删除变得简单:
插入
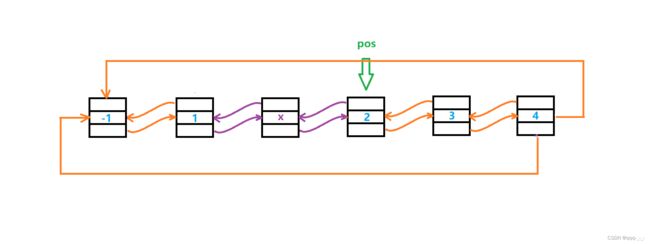
在pos位置插入时,在创建新结点后,同样需要改变4个指针变量的指向:
首先将pos->_prev->_next 改为 newnode,即让pos前面一个结点的_next指向新结点;然后将newnode->_next 改为 pos,即让新结点的与pos连接;然后将newnode->_prev 改为 pos->_prev,即让新结点与pos前面的结点连接;最后将pos->_prev 改为 newnode,即让pos与新结点连接。
由于改变pos的_prev成员后,就不能访问到pos的前一个结点,所以这一步需要放在最后:
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* newnode = BuySListNode(x);
pos->_prev->_next = newnode;
newnode->_next = pos;
newnode->_prev = pos->_prev;
pos->_prev = newnode;
}
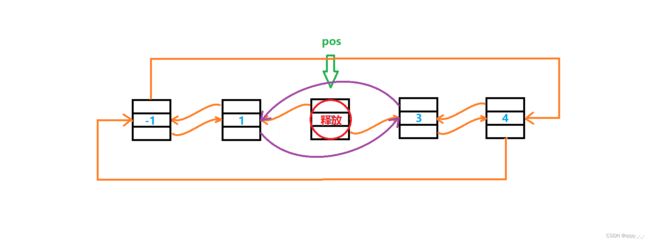
删除
删除pos位置的结点时,只需要将pos->_prev->_next 改为 pos->_next,即让pos前面的结点与pos后面的结点连接;然后将pos->_next->_prev 改为 pos->_prev,即让pos后面的结点与pos前面的结点连接即可。
最后,再释放pos:
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{
assert(pos);
pos->_prev->_next = pos->_next;
pos->_next->_prev = pos->_prev;
free(pos);
}
总结
到此,关于双向带头链表的介绍就结束了
同时,对于链表的知识也就结束了,相信大家都对链表这个数据结构有了一定的理解
如果大家认为我对某一部分没有介绍清楚或者某一部分出了问题,欢迎大家在评论区提出
如果本文对你有帮助,希望一键三连哦
希望与大家共同进步哦