如何在微服务架构下进行数据设计?
作者:唐建法 && Mongoing中文社区
来自:http://www.mongoing.com/
微服务是一个软件架构模式,对微服务的讨论大多集中在容器或其他技术是否能很好的实施微服务这些方面。
本文将从以下几个角度来和大家分享在微服务架构下进行数据设计需要关注的地方,旨在帮助大家在构建微服务架构时,提供一个数据方面的视角:
什么是微服务
微服务的优势及架构特点
微服务架构下的数据设计
一个适合微服务架构的数据库
1 什么是微服务
按照 Martin Fowler 的定义,微服务是一个软件架构模式,通过开发一系列的小型服务的方式来实现一个应用。每一个这样的小服务通常都是运行在自己的进程里面,并且通过轻量级的HTTP API 方式进行通讯。
这些服务通常会以业务模块为界限,能够被单独开发部署,往往都会用自动化的部署工具来进行产品的发布。通过使用微服务方法,大公司可以更快推出新产品和服务,使得开发团队与业务目标保持一致。
2 微服务的优势
微服务方法体现出许多优势,包括更快的上线时间、灵活性、弹性、一致性以及相对更低的成本。
更快的上线时间
实施微服务架构可以使组织更快地将应用程序推向市场。对整体应用程序的更改(即使很小)需要重新部署整个应用程序堆栈,从而引入风险和复杂性。
相反,服务的更新可以立即提交、测试和部署,对个别服务的更改不会影响系统的其他部分。
更好的灵活性和可扩展性
微服务方法在扩展应用程序时也提供了灵活性。单片应用程序要求整个系统(及其所有功能)同时扩展。
使用微服务,只需要缩放需要额外性能的组件或功能。可以通过部署更多微服务实例来扩展服务范围,从而实现更有效的容量规划并降低软件许可成本,从而降低总体拥有成本。
弹性
使用单体应用程序时,组件的故障可能会危及整个应用程序。在微服务中,每项服务都是隔离的,以防止级联失败导致整个系统崩溃。如果单个微服务的所有实例均失败,则整体服务可能会降级,但其他组件仍可提供有价值的服务。
更容易的规模化
微服务使技术团队能够与组织需求保持一致,并且可以调整团队的大小以匹配所需的任务。通常,微服务团队规模较小,但是跨部门(如一般涵盖Ops、Dev、QA),并专注于整个应用程序的单个组件。
通过提供对个人服务的所有权,而不是功能区域,微服务还可以打破团队之间的孤岛,并改善协作。这种方法对于分布式和远程团队尤其强大。 例如,不同地点的团队可以独立发布和部署功能。
让我们通过一个例子来了解微服务架构的技术特点。联邦银行的架构师 Jonnathan 非常不喜欢他的产品经理 Mandy,因为他觉得 Mandy 永远有无穷无尽的想法要实现,搞得他成天就在不断地修改代码。
但是 Mandy 是老板的红人,而且用户对产品的反响也不错,所以很多时候他只能默默的服从。这一天 Mandy 又成功的说服了老板要在他们的客户体验提升项目中增加舆情分析和 AI 客户服务模块,希望通过对社交媒体上有关联邦银行的所有评论进行实时的监控和分析来及时发现联邦银行的产品反馈或者用户体验问题。
Jonnathan已经预感到了这样前所未有的应用场景,会有太多的未知和太多的改变,于是这次决定尝试使用 Microservices 来构建这个应用。这个是 Jonnathan 设计的架构,系统要求对客户的社交账号,如Facebook、Twitter、Google+ 及 Snapchat 公开的信息及评论进行收集,并在某些合适的时候使用 AI 技术直接和用户通过社交工具进行互动。
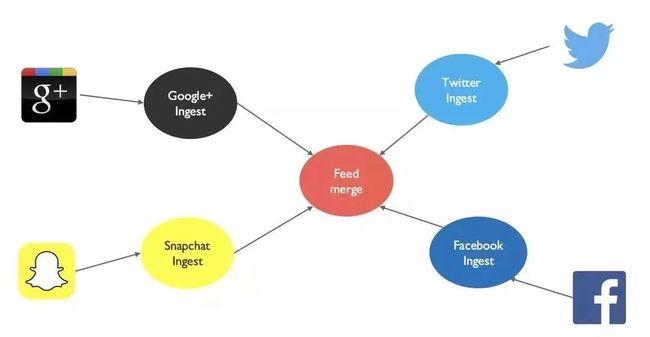
在上图这个架构里面,Jonnathan 把4个不同社交媒体的数据采集和交互用 4 个独立的模块进行实现。并用一个 Feed Merge 服务,一个 Aggregate Service 把 4 个类似功能的微服务模块的数据和功能进行整合,提供给分析平台使用。
这里面每一个服务按照微服务的架构,每一个都是单独部署,在一个独立的容器内执行,并使用自己的一个数据库。
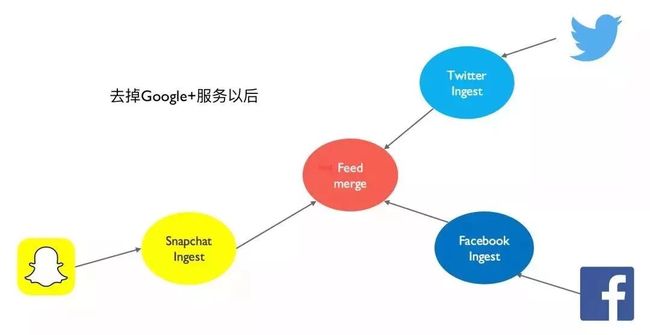
果不其然,系统上线一段时间后,Mandy 说 Google+ 上面几乎没有什么活动,不值得继续维护这样的一套系统。Jonnathan 这次毫无抱怨,直接把负责 Google+ 的容器停了,没有需要任何代码改动,甚至完全没有需要对整个系统进行停机。
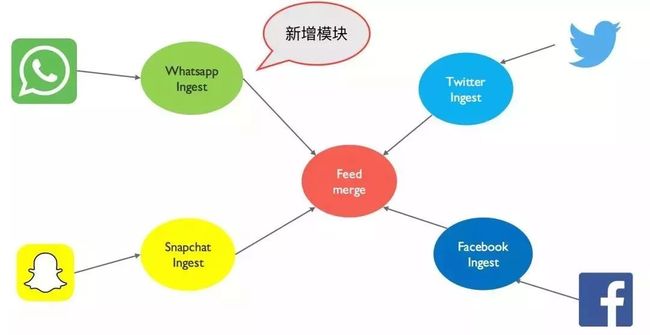
刚下线 Google+,Mandy 又来提需求说最近合并了另一家银行,客户很多使用 Whatsapp。二话不说,Jonnathan 直接上了一个新的模块来处理 Whatsapp ,如下图。
又过了一段时间,这一次是他自己要对系统做调整了,原来 Snapchat 最近大火,他部署的系统频受压力,性能下降。为了解决这个问题,Jonnathan 果断增加了额外 2 台容器来同时支撑 Snapchat 信息的采集和处理。
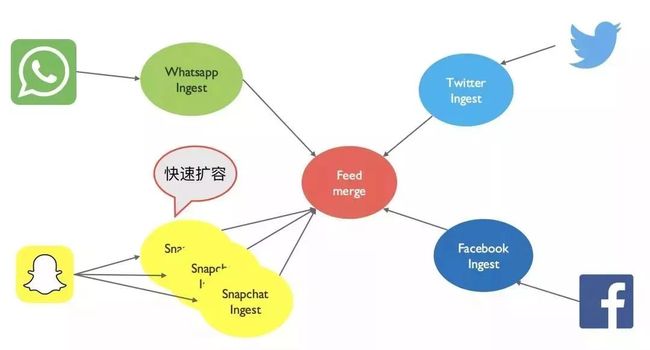
感谢微服务架构,Jonnathan 在一系列的产品需求变化以及系统扩容需求下,可以从容应付。要实现微服务架构,需要你铭记以下几个微服务架构的应用设计原则。
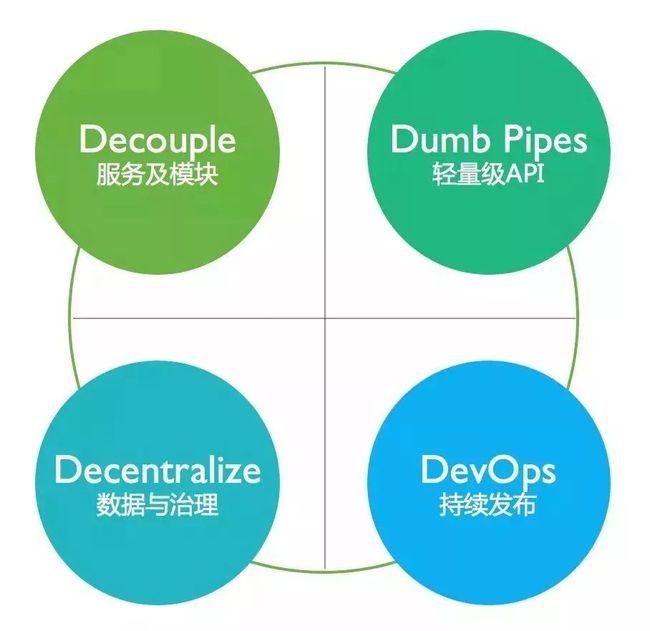
解耦
在微服务架构中,应用程序被分解为小型的独立服务。服务通常专注于特定的离散目标或功能,并沿着业务边界解耦。按业务界限分离服务可让团队专注于正确的目标,并确保服务之间的自主性。
每项服务都是独立开发,测试和部署的,服务通常是作为独立的进程或软件容器分开的,通过网络和商定的 API 进行通信,尽管在某些情况下,网络可能在本地。通常部署相同微服务的多个实例,从而提供冗余和可扩展性。
轻量级 API
微服务之间的通信要使用轻量级 API,如 HTTP RESTful API。这样可以使得服务对 API 通信方案的依赖减到最小。
复杂的通信处理要在服务端进行,而不是像 ESB 或者 Data Pipeline 处理总线那样在数据传输过程中引入非常多的逻辑,导致微服务模块紧紧的绑定在这个数据管道上。
持续发布
微服务架构带来的一个非常显著的负面性就是众多实例的测试发布及管理。传统应用虽然开发复杂,但是部署和运维相对比较集中,一台数据库,2-4 个应用服务器就差不多了。但是微服务架构下单独服务的数量轻则 10-20,多则上百个,所以微服务架构一般需要配套的 CI/CD 方法来支撑。
数据与治理
数据的管理在微服务架构下也是和传统单体有很大的不同考量。大部分时候我们希望数据就和服务一样,要有充分的独立性,可以和某个服务一起部署,一起扩展,或者一起重构。
这通常意味着我们可能要在一个微服务架构应用内使用多个数据库实例。但是同样需要考虑到数据分布在多实例之间以后,往往还需要一些冗余,以及如何保持这些数据在这些系统中的一致性等问题。下面我们就着重来讨论微服务架构下的数据设计的一些考量因素。
4 微服务架构下的数据设计
从来没有一个 one-size-fits-all 的架构,所以在微服务架构下面,我们需要了解的,一样是几个关键的架构考量点。然后针对自己的实际应用,选择哪些考量点是更加重要的。
这篇文章的目的,主要就是跟大家来讨论从哪几个角度着手,来设计一个符合微服务架构原则的数据架构。比如说,我们可以从一系列的问题来开始这个讨论。
这么多微服务之间,我是否可以用一个数据库,还是多个数据库来支持多个微服务?
如果是多个数据库,我是否为每一个微服务挑选一个最合适的数据库,还是选择同一种类型的数据库?
我如何在微服务架构下扩展我的数据库?
当一个我依赖的服务需要修改数据库 Schema 的时候,是否会影响到我?
当微服务应用不断衍变的时候,我的数据库是否可以快速的响应应用需求变化?以上这些就是我们在微服务数据架构时候要关注的地方。
一库一服还是一库多服
无论是单体应用,还是微服务应用,有一点是肯定的:应用的各个模块之间都需要进行较为频繁的通信,通过一起协同合作,来实现应用的整体价值。
在单体应用中,这种通信是通过方法调用来完成的。在微服务中,则通过 API 调用来完成。这些模块或者服务间调用,大部分时候是为了共享数据。
共享数据最贱的方式当然就是采用一种共享数据库的模式,也就是单体应用常用的方式。应用可以有多个系统模块,但一般都是只有一个数据库。如下图左边,3 个微服务模块,后面共享一个数据库,简称一库多服务。
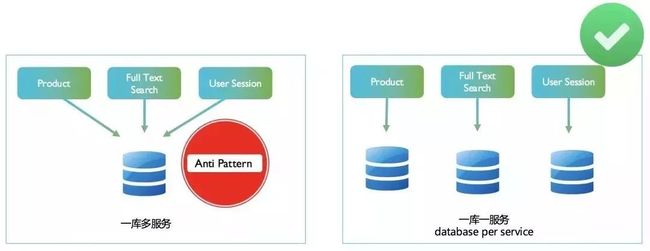
这种架构模式通常会被认为是微服务架构下的反范式,它的问题在于:
单点故障:一个数据库倒下,整批服务全部停止。何来的服务独立性?
数据在同一个地方,会给贪图方便的开发或者 DBA 工程师编写很多数据间高度依赖的程序或者工具。
无法针对某一个服务进行精准优化或扩展,如上文所讲的 Snapchat 的例子。
所以一般推荐的做法,是为每一个微服务准备一个单独的数据库,也即一库一服(Database per Service)模式。如上图右侧所示。这种模式更加适合微服务架构,它满足每一个服务是独立开发、独立部署、独立扩展的特性。
需要对一个服务进行升级或者数据架构改动的时候,不会影响到其他的服务。需要对某个服务进行扩展的时候,也可以手术式的对某一个服务进行局部扩容。另外,如果某些服务对数据库有特殊的需求,这种模式也为下文所讲的混合持久化(Polyglot Persistence)提供了可能性。
混合持久化 vs 多模数据库
混合持久化在大型互联网公司是一个比较风行的模式。它秉承的原则就是为特别的任务提供最好的工具。比如说,如果我希望提供一个高并发低延迟的共享用户会话方案(Shared Session Storage), Redis 可能是一个非常理想的选择。
如果我是在实现一个产品目录,涉及到大量不定结构的商品数据及属性的建模管理,我可能会采用模式灵活,动态 Schema 的 MongoDB 来作为我的数据库解决方案。如果我希望支持非常强大的全文搜索,ElasticSearch 则是行业中的佼佼者。
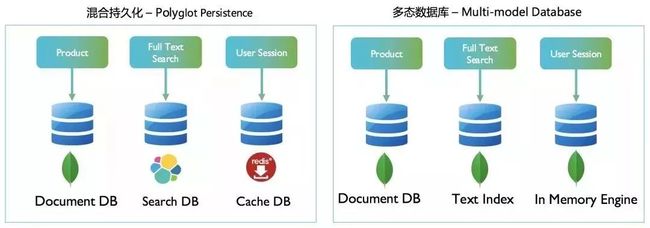
微服务的功能分块独立部署为这种架构模式提供了非常好的基础,如上图左侧所示就是个典型的混合持久化的案例:
混合持久化:Polyglot Persistence
多模数据库:Multi- model Database
当然,有句话说的是架构师的工作就是每天做不断的取舍(Trade Off),因为选择往往是让人很纠结。混合持久化的优势很明显,可以让每个单独的服务使用到最佳的工具和技术。
但是它的弊端也是不容忽视:部署、监控、备份、升级等数据库管理工作从来都是一件困难但是重要的任务。引入多个不同的数据库,也意味着对系统管理维护的复杂度和成本提高了很多。
这种情况下可能需要比较有资源的公司或者团队才可以使用。这也解释了这个模式为何在大型互联网公司得到较多的采用与推广。
针对于其他小型规模的用户,或者是缺乏足够掌握各种新型技术人才的公司来说,另一种更为可行的模式可能是多模数据库(Multi-model)。如上图右侧所示,多模数据库的特征是:
依然是一库一服务(为一个服务部署一个单独的数据库)。
但是使用的是同一种类型,支持多种场景的数据库,如 NoSQL 中间为功能最全面的 MongoDB。
虽然是多实例,但是只需维护一种类型的数据库,管理上和人员配备上都较为简单。
如果你在开发的应用是一款企业级产品,会交付到客户环境部署安装,则运维管理的简单性将在技术选型中占据非常重要的一个比重,无疑这种情况下多模数据库更加适用。
微服务扩展你的数据
微服务架构的一大裨益是其灵活的扩展性。以上面的 Snapchat 为例,如果需要采集或处理的数据量快速增长,在我们增加应用服务实例的同时,支撑数据存储的模块也要相应扩充。
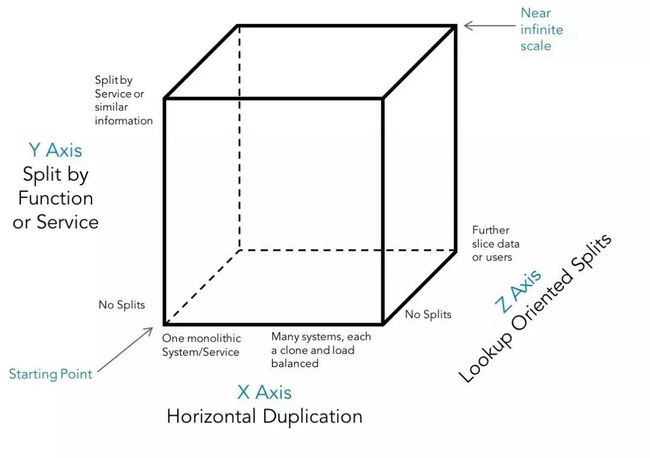
AFK Partners 在他们的 Scale Cube 一文里对性能扩展提出了这样的观点,要设计一个真正意义上的可扩展系统,我们必须考虑3个维度,如上图所示:
X 轴,系统复制(横向扩展)
Y 轴,非重叠功能的拆分(微服务)
Z 轴,数据的分区(Sharding)
一个好的数据架构,在微服务体系内,应该具有同样的可扩展、易扩展性质,从而不给微服务架构拖后腿。关于数据分区扩展有两种做法:
应用数据分区
数据库分区
应用数据分区,顾名思义,就是在应用端对数据的存储进行分区管理。比如说,一个社交应用可以按国家或地区为界把用户的数据分发到不同数据库实例里面。这样的话每个数据库实例只需要存储一部分数据,从而实现海量的数据管理能力。
数据库分区,就是由数据库的路由节点来完成数据分区的任务。数据库分区的优势是显然的,它对应用透明、扩展快速、无须下线等。如果你的应用有潜在扩充的需求,选择一个能够自动扩展的分布式数据库是一个比较明智的选择。
动态模式支持及快速开发能力
这是一个很多架构师可能会忽略,但是非常重要的关注点。我们在迭代式开发 DevOps 微服务上的很多努力,都是为了快速开发,快速上线,以及快速响应变化的需求。
从数据架构师的角度来看,如何不成为在这个快速开发方法模式中的一个瓶颈,有一个很重要的环节就是是否有一个能够及时响应变化的数据模型。
传统的数据库都是强模式,需要对 Schema 进行清晰定义, 在需求修改导致模型修改的时候需要对数据库进行模式升级,是一个需要下线、耗时并且是高成本的运维操作。

在新一代的 NoSQL 数据库产生之前,我们并不需要考虑这个问题,但是以 MongoDB、Cassandra 等为代表的 NoSQL 代表的是灵活建模。
动态支持模式变化的特征使得它们成为敏捷开发和微服务体系内一个有力的竞争者,在选型的时候也是一个重要的考量因素之一。我们说一库一服的架构使得对一个服务的数据库模式修改不会影响到其他服务。
但是如果使用一个动态模式(有时候有人会说无模式)的数据库,则在该服务本身模式修改的时候也可以最小化运维成本。
一个适合微服务架构的数据库
红杉资本的合伙人 Matt Miller 是公认的微服务技术领域专家。他广被传播的“微服务生态图”详尽的列出了微服务架构的相关技术栈。在这里他推荐了 MongoDB 作为主要的数据管理方案。

MongoDB 是一个分布式文档型数据库,它有以下特性使它非常适合于微服务架构,其主要特点包括: 多模数据库(Multi-model)、原生 JSON 数据结构API、动态模式、无模式(Dynamic schema)、数据变化流(Change Stream)、横向扩展能力(Sharding)。
多模数据库
MongoDB 从 3.4 版本起在多模数据库场景上提供了不少功能模块,比如说,使用聚合框架。现在开发者可以使用:
$graphLookup 来实现类似于图数据库的查询。
$facet 来实现分面搜索。
内存引擎功能,用于支持类似于 Redis 的高速缓存。
全文检索,用于实现搜索类型场景。
动态模式
这一点一直是 MongoDB 获得开发者青睐的主要原因之一。MongoDB 无须显式的定义数据模式即可让你开始往数据库写入。
当数据模型有变化时候,比如说在迭代式开发中非常常见的就是增加一些字段,MongoDB 数据库不需要对其进行修改 Schema 操作,而是可以直接在同一个集合(表)里直接写入新版本的文档。这个对于需要实现快速迭代,快速交付的微服务应用开发是一个非常重要的特性。
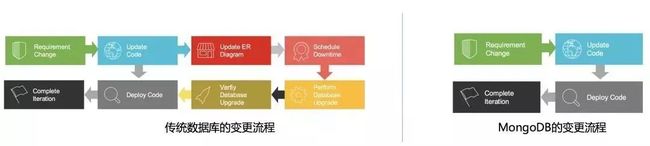
数据变化流
微服务架构中由于其分布特性,传统的强事务机制不再适用。数据的一致性一般需要通过一些基于 Event Sourcing 或者事件驱动模型的解决方案。Mongo DB 3.6 版本推出的数据更改流,可以用来实现一个类似于 Kafak 一样的 Message Queue,为各个微服务间的数据协调提供一个简单易用的线程方案。
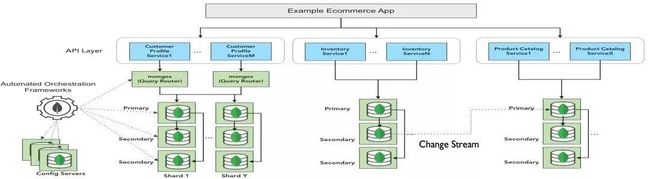
横向扩展能力
MongoDB 一向以其强大的横向扩展能力著称。不少 MongoDB 用户迁移的主要原因就是使用 MongoDB 的 Sharding 技术可以突破关系型数据库在数据量和性能上的瓶颈。

MongoDB 的 Sharding 有几个特征使得其非常适合微服务架构使用:
弹性扩展:可以扩容也可以缩容。
无缝扩展:无须停机,就可在线扩容。
自动均衡:无须应用参与即可实现数据的自动均衡,完全透明。一个基于 MongoDB 的微服务参考架构图。
陛下...看完奏折,点个赞再走吧!
