162.Hadoop(一):Hadoop基本概念,基本环境安装,单机运行,各虚拟机数据同步
目录
一、Hadoop基本概念
1.什么是Hadoop
2.Hadoop的优势
3.Hadoop组成
4.HDFS概述
5.YARN概述
6.MapReduce概述
7 大数据整体的技术栈学历路径
二、基本环境搭建
1.配置虚拟机
2.配置镜像
3.配置ip和主机名称
4.模板虚拟机
5.克隆虚拟机
6. 仅hadoop102中安装jdk
7.仅安装hadoop102安装hadoop
三、执行本地运行模式
四、各虚拟机之间数据同步
1.通过scp/rsync将102的jdk,hadoop复制到103,104
2.xsync循环复制文件到所有节点的相同目录下(重要)
3.免密登录
一、Hadoop基本概念
1.什么是Hadoop
Hadoop是Apache开发的分布式系统基础架构,主要用于解决海量数据的存储和分析计算。
2.Hadoop的优势
(1)高可用:数据副本
(2)高拓展性:集群
(3)高效性:并行工作
(4)高容错性:失败重试
3.Hadoop组成
Hadoop有1.X,2.X,3.X三个版本
(1)Hadoop1.X
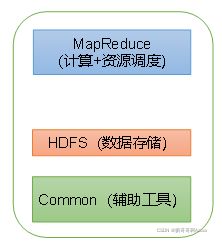
(2)Hadoop2.X
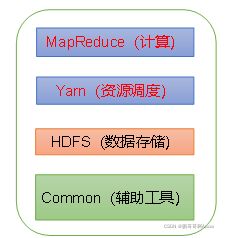
Hadoop3.X和Hadoop2.X组成上一样
4.HDFS概述
HDFS是一个分布式文件系统。
HDFS = NameNode + DataNode + Secondary NameNode
(1)NameNode
存储元数据(对具体的数据的描述的数据),每个文件的块列表,块所在的DataNode。
可以简单的理解为对DataNode的描述信息
(2)DataNode
在本地文件系统存储文件块数据,以及数据的校验。
可以简单理解为存放具体的数据
(3)Secondary NameNode
每隔一段时间对NameNode备份
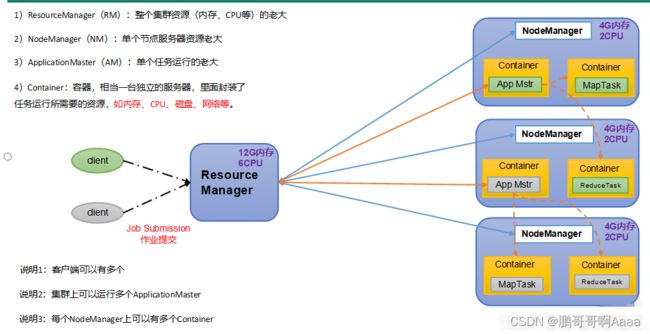
5.YARN概述
YARN是资源协调者,是Hadoop的资源管理者。
YARN = ResourceManager + NodeManager + ApplicationMaster + Container
(1)ResourceManager:管理整个集群的资源(cpu,内存)
(2)NodeManager:管理单个节点服务器的资源
(3)ApplicationMaster:管理单个任务的资源
(4)Container:容器,一个任务可能会需要调用多个相关资源,每个资源被封装成一个虚拟服务器,即容器,供任务调用
注1:客户端可以有多个
注2:集群上可以有多个ApplicationMaster
注3:每个NodeManager可以有多个Container
6.MapReduce概述
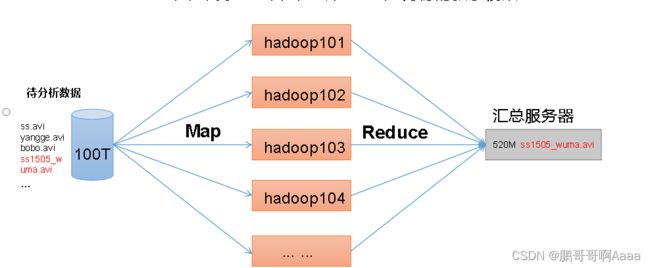
MapReduce用于数据的处理。
MapReduce = Map + Reduce
(1)Map
并行处理输入的数据
(2)Reduce
对Map阶段并行处理的数据进行汇总
7 大数据整体的技术栈学历路径

二、基本环境搭建
1.配置虚拟机
虚拟机是15.5
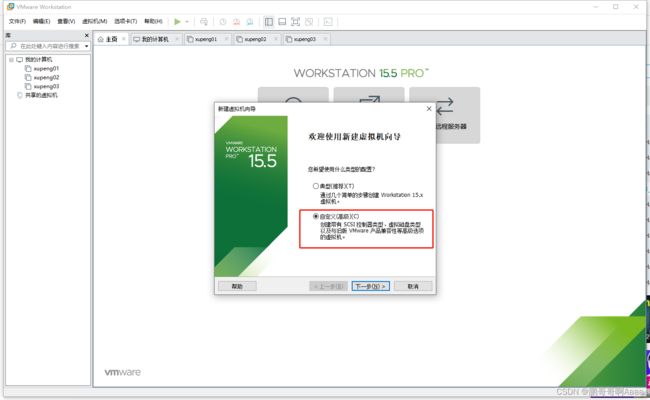
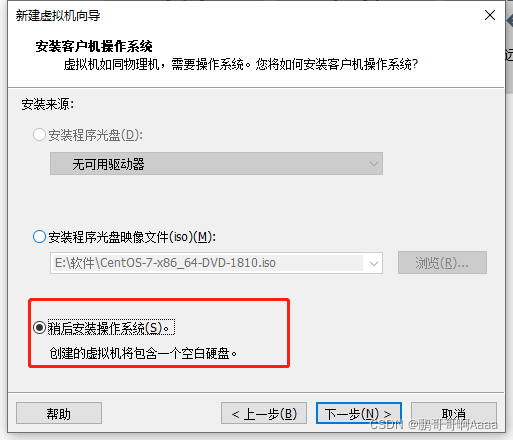
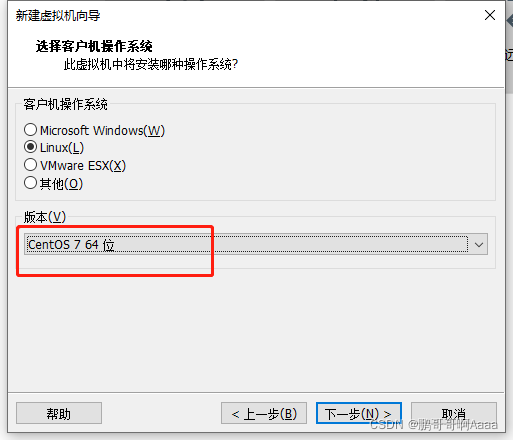
这边声明一下,我们之前也有安装虚拟机的教程,当时使用的是红帽版本,这边使用centos 7 :
然后是配置cpu核数,这个每个电脑不一样,可以参考如下方法:
可以看到,我的cpu是12核,
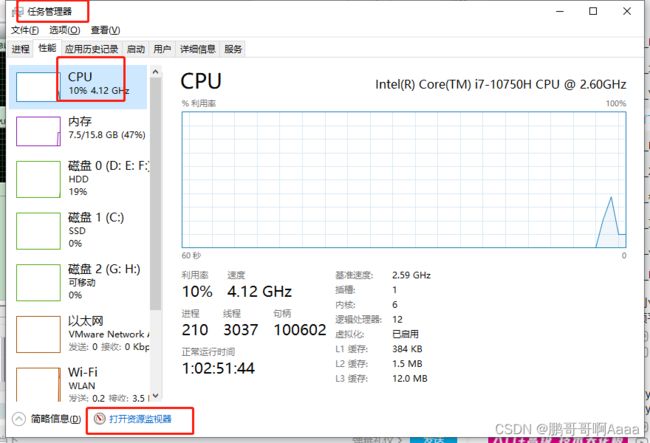
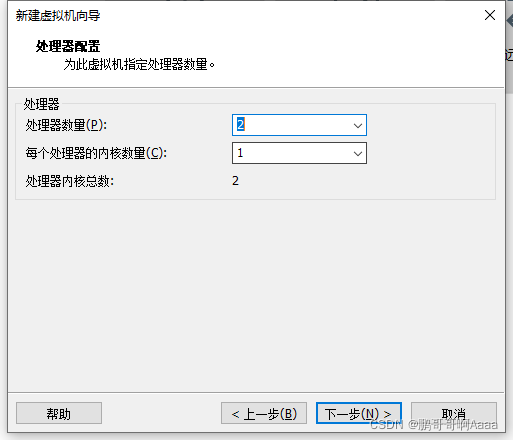
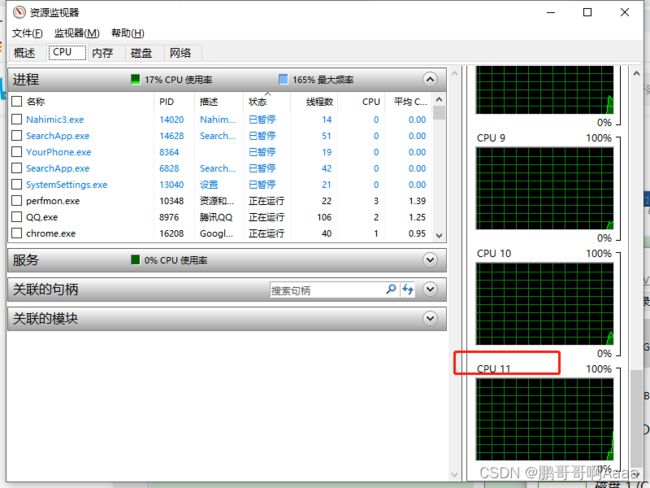 因为我的cpu核一共12个,我们一般会用3个虚拟机,外加windows,所以要分成4个用,一个平均占3个,处理器数量一般给2,所以每个处理器只能1核了:(如果你16核,就2*2)
因为我的cpu核一共12个,我们一般会用3个虚拟机,外加windows,所以要分成4个用,一个平均占3个,处理器数量一般给2,所以每个处理器只能1核了:(如果你16核,就2*2)
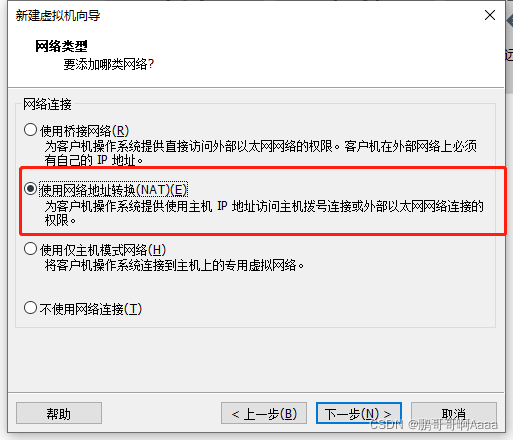

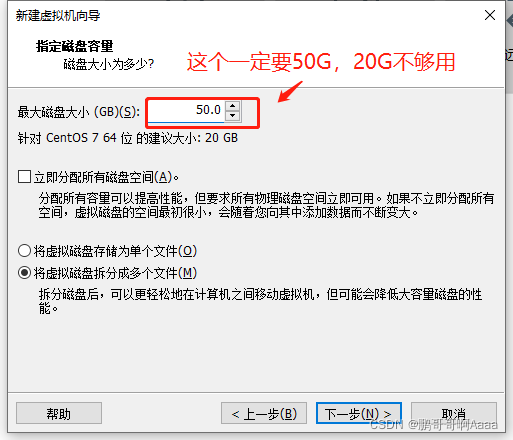
打开虚拟化:
2.配置镜像
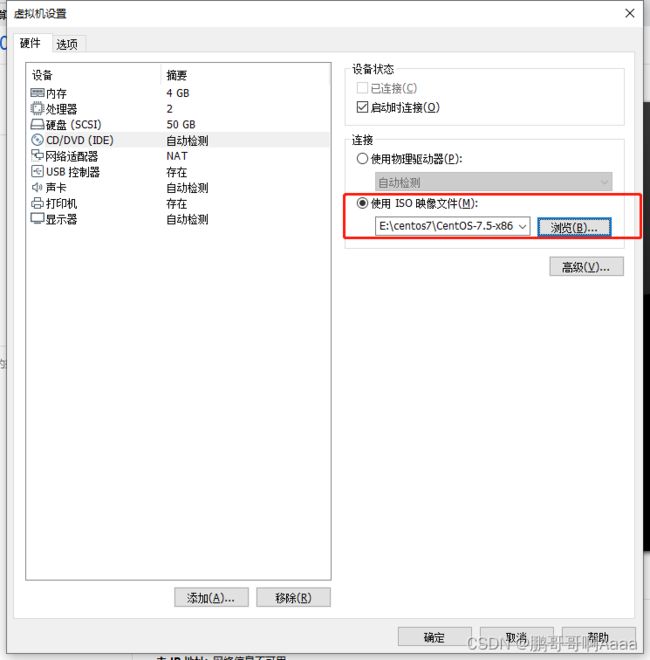
双击CD/DVD:
进来之后先配置时间,然后软件选择桌面:

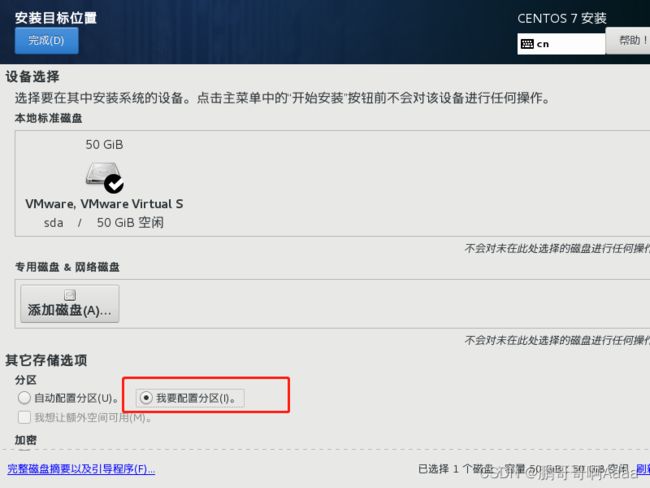
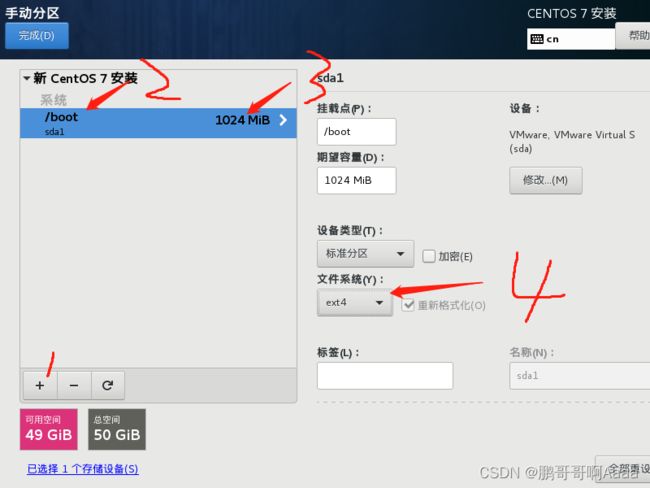
设置安装位置:
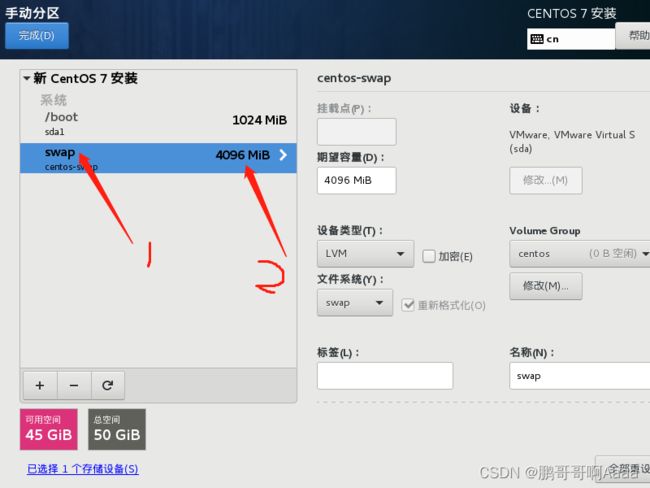
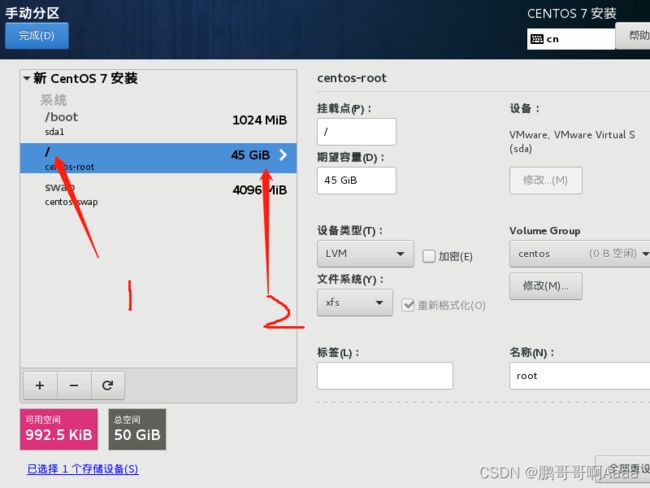
关闭dump:
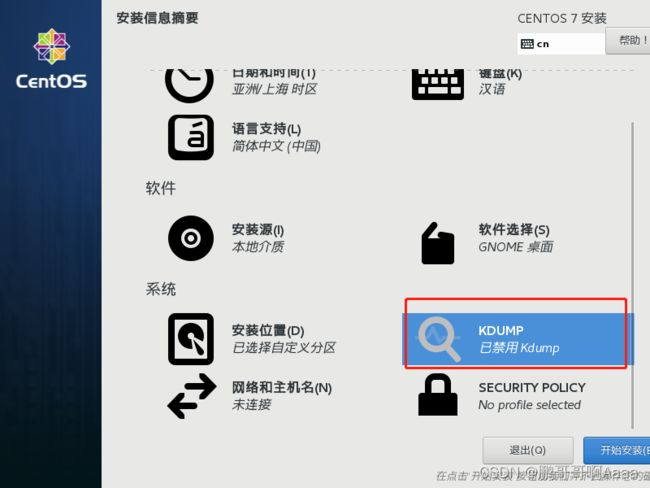
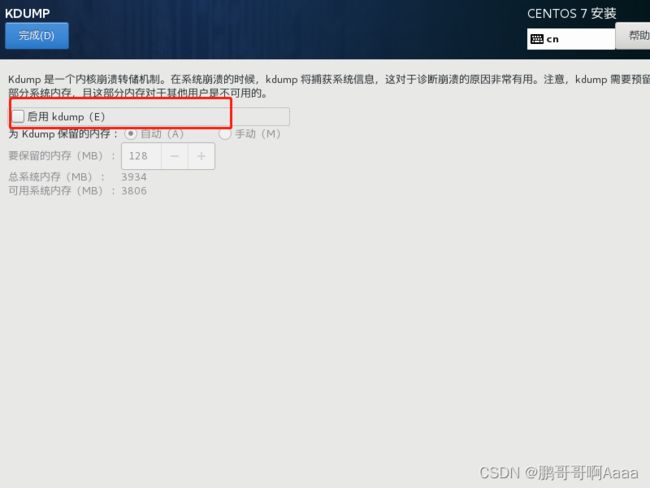
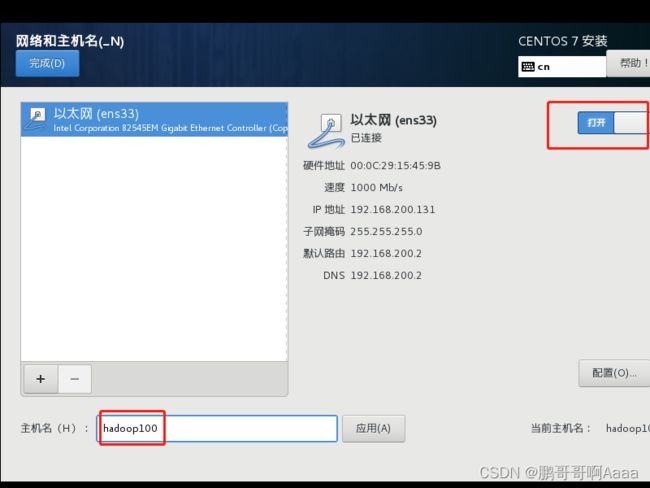
配置好之后重启。
接受一下协议:
3.配置ip和主机名称
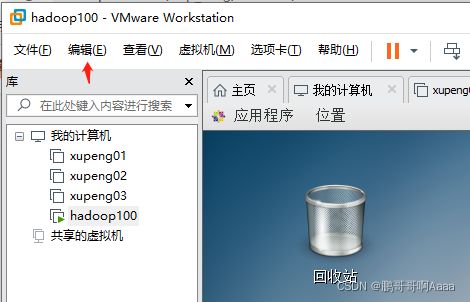
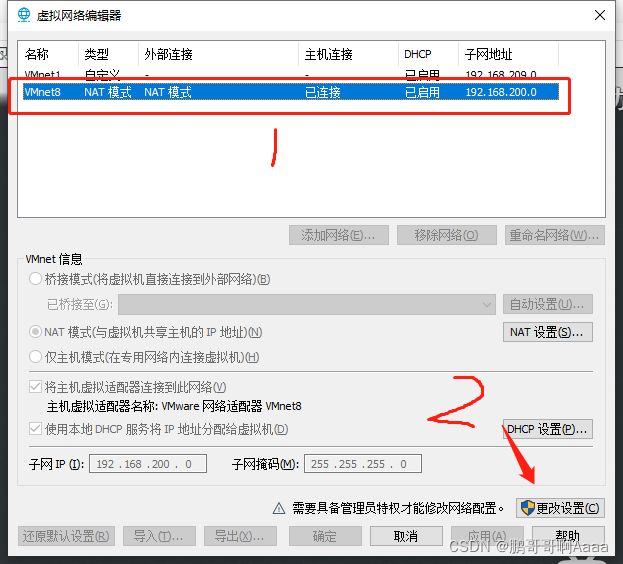
(1)修改虚拟机ip
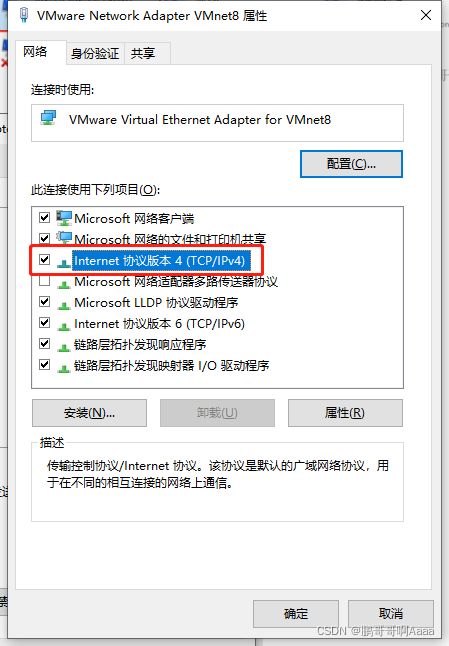
先打开虚拟网络编辑器:
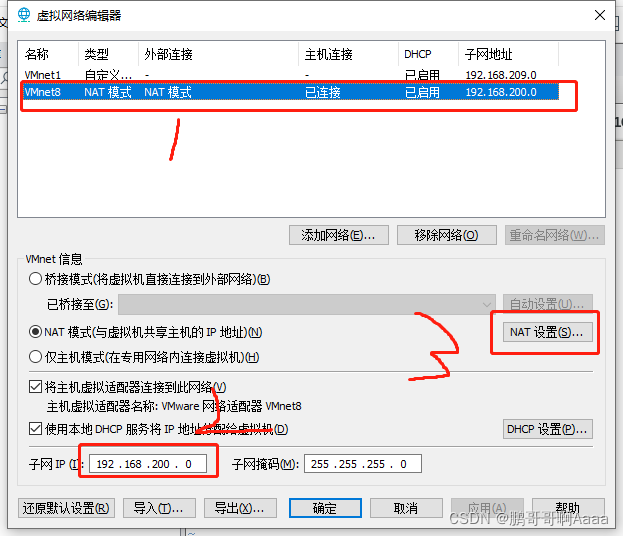
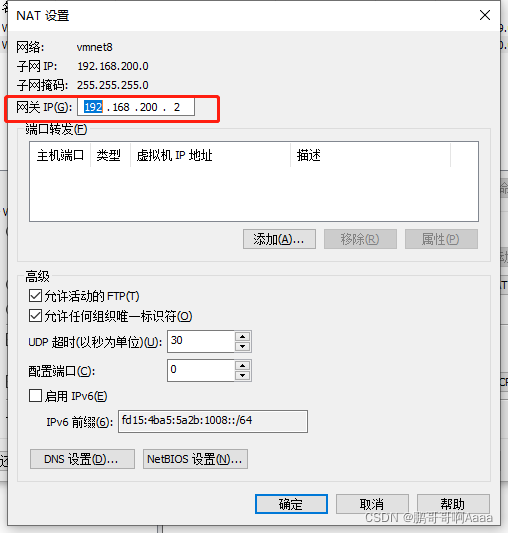
(2)修改windows的ip


(3)指定静态ip和hostname
su root
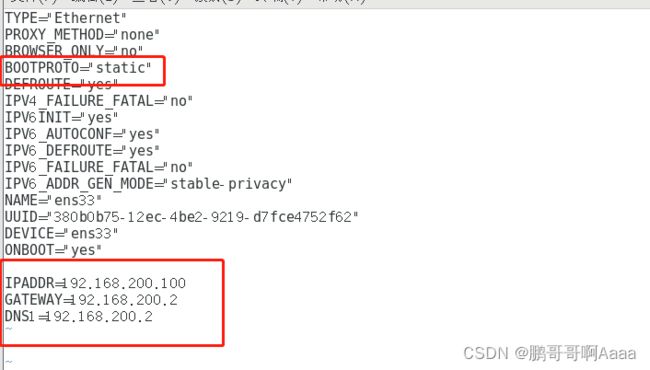
vim /etc/sysconfig/network-scripts/ifcfg-ens33
###########################################
#变更为static
BOOTPROTO="static"
IPADDR=192.168.10.100
GATEWAY=192.168.10.2
DNS1=192.168.10.2
###########################################
#更改主机名称,因为我们之前变了,就不动
vim /etc/hostname 
(4)映射ip
vim /etc/hosts
##################################
192.168.200.100 hadoop100
192.168.200.101 hadoop101
192.168.200.102 hadoop102
192.168.200.103 hadoop103
192.168.200.104 hadoop104
192.168.200.105 hadoop105
192.168.200.106 hadoop106
192.168.200.107 hadoop107
192.168.200.108 hadoop108
##################################都配置好了,reboot重启一下。
4.模板虚拟机
(1)安装基本软件库
yum install -y epel-release
注:如果你安装的不是桌面版,而是最小版的操作系统,还需要添加如下。当然我们是桌面版,下面的就不需要
yum install -y net-tools
yum install -y vim(2)关闭防火墙
systemctl stop firewalld
systemctl disable firewalld.service(3)添加用户
useradd 用户名
passwd 用户密码(4)给用户设置管理员权限
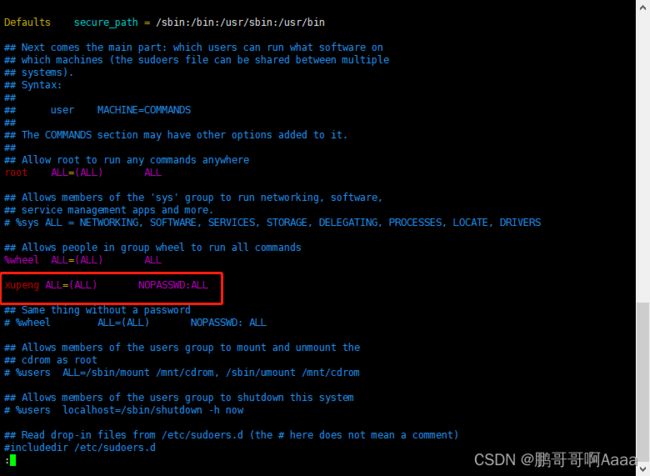
vim /etc/sudoers
##########################################
xupeng ALL=(ALL) NOPASSWD:ALL
##########################################
(5)创建两个文件夹
mkdir -p /opt/module
mkdir -p /opt/software
(6)卸载虚拟机自带的jdk
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
#rpm -qa:查询所安装的所有rpm软件包
#grep -i:忽略大小写
#xargs -n1:表示每次只传递一个参数
#rpm -e –nodeps:强制卸载软件5.克隆虚拟机
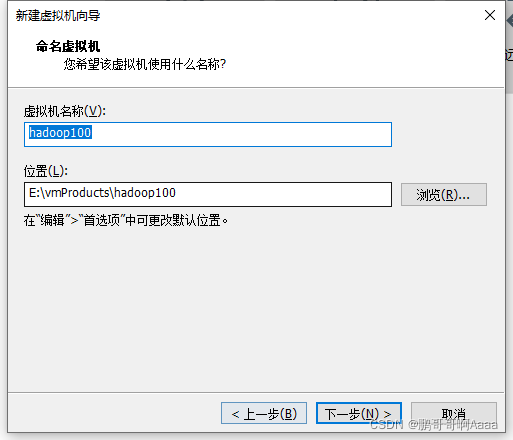
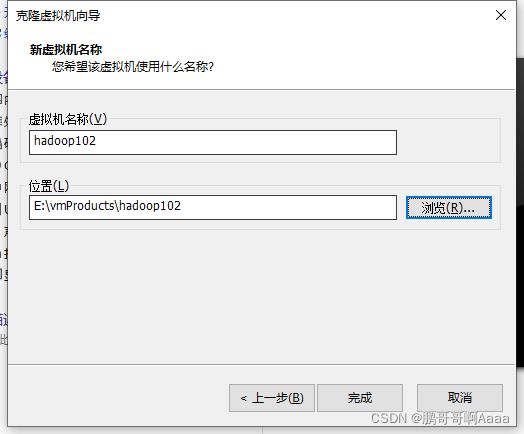
我们给hadoop100克隆3个,分别是102,103,104。其中101先不占用,后期做伪分布式的时候要用。
注1:克隆前需要关闭虚拟机。
注2:没有贴出图片的地方表示都是直接点击下一步即可
注3:102,103,104步骤基本一致,记得改名即可
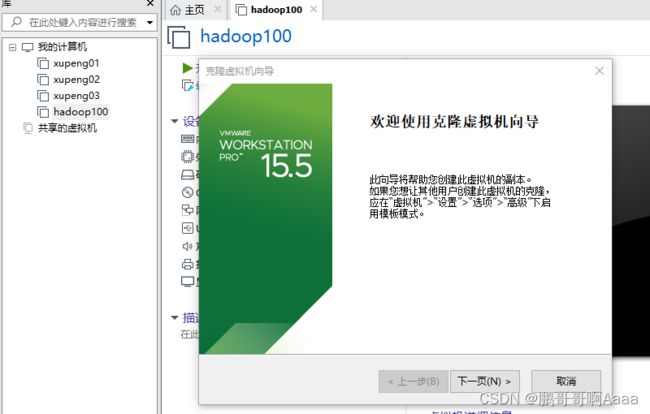
(1)克隆
右键hadoop100=>管理=>克隆

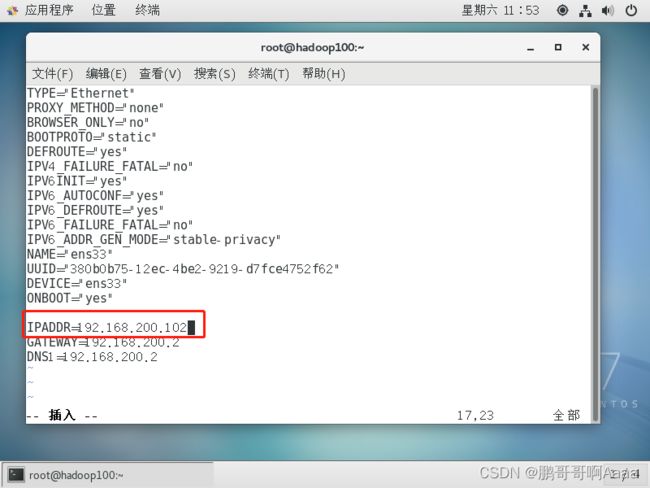
(2)修改ip
用root先登录上去,然后:
#先修改ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33
#再修改hostname
vim /etc/hostname

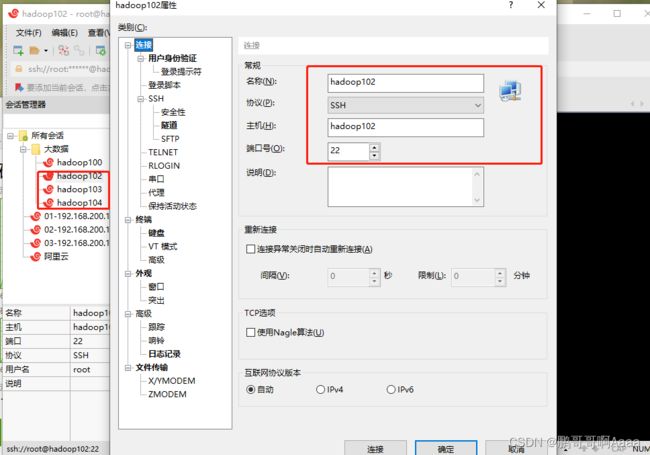
(3)配置xshell
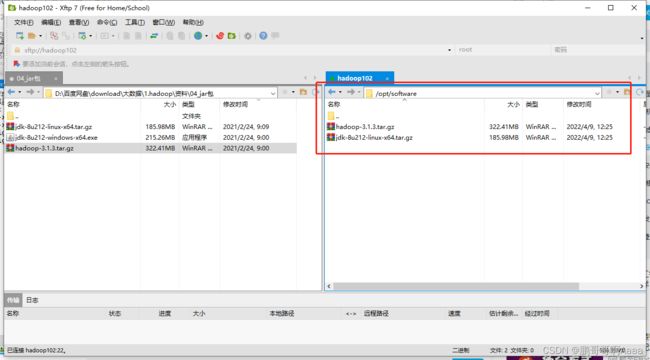
6. 仅hadoop102中安装jdk
我们后续会拷贝到103,104,因此这里只安装102一个
(1)安装
#安装到module目录下
cd /opt/software/
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
(2)配置java环境变量
我们前面讲过的配置环境变量是直接修改/etc/profile文件,这里我们通过自定义一个文件,然后到处到/etc/profile里面:
cd /etc/profile.d/
vim my_env.sh
**********************************
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
**********************************
#刷新一下配置文件
source /etc/profile
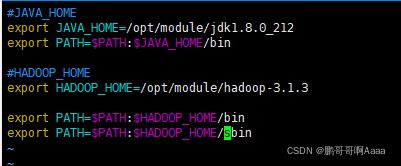
7.仅安装hadoop102安装hadoop
我们后续会拷贝到103,104,因此这里只安装102一个
(1)安装
cd /opt/software/
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/(2)配置hadoop环境变量
cd /etc/profile.d/
vim my_env.sh
**********************************
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
**********************************
#刷新一下配置文件
source /etc/profile
三、执行本地运行模式
hadoop有三种模式:本地、伪分布式、分布式
我们这里先走一个本地运行模式,能够顺利走通。
#先新建一个文档
cd /opt/module/hadoop-3.1.3/
mkdir wcinput
cd wcinput/
vim word.txt
*****************************
aa aa
bb bb bb
cc cc
dd dd dd
ee
ff
*****************************
#运行自带的示例jar包,查看每个单词出现的次数
#注:wcoutput表示输出路径,该路径如果已存在会报错
cd /opt/module/hadoop-3.1.3/bin/
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ ./wcoutput
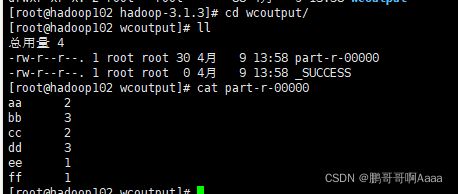
#查看运行结果
cd wcoutput/
cat part-r-00000
四、各虚拟机之间数据同步
hadoop有三种模式:本地、伪分布式、分布式
上面我们试了本地模式,但是真正用的多的是分布式,现在我们来走一遍分布式模式。
1.通过scp/rsync将102的jdk,hadoop复制到103,104
一般来说,第一次通过scp进行复制,后面有修改的话用rsync进行同步。
#本处仅仅是为了展示scp的作用,如果熟悉scp可以直接拷贝即可
#进入到102,将102的jdk复制到103
cd /opt/module/
scp -r jdk1.8.0_212/ root@hadoop103:/opt/module/
#进入103,将102的hadoop复制到103
cd /opt/module/
scp -r root@hadoop102:/opt/module/hadoop-3.1.3 ./
#继续在103上,把102拷贝到104
scp -r root@hadoop102:/opt/module/* root@hadoop104:/opt/module/
#我们再来测试一下同步指令(基本同scp):rsync -av 同步文件A 同步文件B
#先把103中的两个文件删了
cd /opt/module/hadoop-3.1.3/
rm -rf wcinput/
rm -rf wcoutput/
#然后我们用102来同步给103
cd /opt/module/
rsync -av hadoop-3.1.3/ root@hadoop103:/opt/module/hadoop-3.1.3/
2.xsync循环复制文件到所有节点的相同目录下(重要)
我们上一步,复制和同步,一个节点要循环多次才能给其他节点,我们现在需要一个脚本,自动循环复制。
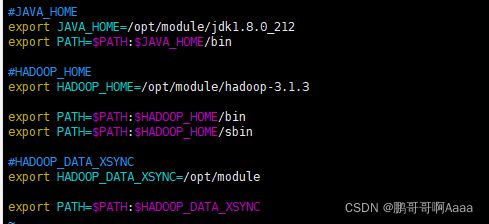
(1)新建一个$PATH的配置文件
注:这些操作均在102执行
#因为我们所有的项目都是写在/opt/module下面的,所以我们把该目录放到$PATH里面去
cd /etc/profile.d/
vim my_env.sh
*********************************************
#HADOOP_DATA_XSYNC
export HADOOP_DATA_XSYNC=/opt/module
export PATH=$PATH:$HADOOP_DATA_XSYNC
*********************************************
source /etc/profile
#可以看到我们新加的/opt/module目录
echo $PATH
(2)编写xsync脚本
cd /opt/module/
vim xsync
************************************************
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
************************************************
#添加操作权
chmod 777 xsync
#将我们之前的my_env.sh环境变量配置文件同步到103,104
xsync /etc/profile.d/my_env.sh
#输入了6次密码后,我们成功了
#将103,104刷新一下配置文件,然后就可以看到java和hadoop可以直接运行了
source /etc/profile

3.免密登录
我们上一步输入密码吐了,我们需要免密登录。
#用102连接103,然后再退出
cd /opt/module/
ssh hadoop103
exit
#进入102的家目录,我因为使用的root,如果是用的普通账号,应该是进入/home/用户名
#能够看到有一个.ssh文件(必须要先ssh一下其他的虚拟机,不然没有.ssh文件)
cd ~
ls -al
cd .ssh/
#配置102无秘登录103,104
#三次回车之后,会生成一个私钥和公钥
ssh-keygen -t rsa
#将102生成的公钥拷贝到103,104,还要设置一次自己,这样自己以后也不用输入密码了
ssh-copy-id hadoop103
ssh-copy-id hadoop104
ssh-copy-id hadoop102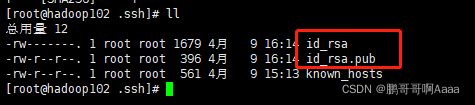
#我们同时希望103访问其他两个也不需要密码,104同理
ssh hadoop102
exit
cd ~
ls -al
cd .ssh/
ssh-keygen -t rsa
ssh-copy-id hadoop103
ssh-copy-id hadoop104
ssh-copy-id hadoop102