技术笔记:.Net全套就业班视频教程——数据库
- 数据库表关系:1对1,1对多,多对多(两个表,如果两个方向都是1对多,它们就是多对多关系,多对多有一个中间表。如:1个人可收藏多个商品,1个商品可被多个人所收藏)。中间表命名规范:“R_”(R–关系)开头,两个表与中间表都是1对多关系。
- CRUD是增加(Create)、查询(Retrieve)、更新(Update)和删除(Delete)单词的首字母。
- SQL server共有5个系统DB:master(sql server系统所有系统级信息。如登陆账号、系统配置、其他数据库的存在和位置等);msdb(代理计划警报和作业、邮件等);model(创建所有数据库的模板);tempdb(保存临时对象和中间结果,每次启动重新创建);Resource(只读的,存放系统对象的物理文件,但逻辑上显示每个DB的sys架构中。)
- 数据库的分离与脱机,二者差不多,操作后你可以移动数据库文件,但是后者操作后在数据库管理器里能看到DB,只是不能用。
- 一个数据库最多可创建32767个数据库文件,最多可有20亿张表,一个表最多可1024列,每行最大字节数为8060。
- 收缩数据库:若往表里插入大量数据,然后delete这些数据,发现数据库文件大小没相应缩小。所以要收缩数据库。
- 数据类型:
- 存图片,可用binary(字节)类型、image类型(存字节,没大小限制,所以也可存文档)。
- char(2) 存中文占2字节,英文或数字占1字节。nchar(2) 表示不论中文、英文、数字等,每个字符都占2字节。浪费磁盘空间!!!! 不带n的最长可为8000,有n的最长是4000。带n的一般存中文或双字节字符。
- char、varchar的var表示可变长度,如varchar(3),仅存“ab”不会用空格补齐。前者是固定长度,如char(3),仅存’a’的话,后面用2两个空格补充。
- 当数据库的“排序规则”不是简体中文(即非中文)要存中文则必须是用带“n”的类型,不用的话存入的是乱码!
- insert语句形如“insert into tblName values(N’张三’,50)”——加‘N’目的是防止中文乱码,英文则可不加。所以,写sql时含中文的一定要加‘N’
- text、ntext,不推荐用,sql2005以前用的多。当长度8000不够用,则用varchar(max)(表示字段可存4GB内容,sql2005后才有)
- datetime、datetime2,后者能存入更高精度的时间(精度主要反映在毫秒、飞秒)
- 一条信息在数据库中是不允许出现两次,我们是通过PK(主键)来实现避免重复的,一个表只能有一个PK(SQL Server是钥匙图标表示)。因为SQL server默认会给它建索引,入库的数据保存在磁盘中顺序是按PK排序后的顺序保存。 可设置为PK的列规则:“业务主键(如身份证号、工号)、逻辑主键(id列自+1)”,推荐用后者,前者发生重复不可避免。不推荐使用“复合主键”,一个列如果符合“单列+入库后值不变+数字+唯一”则优先设置为PK,标识列即自+1的列刚好全达标,也是大家喜欢用标识列来做主键原因)。
- IDENTITY(1,1):设置标识列(列值自增1)。 PRIMARY KEY:设置主键列
- 主键和标识列区别:主键是为了每条数据的唯一,而简单有效的手段是设置id标识列为主键。一个表的主键可以是多列构成(联合主键),标识列只有一列。标识列必须为不带小数的数值类型,主键列可是任意类型。
- SQL是结构化查询语句,是关系型数据库的标准语言。微软和Sybase对其扩展成了T-SQL(作业SQL)。后者是在1986年发布,且是首个商用关系型数据库公司。后来授权给微软,后者支持unix和Linux。MariaDB数据库管理系统是MySQL的一个分支,其是由MySQL的创始人Michael Widenius主导开发。
- DDL——数据定义语言,建库/表,删/改表。DML(数据操作语言)——select、insert、delete、update。DCL(数据库控制语言)——GRANT授权、Revoke取消授权。
- 数据冗余
- 冗余危害:浪费存储空间、“更新、删除”很难做到干净。
- 冗余好处:查询快,SQL编写简单
- 减少冗余办法:越高的范式冗余越小。最直观办法是把表中数据放到多个表中。怎么关联多个表?用PK和FK进行关联。
- 有外键的表叫“外键表”,主键被引用的表叫“主键表”。
- 往id列已经设置为“PK且identity(1,1)”的表中插入值的方法:
SET IDENTITY_INSERT tblName ON --开启手动插入
INSERT INTO tblName ...--insert语句要含id值,但是不能重复!!(如果tblName就1条数据,id值500,则下一个id为501)
SET IDENTITY_INSERT tblName OFF--关闭手动插入
- where后面可以有的逻辑运算符:or 、and、not、in(会被编译成or)、=、>、>=、<、<=、<>(或!=)
- Truncate TABLE tblName–直接清空表,比“delete from tblName”速度快。清空后的表id恢复从1开始。执行时不触发delete触发器。有外键约束时,不能truncate,而delete可能失败,如要删的对象外键在主键表没有,才能执行成功。
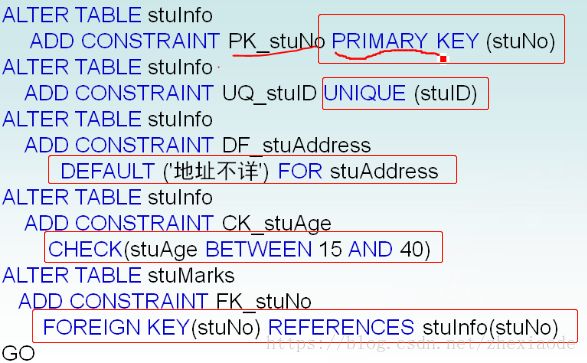
- 约束常见6种:不为空约束、主键约束(PK,金色钥匙图标)、默认约束、
外键约束(要插入的外键如果不存在就会异常。外键表右键“关系”->“添加”->…删除规则:级联–删主表是部门表数据,人员信息外键表相关数据也会删掉;删外键表一条就是一条不会级联)、唯一约束(如邮箱或手机号列必须唯一,右键“索引/键”->添加类型是唯一键,并选相应列,蓝色钥匙图标)、检查约束(年龄列实际肯定不会1000,故可加“age>0 AND age<=150”)
- Select TOP 30 PERCENT * from tbl --符合相应占比(返回小数则向上取整)数据
- 聚合函数:顾名思义就是多条变一条。分组后才能用它,一般用它来统计数据。常用:max、MIN、COUNT、AVG、SUM,没有group by则视为一组(select语句中出现的列,要么放到group by后面用于分组,要么在sum等聚合函数里用于统计值,只会出现在这两个地方)。聚合函数,对null值不计算。若对同一表count(address)和count(*)则,前者有null值时返回值可能比后者小。avg也是不统计空值。
SELECT 平均年龄=(SELECT SUM(age) FROM tlb1)/(SELECT COUNT(age) FROM tlb1)--结果是int型,如果想让结果是小数,则sum值乘以1.0即可.
SELECT Emp_No,SUM(1) a FROM PR_People Where AssessID='225' Group By Emp_No having sum(1)=1 ORDER BY Emp_No
- SELECT * FROM Base_Organize WHERE OrderID IN(1,2,3) --OR 等同于in ,但是如果OrderId是有序的则“OrderID>=1 AND OrderID<=3”(其等同于“between 1 and 3”)更高效
-
Where、Having“过滤”功能区别详解:行级过滤,用where。对分组后的结果集过滤,用having。具体:where语句的执行顺序在分组之前,并且where只能过滤行,不能过滤分组(where中不能使用聚合函数)。having执行在分组之后,对group分组的结果集进行过滤,having子句中可以直接使用聚合函数。
-
Null的处理:
- age is null 和age is not null(不能用age =null或age <>null)。
- SELECT 11+null,返回null(任何值与null计算后得到null)
- isNull(age,0)–age列用值0替换所有 NULL 条目。
- NULL的比较问题
- Null值并不是一个值,任何与Null比较结果一定为Null。
- 查询空值或者非空值的时候,用的是is null/is not null
- 按照ANSI SQL标准,
select * from T where Data=null 或 Data<>null这两种方式都不返回任何行,只有Data is null才能有返回值。实际工作中遇到如:SELECT * FROM A WHERE id NOT IN ( 2, NULL )等同于.... WHERE a.id <> 2 AND a.ID <> NULL而NULL值不能参与比较运算符,即not in子查询中有null值的时候,则不会返回数据。解决办法是子查询中排除NULL值。
- order by English,Math desc——先按英语从大到小在按数学成绩从大到小排,当English分一样后才按数学成绩排序。
order by (English+Math)*1.0/2 desc——按两门平均分排 - 表中数据是集合,集合是无序的。把order by后有序的集合叫“游标”,有序后就不是集合了。
- 一条select语句执行顺序(即先查询出符合条件的然后对其排序):找到要查的表,返回出符合条件的数据汇总成结果集1,在1中仅显示指定列汇总成结果集2,对2去重汇总成结果集3,对3进行排序汇总成结果集4,返回4中的Top 12汇总成最终结果集
1-from,2-on,3-join,4-where,5-group by,6-with cube或with rollup,7-having,8-select,9-distinct,10-order by,11-top
- where name like '安__'--返回所有安开头的3个字的姓名
where name like '张[0-9]妹'----返回所有张和妹中间是数字('张[a-z]妹'、'张[0-9a-z]妹'(中间可是数字或字母)、'张[^0-9]妹'(中间不能是数字就行))
where name like '%[%]%'——返回所有带‘%’的名字,默认放到[]中实现转义。自定义转义 select * from tbl where name like '%/[/]%' ESCAPE '/'
- 类型转换函数:cast/convert,前者先出现,后者功能强大。
SELECT 1+'11'--自动类型转换
SELECT 'a'+1--转换失败
SELECT 1.1+'11'--转换失败
SELECT CAST('11' AS int) +1.1
SELECT CONVERT(INT,'11')+1.1
SELECT CONVERT(VARCHAR(10),GETDATE(),120)--日期输出格式:"yyyy-MM-dd"
SELECT CONVERT(VARCHAR(20),GETDATE(),120)--日期输出格式:"yyyy-MM-dd +时分秒"
- union,联合结果集,把行联合起来。join,把列连接起来。union会去重和排序、union all不去重也不排序,两者比起来union慢些。
- 一次往表中插入多条:
方法1:用union、union all。
方法2:select * into tbl from student (tbl表会自动被创建,只是copy数据、列名及数据类型,对于约束不会复制)。
select * into tbl from student where 1<>1 ,只复制表结构,效率低。建议:select top 0 * into tbl from student
方法3:insert into tbl select * from student (tbl表必须提前建好)
- 字符串函数
SELECT LEN('1啊')--字符串个数:2个
SELECT DATALENGTH('1啊')--字符串磁盘中大小:3b(字节)
SELECT DATALENGTH(N'1啊')--字符串磁盘中大小:4b
SELECT LOWER('HI')--hi 转小写
SELECT UPPER('hi')--HI 转大写
SELECT LTRIM(RTRIM('== ')+LTRIM(' =='))--去掉字符串首尾空格
SELECT LEFT('abcd',2) --从左边开始截取几个字符 结果:ab
SELECT RIGHT('abcd',2) --从右边开始截取几个字符 结果:cd
SELECT SUBSTRING('abcd',2,3)--截取串,从坐标轴是2()的字符开始取3个 结果:bcd。给串画一条x轴则a对应1,轴上可以为负或0。如: SELECT SUBSTRING('abcd',-1,3)--结果是‘a’
- 日期函数 (记忆:add+、diff-、part)
SELECT SYSDATETIME()-- 高精度时间
SELECT DATEADD(second,20,GETDATE())--当前时间增加20 second/minute/hour/day/week/month/year
SELECT * FROM tbl WHERE DATEADD(YEAR,1,joinDate)<=GETDATE()--入职1年以上的人员
SELECT DATEDIFF(MONTH,'1987-11-14',GETDATE())--两个日期差,可知道某个人在地球上生存了多久,时间维度可为“second/minute/hour/day/week/month/year”
SELECT 工龄=DATEDIFF(DAY,JoinTime,GETDATE())/365,COUNT(1) FROM tbl GROUP BY DATEDIFF(DAY,JoinTime,GETDATE())/365--各工龄的人数
SELECT DATEPART(year,GETDATE())--取得当前日期的年部分(结果是int型) 可为“second/minute/hour/day/week/month/year” SELECT YEAR(GETDATE()) 年,month(GETDATE()) 月,day(GETDATE()) 日 --简写只有“年、月、日”
SELECT DATENAME(YEAR,GETDATE())--取得当前日期的年部分(结果是varchar型)
- 内连接
sql1:SELECT * FROM tbl1 ,tbl2 --结果集是返回笛卡尔积
sql2:SELECT * FROM tbl1 a inner join tbl2 b on a.id=b.tId--先得到sql1的笛卡尔积,然后筛选出符合on条件的结果并返回
- 可空值类型,必须是值类型,所以string不能用。可以:int、double、float、bool。
int? age=txtAge.Text.Length()==0 ? null : (int?)txtAge.Text;//要给后者转为int?,因为问号表达式要求三者数据类型要一致。
string sql="insert into tbl values(@name,@age)";
SqlParameter[] pms=new SqlParameter[]{
new SqlParameter("@name",SqlDbType.NVarChar,50){Value="张三"}, //SqlDbType.NVarChar,50——必须与数据库中一致 不推荐“new SqlParameter("@name","李四"),”写法
new SqlParameter("@age",SqlDbType.Int){ Value=age==null ? DBNull.Value : (object)age} //往DB中insert值null,必须是DBNull.Value
};
int? n=null; 等价于Nullable<int> n=null;书上说值类型不能为null,int?可以原因是:它是一个结构在里面封装属性HasValue,无值在其为false,当写“if(n==null){}”等价于“if(!n.HasValue){}”,这些工作都编译器帮我们做的。
- SQL条件控制case-when两种写法
--Case搜索函数,相当于C#的if-else(条件可以是一个范围,推荐实际使用)
select 论坛头衔= case when level>=1 and level<=2 then '菜鸟' when level>=3 and level<=4 then '老鸟' else '??' end from user
--Case函数,相当于C#中的switch(判断条件只能是一个值,不推荐)
select case level when 1 then '菜鸟' when 3 then '老鸟' else '??' end as [论坛头衔] from user
- 扩展:电子教室软件“红蜘蛛多媒体教室 或 TopDomain极限域电子教室 ”
索引
- SQL server的数据是按页(4KB)存放。索引,是SQL server编排数据的内部方法。
索引页:数据库中存储索引的数据页;索引页类似字典中按拼音或笔画排序的目录页。 - 目的就是为了select的快,实际就是对数据排序,当我们创建主键,系统会自动创建为其建主键索引(一个表只能一个,它属于聚集索引)。
- 索引分为
唯一索引,不允许两行具有相同的索引值,一个表可以有多。“聚集索引也叫聚簇索引”(目录顺序与内容顺序一样。像新华字典的拼音方式查字,一个表只能一个)和“非聚集索引”(目录顺序与内容顺序不一样。如字典的偏旁部首找字,一个表可有多个,但是要<249个)。非聚集索引,反应了从多少个角度查询数据,如图书馆,我可按书名找或按价格找等等。主键索引就是一个唯一索引,就是一个聚集索引。
索引缺点:表建索引后要额外占用存储空间。降低了增、删、改的效率(每次这些操作DB都要维护更新索引)。- 通常建索引原则:该列用于频繁搜索;该列用于对数据进行排序(在经常检索即where后、order by后用到的字段上创建索引)。不要创建索引情况:列中仅含几个不同值;表只有几行(小表建索引不划算)
- (*)即使建了索引,也可能全表扫描,如like、函数、类型转换等。“like ‘aa%’”会用到索引,而“like ‘%aa%’”则肯定不会用索引。
- 删除索引: drop index T9IX_T8_tage
- 监控一条sql执行方法:
打开Sql server的统计信息: 查询 > 查询选项 > 高级 > set statics time、set statics io 选中“包括实际的执行计划”或“估计的执行计划”菜单工具。
( 逻辑读取:从缓存中读取数据
物理读取:从磁盘中读取数据
预读取:在执行查询时先预测执行“查询计划”需要的数据和索引页,然后在查询实际使用这些页前将它们读入到缓存区。
读取次数和毫秒数越少越好
Lob类型包括:text varchar(max) varbinary image等大对象数据。) - 当我们不知道为表哪列建索引时,可以用“数据库引擎优化顾问”,流程:工作负荷选择要优化的SQL脚本文件,选择该sql执行的数据库,选择要优化的数据库和表里找到目标数据的目标表,点击“开始分析”,然后找到索引的“定义”列里面脚本执行即可。
子查询
- 把一个查询结果在另一个查询中使用就是子查询。多会用“in、not in、exists、not exists”。如:
select * from ( select col1,col2 from #tmp) as tbl ; select * from tbl where empNo in(select empNo from pr_people where id<10); select * from tbl a where exists (select * from pr_people b where a.empNo=b.empNo and b.id<100)我们写的所有查询都能改为“相关子查询”实现!!!解析本处的含exists语句,该SQL会扫表当扫到第一条时,exists里的sql是true第一条就会返回。 - 子查询分为:独立子查询(子查询可独立运行);相关子查询(子查询中引用了父查询中的结果)。
- 分页的sql必须确定按谁排序。
--TOP版分页
DECLARE @page int=2 --第二页内容
declare @pSize int=10--每页10条
SELECT top (@pSize) * from People where id not in(
select top (@pSize*(@page-1)) id from People order by id asc
) order by id asc
--不用not in版: select top 7 * from (select top (2*7) * from tbl order by id asc ) as t order by id desc
--ROW_NUMBER()版
DECLARE @page INT= 2; --页号
DECLARE @pSize INT= 10;--每页条数
SELECT *
FROM ( SELECT row_No = ROW_NUMBER() OVER ( ORDER BY ID ASC )--row_number--生成编号列,over--请按照id列asc排序后为其编号
,
Emp_NO
FROM B_Employee
) tbl
WHERE row_No BETWEEN ( @page - 1 ) * @pSize + 1 AND ( @page * @pSize );
- set、select为变量赋值的区别:
DECLARE @a int
set @a=(SELECT count(*) from tbl)
SELECT @a=count(*) from tbl
print @a
--上述效果一样。
set @a=(SELECT empNo from tbl)--当返回多个值,set赋值会报错
SELECT @a=empNo from tbl --当返回多个值,select赋值会把最后一个给@a
print @a
- 左外连和右外连接
inner join–返回两个表匹配的数据,过滤掉不匹配的数据
left join-- 返回‘左’表所有数据;‘右’表有匹配的则显示,不匹配的则显示null
right join–返回‘右’表所有数据;‘左’表有匹配的则显示,不匹配的则显示null- left和right互相可以实现同样效果,只是语法不一样。一般用left-join
- 【连接查询执行顺序】:1.生成笛卡尔积 2.根据on后面条件筛选出匹配的数据 3.添加外部行,到此执行完毕(“添加外部行”我的理解:因为是外连接大原则是要返回左表所有行,然后右表仅显示匹配项)。故,注意:当连接查询,如果是写在where的条件就不要在on后面加and方式。如:“tbl t left join tbl2 b on t.id=b.TId and t.sex=‘男’ ”(先根据on返回目标结果,但是最后又会返回所有主表数据,就会覆盖所以与后面条件不一样)与 “on t.id=b.TId where t.sex=‘男’” 不能等同。
left join中关于where和on条件的几个知识点:(筛选条件写在where还是on后面解读)
1.多表left join是会生成一张临时表,并返回给用户
2.where条件是针对最后生成的这张临时表进行过滤,过滤掉不符合where条件的记录,是真正的不符合就过滤掉。
3.on条件是对left join的右表进行条件过滤,但依然返回左表的所有行,右表中没有的补为NULL
4.on条件中如果有对左表的限制条件,无论条件真假,依然返回左表的所有行,但是会影响右表的匹配值。也就是说on中左表的限制条件只影响右表的匹配内容,不影响返回行数。
结论:
1.where条件中对左表限制,不能放到on后面
2.where条件中对右表限制,放到on后面,会有数据行数差异,比原来行数要多
- study、study_req表都有 deleted_Mark(1删除,0未删除)下面三条查询语句分析
--正确,但是麻烦
select * from study st left join (SELECT * FROM study_req where deleted_Mark=0) sr on st.study_id = sr.study_id where st.deleted_Mark=0
--正确???
select * from study st left join study_req sr on st.study_id = sr.study_id on sr.deleted_Mark=0 where st.deleted_Mark=0
--错误写法
select * from study st left join study_req sr on st.study_id = sr.study_id where st.deleted_Mark=0 and sr.deleted_Mark=0
- 自连接:表本身连接本身
--返回笛卡尔积:SELECT * FROM B_Organize a, B_Organize b
SELECT a.OrgName,b.OrgName FROM B_Organize a inner join B_Organize b on a.Org_NO=b.FatherID--返回“襄阳市,湖北省;武汉市,湖北省;宜昌市,湖北省;
CREATE TABLE [dbo].[B_Organize]
(
[Org_ID] [int] NOT NULL IDENTITY(1, 1),--表id
[Org_NO] [int] NOT NULL,--机构号
[OrgName] [nvarchar] (50) COLLATE Chinese_PRC_CI_AS NOT NULL,--组织机构名称
[Visable] [tinyint] NOT NULL,--是否显示在通讯录中
[Flag] [tinyint] NOT NULL,--是否为组织机构,1为组织机构,0为用户组
[OrderID] [int] NULL,--排序顺序
[FatherID] [int] NULL,--上一级节点ID
[FatherPath] [varchar] (50) COLLATE Chinese_PRC_CI_AS NULL,--组织机构全路径
[EffectDate] [datetime] NULL,--启用时间
[ExpiredDate] [datetime] NULL,--失效时间
[istop] [int] NULL,
[orderid_sap] [nvarchar] (50) COLLATE Chinese_PRC_CI_AS NULL
)
- 视图:实际开发过程中要经常查询一些数据,但是要用复杂的sql语句才能查到,我们可将语句封装成视图,下次只需要直接“select * from view_tbls(视图)”就可以了。视图中不存放原始数据。sql server的索引视图存放数据。
- 视图是无参且只是select语句的集合
- 创建视图语法:create view view_tbls as select * from tbl–没有where条件select语句(也不能只跟order by,但是它可以与top配合使用是可以的)
- 好处:降低了数据库复杂度;防止未经许可用户访问敏感数据(一个系统A用户登陆后仅能执行某几个视图来查看对其开放的字段);将多个物理数据库抽象为一个逻辑数据库。
T-SQL编程
- 声明变量:两个“@@”开头一般是系统变量,不过自己变量时也可加两个“@@”
declare @name varchar(50)
declare @age int
或 declare @name varchar(50),@age int
PRINT @@VERSION--数据库版本,@@error,最后一次sql错误的错误号(正常返回0,错误则“<>0”),@@identity 最后一次插入的标示值
PRINT @@MAX_CONNECTIONS--数据库可同时连接的最大数
PRINT @@rowcount--上条sql影响的行数
PRINT @@SERVERNAME--服务器名称
-
使用while循环
declare @i int=1; while (i<10)--括号可不写 begin print 'hi' set @i=@i+1 break;--跳出循环 continue;--继续下次循环 end -
if语句
if @i>10 begin print 'n大于10' end else if @i>5 begin print 'n大于5' end else begin print 'hi' end -
事务:事务一旦开启就两种可能"ROLLBACK,COMMIT"。 事务分类:
自动提交事务(当我们执行一条insert、update、delete,如果出错就回滚);隐式事务(每次执行一条sql,数据库自动帮我们打开一个事务,但是需要手动提交或回滚事务);显示事务(需要手动打开事务,手动提交或回滚事务)- [显示事务]–(常用)
BEGIN TRANSACTION --开始转账事务 或 “begin tran” DECLARE @flag INT=0 --汇总的@@error值 UPDATE tbl SET money =money+100 WHERE id='u001'--给账号1加100元 SET @flag=@flag+@@ERROR --必须在每条sql后面进行累加操作 UPDATE tbl SET money =money-100 WHERE id='u002' --给账号2减100元,假设该人只有108元,而该表有对money检查约束(该字段最少10),故必会发生异常 SET @flag=@flag+@@ERROR IF(@flag>0) --有一条sql语句出错,就回滚事务 BEGIN ROLLBACK--回滚 END ELSE BEGIN COMMIT--没出错就提交事务 END- [隐式事务]–(少用)开启后,每个SQL语句都自动按事务模式执行
SET IMPLICIT_TRANSACTIONS ON--打开隐式事务 INSERT INTO tbl VALUES('12','123123')--当没写COMMIT,则此表一直被占用,此时执行select时给人感觉是耗费很久但是还是查询不到结果。 COMMIT SET IMPLICIT_TRANSACTIONS off--关闭隐式事务 -
事务的ACID特性:
原子性(各步操作不可分隔,要么都执行要么都不执行)、一致性(事务完成后所有数据一致,银行总钱数在“已有数+n次转入-n次转出”后不会发生混乱)、隔离性(并发事务在执行时,是互相独立的别人不可干预)、持久性(数据会被永久保存) -
Trigger(触发器,枪的扳机)一个特殊的存储过程,事件触发后自动调用它。具备事务功能;它能在多表之间执行特殊业务规则。触发器是在对表进行插入、删除、改时自动执行的存储过程(它是与表相关的,是自动执行,不能直接调用)。触发器是一种高级约束,可以定义比check约束更复杂的约束。扩展:SQLSERVER的触发器
- DML触发器:Inserte、delete、update ;DDL触发器:create table/create database/alter/drop等
- [“增、删、改”触发器原理]——触发器激发时,系统会在内存准备deleted和inserted两个表(只读,触发器执行完毕后自动删除,表结构与关联表完全一致),只有在触发器体内才能访问,其地方访问不到。要insert记录到tbl表,先插入到tbl表,然后在往inserted表插入一条。插入成功,则inserted表会释放,插入失败,回滚会清空两表记录。要删除id=3:先把tbl表的id=3数据移到deleted表。删除失败,回滚是把deleted表恢复到tbl表。 要udpate id=3:先把id=3的数据移到deleted表,然后插入新的记录到inserted表和tbl表
- After触发器:执行后的触发器。建立在普通表上,视图临时表不起作用。Instead of触发器:执行前的触发器,可建在表和视图上。每个表只能创建一个 INSTEAD OF 触发器,但可以有多个 AFTER 触发器。
--为tbl表创建执行删除后把被删除的内容备份到备份表 CREATE TRIGGER triName_delete ON tbl AFTER delete AS BEGIN INSERT INTO tbl的备份表 VALUES('','') SELECT * FROM deleted END- 触发器使用建议:尽量避免在触发器中执行耗时的复杂的操作,因为触发器会与sql语句认为在同一个事务中,事务不结束,就无法释放锁。触发器编写时要多注意对多行触发时的处理。
-
存储过程
- 以sp和xp开头的都是系统存储过程,在master数据库中
sp_databases--返回所有数据库
sp_helpdb——列出所有数据库
sp_renamedb——更改数据库名称(sp_password--添加修改登录账户的密码)
sp_tables--返回某个库所有表(SELECT * FROM INFORMATION_SCHEMA.TABLES)
sp_columns 'pr_people'--返回某个表所有字段信息 (SELECT * FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME='pr_people')
select * from sysobjects where xtype='V'--库中所有的视图
sp_helptext——查看存储过程、触发器、视图的实体文本
sp_help 'pr_people'——看某个表所有信息
sp_helpconstraint 'pr_people'——看某个表约束
sp_helpindex 'pr_people'——看某个表索引
sp_stored_procedures--列出所有存储过程(含函数)
- 存储过程缺点:大量业务逻辑写到存储过程中,访问压力转到数据库服务器了,优化数据库比优化代码难。
优点:同样的sql代码块,proc速度要快(保存到数据库后就是编译过的);允许模块程序设计(类似方法复用);提高系统安全性(防止SQL注入);减少网络流量(只需要传存储过程名) - 存储过程与函数区别:二者本质上没区别,只是函数只能返回一个变量(这个变量可是一个值或表对象,常用系统函数有getDate()、count()、sum()等),而存储过程可返回多个。select后面可跟一个函数,而存储过程不行。函数不能用临时表,只能是表变量。
- 存储过程例子
--无参存储过程
create proc usp_myProc
as begin
print 'hi'
end
-- 自己写带2个参数存储过程 exec usp_myProc 1,2 或exec usp_myProc @n1=1,@n2=2
create proc usp_myProc @n1 int=0,@n2 int--可以给默认值
as begin
select @n1+@n2
end
-- 输出参数的存储过程 适用情况:当不仅需要返回查询结果还需要返回其他值,如分页存储过程返回结果和总条数。
create proc usp_myProc @n1 int=0,@rowcount int output --输出参数关键字
as begin
select * from tbl where id=@n1
set @rowcount=(select count(*) from tbl where id=@n1)
end
--调用语句:
declare @rc int; exec usp_myProc 12,@rc output; print @rc;(下例子out与C#的out类似)
○ 有这样一个需求:创建查询机构表存储过程,传入参数机构号多个用逗号分隔如"19999999,10000104"
实现思路:
--方法1:自定义的split函数
create function [dbo].[f_split](@c varchar(2000),@split varchar(2))
returns @t table(col varchar(20))
as
begin
while(charindex(@split,@c)<>0)
begin
insert @t(col) values (substring(@c,1,charindex(@split,@c)-1))
set @c = stuff(@c,1,charindex(@split,@c),'')
end
insert @t(col) values (@c)
return
end
--调用:SELECT * FROM Organize WHERE Org_NO IN( select * from f_split('1,2,3',',') )以table形式返回分隔后值
--方法2:
DECLARE @s VARCHAR(5000);DECLARE @orgNo VARCHAR(5000)='19999999,10000104'
SET @s='SELECT * FROM Organize WHERE Org_NO IN('+@orgNo+')'
EXEC (@s)
- 扩展:SQL中存储过程out与output有什么不同、存储过程中的out,output,return 的使用
CREATE PROCEDURE Proc_Test @INPUT int,@OUTPUT int output
AS BEGIN
SET NOCOUNT ON;--不返回受影响行数
SELECT @OUTPUT=@INPUT
RETURN @INPUT+1--注意return
END
--调用:
DECLARE @OUT int,@Rt int
EXEC @Rt=Proc_Test3 10,@OUT output
SELECT @Rt,@OUT
数据库优化
- 数据库锁、数据库优化 (scale up–纵向扩展 向已有机器内加内存 scale out–横向扩展 加机器)
- “修改、删除、添加”时会加“写锁(也叫x锁/排他锁,表有它则表示此表被独占,其他锁就不能加了就连查都不让查)”;“查询”加“读锁(也叫s锁/共享锁,多个查询sql可在一个表上加多个读锁,有了读锁后就不能加写锁)”。SqlServer中select语句会引起的死锁。通过“SELECT * FROM People WITH(NOLOCK)”可查询加写锁的表,但是可能会查询到脏数据。
- 总结:
脏读含义:用户A对一个资源做了修改,此时用户B正好拿到了A修改的结果,但是B拿走后A又进行了回滚,B拿到与真实的不同。通过加锁机制可以避免脏读(因为锁可以做到:用户甲查询时,则不让用户乙改变表内容(因为甲查询给表加读锁了,就不让加写锁)或用户乙改变表内容时,不让用户甲查(因为给表加写锁了,就不让加读锁)。一个表可以被多个用户同时查)。with(nolock)作用是对查询的表不加读锁。这样好处是,它既不会被排他锁阻塞也不会去阻塞排他锁。但是会引起脏读。它允许SELECT语句读取正在修改中的数据。可提高并发时的性能,效果要在并发环境才可看到,多用在对读出的数据精度要求不高的情况下。- 锁:
- 一个表的读锁可以有多个。
- 一个表的写锁只能有一个。
- 一个表的读锁与写锁互斥。
- 有两个使用频率很高的表。A人独占表1中又准备独占表2;B人独占表2中又准备查表1。数据库自己有一个线程会查是否有死锁,有的话强行牺牲一个竞争者来解决死锁问题。具体的SqlServer表死锁的解决方法:先找到发生死锁的表
select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableName,* from sys.dm_tran_locks where resource_type='OBJECT'(在查询时间点数据库加锁情况的快照,列出来的不都是死锁但是死锁包含其中),然后对表解锁KILL 52(杀掉被锁的进程ID)。(sp_lock,SQL Server 2000就有,查看当前阻塞的数据表,以便分析程序,解决问题。)
- SQL Server可设置锁超时,超时可以释放死锁。怎么设置与查看锁的超时时间?
select @@LOCK_TIMEOUT——返回会话的锁超时时间,单位为毫秒。默认-1,代表没有超时时间。而0,在发生资源锁定时,不做任何等待,直接返回1222错误。SET LOCK_TIMEOUT 1800——超时期限设置为1,800毫秒。仅对当前会话有效,对新会话无效。- 弊端:超时值设置不恰当,则SQL server会不分好坏超时就返回错误。
- 具体怎么找到死锁?SQL server管理器,
工具 → SQL SERVER Profiler → 跟踪属性 → “常规”选项卡,“使用模板”里选TSQL_Locks → “事件选择” 勾选“Locks”的“Deadlock graph”等有Deadlock字样的选项 → 点确定统计结果中“EventClass”是“Deadlock graph”是以图形显示死锁的图形事件。资料1、资料2 - 死锁会造成系统反应超慢(类似连接超时),避免死锁办法:
1、sql操作表顺序尽量一致(A人操作要占表1,2;B操作也要占表1,2,这样在写sql语句时都先执行1,再执行2)。
2、查询sql添加with(nolock)就是不加s锁(如:SELECT * FROM tbl with(nolock) WHERE id=1)。
3、一个查询join非常多的表易引起死锁,解决办法是使用临时表(其暂存在tempdb,每次会话结束就会释放):让一个原始表跟临时表进行join查询 → 临时表 → 原始表2进行join查询 → 临时表 → 原始表3进行join查询。同一时间只对一个表加s锁。
4、分库:水平分库,垂直分库。
5、数据库集群,读写分离 - 下面一些场景可以使用WITH(NOLOCK)
1: 数据很少变更的表:基础数据表、历史数据表。
3:业务允许出现脏读涉及的表。
4:数据量超大的表,出于性能考虑,而允许脏读。
[扩展]
- 深入浅出SQL Server中的死锁, 在多并发的环境中,死锁不可避免,只能尽量的优化查询/索引/隔离等级来降低死锁发生的可能性。
- T-SQL查询进阶—理解SQL Server中的锁
- 人为模拟一个死锁——使用sys.dm_tran_locks处理死锁问题。
- DMV(Dynamic Management Views,动态管理视图)是SQL Server内核的元数据,通过对这些元数据分析,从而进行性能分析。
- 当查询在SQL Server中运行时,SQL Server会自动的将此次活动的相关信息记录下来,并且保存在内存之中,这些活动信息,就称之为:DMV。
- DMV只会在2005及以上的版本存在,2000没有引用DMV的概念。
- SQL中利用DMV进行数据库性能分析
- sql优化之(DMV)
- SQL Profiler工具简介 ,Profiler可以用自定义一个跟踪模板,更多见“跟踪模板”部分。
- 一般企业DB优化历程:加硬件 → 分库(水平分库→垂直分库) → 数据库集群 → 用缓存
- 水平分库:(1个系统有1台web服务器1台DB服务器,通过为活跃数据表增加对应history表方式缓解常用表压力;或主副库放多台服务器来分摊压力)
1、数据库文件放到不同服务器硬盘上,充分利用磁盘的IO性能。
2、表分区,一个大表,分拆到不同文件里。按某个条件(如日期)分区。分拆的数据文件放到不同服务器硬盘里。
3、主动分区:当前表,放近“3天”(时间根据实际情况确定)数据,表只有主键索引,不加其他索引,写频繁时忌讳加过多的索引(因为写时会更新全表索引),历史数据放历史表。
-
垂直分库:(我的理解:1个系统有1台web服务器1台DB服务器,通过加机器把库拆分成n个库,然后放到n台DB服务器上,来分摊压力。如:csdn的博文数据库、收藏夹数据库)
1、把一个数据库根据业务模块分成多个数据库。用户相关的数据放到用户数据库。订单相关数据放到订单数据库上。如果同样的用户信息重复存在于不同业务系统数据库里,则弊端是数据同步很麻烦且会发生滞后问题!!!——我2014年到2018年期间维护的多个系统都有自己的用户信息表,他们这些用户信息同步方式是先从SAP同步数据到OA然后同步其他子系统。 -
数据库运维人员工作时间:凌晨2、3点。数据库可在“管理> 维护计划”每隔一段时间执行分表。
-
[数据库集群]:读写分离。但是有数据同步问题。“一个主库,多个从库” → “多主库,多从库”。互联网应用的最好用:MySQL、oracle,最好不用SQL server。
-
[缓存解决,磁盘IO瓶颈] 微博先放到Redis(解决读写瓶颈),然后再用MySQL保证数据完整性。
-
大表数据连接查询优化 临时表
数据库中有两个大表:userInfo(100w)、orderInfo(1000w)表,需要把所有用户数据和所有订单数据关联成一起后显示,如果直接连接查询,则要从笛卡尔集条数是“100w*1000w”条筛选,查询速度会很慢。
优化思路:分别对两个单表进行查询出的结果放到内存,在内存里组装数据。两个大表不能直接连接,表上锁时间不能过长。
1、把连接查询进行分解,转成单个大表的查询最后在内存组装数据。
2、使用临时表(select * into #tbl from userInfo),解决“查询频繁造成死锁问题” tbl1 inner join tbl2 on a.id=b.tid–查询会锁tbl1和tbl2,尽量减少在原始表上加锁。用临时表来降低原始表被锁的情况。- 表变量:一个变量但是是个表。
- 临时表:可以创建“本地和全局”临时表。本地临时表仅在当前会话中可见(sql 2008关闭“创建新查询”建的tab就是关闭会话);全局临时表在所有会话中都可见。##tbl,两个‘#’是全局临时表,一个‘#’是本地临时表。存储在tempdb数据库,在sysobjects 表可查询临时表信息。除非使用DROP TABLE 语句显式除去临时表,否则临时表将在退出其作用域时由系统自动除去。当创建全局临时表的会话结束时,最后一条引用此表的T-SQL语句完成后,将自动除去。
-
sql优化自己总结:一个表查询执行时间不能过长也不能过频繁,要连接的表尽量少,采用临时表连接。频繁写入的表尽量小,索引尽量少(最好只有PK索引)。注意s/x锁的问题。select语句where后面常用的字段巧用索引和WITH(NOLOCK)。
[扩展] 表变量、临时表 -
表变量在T-SQL语句执行结束后立刻自动被清除(选中下面SQL块,执行没问题,然后在单独选中
SELECT * FROM @tb1执行就会异常)。
DECLARE @tb1 Table
(
Id int,
Name varchar(20),
Age int
)
INSERT INTO @tb1 VALUES(1,'刘备',22)
SELECT * FROM @tb1
/*临时表与join的使用*/
SELECT soh.CustomerID ,
MIN(soh.OrderDate) AS OrderDate
INTO #MinOrderDates
FROM Sales.SalesOrderHeader soh
GROUP BY soh.CustomerID;
SELECT soh.CustomerID ,
soh.SalesOrderID ,
soh.OrderDate
FROM Sales.SalesOrderHeader soh
JOIN #MinOrderDates t ON soh.CustomerID = t.CustomerID
AND soh.OrderDate = t.OrderDate
GROUP BY soh.CustomerID;
DROP TABLE #MinOrderDates;
- 数据库开发步骤:根据需求分析文档 -> Excel粗略列出要用到表 -> 在数据库设计器中建表 -> 绘制各表的主外键关系 -> 在设计器中得到sql脚本 -> 在SQL Server 2008中执行sql脚本即完成数据库创建。在开发过着,DB设计器是一个设计DB直观、省力(帮你生成sql)、excel表格变成sql脚本的高效工具。这里推荐一个简单有效的设计器:EZDML(
fee) 。扩展:如何设计合理高效的数据库