"模式识别与机器学习"读书笔记——1.5 Decision Theory
经过之前的章节,我们应该可以做到通过训练数据训练后,给一个新的x,得到结果t的可能概率分布,比如通过一张新的x片得出这个人得癌症的概率分布如何,不得癌症的分布如何,然后做出最可能的选择决策。这章开始引入分类的概念,将所得结果分类,即所谓的决策。(既然已经知道概率了,选大的不就完了么?)
1.5.1 Minimizing the misclassification rate
通过前几节我们可以求出当照片为x时,其患癌症的概率分布与不患癌症的概率分布,本节就是要做决策到底哪些x是患癌症的,要确保决策的失误率最小。(感觉挺扯的,概率分布都求出来了,找概率大的不就完事儿了么,他使用了非常学术的方法最后得出了相同结论……)
这里的分类是针对输入进行的分类。比如在某段范围内的照片都归为癌症类,其他归为非癌症。
用一维输入举例最简单,书上也就举了个一维的例子。当x在R1范围内时,把其归为癌症类C1,当x在R2范围内时,把其归为非癌症类C2。
但是这种做法明显有一刀切的嫌疑,在R2范围内肯定有癌症患者,在R1范围内也肯定有误诊的,那么怎么确定R1,R2的范围能让这个失误率最小呢?
先确失误率的定量表述:
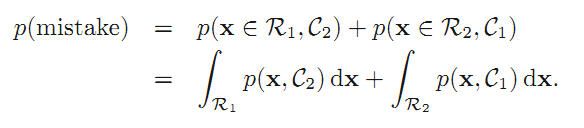
让这式子最小就行了,结论就是那个:如果p(x,C1)>p(x,C2),那么把x分类到C1类。
1.5.2 Minimizing the expected loss
同样是判断错误,把正常人判断成癌症患者与把癌症患者判断成正常人所造成的损失是截然不同的,因此应该区别对待错误。
引入了loss function或cost function,给不同的错误赋权值,可以用矩阵表示对应关系,然后算法稍微变下:让整个分类的错误值之和最小。
1.5.3 The reject option
对输入x,在有些区域,posterior probability很大趋近于1,这时机器做出的判断基本没错。而在有些区域那个概率不高,不方便做判断,所以就不应该由机器做判断,而是留给人类专家,这个区域就叫做reject option。
1.5.4 Inference and decision
现在开始进入实际应用。从拿到数据到分好类一般要走两步:求出posterior probability,然后用decision theory分类。
有三种方法:
a.求出P(Ck|x),p(x),再用决策论。有点多余,但可以把x出现概率也考虑进去,更精确。
b.求出P(Ck|x),再用决策论。比较通用
c.直接求离散的输入-分类对应关系f(x)。应用比较局限,不用求P(Ck|x)。
1.5.5 Loss functions for regression
用决策论的这种方法还可以解决回归问题。(那种多项式拟合)
要点就是让偏差最小,偏差(loss)的表示式为:
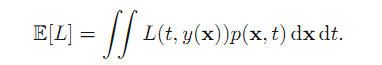
这个表达式从这张图的角度看还是很好理解的:
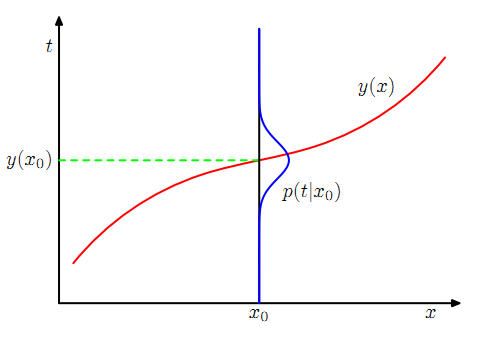
求导或用拆分的方法求出使E[L]最小,y(x)满足:
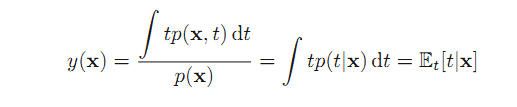
所以这种拟合的求法也有三种:
a.求出p(x,t),再normalize成p(t|x),带入上式。
b.求出p(t|x)带入上式。
c.直接从已知数据中推导y(x)