java学习笔记
第一个Java程序
- Java语言的平台
JavaME--Android JRE:Java程序的运行环境
JavaEE JDK:Java程序的开发环境
JRE: 包含JVM标准实现及Java核心类库。
JDK: 是整个java开发的核心,它包含了JAVA的运行环境(JVM+Java系统类库)和JAVA工具。
java语言特点:简单性,面向对象,分布式,健壮性,安全性,体系结构中立,可移植性,解释型,高性能,多线程,动态性
- path和classpath的区别
classpath环境变量里记录的是 java类的运行文件 所在的目录
- 打开CMD,运行javac、java检验是否安装成功
- 我要求文件名称和类名一致。实际上不这样做也是可以的。但是,注意:
关键字
被Java语言赋予特定含义的单词 全部小写 goto和const作为保留字存在。
标识符
给类,接口,方法,变量等起名字的字符序列
组成规则:
A:英文大小写字母
B:数字
C:$和_
注意事项:
A:不能以数字开头
B:不能是java中的关键字
C:区分大小写
A:包 全部小写
单级包:小写
多级包:小写,并用 . 隔开(代码中)
举例:com.baidu
B:类或者接口
大驼峰
举例:HelloWorld,StudentName
C:方法或者变量
小驼峰
举例:studentAge
D:常量
全部大写
一个单词:大写
举例:PI
多个单词:大写,并用 _ 隔开
举例:STUDENT_MAX_AGE
注释
(1)就是对程序进行解释说明的文字
(2)分类:
A:单行注释 //
B:多行注释 /* */
C:文档注释(后面讲) /** */
常量
(1)在程序执行的过程中,其值不发生改变的量
(2)分类:A:字面值常量
B:自定义常量(后面讲)
(3)字面值常量A:字符串常量 "hello"
B:整数常量 12,23
C:小数常量 12.345
D:字符常量 'a','A','0'
E:布尔常量 true,false
F:空常量 null(后面讲)
A: 二进制 由0,1组成。以0b开头。
B: 八进制 由0,1,...7组成。以0开头。
C: 十进制 由0,1,...9组成。整数默认是十进制。
D: 十六进制 由0,1,...9,a,b,c,d,e,f(大小写均可)组成。以0x开头。
进制转换
(1)其他进制到十进制系数:就是每一个位上的数值
基数:x进制的基数就是x
权:对每一个位上的数据,从右,并且从0开始编号,对应的编号就是该数据的权。
结果:系数*基数^权次幂之和。
(2)十进制到其他进制除基取余,直到商为0,余数反转。
(3)进制转换的快速转换法A:十进制和二进制间的转换
8421码。
B:二进制到八进制,十六进制的转换
变量
(1)在程序的执行过程中,其值在某个范围内可以发生改变的量(2)变量的定义格式:
A:数据类型 变量名 = 初始化值; int a = 10;
B:数据类型 变量名; int a;
变量名 = 初始化值; a = 10;
成员变量:有默认值
数据类型
(1)Java是一种强类型语言,针对每种数据都提供了对应的数据类型。A:基本数据类型:4类8种
B:引用数据类型:类,接口,数组。
(3)基本数据类型
A:整数。 占用字节数
byte 字节 1
short 短 整数 2
int 整数 4
long 长整数 8
B:浮点数。
float 单精度 4
double 双精度 8
C:字符。
char 2
D:布尔。
boolean 1
注意:
整数默认是int类型,浮点数默认是double。
长整数要加L或者l。
单精度的浮点数要加F或者f。
- java语言采用Unicode编码表, 它为每种语言中的每个字符设定了统一并且唯一的二进制编码,Unicode码扩展自ASCII字元集。 编码从0到127的字符与ASCII编码的字符一样。
- 字符串数据和其他数据做+拼接运算,结果是字符串类型。 这里的+不是加法运算,而是字符串连接符。
System.out.println(“hello!” +3*4); //最后结果是hello!12
数据类型转换
(2)默认转换
A:从小到大
B:byte,short,char -- int -- long -- float -- double
(3)强制转换
A:从大到小
B:可能会有精度的损失,一般不建议这样使用。
C:格式:
目标数据类型 变量名 = (目标数据类型) (被转换的数据); 被转换的数据如果是一个数值可以不加括号
注意:
运算符
(1)算术运算符A:+,-,*,/,%,++,--
a:他们的作用是自增或者自减
b:使用
**单独使用放在操作数据的前面和后面效果一样。
a++或者++a效果一样。
**参与操作使用放在操作数的前面:先自增或者自减,再参与操作
int a = 10;
int b = ++a; //int b = 11;
放在操作数的后面:先参与操作,再自增或者自减
int a = 10;
int b = a++; //int b = 10;
(2)赋值运算符A:=,+=,-=,*=,/=,%=等
B:=叫做赋值运算符,也是最基本的赋值运算符
int x = 10; 把10赋值给int类型的变量x。
C:扩展的赋值运算符的特点
隐含了自动强制转换。
short s=1;s = s+1; //错误: 不兼容的类型: 从int转换到short可能会有损失
short s=1;s+=1; //没问题
为什么第二个没有问题呢?
扩展的赋值运算符其实隐含了一个强制类型转换。
s += 1;
不是等价于 s = s + 1;
而是等价于 s = (s的数据类型)(s + 1);
(3)比较运算符
A:==,!=,>,>=,<,<=
B:无论运算符两端简单还是复杂最终结果是boolean类型。
4)逻辑运算符
A:&,|,^,!,&&,||
B:逻辑运算符用于连接boolean类型的式子
C:结论
&:有false则false
|:有true则true
^:相同则false,不同则true。
情侣关系。
!:非true则false,非false则true
&&:结果和&是一样的,只不过有短路效果。左边是false,右边不执行。
||:结果和|是一样的,只不过有短路效果。左边是true,右边不执行。
(5)位运算符(了解)
A:^的特殊用法
一个数据针对另一个数据位异或两次,该数不变 同一变量与另一变量和其异或值异或等于另一个数,如(a^b)^a=b。 //a^a=0
(6)三元运算符A:格式
比较表达式?表达式1:表达式2;
B:执行流程:
首先计算比较表达式的值,看是true还是false。
如果是true,表达式1就是结果。
如果是false,表达式2就是结果。
int a = ( a > b ) ? a : c;
三元运算符是一个运算符,运算符操作完毕就应该有一个结果。不可以是输出语句。
键盘录入
如何实现呢?目前就记住A:导包
import java.util.Scanner;
位置:在class的上边
B:创建对象
Scanner sc = new Scanner(System.in);
C:获取数据
int x = sc.nextInt();
import java.util.Scanner;
class ScannerDemo {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int x = sc.nextInt();
System.out.println("你输入的数据是:"+x);
}
}
流程控制语句
(1)顺序结构 从上往下,依次执行(2)选择结构 按照不同的选择,执行不同的代码
(3)循环结构 做一些重复的代码
选择结构
if语句
(1)三种格式A:格式1
if(比较表达式) {
语句体;
}
执行流程:
判断比较表达式的值,看是true还是false
如果是true,就执行语句体
如果是false,就不执行语句体
B:格式2
if(比较表达式) {
语句体1;
}else {
语句体2;
}
执行流程:
判断比较表达式的值,看是true还是false
如果是true,就执行语句体1
如果是false,就执行语句体2
C:格式3
if(比较表达式1) {
语句体1;
}else if(比较表达式2){
语句体2;
}
...
else {
语句体n+1;
}
执行流程:
判断比较表达式1的值,看是true还是false
如果是true,就执行语句体1
如果是false,就继续判断比较表达式2的值,看是true还是false
如果是true,就执行语句体2
如果是false,就继续判断比较表达式3的值,看是true还是false
...
如果都不满足,就执行语句体n+1
(2)注意事项
A:比较表达式无论简单还是复杂,结果是boolean类型
B:if语句控制的语句体如果是一条语句,是可以省略大括号的;如果是多条,不能省略。
建议:永远不要省略。
D:else后面如果没有if,是不会出现比较表达式的。
E:三种if语句其实都是一个语句,只要有一个执行,其他的就不再执行。
if语句是可以嵌套使用的。而且是可以任意的嵌套。
(4)三元运算符和if语句第二种格式的关系
所有的三元运算符能够实现的,if语句的第二种格式都能实现。
反之不成立。
如果if语句第二种格式控制的语句体是输出语句,就不可以。
因为三元运算符是一个运算符,必须要有一个结果返回,不能是一个输出语句。
switch语句
(1)格式:switch(表达式) {
case 值1:
语句体1;
break;
case 值2:
语句体2;
break;
...
default:
语句体n+1;
break;
}
格式解释说明:
switch:说明这是switch语句。
表达式:可以是byte,short,int,char
JDK5以后可以是枚举
JDK7以后可以是字符串
case:后面的值就是要和表达式进行比较的值
break:表示程序到这里中断,跳出switch循环语句
default:如果所有的情况都不匹配,就执行这里,相当于if语句中的else
注意事项:
A:case后面只能是常量,不能是变量,而且,多个case后面的值不能出现相同的
B:default可以省略吗?
可以省略,但是不建议,因为它的作用是对不正确的情况给出提示。
特殊情况:
case就可以把值固定。
A,B,C,D
C:break可以省略吗?
可以省略,但是结果可能不是我们想要的。
会出现一个现象:case穿透。
最终我们建议不要省略
D:default一定要在最后吗?
不是,可以在任意位置。但是建议在最后。
E:switch语句的结束条件
a:遇到break就结束了
b:执行到末尾就结束了
if语句和switch语句各自的场景
A:if
针对boolean类型的判断
针对一个范围的判断
针对几个常量的判断
B:switch
针对几个常量的判断
循环语句
有三种:for,while,do...whilefor循环语句
A:格式for(初始化语句;判断条件语句;控制条件语句){
循环体语句;
}
执行流程:
a:执行初始化语句
b:执行判断条件语句
如果这里是true,就继续
如果这里是false,循环就结束
c:执行循环体语句
d:执行控制条件语句
e:回到b
while循环
A:基本格式while(判断条件语句) {
循环体语句;
}
扩展格式:初始化语句;
while(判断条件语句){
循环体语句;
控制条件语句;
}
通过查看这个格式,我们就知道while循环可以和for循环等价转换。 for和while的区别:
a:使用上的区别for语句的那个控制条件变量,在循环结束后不能在使用了。
而while的可以继续使用。
b:理解上的区别
for适合于一个范围的判断
while适合次数不明确的
do...while循环
A:基本格式do {
循环体语句;
}while(判断条件语句);
扩展格式:
初始化语句;
do {
循环体语句;
控制条件语句;
}while(判断条件语句);
通过查看格式,我们就可以看出其实三种循环的格式可以是统一的。
B:三种循环的区别
a:do...while循环至少执行一次循环体
b:for和while必须先判断条件是否是true,然后后才能决定是否执行循环体
循环使用的注意事项(死循环)
A:一定要注意修改控制条件,否则容易出现死循环。
B:最简单的死循环格式
a:while(true){...}
b:for(;;){}
控制跳转语句
(1)break:中断的意思A:用在循环和switch语句中,离开此应用场景无意义。
B:作用
a:跳出单层循环
b:跳出多层循环,需要标签语句的配合(标签名就是起个名字)
格式:
标签名: 语句
wc:for(int x=0; x<3; x++) {
nc:for(int y=0; y<4; y++) {
if(y == 2) {
//break nc;
break wc;
}
System.out.print("*");
}
System.out.println();
}
A:用在循环中,离开此应用场景无意义。
B:作用
a:跳出单层循环的一次,可以继续下一次
(3)return:返回
A:用于结束方法的,后面还会在继续讲解和使用。
B:一旦遇到return,程序就不会在继续往后执行。
方法
//下面引用《疯狂Java讲义》中的一段话。
48
49 因为Java里的方法不能独立存在,它必须属于一个类或一个对象,
50 因此方法也不能直接像函数那样被独立执行,执行方法时必须使用
51 类或对象作为调用者,即所有的方法都必须使用“类.方法”或“对象.方法”
52 的形式来调用。这里可能产生一个问题:同一个类里不同方法之间相互调用
53 时,不就可以直接调用吗?这里需要指出的是:同一个类的一个方法调用另一个
54 方法时,如果被调用方法是普通方法,则默认使用this作为调用者;如果被调用
55 方法是静态方法,则默认使用类作为调用者(静态只能被静态调用)。也就是说表面上看起来某些方法可以
56 被独立执行,但实际上还是使用this或类来作为调用者。格式:
修饰符 返回值类型 方法名(参数类型 参数名1,参数类型 参数名2...) {
方法体语句;
return 返回值;
}
修饰符:目前就用 public static。后面再详细讲解其他修饰符
参数分类:
实参:实际参与运算的数据
形参:方法上定义的,用于接收实际参数的变量
方法调用
A:有明确返回值的方法
a:单独调用,没有意义
b:输出调用,不是很好,因为我可能需要不结果进行进一步的操作。但是讲课一般我就用了。
c:赋值调用,推荐方案
B:void类型修饰的方法
a:单独调用 //没有明确的返回值
A: 方式1:单独调用
sum(x,y); //sum是方法名,x,y是实际参数
方式2:输出调用
System.out.println(sum(x,y));
方式3:赋值调用
int c = sum(x,y);
System.out.println(c);
示例方法:public static int sum(int a,int b) {
int c = a + b;
return c;
//c就是a+b,所以,我可以直接返回a+b
//return a + b;
B:void 单独调用
pringXing(3,4);
输出调用
此处不允许使用 '空' 类型
System.out.println(pringXing(3,4));
赋值调用
非法的表达式开始
void v = pringXing(3,4);
示例方法:public static void pringXing(int a,int b) {
int c = a+b;
System.out.println(c);
方法的注意事项
A:方法不调用不执行
B:方法之间是平级关系,不能嵌套定义
C:方法定义的时候,参数是用,隔开的
D:方法在调用的时候,不用在传递数据类型
E:如果方法有明确的返回值类型,就必须有return语句返回。
方法重载
在同一个类中,方法名相同,参数列表不同。与返回值无关。参数列表不同:
a:参数的个数不同。
b:参数的对应的数据类型不同。
数组
(1)数组:存储同一种数据类型的多个元素的容器。
(2)特点:每一个元素都有编号,从0开始,最大编号是长度-1。
编号的专业叫法:索引
注意:数组提供了一个属性length,用于获取数组的长度。
格式:数组名.length
* length() 针对字符串
A:数据类型[] 数组名; //推荐
B:数据类型 数组名[];
(4)数组的初始化
A:动态初始化
只给长度,系统给出默认值
举例:int[] arr = new int[3];
B:静态初始化
给出值,系统决定长度
举例:int[] arr = new int[]{1,2,3};
简化版:int[] arr = {1,2,3};
(5)Java的内存分配
A:栈 存储局部变量 //基本类型:形式参数的改变对实际参数没有影响。
B:堆 存储所有new出来的 //引用类型:形式参数的改变直接影响实际参数。
C:方法区(面向对象部分详细讲解)
D:本地方法区(系统相关)
E:寄存器(CPU使用)
注意:
a:局部变量 在方法里或者方法声明上定义的变量。 //成员变量 在类中方法外定义的变量(对象讲)
b:栈内存和堆内存的区别
栈:数据使用完毕,就消失。
堆:每一个new出来的东西都有地址
每一个变量都有默认值
byte,short,int,long 0
float,double 0.0
char '\u0000'
boolean false
引用类型 null
数据使用完毕后,在垃圾回收器空闲的时候回收。
数组操作的两个常见小问题:
ArrayIndexOutOfBoundsException:数组索引越界异常
原因:你访问了不存在的索引。
NullPointerException:空指针异常
原因:数组已经不在指向堆内存了。而你还用数组名去访问元素。
作用:请自己把所有的场景Exception结尾的问题总结一下。以后遇到就记录下来。
现象,原因,解决方案。
二维数组:就是元素为一维数组的一个数组。
格式1:
数据类型[][] 数组名 = new 数据类型[m][n];
m:表示这个二维数组有多少个一维数组。
n:表示每一个一维数组的元素有多少个。
注意:
A:以下格式也可以表示二维数组
a:数据类型 数组名 [][] = new 数据类型[m][n];
b:数据类型[] 数组名[] = new 数据类型[m][n];
格式2:
数据类型[][] 数组名 = new 数据类型[m][];
m:表示这个二维数组有多少个一维数组。
列数没有给出,可以动态的给。这一次是一个变化的列数。
class Array2Demo2 {
public static void main(String[] args) {
//定义数组
int[][] arr = new int[3][];
System.out.println(arr); //[[I@175078b 二维数组的地址值
System.out.println(arr[0]); //null 一维数组还没有给值,引用类型默认值为null
System.out.println(arr[1]); //nullSystem.out.println(arr[2]); //null
//动态的为每一个一维数组分配空间
arr[0] = new int[2];
arr[1] = new int[3];
arr[2] = new int[1];
System.out.println(arr[0]); //[I@42552c 给值后生成一维数组的地址值
System.out.println(arr[1]); //[I@e5bbd6System.out.println(arr[2]); //[I@8ee016
格式3:
基本格式:
数据类型[][] 数组名 = new 数据类型[][]{{元素1,元素2...},{元素1,元素2...},{元素1,元素2...}};
简化版格式:
数据类型[][] 数组名 = {{元素1,元素2...},{元素1,元素2...},{元素1,元素2...}};
举例:
int[][] arr = {{1,2,3},{4,5,6},{7,8,9}};
数组元素逆序,指的是把元素对调,不是逆着输出它。
面向对象
面向对象:面向对象是基于面向过程的编程思想
对象:对象是类的一个实例,有状态和行为。类:类是一个模板,它描述一类对象的行为和状态。
类:是一组相关的属性和行为的集合。是一个抽象的概念。
对象:是该类事物的具体存在,是一个具体的实例。(对象)
Java程序的开发,设计和特征
A:开发:就是不断的创建对象,通过对象调用功能
B:设计:就是管理和维护对象间的关系
C:特征
a:封装
b:继承
c:多态
成员变量和局部变量
成员变量和局部变量的区别(理解)
(1)在类中的位置不同
成员变量:类中方法外
局部变量:方法定义中或者方法声明上
(2)在内存中的位置不同成员变量:在堆中
局部变量:在栈中
(3)生命周期不同成员变量:随着对象的创建而存在,随着对象的消失而消失
局部变量:随着方法的调用而存在,随着方法的调用完毕而消失
(4)初始化值不同成员变量:有默认值
局部变量:没有默认值,必须定义,赋值,然后才能使用
局部变量初始化:
类作为形式参数的问题?(理解)
如果你看到了一个方法的形式参数是一个类类型(引用类型),这里其实需要的是该类的对象。
匿名对象
匿名对象:就是没有名字的对象。
匿名对象的应用场景:
A:调用方法,仅仅只调用一次的时候。 //匿名对象调用方法,如果还想再调用,
注意:调用多次的时候,不适合。 等于又创建了一个新的匿名对象。
那么,这种匿名调用有什么好处吗?
有,匿名对象调用完毕就是垃圾。可以被垃圾回收器回收。
B:匿名对象可以作为实际参数传递 //对象名.方法名(匿名对象())
//匿名对象
new Student();
//匿名对象调用方法new Student().show(); 、
new Student().show(); //这里其实是重新创建了一个新的对象
StudentDemo sd = new StudentDemo(); 、
//Student ss = new Student();
//sd.method(ss); //这里的ss是一个实际参数
//匿名对象作为实际参数传递sd.method(new Student());
//在来一个
new StudentDemo().method(new Student());
封装
private
this
我们曾经说过:起名字要做到见名知意。可是这样有时候会造成局部变量隐藏成员变量 (局部变量和成员变量同名)
this:是当前类的对象引用。简单的记,它就代表当前类的一个对象。
注意:谁调用这个方法,在该方法内部的this就代表谁。
也就是哪个对象调用那个方法,this就代表那个对象
this的应用场景:
解决局部变量隐藏成员变量
构造方法
(1)作用:用于对对象的数据进行初始化
(2)格式:
A:方法名和类名相同
B:没有返回值类型,连void都不能有
C:没有返回值
思考题:构造方法中可不可以有return语句呢?可以。我们写成这个样子就OK了:return;
其实,在任何的void类型的方法的最后你都可以写上:return; (没有东西可以返回)
(3)构造方法的注意事项A:如果我们没写构造方法,系统将提供一个默认的无参构造方法 public Student() {} //无参构造方法
B:如果我们给出了构造方法,系统将不再提供默认构造方法如果这个时候,我们要使用无参构造方法,就必须自己给出。
推荐:永远手动自己给出无参构造方法。
(4)给成员变量赋值的方式
A:setXxx() //调用方法赋值
B:带参构造方法 //Student s = new Student("林青霞");
每个类都有构造方法。如果没有显式地为类定义构造方法,Java编译器将会为该类提供一个默认构造方法。
在创建一个对象的时候,至少要调用一个构造方法。构造方法的名称必须与类同名,一个类可以有多个构造方法。
类的初始化顺序
(1)把Student.class文件加载到内存
(2)在栈内存为s开辟空间
(3)在堆内存为学生对象申请空间
(4)给学生的成员变量进行默认初始化。null,0 成员变量进行初始化
(5)给学生的成员变量进行显示初始化。林青霞,27 显示初始化
(6)通过构造方法给成员变量进行初始化。刘意,30 构造方法初始化
(7)对象构造完毕,把地址赋值给s变量、
static
(1)静态的意思。可以修饰成员变量和成员方法。
(2)静态的特点:A:随着类的加载而加载
B:优先与对象存在
C:被类的所有对象共享
针对多个对象有共同的这样的成员变量值的时候
这其实也是我们判断该不该使用静态的依据。举例:饮水机和水杯的问题思考
D:可以通过类名调用
既可以通过对象名调用,也可以通过类名调用,建议通过类名调用。
(3)静态的内存图静态的内容在方法区的静态区
(4)静态的注意事项;A:在静态方法中没有this对象
B:静态只能访问静态
(5)静态变量和成员变量的区别A:所属不同
静态变量:属于类,类变量
成员变量:属于对象,对象变量,实例变量
B:内存位置不同
静态变量:方法区的静态区
成员变量:堆内存
C:生命周期不同
静态变量:静态变量是随着类的加载而加载,随着类的消失而消失
成员变量:成员变量是随着对象的创建而存在,随着对象的消失而消失
D:调用不同
静态变量:可以通过对象名调用,也可以通过类名调用
成员变量:只能通过对象名调用
(6)main方法是静态的public:权限最大
static:不用创建对象调用
void: main方法被jvm调用,返回值给jvm没有意义
main:就是一个常见的方法入口。
String[] args:早期可以接收数据,提供程序的灵活性 (但是现在有了键盘录入)
格式:java MainDemo hello world javajava MainDemo 10 20 30
命令行上编译 java+类名+数值(举例hello world java)
相当于String[] args = {hello,world,java};
(7)static关键字注意事项
A:在静态方法中是没有this关键字的
如何理解呢? //静态加载的时候this指向的内容还不存在呢
静态是随着类的加载而加载,this是随着对象的创建而存在。
静态比对象先存在。
B:静态方法只能访问静态的成员变量和静态的成员方法
静态方法:
成员变量:只能访问静态变量
成员方法:只能访问静态成员方法
非静态方法:
成员变量:可以是静态的,也可以是非静态的
成员方法:可是是静态的成员方法,也可以是非静态的成员方法。
简单记:
静态只能访问静态。
代码块
代码块:在Java中,使用{}括起来的代码被称为代码块。
根据其位置和声明的不同,可以分为
局部代码块: 局部位置,用于限定变量的生命周期。
构造代码块: 在类中的成员位置,用{}括起来的代码。每次调用构造方法执行前,都会先执行构造代码块。
作用:可以把多个构造方法中的共同代码放到一起,对对象进行初始化。
静态代码块: 在类中的成员位置,用{}括起来的代码,只不过它用static修饰了。
作用:一般是对类进行初始化。
面试题?
静态代码块,构造代码块,构造方法的执行顺序?
静态代码块 -- 构造代码块 -- 构造方法
静态代码块:只执行一次 (随着加载类的时候执行一次)构造代码块:每次调用构造方法都执行
super
- 我不仅仅要输出局部范围的num,还要输出本类成员范围的num, (同名访问) 还想要输出父类成员范围的num。怎么办呢?
恭喜你,这个关键字是存在的:super。 指向父类
this代表本类对象的引用。
super 代表父类存储空间的标识(可以理解为父类引用,可以操作父类的成员)
继承
(1)把多个类中相同的成员给提取出来定义到一个独立的类中。然后让这多个类和该独立的类产生一个关系,
这多个类就具备了这些内容。这个关系叫继承。
(2)Java中如何表示继承呢?格式是什么呢?A:用关键字extends表示
B:格式:
class 子类名 extends 父类名 {}
(3)Java中继承的特点
A:Java中类只支持单继承,不支持多继承
B:Java中可以多层(重)继承(继承体系)
(4)继承的注意事项:A:子类不能继承父类的私有成员
B:子类不能继承父类的构造方法,但是可以通过super去访问
(子类会默认访问父类的构造方法,构造方法的第一条语句隐含了super())
虽然子类中构造方法默认有一个super()
初始化的时候,不是按照那个顺序进行的。
而是按照分层初始化进行的。
它仅仅表示要先初始化父类数据,再初始化子类数据。
它仅仅表示要先初始化父类数据,初始化了那还执行什么。
C:不要为了部分功能而去继承
Java继承中的成员关系
A:成员变量a:子类的成员变量名称和父类中的成员变量名称不一样。
b:子类的成员变量名称和父类中的成员变量名称一样,这个怎么访问呢?
子类的方法访问变量的查找顺序:
(就近原则) 在子类方法的局部范围找,有就使用。
在子类的成员范围找,有就使用。
在父类的成员范围找,有就使用。
找不到,就报错。
B:构造方法
a:子类的构造方法默认会先去访问父类的无参构造方法(子类没有访问父类的构造方法就会报错)
是为了子类访问父类数据的初始化
b:子类使用无参构造创建对象,而父类中如果没有无参构造方法,怎么办?
A:在父类中加一个无参构造方法
B:通过使用super关键字在调用的无参构造方法里显示的调用父类的带参构造方法
C:子类通过this去调用本类的其他构造方法
子类中一定要有一个去访问了父类的构造方法,否则父类数据就没有初始化。
子类中如果有其他的构造方法访问了父类的构造方法,就通过this去调用本类的其他构造方法。
class Father {
/*
public Father() {
System.out.println("Father的无参构造方法");
}
*/
public Father(String name) {
System.out.println("Father的带参构造方法");
}
}
class Son extends Father {
public Son() {
super("随便给");
System.out.println("Son的无参构造方法");
//super("随便给");
}
public Son(String name) {
//super("随便给");
this();
System.out.println("Son的带参构造方法");
}
}
class ExtendsDemo7 {
public static void main(String[] args) {
Son s = new Son();
System.out.println("----------------");
Son ss = new Son("林青霞");
}
} 注意事项:
this(...)或者super(...)必须出现在第一条语句上。
如果不是放在第一条语句上,就可能对父类的数据进行了多次初始化,所以必须放在第一条语句上。
如果第一行有了this()或其他,默认super()不存在
a:子类的成员方法和父类中的成员方法名称不一样,这个太简单
b:子类的成员方法和父类中的成员方法名称一样,这个怎么访问呢?
通过子类对象访问一个方法的查找顺序:
(就近原则) 在子类中找,有就使用
在父类中找,有就使用
找不到,就报错
方法重写
方法重写:子类中出现了和父类中方法声明一模一样的方法。
方法重载:本类中出现的方法名一样,参数列表不同的方法。与返回值无关。
子类对象调用方法的时候:
先找子类本身,再找父类。
方法重写的应用:
当子类需要父类的功能,而功能主体子类有自己特有内容时,可以重写父类中的方法。
这样,即沿袭了父类的功能,又定义了子类特有的内容。
方法重写的注意事项
A:父类中私有方法不能被重写
因为父类私有方法子类根本就无法继承
B:子类重写父类方法时,访问权限不能更低
最好就一致
C:声明为static的方法不能被重写,但是能够被再次声明。
D:构造方法不能被重写。
E:如果不能继承一个方法,则不能重写这个方法。
子类重写父类方法的时候,最好声明一模一样。
C:重写方法的目的是为了多态,或者说:重写是实现多态的前提,即重写是发生在继承中且是针对非static方法的。
语法上子类允许出现和父类只有方法体不一样其他都一模一样的static方法,但是在父类引用指向子类对象时,通过父类引用调用的依然是父类的static方法,而不是子类的static方法。
即:语法上static支持重写,但是运行效果上达不到多态目的
class Father {
public static void show() {
System.out.println("Father");
}
}
class Son extends Father {
// @Override 因为从逻辑上达不到重写的目的,所以这里添加 @Override 会编译报错
public static void show() {
System.out.println("Son");
}
}
public class M {
public static void main(String[] args) {
Father f = new Father();
Father fS = new Son();
Son s = new Son();
f.staticMethod(); // Father
fS.staticMethod(); // 这里返回的是Father而不是Son, static方法上重写不会报错,但是从逻辑运行效果上来看达不到多态的目的
s.staticMethod(); // Son
}
}
- 方法重写和方法重载的区别?方法重载能改变返回值类型吗?
在子类中,出现和父类中一模一样的方法声明的现象。
方法重载:
同一个类中,出现的方法名相同,参数列表不同的现象。
方法重载能改变返回值类型,因为它和返回值类型无关。
Override:方法重写 Overload:方法重载
方法的重写(Overriding)和重载(Overloading)是java多态性的不同表现,重写是父类与子类之间多态性的一种表现, 重载是一类中多态性的一种表现。
Java 修饰符
Java语言提供了很多修饰符,主要分为以下两类:访问修饰符、非访问修饰符;
访问控制修饰符
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java支持4种不同的访问权限。
1、默认的,也称为 default,在同一包内可见,不使用任何修饰符。
2、私有的,以 private 修饰符指定,在同一类内可见。
3、共有的,以 public 修饰符指定,对所有类可见。
4、受保护的,以 protected 修饰符指定,对同一包内的类和所有子类可见。非访问控制修饰符
为了实现一些其他的功能,Java 也提供了许多非访问修饰符。
static 修饰符,用来创建类方法和类变量
静态变量:
static 关键字用来声明独立于对象的静态变量,无论一个类实例化多少对象,它的静态变量只有一份拷贝。 静态变量也被成为类变量。局部变量不能被声明为 static 变量。
静态方法:
static 关键字用来声明独立于对象的静态方法。静态方法不能使用类的非静态变量。静态方法从参数列表得到数据,然后计算这些数据。
对类变量和方法的访问可以直接使用 classname.variablename 和 classname.methodname 的方式访问。
如下例所示,static修饰符用来创建类方法和类变量。
final 修饰符,用来修饰类、方法和变量
final 修饰的类不能够被继承,修饰的方法不能被继承类重新定义,修饰的变量为常量,是不可修改的。
final 变量
final 变量能被显式地初始化并且只能初始化一次。被声明为 final 的对象的引用不能指向不同的对象。但是 final 对象里的数据可以被改变。 也就是说 final 对象的引用不能改变,但是里面的值可以改变。
final 修饰符通常和 static 修饰符一起使用来创建类常量。
final 方法
类中的 final 方法可以被子类继承,但是不能被子类修改。
声明 final 方法的主要目的是防止该方法的内容被修改。
如下所示,使用 final 修饰符声明方法。
final 类
final 类不能被继承,没有类能够继承 final 类的任何特性。
abstract 修饰符,用来创建抽象类和抽象方法
抽象类
抽象类不能用来实例化对象,声明抽象类的唯一目的是为了将来对该类进行扩充。
一个类不能同时被 abstract 和 final 修饰。如果一个类包含抽象方法,那么该类一定要声明为抽象类,否则将出现编译错误。
抽象类可以包含抽象方法和非抽象方法。
抽象方法
抽象方法是一种没有任何实现的方法,该方法的的具体实现由子类提供。
抽象方法不能被声明成 final 和 static。
任何继承抽象类的子类必须实现父类的所有抽象方法,除非该子类也是抽象类。
如果一个类包含若干个抽象方法,那么该类必须声明为抽象类。抽象类可以不包含抽象方法。
抽象方法的声明以分号结尾,例如:public abstract sample();。
synchronized 修饰符
synchronized 关键字声明的方法同一时间只能被一个线程访问。synchronized 修饰符可以应用于四个访问修饰符。
transient 修饰符
序列化的对象包含被 transient 修饰的实例变量时,java 虚拟机(JVM)跳过该特定的变量。
该修饰符包含在定义变量的语句中,用来预处理类和变量的数据类型。
volatile 修饰符
volatile 修饰的成员变量在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
一个 volatile 对象引用可能是 null。
多态
(1)同一个对象在不同时刻体现出来的不同状态。(2)多态的前提:
A:有继承或者实现关系。
B:有方法重写。 //其实没有也是可以的,但是如果没有这个就没有意义。
C:有父类或者父接口引用指向子类对象。(即向上转型)
多态的分类:
a:具体类多态
class Fu {}
class Zi extends Fu {}
Fu f = new Zi();
b:抽象类多态
abstract class Fu {}
class Zi extends Fu {}
Fu f = new Zi();
c:接口多态
interface Fu {}
class Zi implements Fu {}
Fu f = new Zi();
(3)多态中的成员访问特点A:成员变量
编译看左边,运行看左边
B:构造方法
子类的构造都会默认访问父类构造,对父类的数据进行初始化。
C:成员方法
编译看左边,运行看右边
D:静态方法
编译看左边,运行看左边
(静态和类相关,算不上重写,所以,访问还是左边的)
为什么?
因为成员方法有重写,所以它运行看右边。
(4)多态的好处:A:提高代码的维护性(继承体现)
B:提高代码的扩展性(多态体现)
(5)多态的弊端:父不能使用子的特有功能。
现象:
子可以当作父使用,父不能当作子使用。
向上转型
子类引用的对象转换为父类类型称为向上转型。通俗地说就是是将子类对象转为父类对象。此处父类对象可以是接口。
注意:向上转型时,子类单独定义的方法会丢失。
我们可以 A:创建子类对象调用方法即可。(可以,但是很多时候不合理。而且,太占内存了)
B:把父类的引用强制转换为子类的引用。(向下转型)
向下转型
与向上转型相对应的就是向下转型了。向下转型是把父类对象转为子类对象。
- 向下转型的前提是父类对象指向的是子类对象(也就是说,在向下转型之前,它得先向上转型)
向下转型只能转型为本类对象(猫是不能变成狗的)。要求该f必须是能够转换为Zi的。
ClassCastException:类型转换异常
一般在多态的向下转型中容易出现
class Fu {
public void show() {
System.out.println("show fu");
}
}
class Zi extends Fu {
public void show() {
System.out.println("show zi");
}
public void method() {
System.out.println("method zi");
}
}
class DuoTaiDemo4 {
public static void main(String[] args) {
//测试
Fu f = new Zi();
f.show();
//f.method();
//创建子类对象
//Zi z = new Zi();
//z.show();
//z.method();
//你能够把子的对象赋值给父亲,那么我能不能把父的引用赋值给子的引用呢?
//如果可以,代码如下
Zi z = (Zi)f;
z.show();
z.method();
}
}抽象类
在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。
就像我们上面中的例子一样。Dog狗和Cat猫可以用一个普通类来描绘,但是Animal动物不可以,Animal就应该是一个抽象类。
(1)抽象类的特点:
A:抽象类和抽象方法必须用abstract关键字修饰
B:抽象类中不一定有抽象方法,但是有抽象方法的类必须定义为抽象类
C:抽象类不能被实例化
因为它不是具体的。
D:抽象的子类
a:是一个抽象类。
b:是一个具体类。这个类必须重写抽象类中的所有抽象方法。
抽象类的实例化其实是靠具体的子类实现的。是多态的方式。
Animal a = new Cat();
//abstract class Animal //抽象类的声明格式
abstract class Animal {
//抽象方法
//public abstract void eat(){} //空方法体,这个会报错。抽象方法不能有主体
public abstract void eat();
public Animal(){} //构造方法
}
//子类是抽象类
abstract class Dog extends Animal {}
//子类是具体类,重写抽象方法
class Cat extends Animal {
public void eat() {
System.out.println("猫吃鱼");
}
}(2)抽象类的成员特点:
A:成员变量
既可以是变量,也可以是常量
B:构造方法
有构造方法
C:成员方法
既可以是抽象的,也可以是非抽象的
(3)一个类如果没有抽象方法,可不可以定义为抽象类?如果可以,有什么意义?
A:可以。
B:不让创建对象。
abstract不能和哪些关键字共存?
private 冲突 //虽然可以通过公共方法访问 但是私有的不能被继承也就无法被重写
final 冲突 //final可以修饰类,该类不能被继承;修饰方法,该方法不能被重写
static 无意义 //静态方法可以通过类名调用,但是抽象方法没有方法体,调用它无意义,
接口
(1)接口的特点:A:接口用关键字interface修饰
interface 接口名 {}
B:类实现接口用implements修饰
class 类名 implements 接口名 {}
C:接口不能实例化
D:接口的实现类
a:是一个抽象类。
b:是一个具体类,这个类必须重写接口中的所有抽象方法。
(2)接口的成员特点:A:成员变量
只能是常量
默认修饰符:public static final
B:构造方法
没有构造方法 //因为接口主要是扩展功能的,而没有具体存在
C:成员方法
只能是抽象的
默认修饰符:public abstract 建议:永远自己手动给出。
(3)类与类,类与接口,接口与接口A:类与类
继承关系,只能单继承,可以多层继承
B:类与接口
实现关系,可以单实现,也可以多实现。
还可以在继承一个类的同时,实现多个接口
C:接口与接口
继承关系,可以单继承,也可以多继承
抽象类和接口的区别:
A:成员区别
抽象类:
成员变量:可以变量,也可以常量
构造方法:有
成员方法:可以抽象,也可以非抽象
接口:
成员变量:只可以常量
成员方法:只可以抽象
B:关系区别
类与类
继承,单继承,多层继承
类与接口
实现,单实现,多实现
接口与接口
继承,单继承,多继承
C:设计理念区别 (狗是动物)
抽象类 被继承体现的是:"is a" 的关系。抽象类中定义的是该继承体系的共性功能。
接口 被实现体现的是:"like a" 的关系。接口中定义的是该继承体系的扩展功能。
(狗像人一样站立)
或者:抽象类表示的是,这个对象是什么。接口表示的是,这个对象单独能做什么。
抽象类一般作为公共的父类为子类的扩展提供基础,这里的扩展包括了属性上和行为上的。而接口一般来说不考虑属性,只考虑方法,使得子类可以自由的填补或者扩展接口所定义的方法。
形式参数和返回值的问题
(1)形式参数:类名:需要该类的对象
抽象类名:需要该类的子类对象
接口名:需要该接口的实现类对象
(2)返回值类型:类名:返回的是该类的对象
抽象类名:返回的是该类的子类对象
接口名:返回的是该接口的实现类的对象
链式编程
对象.方法1().方法2().......方法n();这种用法:其实在方法1()调用完毕后,应该返回一个对象;
方法2()调用完毕后,应该返回一个对象。
方法n()调用完毕后,可能是对象,也可以不是对象。
包
(1)其实就是文件夹
(2)作用:A:区分同名的类,把相同的类名放到不同的包中
B:对类进行分类管理
a:按照功能分
b:按照模块分
(3)包的定义package 包名;
多级包用.分开。
(4)注意事项:A:package语句必须在文件中的第一条有效语句
B:在一个java文件中,只能有一个package
C:如果没有package,默认就是无包名
(5)带包的编译和运行A:手动式
a:编写一个带包的java文件。
b:通过javac命令编译该java文件。
c:手动创建包名。
d:把b步骤生成的class文件放到c步骤的最底层包
e:回到和包根目录在同一目录的地方,然后运行
d:带包运行。
javac编译的时候带上-d即可
javac -d . Demo.java
导包
(1)我们多次使用一个带包的类,非常的麻烦,这个时候,Java就提供了一个关键字import。不同包下的类之间的访问
(2)格式:import 包名...类名;
另一种:
import 包名...*; 表示导入这个包下的所有类,使用的时候逐一匹配(不建议)
(3)面试题:package,import,class有没有顺序关系?
有。
package > import > class
Package:只能有一个
import:可以有多个
class:可以有多个,以后建议是一个
修饰符
(1)修饰符分类:权限修饰符:private,default,protected,public
状态修饰符:static,final
抽象修饰符:abstract
(2)常见的类及其组成的修饰:类:
public, default, final,abstra ct. (private:只能修饰内部类,一般不推荐使用)
常用的:public
成员变量:
private,default,protected,public,static,final
常用的:private
构造方法:
public, private, protected
常用的:public
成员方法:
public, private,default,protected,static,final,abstract
常用的:public
除此以外的组合规则:
成员变量:public static final int a = 10; final 修饰符通常和 static 修饰符一起使用来创建类常量。
成员方法:public static 静态
public abstract 抽象
public final 它修饰的方法,不能被重写。
(3)权限修饰符
本类 同一个包下 不同包下的子类 不同包下的无关类
private Y
默认 Y Y
protected Y Y Y
public Y Y Y Y
Java中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。Java支持4种不同的访问权限。
1、默认的,也称为 default,在同一包内可见,不使用任何修饰符。(包(package)访问权限)
2、私有的,以 private 修饰符指定,在同一类内可见。 (当前类访问权限)
3、共有的,以 public 修饰符指定,对所有类可见。 (公共访问权限)
4、受保护的,以 protected 修饰符指定,对同一包内的类和所有子类可见。(子类访问权限)
(4)这四种权限修饰符在任意时刻只能出现一种。
public class Demo {}
内部类
(1)把类定义在另一个类的内部,该类就被称为内部类。
内部类是一种非常有用的特性,因为它允许你把一些逻辑相关的类组织在一起。
举例:把类B定义在类A中,类B就被称为内部类。
(2)内部类的访问规则A:可以直接访问外部类的成员,包括私有
B:外部类要想访问内部类成员,必须new一个内部类对象
在外部类中可以访问到内部类的任何变量,包括私有变量。
A:成员内部类
B:局部内部类
成员内部类
在成员位置定义的类,被称为成员内部类。
(1)成员内部类的修饰符:
A:private 为了数据的安全性B:static 为了访问的方便性
- 静态内部类中的静态方法可以通过【外部类.内部类.方法名】直接调用
成员内部类不是静态的:
外部类名.内部类名 对象名 = new 外部类名().new 内部类名();
成员内部类是静态的:
外部类名.内部类名 对象名 = new 外部类名.内部类名();
(2)在内部类中,可以通过【.this】访问到外部类。
class Outer {
public int num = 10;
class Inner {
public int num = 20;
public viod show() {
int num = 30;
System.out.println(num); //30 就近原则
System.out.println(this.num); //20 内部类变量 //System.out.println(new Outer.num); //10 可以这样或者 // 通过外部类名限定this对象
System.out.println(Outer.this.num); //10 外部类变量
}
}
}静态内部类
- 只有将某个内部类修饰为静态类,然后才能够在这个类中定义静态的成员变量与成员方法。这是静态内部类都有的一个特性。
- 非静态内部类也可以定义静态成员但需要同时有final关键词修饰,静态方法鉴于无法用final修饰,仍必须是在静态内部类或者非内部类中定义。
- public static final int a = 10; final 修饰符通常和 static 修饰符一起使用来创建类常量。
- 在创建静态内部类时不需要将静态内部类的实例绑定在外部类的实例上。
通常情况下,在一个类中创建成员内部类的时候,有一个强制性的规定,即内部类的实例一定要绑定在外部类的实例中。也就是说,在创建内部类之前要先在外部类中要利用new关键字来创建这个内部类的对象。如此的话如果从外部类中初始化一个内部类对象,那么内部类对象就会绑定在外部类对象上。也就是说,普通非静态内部类的对象是依附在外部类对象之中的。但是,如果成员开发人员创建的时静态内部类,那么这就又另当别论了。通常情况下,程序员在定义静态内部类的时候,是不需要定义绑定在外部类的实例上的。也就是说,要在一个外部类中定义一个静态的内部类,不需要利用关键字new来创建内部类的实例。即在创建静态类内部对象时,不需要其外部类的对象。
一般程序开发人员可以这么理解,非静态的内部类对象隐式地在外部类中保存了一个引用,指向创建它的外部类对象。
- 在静态内部类中可以存在静态成员和非静态成员
- 静态内部类,不管是静态方法还是非静态方法,只能访问外围类的静态成员变量和方法,不能访问外围类的非静态成员变量和方法
- 静态内部类中的静态方法可以通过【外部类.内部类.方法名】直接调用
- 静态内部类在其他类中不能new出来。
- 但是在外部类中,可以new一个静态内部类的对象。
- 静态内部类中不能使用【.this】
局部内部类
在一个方法里或者任意作用域里定义的内部类叫做局部内部类。
局部内部类
A:可以直接访问外部类的成员
B:在局部位置,可以创建内部类对象,通过对象调用内部类方法,来使用局部内部类功能
面试题:
局部内部类访问局部变量的注意事项?
A:局部内部类访问局部变量必须用final修饰 (匿名内部类也属于)
B:为什么呢?
局部变量是随着方法的调用而调用,随着调用完毕而消失。
而堆内存的内容并不会立即消失。所以,我们加final修饰。
加入final修饰后,这个变量就成了常量。既然是常量。你变量消失了。
我在内存中存储的是数据,所以,我还是有数据在使用。
class Outer {
private int num = 10;
public void method() {
//int num2 = 20; //局部变量栈中,调用完毕消失。
final int num2 = 20; //加入final修饰,成为常量。
class Inner { //堆中,不会立即消失。
public void show() {
System.out.println(num);
//从内部类中访问本地变量num2; 需要被声明为最终类型
System.out.println(num2);//20
}
}
//System.out.println(num2);
Inner i = new Inner();
i.show(); // 访问已经消失的局部变量,报错。
}
}匿名内部类
(1)匿名内部类
就是内部类的简化写法。
前提:存在一个类或者接口
这里的类可以是具体类也可以是抽象类。
格式:
new 类名或者接口名(){
重写方法;
}
本质是什么呢?
是一个继承了该类或者实现了该接口的子类匿名对象。这样就不用再写一个实现类了
(2)匿名内部类在开发中的使用
我们在开发的时候,会看到抽象类,或者接口作为参数。
而这个时候,我们知道实际需要的是一个子类对象。
如果该方法仅仅调用一次,我们就可以使用匿名内部类的格式简化。
- 匿名内部类是没有访问修饰符的。
匿名内部类中不能存在任何的静态成员变量和静态方法。 - new 匿名内部类或接口,这个类或接口首先是要存在的。
- 当所在方法的形参需要被匿名内部类使用,那么这个形参就必须为final。
- 匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
API
Object
Object:类 Object 是类层次结构的根类。每个类都使用 Object 作为超类。每个类都直接或者间接的继承自Object类。
Object类的方法:
1.public int hashCode():返回该对象的哈希码值。
public static String toHexString(int i)是Integer类下的一个静态方法:把一个整数转成一个十六进制表示的字符串
直接输出一个对象的名称,其实就是调用该对象的toString()方法:
toString()方法的值等价于它:
getClass().getName() + '@' + Integer.toHexString(hashCode())
3. Object 类的 equals 方法:public boolean equals(Object obj):指示其他某个对象是否与此对象“相等”。
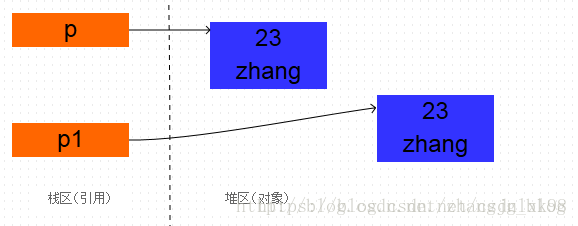
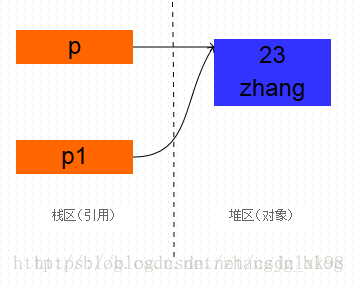
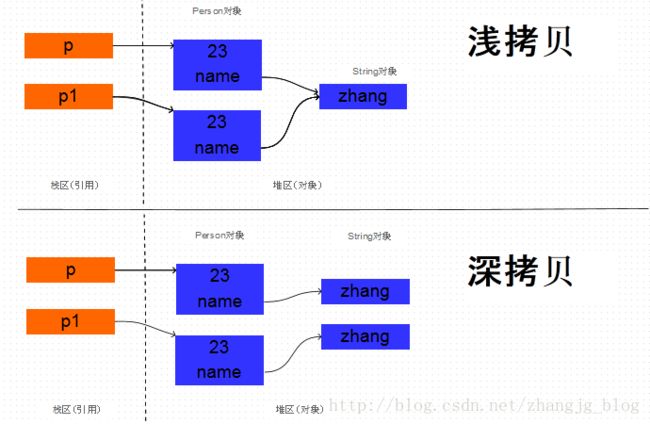
clone方法是浅拷贝的,实现了对象的克隆,包括成员变量的数据复制,两个对象的地址是不同的,也就是说创建了新的对象.
Studebt p = new Student(23,"zhang"); Student p1 = (Student)p.clone();
Scanner
A:先获取一个数值后,在创建一个新的键盘录入对象获取字符串。
B:把所有的数据都先按照字符串获取,然后要什么,你就对应的转换为什么。
c:可以再nextInt()方法后面多加一句nextLine()方法专门用来取出缓冲区中留下的空白符,像这样:
+扫描器在扫描过程中判断停止的依据就是“空白符”,空格啊,回车啊什么的都算做是空白符。
nextInt()方法在扫描到空白符的时候会将前面的数据读取走,但会丢下空白符“\r”在缓冲区中,
但是,nextLine()方法在扫描的时候会将扫描到的空白符一同清理掉。
nextInt()方法之后在缓冲区中留下了“\r”,然后nextLine()方法再去缓冲区找数据的时候首先看到了“\r”,
然后就把这个“\r”扫描接收进来(停止),并在缓冲区内清除掉。其实,nextLine()方法是执行过的,并没有不执行。调用hasNextXxx()是可以直接输入数据的,只不过它只做判断,返回的是boolean类型
public Xxx nextXxx():获取该元素
//创建对象
Scanner sc = new Scanner(System.in);
// 获取数据
if (sc.hasNextInt()) { //如果输入的是int类型,true,执行第一条语句。
int x = sc.nextInt();
System.out.println("x:" + x);
} else {
System.out.println("你输入的数据有误");
}public Xxx nextXxx():获取该元素
int x = sc.nextInt(); //获取int类型的就要int类型接收,不然报错
InputMismatchException:输入的和你想要的不匹配String
String s1 = "hello";
String s2 = "world";
String s3 = s1 + s2; //这种方式比较常用
String s4 = s1.concat(s2);
其他
1 java中的length属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了length这个性。
2.String s = new String(“hello”)和String s = “hello”;的区别?
前者会创建2个对象,后者创建1个对象。
堆一个,方法区常量池一个,常量池有就不创建了。
字符串如果是常量相加,是先加,然后在常量池找,如果有就直接返回,否则,就创建。
栈 方法区常量池
String s1————"hello" 0x001
String s2————"world" 0x002
String s3————"helloworld" 0x003
s3 == s1 + s2(false)————"hello""world" 0x004 字符串如果是变量相加,先开空间,在拼接。
s3 == "hello" + "world"(true)———"helloworld" 0x003 字符串如果是常量相加,是先加,然后在常量池找,
如果有就直接返回,否则,就创建。
5. String类的获取功能 int indexOf(int ch):返回指定字符在此字符串中第一次出现处的索引。
为什么这里是int类型,而不是char类型? 原因是:为了方便。举例'a'和97其实都可以代表'a'int类型可以表示char类型,即:char ch='a'(或者char ch=97)然后 int x=ch;没问题。
而char类型不能表示已经定义的int类型,即:int x='a'(或者int x=97)然后char ch=x;报错。表示x需要强转为char。
StringBuffer
StringBuffer: 可安全的用于多个线程——同步——效率低 (线程安全的可变字符序列)
StringBuilder: 普遍用在被单个线程使用的时候(用于多个线程是不安全的)——不同步——效率高 (此类提供一个与 StringBuffer 兼容的 API,但不保证同步。该类被设计用作 StringBuffer 的一个简易替换)
安全:医院的网站,银行网站
效率:新闻网站,论坛之类的
StringBuffer和String的区别?
* 前者长度和内容可变,后者不可变。
* 如果使用前者做字符串的拼接,不会浪费太多的资源。
StringBuffer的构造方法
public StringBuffer()
构造一个其中不带字符的字符串缓冲区,其初始容量为 16 个字符。
public StringBuffer(int capacity)
- 构造一个不带字符,但具有指定初始容量的字符串缓冲区。
public StringBuffer(String str)
-
构造一个字符串缓冲区,并将其内容初始化为指定的字符串内容。该字符串的初始容量为
16加上字符串参数的长度。
其他:
public int capacity()
- 返回当前容量。容量指可用于最新插入的字符的存储量,超过这一容量就需要再次进行分配。
public int length()
- 返回长度(字符数)。
添加功能
public StringBuffer append(String str): 将任意类型数据添加到字符串缓冲区里面,并返回字符串缓冲区本身
public StringBuffer insert(int offset,String str): 在指定位置把任意类型的数据插入到字符串缓冲区里面,并返回字符串缓冲区本身 * offset 参数必须大于等于 0,且小于等于此序列的长度。
删除功能
public StringBuffer deleteCharAt(int index): 移除此序列指定位置的字符,并返回本身
public StringBuffer delete(int start,int end): 删除从指定位置开始指定位置结束的内容,并返回本身(start - 起始索引(包含)。end - 结束索引(不包含)。 ) //包左不包右 (Java的这类方法普遍这样)
替换功能
String 中的字符替换此序列的子字符串中的字符。该子字符串从指定的 start 处开始,一直到索引 end - 1 处的字符
反转功能
public StringBuffer reverse(): 将此字符序列用其反转形式取代。
截取功能
public String substring(int start): 返回一个新的 String,该子字符串始于指定索引处的字符,一直到此字符串末尾。
public String substring(int start,int end)-
返回一个新的
String,它包含此序列当前所包含的字符子序列。该子字符串从指定的start处开始,一直到索引end - 1处的字符。
String和StringBuffer的相互转换
方式2:通过append()方法
public StringBuffer append(String str): 可以把任意类型数据添加到字符串缓冲区里面,并返回字符串缓冲区本身
StringBuffer sb2 = new StringBuffer();
sb2.append(s);
StringBuffer -- String
方式1:通过String的构造方法
public String(StringBuffer buffer) : 分配一个新的字符串,它包含字符串缓冲区参数中当前包含的字符序列。
方式2:通过StringBuffer的toString()方法
public String toString():返回此序列中数据的字符串表示形式。
StringBuffer buffer = new StringBuffer("java"); String str2 = buffer.toString();
把数组拼接成一个字符串
/*
* 把数组拼接成一个字符串
*/
public class StringBufferTest2 {
public static void main(String[] args) {
// 定义一个数组
int[] arr = { 44, 33, 55, 11, 22 };
// 定义功能
// 方式1:用String做拼接的方式
String s1 = arrayToString(arr);
System.out.println("s1:" + s1);
// 方式2:用StringBuffer做拼接的方式
String s2 = arrayToString2(arr);
System.out.println("s2:" + s2);
}
// 用StringBuffer做拼接的方式
public static String arrayToString2(int[] arr) {
StringBuffer sb = new StringBuffer();
sb.append("[");
for (int x = 0; x < arr.length; x++) {
if (x == arr.length - 1) {
sb.append(arr[x]);
} else {
sb.append(arr[x]).append(", ");
}
}
sb.append("]");
return sb.toString();
}
// 用String做拼接的方式(产生新的字符串常量,费内存)
public static String arrayToString(int[] arr) {
String s = "";
s += "[";
for (int x = 0; x < arr.length; x++) {
if (x == arr.length - 1) {
s += arr[x];
} else {
s += arr[x];
s += ", ";
}
}
s += "]";
return s;
}
}字符串反转
import java.util.Scanner;
/*
* 把字符串反转
*/
public class StringBufferTest3 {
public static void main(String[] args) {
// 键盘录入数据
Scanner sc = new Scanner(System.in);
System.out.println("请输入数据:");
String s = sc.nextLine();
// 方式1:用String做拼接
String s1 = myReverse(s);
System.out.println("s1:" + s1);
// 方式2:用StringBuffer的reverse()功能
String s2 = myReverse2(s);
System.out.println("s2:" + s2);
}
// 用StringBuffer的reverse()功能
public static String myReverse2(String s) {
// StringBuffer sb = new StringBuffer();
// sb.append(s);
// StringBuffer sb = new StringBuffer(s);
// sb.reverse();
// return sb.toString();
// 简易版
return new StringBuffer(s).reverse().toString();
}
// 用String做拼接
public static String myReverse(String s) {
String result = "";
char[] chs = s.toCharArray();
for (int x = chs.length - 1; x >= 0; x--) {
// char ch = chs[x];
// result += ch;
result += chs[x];
}
return result;
}
}判断一个字符串是否是对称字符串
import java.util.Scanner;
/*
* 判断一个字符串是否是对称字符串
* 例如"abc"不是对称字符串,"aba"、"abba"、"aaa"、"mnanm"是对称字符串
*
* 分析:
* 判断一个字符串是否是对称的字符串,我只需要把
* 第一个和最后一个比较
* 第二个和倒数第二个比较
* ...
* 比较的次数是长度除以2。
*/
public class StringBufferTest4 {
public static void main(String[] args) {
// 创建键盘录入对象
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个字符串:");
String s = sc.nextLine();
// 一个一个的比较
boolean b = isSame(s);
System.out.println("b:" + b);
//用字符串缓冲区的反转功能
boolean b2 = isSame2(s);
System.out.println("b2:"+b2);
}
public static boolean isSame2(String s) {
return new StringBuffer(s).reverse().toString().equals(s);
}
// public static boolean isSame(String s) {
// // 把字符串转成字符数组
// char[] chs = s.toCharArray();
//
// for (int start = 0, end = chs.length - 1; start <= end; start++, end--) {
// if (chs[start] != chs[end]) {
// return false;
// }
// }
//
// return true;
// }
public static boolean isSame(String s) {
boolean flag = true;
// 把字符串转成字符数组
char[] chs = s.toCharArray();
for (int start = 0, end = chs.length - 1; start <= end; start++, end--) {
if (chs[start] != chs[end]) {
flag = false;
break;
}
}
return flag;
}
}
StringBuffer和数组的区别
二者都可以看做是一个容器,放置其他的数据。
StringBuffer可以放置任意数据但最终结果是一个字符串数据。
而数组可以放置多种数据,但必须是同一种数据类型的。
String,StringBuffer作为形参传递
形式参数:基本类型:形式参数的改变不影响实际参数
引用类型:形式参数的改变直接影响实际参数
注意:
String作为参数传递,效果和基本类型作为参数传递是一样的。
Arrays
除非特别注明,否则如果指定数组引用为 null,则此类中的方法都会抛出 NullPointerException。
* 2:public static void sort(int[] a) 对数组进行排序(这个方法底层是快速排序)
* 3:public static int binarySearch(int[] a,int key) 二分查找
只要是对象,我们就要判断该对象是否为null。
包装类类型
* byte Byte
* short Short
* int Integer
* long Long
* float Float
* double Double
* char Character
* boolean Boolean
* BigInteger、BigDecimal没有相对应的基本类型,主要应用于高精度的运算,BigInteger 支持任意精度的整数,BigDecimal支持任意精度带小数点的运算。
Integer
Integer 类在对象中包装了一个基本类型 int 的值。该类提供了多个方法,能在 int 类型和 String 类型之间互相转换,还提供了处理 int 类型时非常有用的其他一些常量和方法。
进制转换
1.常用的基本进制转换:
toBinaryString
public static String toBinaryString(int i)
以二进制(基数 2)无符号整数形式返回一个整数参数的字符串表示形式。
toOctalString
public static String toOctalString(int i)
- 以八进制(基数 8)无符号整数形式返回一个整数参数的字符串表示形式。
toHexString
public static String toHexString(int i)
以十六进制(基数 16)无符号整数形式返回一个整数参数的字符串表示形式。
2.十进制到其他进制
public static String toString(int i,
int radix)
- 返回用第二个参数指定基数表示的第一个参数的字符串表示形式。
-
i- 要转换成字符串的整数。
radix - 用于字符串表示形式的基数。
3.其他进制到十进制
public static int parseInt(String s,
int radix)
使用第二个参数指定的基数,将字符串参数解析为有符号的整数。字符串中的字符必须都是指定基数的数字
示例: system.out.println(Integer.parseInt("123", 2)); //NumberFormatException
二进制:由0,1组成。"123"不是由二进制所表示的字符组成所以抛出异常。
4.进制的范围
2进制———36进制。为什么呢?
不同进制的数据表现:
二进制:由0,1组成。以0b开头。
八进制:由0,1,...7组成。以0开头。
十进制:由0,1,...9组成。默认整数是十进制。十六进制:由0,1,...9,a,b,c,d,e,f(大小写均可)组成。以0x开头。(16个
三十六进制:由0,...9,a...z组成。(36个字符)
字段
MIN_VALUE
public static final int MIN_VALUE
- 值为 -231 的常量,它表示
int类型能够表示的最小值。
MAX_VALUE
public static final int MAX_VALUE
值为 231-1 的常量,它表示 int 类型能够表示的最大值。
构造方法
public Integer(int value)
-
构造一个新分配的
Integer对象,它表示指定的int值。
public Integer(String s)
构造一个新分配的 Integer 对象,它表示 String 参数所指示的 int 值。(注意:这个字符串必须是由数字字符组成)
int和String的相互转换
package cn.itcast_03;
/*
* int类型和String类型的相互转换
*
* int -- String
* String.valueOf(number)
*
* String -- int
* Integer.parseInt(s)
*/
public class IntegerDemo {
public static void main(String[] args) {
// int -- String
int number = 100;
// 方式1
String s1 = "" + number;
System.out.println("s1:" + s1);
// 方式2
String s2 = String.valueOf(number);
System.out.println("s2:" + s2);
// 方式3
// int -- Integer -- String
Integer i = new Integer(number);
String s3 = i.toString();
System.out.println("s3:" + s3);
// 方式4
// public static String toString(int i)
String s4 = Integer.toString(number);
System.out.println("s4:" + s4);
System.out.println("-----------------");
// String -- int
String s = "100";
// 方式1
// String -- Integer -- int
Integer ii = new Integer(s);
// public int intValue()
int x = ii.intValue();
System.out.println("x:" + x);
//方式2
//public static int parseInt(String s)
int y = Integer.parseInt(s);
System.out.println("y:"+y);
}
}
JDK5的新特性
package cn.itcast_05;
/*
* JDK5的新特性
* 自动装箱:把基本类型转换为包装类类型
* 自动拆箱:把包装类类型转换为基本类型
*
* 注意一个小问题:
* 在使用时,Integer x = null;代码就会出现NullPointerException。
* 建议先判断是否为null,然后再使用。
*/
public class IntegerDemo {
public static void main(String[] args) {
// 定义了一个int类型的包装类类型变量i
// Integer i = new Integer(100);
Integer ii = 100;
ii += 200;
System.out.println("ii:" + ii);
// 通过反编译后的代码
// Integer ii = Integer.valueOf(100); //自动装箱
// ii = Integer.valueOf(ii.intValue() + 200); //自动拆箱,再自动装箱
// System.out.println((new StringBuilder("ii:")).append(ii).toString());
Integer iii = null;
// NullPointerException
if (iii != null) {
iii += 1000;
System.out.println(iii);
}
}
}
1.Integer方法 public static Integer valueOf(int i) 返回一个表示指定的 int 值的 Integer 实例。
2.Integer方法 public int intValue() 以 int 类型返回该 Integer 的值。
3.StringBuilder方法 public StringBuilder(String str) 构造一个字符串生成器,并初始化为指定的字符串内容。
StringBuilder方法 public StringBuilder append(Object obj) 追加 Object 参数的字符串表示形式。
StringBuilder方法 public String toString() 返回此序列中数据的字符串表示形式。Integer数据的直接赋值
package cn.itcast_06;
/*
* 看程序写结果
*
* 注意:Integer的数据直接赋值,如果在-128到127之间,会直接从缓冲池里获取数据
*/
public class IntegerDemo {
public static void main(String[] args) {
Integer i1 = new Integer(127);
Integer i2 = new Integer(127); //创建了新的空间,== 比的是地址值
System.out.println(i1 == i2); //false
System.out.println(i1.equals(i2)); //true
System.out.println("-----------");
Integer i3 = new Integer(128);
Integer i4 = new Integer(128);
System.out.println(i3 == i4); //false
System.out.println(i3.equals(i4)); //true
System.out.println("-----------");
Integer i5 = 128;
Integer i6 = 128;
System.out.println(i5 == i6); //false
System.out.println(i5.equals(i6)); //true
System.out.println("-----------");
Integer i7 = 127;
Integer i8 = 127;
System.out.println(i7 == i8); //true
System.out.println(i7.equals(i8)); //true
// Integer i7 = 127;直接赋值使用了java的自动装箱,等价于Integer i7 = Integer.valueOf(127);
// 通过查看valueOf源码,我们知道了,针对-128到127之间的数据做了一个数据缓冲池,
如果数据是该范围内的,每次并不创建新的空间。如果数据不是该范围内的,才重新new一个。
}
}
Character
Character 类在对象中包装一个基本类型 char 的值。该类提供了几种方法,以确定字符的类别(小写字母,数字,等等),并将字符从大写转换成小写,反之亦然。
构造方法
只有一个: public Character(char value)
创建对象: Character ch = new Character('a'); 也可以 Character ch = new Character((char) 97); (强转)
常用方法
* public static boolean isUpperCase(char ch):判断给定的字符是否是大写字符
* public static boolean isLowerCase(char ch):判断给定的字符是否是小写字符
* public static boolean isDigit(char ch):判断给定的字符是否是数字字符
* public static char toUpperCase(char ch):把给定的字符转换为大写字符
* public static char toLowerCase(char ch):把给定的字符转换为小写字
正则表达式(Regex)
正则表达式 就是符合一定规则的字符串。正则表达式的编译表示形式在 java.util.regex.Pattern 类中。
API Pattern
A:字符
x 字符 x。举例:'a'表示字符a 任意一个字符表示字符本身
\\ 反斜线字符。 \具有转译作用(java中两个反斜杠代表一个反斜杠)
\n 新行(换行)符 ('\u000A')
\r 回车符 ('\u000D')
B:字符类
[abc] a、b 或 c(简单类)
[^abc] 任何字符,除了 a、b 或 c(否定)
[a-zA-Z] a到 z 或 A到 Z,两头的字母包括在内(范围)
[0-9] 0到9的字符都包括
C:预定义字符类
. 任何字符。我的就是.字符本身,怎么表示呢? \.
\d 数字:[0-9]
\w 单词字符:[a-zA-Z_0-9]
在正则表达式里面组成单词的东西必须有这些东西组成
D:边界匹配器
^ 行的开头
$ 行的结尾
\b 单词边界
就是不是单词字符的地方。
举例:hello world?haha;xixi
E:Greedy 数量词
X? X,一次或一次也没有
X* X,零次或多次
X+ X,一次或多次
X{n} X,恰好 n 次
X{n,} X,至少 n 次
X{n,m} X,至少 n 次,但是不超过 m 次
没有给定默认一次- 判断功能:
String类下的public boolean matches(String regex) 告知此字符串是否匹配给定的正则表达式。
定义规则:String regex ="[1-9][0-9]{4,14}";
返回结果:boolean flag = qq.matches(regex);
或者直接:return qq.matches("[1-9]\\d{4,14}");
- 分割功能:
String类的public String[] split(String regex) 根据给定正则表达式的匹配拆分此字符串。
// 定义一个字符串
String s1 = "aa,bb,cc";
// 直接分割
String[] str1Array = s1.split(",");
for (int x = 0; x < str1Array.length; x++) {
System.out.println(str1Array[x]);
}
例如,字符串 "boo:and:foo" 使用这些表达式可生成以下结果:
所得数组中不包括结尾空字符串。详见
Regex 结果 : { "boo", "and", "foo" } o { "b", "", ":and:f" } 可以这么理解“b”“”“:and:f”“”“” 限制参数就是 “”
String类下的 public String[] split(String regex,int limit)
- 替换功能:
String类的public String replaceAll(String regex,String replacement)
使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。
String s = "123java456789";
String s2 = s.replaceAll("\\d", "*");
System.out.println(s2); //***java******
- 获取功能:
Pattern和Matcher类的使用
典型的调用顺序是:
//把正则表达式编译成模式对象
Pattern p = Pattern.compile("a*b"); //规则 a* 零次或多次 b默认一次
//通过模式对象得到匹配器对象,这个时候需要的是被匹配的字符串
Matcher m = p.matcher("aaaaab");
调用匹配器对象的功能(判断)
boolean b = m.matches(); //true
Pattern类的public static Pattern compile(String regex) 将给定的正则表达式编译到模式中。
Pattern类的public Matcher matcher(CharSequence input) 创建匹配给定输入与此模式的匹配器。
Matcher类的public boolean matches() 尝试将整个区域与模式匹配。
//这个是判断功能,但是如果做判断,这样做就有点麻烦了,我们直接用字符串的方法做
String s = "aaaaab";
String regex = "a*b";
boolean bb = s.matches(regex);
String类的public boolean matches(String regex) 告知此字符串是否匹配给定的正则表达式。
- 从模式创建匹配器后,可以使用它执行三种不同的匹配操作:
matches方法尝试将整个输入序列与该模式匹配。lookingAt尝试将输入序列从头开始与该模式匹配。find方法扫描输入序列以查找与该模式匹配的下一个子序列。
如果匹配成功,则可以通过 start、end 和 group 方法获取更多信息。
- 在仅使用一次正则表达式时,可以方便地通过Pattern类定义
matches方法。对于重复的匹配而言它效率不高。
boolean b = Pattern.matches("a*b", "aaaaab");
Pattern类的public static boolean matches(String regex,CharSequence input):
- 编译给定正则表达式并尝试将给定输入与其匹配。
调用此便捷方法的形式
Pattern.matches(regex, input);
与表达式
Pattern.compile(regex).matcher(input).matches()
如果要多次使用一种模式,编译一次后重用此模式比每次都调用此方法效率更高。
Math(数学)
java.lang.Math
Math 类包含用于执行基本数学运算的方法,如初等指数、对数、平方根和三角函数。
成员变量:
1. public static final double PI
比任何其他值都更接近 pi(即圆的周长与直径之比)的 double 值。
(圆周率(Pi)是圆的周长与直径的比值,一般用希腊字母π表示。)
2. public static final double E
比任何其他值都更接近 e(即自然对数的底数)的 double 值。
(自然对数:以常数e为底数的对数。 e是一个无限不循环小数,其值约等于2.718281828459…,它是一个超越数。)
成员方法:
1. public static int abs(int a):绝对值
(绝对值是指一个数在数轴上所对应点到原点的距离,用“| |”来表示。正数的绝对值是它本身;
负数的绝对值是它的相反数;0的绝对值还是0。
|5|指在数轴上5与原点的距离,这个距离是5,所以5的绝对值是5。|-5|的绝对值也是5。)
2. public static double ceil(double a):向上取整
(System.out.println("ceil:" + Math.ceil(12.34)); //13.0
System.out.println("ceil:" + Math.ceil(12.56)); //13.0)
3. public static double floor(double a):向下取整
(System.out.println("floor:" + Math.floor(12.34)); //12.0
System.out.println("floor:" + Math.floor(12.56)); //12.0)
4. public static int max(int a,int b):最大值
(System.out.println("max:" + Math.max(12, 23)); //23
方法的嵌套调用:
System.out.println("max:"+ Math.max(Math.max(12, 78), Math.max(34, 56))); //78)
5. public static int min(int a,int b):最小值
6. public static double pow(double a,double b):a的b次幂
(System.out.println("pow:" + Math.pow(2, 3)); //8.0)
7. public static double random():随机数。
(返回带正号的 double 值,该值大于等于 0.0 且小于 1.0。)
8. public static int round(float a) 四舍五入
(返回最接近参数的 int。结果将舍入为整数:加上 1/2,对结果调用 floor 并将所得结果强制转换为 int 类型。
换句话说,结果等于以下表达式的值: (int)Math.floor(a + 0.5f)
System.out.println("round:" + Math.round(12.34f)); //12
System.out.println("round:" + Math.round(12.56f)); //13)
9. public static double sqrt(double a):正平方根
(System.out.println("sqrt:"+Math.sqrt(9)); //3
√ ̄9=3;9的平方根是3,3的平方等于9。)
double 值,该值大于等于 0.0 且小于 1.0 。
Random(随机)
此类的实例用于生成伪随机数流。很多应用程序会发现 Math.random() 方法更易于使用。
构造方法:
public Random():没有给种子,用的是默认种子,是当前时间的毫秒值。
public Random(long seed):给出指定的种子,给定种子后,每次得到的随机数是相同的。
成员方法:
public int nextInt():返回的是int范围内的随机数。
public int nextInt(int n):返回的是0~n范围内的随机数。
eg:
输出1~100的随机数:Random r = new Random(1111); int num = r.nextInt(100) + 1; //且每次得到随机数相同
System
- public static void gc():运行垃圾回收器。
System.gc()可用于垃圾回收。在没有明确指定资源清理的情况下,Java提供了默认机制来清理该对象的资源,就是调用Object类的finalize()方法。
finalize()方法的作用是释放一个对象占用的内存空间时,会被JVM调用。
从程序的运行结果可以发现,执行System.gc()前,系统会自动调用finalize()方法清除对象占有的资源,通过super.finalize()方式可以实现从下到上的finalize()方法的调用,即先释放自己的资源,再去释放父类的资源。
但是,不要在程序中频繁的调用垃圾回收,因为每一次执行垃圾回收,jvm都会强制启动垃圾回收器运行,这会耗费更多的系统资源,会与正常的Java程序运行争抢资源,只有在执行大量的对象的释放,才调用垃圾回收最好
Object类的protected void finalize()throws Throwable:
当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。
子类可以重写 finalize 方法,以配置系统资源或执行其他清除。
- public static void exit(int status):终止当前正在运行的 Java 虚拟机。参数用作状态码;根据惯例,非 0 的状态码表示异常终止。 // System.exit(0);
- public static long currentTimeMillis():返回以毫秒为单位的当前时间。当前时间与 1970 年 1 月 1 日午夜之间的时间差(以毫秒为单位测量)。// long start = System.currentTimeMillis();
- public static void arraycopy(Object src,int srcPos,Object dest,int destPos,int length):从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。
srcPos - 源数组中的起始位置。
dest - 目标数组。
destPos - 目标数据中的起始位置。
length - 要复制的数组元素的数量。
// 定义数组
int[] arr = { 11, 22, 33, 44, 55 };
int[] arr2 = { 6, 7, 8, 9, 10 };
// 请大家看这个代码的意思
System.arraycopy(arr, 1, arr2, 2, 2);
System.out.println(Arrays.toString(arr)); // [11, 22, 33, 44, 55]
System.out.println(Arrays.toString(arr2)); // [6, 7, 22, 33, 10]
Arrays类的public static String toString(int[] a):返回指定数组内容的字符串表示形式。
BigInteger
不可变的任意精度的整数。可以让超过Integer范围内的数据进行运算。
- Integer.MAX_VALUE; //int能表示的最大值2147483647
Integer i = new Integer("2147483648"); System.out.println(i); // NumberFormatException
BigInteger bi = new BigInteger("2147483648"); System.out.println(bi); //2147483648
- 构造方法:public BigInteger(String val):将 BigInteger 的十进制字符串表示形式转换为 BigInteger。
- public BigInteger add(BigInteger val): 加
* public BigInteger subtract(BigInteger val): 减
* public BigInteger multiply(BigInteger val): 乘
* public BigInteger divide(BigInteger val): 除
* public BigInteger[] divideAndRemainder(BigInteger val): 返回两个 BigInteger 的数组:商 (this / val) 是初始元素,余数 (this % val) 是最终元素。 (商和余数的数组) BigDecimal
不可变的、任意精度的有符号十进制数。可以解决数据精度丢失问题。
- System.out.println(1.0 - 0.32); //0.6799999999999999
结果和我们想的有点不一样,这是因为浮点数类型的数据存储和整数不一样导致的。它们大部分的时候,都是带有有效数字位。
所以,为了能精确的表示、计算浮点数,Java提供了BigDecimal。
- 构造方法: public BigDecimal(String val):将 BigDecimal 的字符串表示形式转换为 BigDecimal。(推荐)
- public BigDecimal add(BigDecimal augend):加
- public BigDecimal subtract(BigDecimal subtrahend):减
- public BigDecimal multiply(BigDecimal multiplicand):乘
- public BigDecimal divide(BigDecimal divisor):除
public BigDecimal divide(BigDecimal divisor,int scale,int roundingMode):返回一个 BigDecimal,其值为 (this / divisor),其标度为指定标度。
divisor - 此 BigDecimal 要除以的值。roundingMode - 要应用的舍入模式。
scale - 要返回的 BigDecimal 商的标度。(也就是小数点后保留几位)
Date(日期)
类 Date 表示特定的瞬间,精确到毫秒。
在 JDK 1.1 之前,类 Date 有两个其他的函数。它允许把日期解释为年、月、日、小时、分钟和秒值。它也允许格式化和解析日期字符串。不过,这些函数的 API 不易于实现国际化。从 JDK 1.1 开始,应该使用 Calendar 类实现日期和时间字段之间转换,使用 DateFormat 类来格式化和解析日期字符串。Date 中的相应方法已废弃。
- 构造方法:
Date():根据当前的默认毫秒值创建日期对象
Date(long date):根据给定的毫秒值创建日期对象
// 创建对象
Date d = new Date();
System.out.println("d:" + d); // d:Fri Jun 22 20:58:38 CST 2018
// 创建对象
long time = 1000 * 60 * 60; // 1小时
//本来应该为1月1日01:00:00,但因为时区问题(东8区)显示为09:00:00
Date d2 = new Date(time);
System.out.println("d2:" + d2); // d2:Thu Jan 01 09:00:00 CST 1970
- public long getTime():获取自 1970 年 1 月 1 日 00:00:00 GMT 以来此 Date 对象表示的毫秒数。
- public void setTime(long time):设置时间。(可以把当前的毫秒值设置进去,得到当前的日期)
Date d = new Date();
long time = d.getTime();
// System类的currentTimeMillis()也可以获取时间:返回以毫秒为单位的当前时间。
d.setTime(time);
System.out.println(d);
DateForamt(日期格式化)
DateFormat 是日期/时间格式化子类的抽象类,它以与语言无关的方式格式化并解析日期或时间。
但由于是抽象类,所以我们使用具体子类SimpleDateFormat。
Date -- String (日期 -> 文本 格式化)
public final String format(Date date):将一个 Date 格式化为日期/时间字符串。
String -- Date (文本 -> 日期 解析)
public Date parse(String source):从给定字符串的开始解析文本,以生成一个日期。
SimpleDateFormat是一个以与语言环境有关的方式来格式化和解析日期的具体类。它允许进行格式化(日期 -> 文本)、解析(文本 -> 日期)和规范化。
构造方法:
public SimpleDateFormat():用默认的模式和默认语言环境的日期格式符号构造 SimpleDateFormat。
public SimpleDateFormat(String pattern):用给定的模式和默认语言环境的日期格式符号构造 SimpleDateFormat。
/** 通过查看API,我们就找到了对应的模式
* 年 y
* 月 M
* 日 d
* 时 H
* 分 m
* 秒 s
*
* 2014年12月12日 12:12:12
*/import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateFormatDemo {
public static void main(String[] args) throws ParseException {
// Date -- String
// 创建日期对象
Date d = new Date();
// 创建格式化对象
// SimpleDateFormat sdf = new SimpleDateFormat();
// 给定模式
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
// public final String format(Date date)
String s = sdf.format(d);
System.out.println(s); //2014年12月12日 12:12:12
//String -- Date
String str = "2008-08-08 12:12:12";
//在把一个字符串解析为日期的时候,请注意格式必须和给定的字符串格式匹配
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date dd = sdf2.parse(str);
System.out.println(dd); // Fri Aug 08 12:12:12 CST 2008
}
}Calendar(日历)
它为特定瞬间与一组诸如 YEAR、MONTH、DAY_OF_MONTH、HOUR 等 日历字段之间的转换提供了一些方法,并为操作日历字段(例如获得下星期的日期)提供了一些方法。日历类中的每个日历字段都是静态的成员变量,并且是int类型。
- 与其他语言环境敏感类一样,
Calendar提供了一个类方法getInstance,以获得此类型的一个通用的对象。Calendar的getInstance方法返回一个Calendar对象,其日历字段已由当前日期和时间初始化:
Calendar rightNow = Calendar.getInstance();
- public int get(int field):使用默认时区和语言环境获得一个日历。返回的
Calendar基于当前时间,使用了默认时区和默认语言环境。
public class CalendarDemo {
public static void main(String[] args) {
// 其日历字段已由当前日期和时间初始化:
Calendar rightNow = Calendar.getInstance(); // 子类对象。多态
// 获取年
int year = rightNow.get(Calendar.YEAR);
// 获取月
int month = rightNow.get(Calendar.MONTH);
// 获取日
int date = rightNow.get(Calendar.DATE);
System.out.println(year + "年" + (month + 1) + "月" + date + "日");
} // 因为month(月)从0开始所以我们加1。
}
- public void add(int field,int amount):
add(Calendar.Date, -5)。
public static final int DATE; 天数
- public final void set(int year,int month,int date):设置当前日历的年月日
Collection(集合)
Collection 层次结构 中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 不提供此接口的任何直接 实现:它提供更具体的子接口(如 Set 和 List)实现。
- Collection集合总结
|--List 有序,可重复
|--ArrayList
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高
|--Vector
底层数据结构是数组,查询快,增删慢。
线程安全,效率低
|--LinkedList
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高
|--Set 无序,唯一
|--HashSet
底层数据结构是哈希表。
如何保证元素唯一性的呢?
依赖两个方法:hashCode()和equals()
开发中自动生成这两个方法即可
|--LinkedHashSet
底层数据结构由哈希表和链表组成
由链表保证元素有序
由哈希表保证元素唯一
|--TreeSet
底层数据结构是红黑树。
如何保证元素排序的呢?
自然排序
比较器排序
如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
针对Collection集合我们到底使用谁呢?
唯一吗?
是:Set
排序吗?
是:TreeSet
否:HashSet
如果你知道是Set,但是不知道是哪个Set,就用HashSet。
否:List
要安全吗?
是:Vector
否:ArrayList或者LinkedList
查询多:ArrayList
增删多:LinkedList
如果你知道是List,但是不知道是哪个List,就用ArrayList。
如果你知道是Collection集合,但是不知道使用谁,就用ArrayList。
如果你知道用集合,就用ArrayList。
在集合中常见的数据结构
ArrayXxx:底层数据结构是数组,查询快,增删慢
LinkedXxx:底层数据结构是链表,查询慢,增删快
HashXxx:底层数据结构是哈希表。依赖两个方法:hashCode()和equals()
TreeXxx:底层数据结构是二叉树。两种方式排序:自然排序和比较器排序
- 集合的由来:
* 我们学习的是面向对象语言,而面向对象语言对事物的描述是通过对象体现的,为了方便对多个对象进行操作,我们就必须把这多个对象进行存储。
* 而要想存储多个对象,就不能是一个基本的变量,而应该是一个容器类型的变量,在我们目前所学过的知识里面,有哪些是容器类型的呢?
* 数组和StringBuffer。但是呢?StringBuffer的结果是一个字符串,不一定满足我们的要求,所以我们只能选择数组,这就是对象数组。
* 而对象数组又不能适应变化的需求,因为数组的长度是固定的,这个时候,为了适应变化的需求,Java就提供了集合类供我们使用。
*
* 数组和集合的区别?
* A:长度区别
* 数组的长度固定
* 集合长度可变
* B:内容不同
* 数组存储的是同一种类型的元素
* 而集合可以存储不同类型的元素
* C:元素的数据类型问题
* 数组可以存储基本数据类型,也可以存储引用数据类型
* 集合只能存储引用类型
*
* 刚说过集合是存储多个元的,但是呢,存储多个元素我们也是有不同需求的:比如说,我要这多个元素中不能有相同的元素,
* 再比如说,我要这多个元素按照某种规则排序一下。针对不同的需求,Java就提供了不同的集合类,这样呢,Java就提供了很多个集合类。
* 这多个集合类的数据结构不同,结构不同不重要的,重要的是你要能够存储东西,并且还要能够使用这些东西,比如说判断,获取等。
* 既然这样,那么,这多个集合类是有共性的内容的,我们把这些集合类的共性内容不断的向上提取,最终就能形成集合的继承体系结构。
*
* 数据结构:数据的存储方式。
集合的遍历:
A:把集合转数组 B:迭代器(集合专用方式) C:增强for(其实是用来替代迭代器的,底层还是迭代器,不过更简洁)
List集合的特有遍历:
A:由size()和get()结合。普通for循环
B:ListIterator listIterator():列表迭代器。List集合特有的迭代器
Map集合的遍历:
A:键找值 B:键值对对象找键和值
TreeMap TreeSet的排序:A:自然排序 B:比较器排序
- Collection的功能概述:
* boolean add(E e):添加一个元素 //如果此 collection 由于调用而发生更改,则返回 true
* boolean addAll(Collection c):添加一个集合的元素
* 2:删除功能
* void clear():移除所有元素
* boolean remove(Object o):移除一个元素 //如果此调用将移除一个元素,则返回 true
* boolean removeAll(Collection c):移除一个集合的元素 //移除此 collection 中那些也包含在指定collection 中的所有元素
* 3:判断功能
* boolean contains(Object o):contains():判断集合中是否包含指定的元素
// contains()方法底层依赖的是equals()方法。
* boolean isEmpty():判断集合是否为空 //如果此列表中没有元素,则返回 true
* 4:获取功能
* Iterator
* 5:长度功能
* int size():元素的个数
* 面试题:数组length,字符串length(),集合size()。
* 6:交集功能
* boolean retainAll(Collection c):仅保留此 collection 中那些也包含在指定 collection 的元素。如果此 collection 由于调用而发生更改,则返回 true // A对B做交集,最终的结果保存在A中,B不变。
* 7:把集合转换为数组
* Object[] toArray():返回包含此 collection 中所有元素的数组。/*
* 集合的遍历。其实就是依次获取集合中的每一个元素。
*
* Object[] toArray():把集合转成数组,可以实现集合的遍历
*/
public class CollectionDemo3 {
public static void main(String[] args) {
// 创建集合对象
Collection c = new ArrayList();
// 添加元素
c.add("hello"); //Object obj = "hello"; 向上转型
c.add("world");
c.add("java");
// 遍历
// Object[] toArray():把集合转成数组,可以实现集合的遍历
Object[] objs = c.toArray();
for (int x = 0; x < objs.length; x++) {
System.out.println(objs[x]);
// 我知道元素是字符串,我在获取到元素的的同时,还想知道元素的长度。
// System.out.println(objs[x] + "---" + objs[x].length());
// 上面的实现不了,原因是Object中没有length()方法
// 我们要想使用子类的特有功能
// 向下转型
String s = (String) objs[x];
System.out.println(s + "---" + s.length());
}
}
}Iterator
Collection集合的遍历
A:把集合转数组
B:迭代器(集合专用方式)
Iterator iterator():返回在此 collection 的元素上进行迭代的迭代器。
boolean hasNext():如果仍有元素可以迭代,则返回 true。
Object next():返回迭代的下一个元素。
NoSuchElementException:没有元素可以迭代,因为你已经找到了最后。 所以,我们应该在每次获取前,判断一下
迭代器
A:是集合的获取元素的方式。
B:是依赖于集合而存在的。
C:迭代器的原理和源码。
a:为什么定义为了一个接口而不是实现类?
因为Java提供集合类的数据机构不尽相同,存储和遍历的方式也应该不同,所以没有定义为实现类。
而无论你是哪种集合,判断和获取功能都应该是一个集合遍历应该具备的,所以我们把这两个功能单独提取出来,
这种方式就是接口
b:集合遍历的实现类。(看源码)
//Collection是根接口,有一个List子接口,List子接口下有一个ArrayList实现类,
我们用这个具体的实现类new一个对象Collection c = new ArrayList(),这是多态,
Collection继承了一个接口Iterable,它有一个iterator方法Iterator iterator(),
调用它的iterator方法返回一个迭代器。
c.iterator();编译看左边Collection有iterator(),运行看右边使用ArrayList的iterator(),
返回一个new Itr();因为接收的是Iterator一个接口,所以返回的Itr只能是Iterator的实现类。
it.hasNext();编译看左边Iterator有hasNext(),运行看右边使用Itr的hasNext()。
所以说集合遍历的真正的具体的实现类在真正的具体的子类中,以内部类的方式体现。
Collection集合的案例(遍历方式 迭代器)
集合的操作步骤:
A:创建集合对象
B:创建元素对象
C:把元素添加到集合
D:遍历集合
a:通过集合对象获取迭代器对象(通过调用Iterator iterator()获得迭代器对象)
b:通过迭代器对象的hasNex()方法是否还有元素可以迭代
c:通过迭代器对象的next()方法获取元素并移动到下一个位置
public class CollectionDemo {
public static void main(String[] args) {
//创建集合对象
Collection c = new ArrayList();
//创建并添加元素
c.add("hello");
c.add("world");
c.add("java");
//遍历集合
Iterator it = c.iterator();
while(it.hasNext()) {
String s =(String) it.next();
System.out.println(s);
}
}
}
//for循环改写。for循环效率高但是不如while循环清晰
for(Iterator it = c.iterator();it.hasNext();){
String s = (String) it.next();
System.out.println(s);
}
List
List集合的特点:
有序的 collection(也称为序列)(存储和取出的元素顺序一致),允许重复的元素。
List集合的特有功能:
* A:添加功能
* void add(int index,Object element):在指定位置添加元素
//如果索引超出范围 (index < 0 || index > size()). IndexOutOfBoundsException 越界
* B:获取功能
* Object get(int index):获取指定位置的元素
* C:列表迭代器
* ListIterator listIterator():List集合特有的迭代器
* D:删除功能
* Object remove(int index):根据索引删除元素,返回被删除的元素
* E:修改功能
* Object set(int index,Object element):根据索引修改元素,返回被修饰的元素
List集合的特有遍历功能
A:由size()和get()结合。普通for循环
B:代码演示
// 创建集合对象
List list = new ArrayList();
// 创建学生对象
Student s1 = new Student("林黛玉", 18);
Student s2 = new Student("刘姥姥", 88);
Student s3 = new Student("王熙凤", 38);
// 把学生添加到集合中
list.add(s1);
list.add(s2);
list.add(s3);
// 遍历
// 迭代器遍历
Iterator it = list.iterator();
while (it.hasNext()) {
Student s = (Student) it.next();
System.out.println(s.getName() + "---" + s.getAge());
}
System.out.println("--------");
// 普通for循环
for (int x = 0; x < list.size(); x++) {
Student s = (Student) list.get(x);
System.out.println(s.getName() + "---" + s.getAge());
}
列表迭代器:
* ListIterator listIterator():List集合特有的迭代器
* 该迭代器继承了Iterator迭代器,所以,就可以直接使用hasNext()和next()方法。
*
* 特有功能:
* Object previous():获取上一个元素
* boolean hasPrevious():判断是否有元素
*
* 注意:ListIterator可以实现逆向遍历,但是必须先正向遍历,才能逆向遍历,
否则没有可输出的元素,所以一般无意义,不使用。
// 创建List集合对象
List list = new ArrayList();
// 添加元素
list.add("hello");
list.add("world");
list.add("java");
// ListIterator listIterator()
ListIterator lit = list.listIterator(); //返回的是一个接口,实际是这个接口的子类对象
// 迭代器(先正向遍历)
Iterator it = lit.iterator();
while (it.hasNext()) {
String s = (String) it.next();
System.out.println(s);
}
// 列表迭代器(才能逆向遍历)
while (lit.hasPrevious()) {
String s = (String) lit.previous();
System.out.println(s);
}
/*
* 问题?
* 我有一个集合,如下,请问,我想判断里面有没有"world"这个元素,如果有,我就添加一个"javaee"元素,请写代码实现。
*
* ConcurrentModificationException:当方法检测到对象的并发修改,但不允许这种修改时,抛出此异常。
* 产生的原因:
* 迭代器是依赖于集合而存在的,在判断成功后,集合的中新添加了元素,而迭代器却不知道,所以就报错了,这个错叫并发修改异常。
* 其实这个问题描述的是:迭代器遍历元素的时候,通过集合是不能修改元素的。
* 如何解决呢?
* A:迭代器迭代元素,迭代器修改元素
* 元素添加在刚才迭代的位置
* B:集合遍历元素,集合修改元素(普通for)
* 元素添加在集合的末尾
*/
public class ListIteratorDemo2 {
public static void main(String[] args) {
// 创建List集合对象
List list = new ArrayList();
// 添加元素
list.add("hello");
list.add("world");
list.add("java");
// 迭代器遍历 (并发修改异常)
// Iterator it = list.iterator();
// while (it.hasNext()) {
// String s = (String) it.next();
// if ("world".equals(s)) {
// list.add("javaee");
// }
// }
// 解决方式1:迭代器迭代元素,迭代器修改元素
// 而Iterator迭代器却没有添加功能,所以我们使用Iterator其子接口ListIterator
// ListIterator lit = list.listIterator();
// while (lit.hasNext()) {
// String s = (String) lit.next();
// if ("world".equals(s)) {
// lit.add("javaee");
// }
// }
// 解决方式2:集合遍历元素,集合修改元素(普通for)
for (int x = 0; x < list.size(); x++) {
String s = (String) list.get(x);
if ("world".equals(s)) {
list.add("javaee");
}
}
}
}
List的子类特点
ArrayList:
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。
Vector:
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
LinkedList:
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
List有三个儿子,我们到底使用谁呢?
看需求(情况)。
要安全吗?
要:Vector(即使要安全,也不用这个了,后面有替代的)
不要:ArrayList或者LinkedList
查询多:ArrayList
增删多:LinkedList
如果你什么都不懂,就用ArrayList。
ArrayList
Vector
* public void addElement(Object obj) -- add()
* 2:获取功能
* public Object elementAt(int index) -- get()
* public Enumeration elements() -- Iterator iterator()
* boolean hasMoreElements() hasNext()
* Object nextElement() next()
*
* JDK升级的原因:
* A:安全
* B:效率
* C:简化书写
LinkedList
* A:添加功能
* public void addFirst(E e):将指定元素插入此列表的开头。
* public void addLast(E e):将指定元素添加到此列表的结尾。
* B:获取功能
* public Object getFirst():返回此列表的第一个元素。
* public Obejct getLast():返回此列表的最后一个元素。
* C:删除功能
* public Object removeFirst():移除并返回此列表的第一个元素。
* public Object removeLast():移除并返回此列表的最后一个元素。泛型(Generic)
泛型:是一种把类型明确的工作推迟到创建对象或者调用方法的时候才去明确的特殊的类型。参数化类型,把类型当作参数一样的传递。* 推迟?(因为在定义类或方法的时候就可以明确类型)
* 格式:* <数据类型>
* 此处的数据类型只能是引用类型。
* 好处:* A:把运行时期的问题提前到了编译期间
* B:避免了强制类型转换
* C:优化了程序设计,解决了黄色警告线
* 泛型在哪些地方使用呢?
* 看API,如果类,接口,抽象类后面跟的有
JDK7的新特性:泛型推断。(前面是Student后面默认是Student)
// ArrayList
// 但是我不建议这样使用。
ArrayList
* 早期的时候,我们使用Object来代表任意的类型。
* 向上转型是没有任何问题的,但是在向下转型的时候其实隐含了类型转换的问题。
* 也就是说这样的程序其实并不是安全的。所以Java在JDK5后引入了泛型,提高程序的安全性。
Object obj = new Integer(10);
String s = (String) obj; // 编译不报错是因为JDK认为它有可能是,但运行肯定报错。
泛型接口:把泛型定义在接口上
public interface Inter
public abstract void show(T t);
}
泛型方法:把泛型定义在方法上
public class ObjectTool {
public
System.out.println(t);
}
}
泛型高级(通配符):
* ? —— 任意类型,如果没有明确,那么就是Object以及任意的Java类了
* ? extends E —— 向下限定,E及其子类
* ? super E —— 向上限定,E极其父类
* 泛型明确的写的时候,前后必须一致。JDK5的新特性
JDK5的新特性:自动拆装箱,泛型,增强for,静态导入,可变参数,枚举
* 增强for:是for循环的一种。
* 增强for其实是用来替代迭代器的。(底层还是迭代器,不过更简洁)
格式:
* for(元素数据类型 变量 : 数组或者Collection集合) {
* 使用变量即可,该变量就是元素
* }
好处:简化了数组和集合的遍历。
弊端: 增强for的目标不能为null。
* 如何解决呢?对增强for的目标先进行不为null的判断,然后在使用。
// 定义一个集合
ArrayList
array.add("hello");
array.add("world");
array.add("java");
// 增强for
for (String s : array) {
System.out.println(s);
}
List
// 不为null的判断
if (list != null) {
for (String s : list) {
System.out.println(s);
}
}
集合存储集合并遍历:
// 存储了Student对象集合的大集合
ArrayList
for (ArrayList
for (Student s : array) {
System.out.println(s.getName() + "---" + s.getAge());
}
}
静态导入:
* 格式:import static 包名….类名.方法名;
* 可以直接导入到方法的级别
*
静态导入的注意事项:* A:要导入的方法必须是静态的
* B:如果有多个同名的静态方法,容易不知道使用谁?这个时候要使用,必须加前缀,
* (java.lang.Math.max这样子)由此可见,意义不大,所以一般不用,但是要能看懂。
1.直接使用
System.out.println(java.lang.Math.max(20, 30));
2.import导入后使用
import static java.lang.Math.max;
System.out.println(Math.max(20, 30));可变参数:定义方法的时候不知道该定义多少个参数
格式:
* 修饰符 返回值类型 方法名(数据类型… 变量名){
*
* }
*
* 注意:
* 这里的变量其实是一个数组 (int... a = int a[])
* 如果一个方法有可变参数,并且有多个参数,那么,可变参数肯定是最后一个
* public static int sum(int b,int... a) {} b代表第一个参数,a代表后面所有的参数
* public static int sum(int... a,int b) {} 这样a代表所有参数,b没有对应的参数了,就会报错。Arrays类:
* public static
*
* 注意事项:
* 虽然可以把数组转成集合,但是集合的长度不能改变。
* 不能添加元素,但是可以做删除修改,因为没有改变长度。
Set
一个不包含重复元素的 collection。无序(存储顺序和取出顺序不一致),唯一。
注意:虽然Set集合的元素无序,但是,作为集合来说,它肯定有它自己的存储顺序,
而你的顺序恰好和它的存储顺序一致,这代表不了有序,你可以多存储一些数据,就能看到效果。
哈希表:是一个元素为链表的数组。
HashSet:存储字符串并遍历:
* 问题:为什么存储字符串的时候,字符串内容相同的只存储了一个呢?
* 通过查看add方法的源码,我们知道这个方法底层依赖 两个方法:hashCode()和equals()。
* 为了提高效率我们应让对象的哈希值尽可能不同
* public int hashCode():返回此 set 的哈希码值。
* public boolean equals(Object o):比较指定对象与此 set 的相等性。
* 首先比较哈希值
* 如果相同,继续走,比较地址值或者走equals()
* 如果不同,就直接添加到集合中
* 按照方法的步骤来说:
* 先看hashCode()值是否相同
* 相同:继续走equals()方法
* 返回true: 说明元素重复,就不添加
* 返回false:说明元素不重复,就添加到集合
* 不同:就直接把元素添加到集合
* 也就是if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
* 如果类没有重写这两个方法,默认使用Object()的。一般来说哈希值不同。
* 而String类重写了hashCode()和equals()方法,所以它就可以把内容相同的字符串去掉。需求:存储自定义对象,并保证元素的唯一性
* 要求:如果两个对象的成员变量值都相同,则为同一个元素。
*
* 我们知道HashSet底层依赖的是hashCode()和equals()方法。
* 而这两个方法我们在学生类中没有重写,所以,默认使用Object类的。
* 这个时候,他们的哈希值是不会一样的,根本就不会继续判断,直接就执行了添加操作。
* 你就应该重写这两个方法。如何重写呢?不同担心,自动生成即可。
LinkedHashSet
* 哈希表保证元素的唯一性。
* 链表保证元素有素。(存储和取出是一致)
TreeSet
或者根据创建 set 时提供的 Comparator 进行排序,具体取决于使用的构造方法。
底层数据结构是红黑树(是一个自平衡的二叉树)。
TreeSet集合的特点:排序和唯一。能够对元素按照某种规则进行排序。
如何保证元素排序的呢?自然排序
比较器排序
如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
通过TreeSet的add()方法执行判断和排序,观察后我们知道最终要看TreeMap的put()方法。
TreeSet集合保证元素排序和唯一性的原理:
* 唯一性:是根据比较的返回是否是0来决定。
* 排序:
* A:自然排序(元素具备比较性)
* public TreeSet() —— (无参构造)
* 真正的比较是依赖于元素的compareTo()方法,而这个方法是定义在 Comparable里面的。
* 所以要让元素所属的类实现自然排序接口 Comparable
*
* B:比较器排序(集合具备比较性)
* public TreeSet(Comparator comparator) —— (带参构造)
* 让集合的构造方法接收一个比较器接口Comparator的子类对象,重写compare()方法。
* // 定义一个类并且实现Comparator接口,那么它就是比较器接口的子类对象
* // TreeSet
而匿名内部类就可以实现这个东西
仅使用一次时推荐匿名内部类,因为其他排序,需求一旦该变就又要相应的改动代码
TreeSet自然排序:
Comparable
如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
String类的public int compareTo(String anotherString):按字典顺序比较两个字符串。
Integer类的public int compareTo(Integer anotherInteger):在数字上比较两个 Integer 对象。
...
Map
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
键唯一,值可以重复。LinkedHashMap 具有可预知的迭代顺序。TreeMap 键是红黑树结构,可以自然排序和比较器排序。
Map里面的键和值是否可以为空,答案是:不一定。对于HashMap来说,可以存放null键和null值,而HashTable则不可以。
K - 此映射所维护的键的类型
V - 映射值的类型
Map集合和Collection集合的区别?
* Map集合存储元素是成对出现的,Map集合的键是唯一的,值是可重复的。
* Collection集合存储元素是单独出现的,Collection的儿子Set是唯一的,List是可重复的。
*
注意:
* Map集合的数据结构只针对键有效,跟值无关
*
* Collection集合的数据结构是针对元素有效
Hashtable和HashMap的区别? //HashMap就是用来替代Hashtable的* Hashtable:线程安全,效率低。不允许null键和null值
* HashMap:线程不安全,效率高。允许null键和null值
* 1:添加功能
* V put(K key,V value):添加元素。这个其实还有另一个功能?先不告诉你,等会讲
* 如果键是第一次存储,就直接存储元素,返回null
* 如果键不是第一次存在,就用值把以前的值替换掉,返回以前的值
* 2:删除功能
* void clear():移除所有的键值对元素
* V remove(Object key):根据键删除键值对元素,并把值返回
* 3:判断功能* boolean containsKey(Object key):判断集合是否包含指定的键
* boolean containsValue(Object value):判断集合是否包含指定的值
* boolean isEmpty():判断集合是否为空
* 4:获取功能* V get(Object key):根据键获取值
* Set
* Set
* Collection
* int size():返回集合中的键值对的对数
Map集合的遍历:
A:键找值
a:获取所有键的集合
b:遍历键的集合,得到每一个键
c:根据键到集合中去找值
B:键值对对象找键和值
a:获取所有的键值对对象的集合
b:遍历键值对对象的集合,获取每一个键值对对象
c:根据键值对对象去获取键和值
代码体现:
Map
hm.put("it002","hello");
hm.put("it003","world");
hm.put("it001","java");
//方式1 键找值
** Set
for(String key : set) {
String value = hm.get(key);
System.out.println(key+"---"+value);
}
//方式2 键值对对象找键和值
** Set
** 接口 Map.Entry
for(Map.Entry
String key = me.getKey();
String value = me.getValue();
System.out.println(key+"---"+value);
}
HashMap:是基于哈希表的Map接口实现。
* 此实现提供所有可选的映射操作, 并允许使用 null 值和 null 键。
* 此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
* 由哈希表保证键的唯一性
HashMap
* 键:Student
* 要求:如果两个对象的成员变量值都相同,则为同一个对象。
* //键唯一,而这个判断依赖于HashMap的hashCode()跟equals(Object obj)方法,
* //但Student没有重写这两个方法就可能会出现相同的键,所以我们要用自动生成重写。
* 值:String
LinkedHashMap:是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。
* 由哈希表保证键的唯一性
* 由链表保证键盘的有序(存储和取出的顺序一致)
TreeMap:是基于红黑树的Map接口的实现。该映射根据其键的自然顺序进行排序,
或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
底层数据结构是红黑树。
如何保证元素排序的呢?
自然排序
比较器排序
如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
Collections
Collections:是针对集合进行操作的工具类,都是静态方法。 * 面试题:* Collection和Collections的区别?
* Collection:是单列集合的顶层接口,有子接口List和Set。 //Map双列
* Collections:是针对集合操作的工具类,有对集合进行排序和二分查找的方法
*
* 要知道的方法
* public static
* public static
* 根据指定比较器产生的顺序对指定列表进行排序。
* public static
* public static
* public static void reverse(List list): 反转
* public static void shuffle(List list): 随机置换(随机调动位置。扑克洗牌)
*/