牛客MySQL题库总结(一)
1、INNER JOIN(内连接、等值连接)
作用:获取两个表中的字段匹配关系的记录。
题目分析:
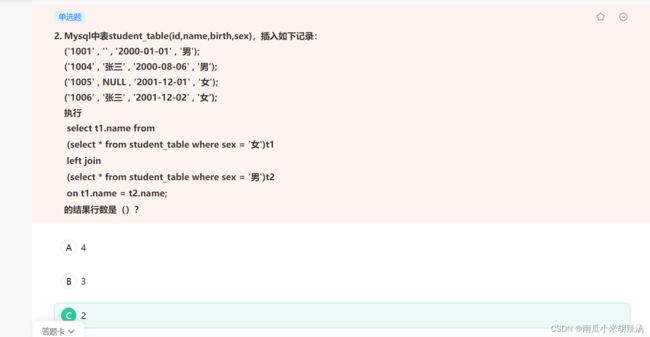
Mysql中表student_table(id,name,birth,sex),插入如下记录:
('1003' , '' , '2000-01-01' , '男');
('1004' , '张三' , '2000-08-06' , '男');
('1005' , NULL , '2001-12-01' , '女');
('1006' , '张三' , '2000-08-06' , '女');
('1007' , ‘王五’ , '2001-12-01' , '男');
('1008' , '李四' , NULL, '女');
('1009' , '李四' , NULL, '男');
('1010' , '李四' , '2001-12-01', '女');
执行
select t1.*,t2.*
from (
select * from student_table where sex = '男' ) t1
inner join
(select * from student_table where sex = '女')t2
on t1.birth = t2.birth and t1.name = t2.name ;
的结果行数是()?

总结:对于如果数据库中的值为null的时候,是不会进行匹配的!!!
2、LEFT JOIN(左连接)
查询的结果以坐标的数据为主,对于右表中不存在的数据进行null进行填充。
提示:在这里需要注意我们根据判断条件删选出来的数据,及时部分属性值为空也没有关系,只要筛选时的判读条件不为空就可以。
举个例子:

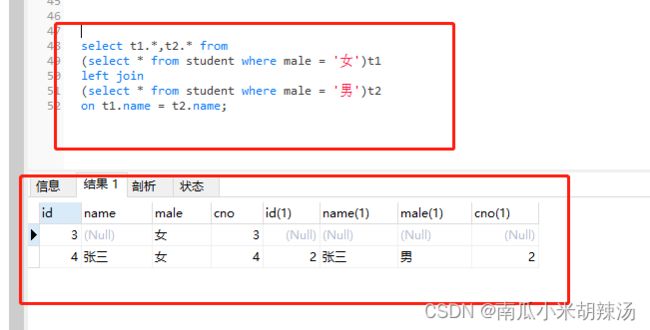
3、RIGHT JOIN(右连接)
其实与左连接相反,右连接则是以右表为主,对于左表中不存在的数据用null进行填充。
注意:在这里你需要注意那一个是左表,那一个是右表!
其实很简单:左表就是left join或者right join前面的那个表中,右表则是指left join或者right join后面的表。
4、聚合函数
count()函数:用于统计数量
avg()函数:统计平均值,适用于数值型数据,对于字符型数据使用这种聚合函数结果为0.
sum()函数:数量求和。适用于数值型数据。
min()函数:指定字段在分组中的最小值。
max()函数:指定字段在分组中的最大值。
注意max(),min()函数,他返回的仅仅是最大值,最小值,而不是最大值、最小值所在的整行数据信息,再次强调返回的是数值,数值,数值!!
=举个例子:=

查询语句:
select subject, max(score)
from score
结果呈现

我们可以发现返回的仅仅是98最高分,但是其对应的科目是不对的!!
提出问题?
如果我们想要一张成绩表中分别求出这张表中各科目的最高分,最低分,以及所对应的学生信息,SQL语句怎么写呢?
(1)学生信息表:student表

(2)成绩信息表:score表
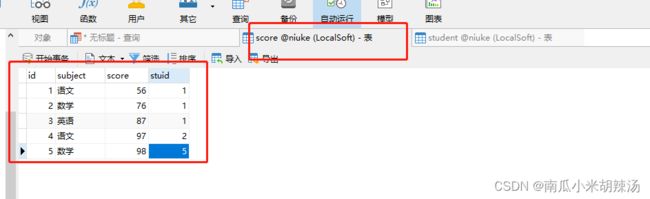
查询语句:
select stu.*,r.subject,r.score
from
(select b.*
from
(select subject,max(score) m
from score
GROUP BY subject) t,
score b
where t.subject = b.subject and t.m = b.score) r,
student stu
where stu.id = r.stuid
结果展示:
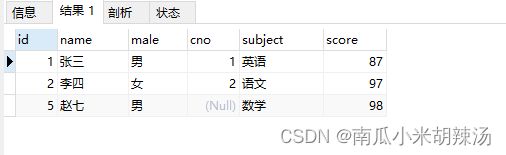
5、注意count(*)和count(列名)的却别和联系?
count(*)会统计会统计值为NULL的行,而count(列名)则会忽略值为NULL的行!
这一点如果在做题的时候一定要注意!!!!
6、Having语句
(1)保证已经被分组之后才能使用
(2)满足Having子句中的条件才能显示
(3)Having语句不能单独使用,必须搭配GROUP BY才能所使用
(4)使用having语句的同时也可以使用where,但是注意where判断条件的位置。
来一个牛客网的例题,在这里重点讲解一下F选项为啥不对!!!

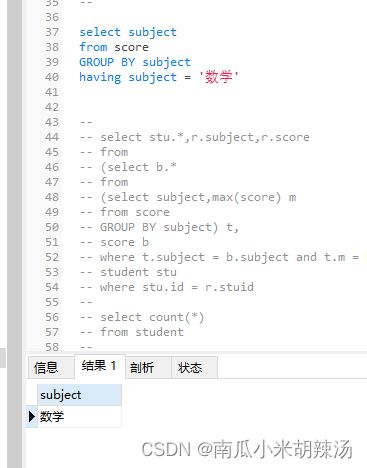
可以看出来没有聚合函数的使用,having也是可以使用的,重点是要搭配GROUP BY才可以!!!
7、去重操作
那么一般有两种比较简单的方法:group by和distinct
=举个例子:=
如果要求统计一张成绩单融合了数学、英语、语文的成绩,但是我们想要知道这张成绩单主要有哪几类的科目?
(1)我们可以对名字这个字段进行distinct方法进行去重,这个也是我们能想到的最简单的方式。
(2)第二种则是利用group by 进行分组查询。
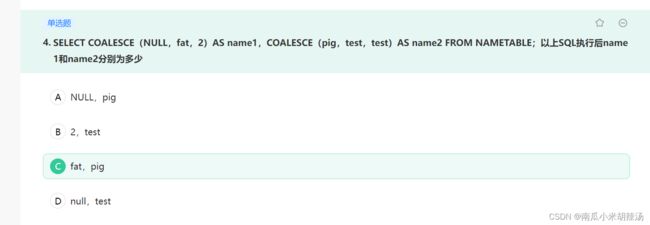
8、coalesce()函数
coalesce()解释:返回参数中的第一个非空表达式(从左向右);
coalesce()函数主要是返回函数参数中第一个非NULL的值。
举个例子:
coalesce(NULL,fat,pig)那么我们函数返回数值为fat。
coalesce(pig,test,test)那么我们这个函数返回的数值为pig。
9、SQL中的@@问题及用法

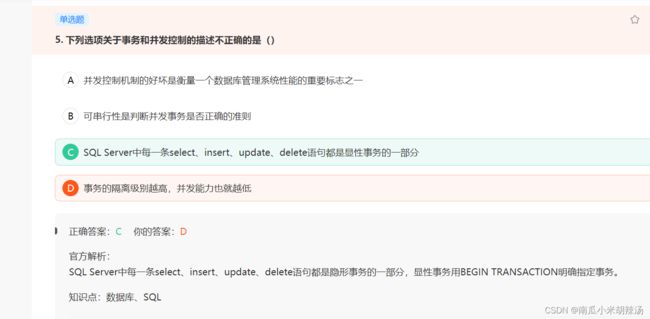
10、显示事务和隐式事务
显示事务和隐式事务:

11、数据库的关系代数运算符:
数据库的关系代数运算符主要分为专门的集合运算符和专门的关系运算符:

选择(σ, selection)、投影(π, projection)、叉乘(x, cross-product)、
差(-, set-difference)和并(υ, union)
它们和SQL语句的对应关系为:
(1) 选择(σ, selection)相当于SQL语句中的where,表示选出满足一定条件的行。如:σ rating>8 (S2)相当于 select * from S2 where rating>8;
(2)投影(π, projection)相当于SQL语句中的select。。。distinct, 表示选择哪些列。注意:投影是会去重的!如:π sname,rating (σ rating>8 (S2))相当于 select sname, rating from S2 where rating>8;
(3)叉乘(x, cross-product)相当于SQL语句中的from,表示穷举所有集合两边元素的组合量如: AxB 相当于 select * from A, B; 注意:叉乘时两个集合不能有重名列
(4)差(-, set-difference)R-S返回所有在R中而不在S中的元组
(5)并(υ, union)RυS返回包含在R中或在S中的所有元组
(6)交(∩)S1∩S2,R∩S 的交既属于R又属于S的元组组成。
(7)=自然连接(⨝) (平时用的比较少,这里简单探讨一下)=
自然连接的结果显示全部的属性列,但是相同属性列只显示一次,显示两个关系模式中属性相同且值相同的记录。
笛卡尔积只要在相同属性上做选择并且投影去掉重复的属性,就可以得到自然连接的结果。
在这里以MYSQL为例,其中的Natural Join语句相当于自然连接。
s1表:
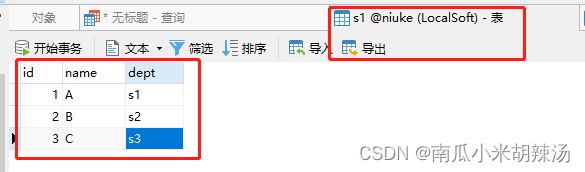
s3表:
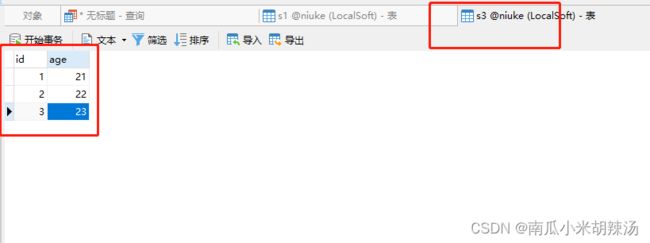
将两个表利用Natural Join进行自然连接,发现对于s3表中的id属性列被取消显示了额!
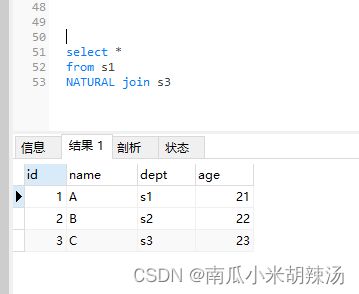
那么如果我们将id属性列的名字进行替换成uid,那么自然连接相当于笛卡尔积形式了!
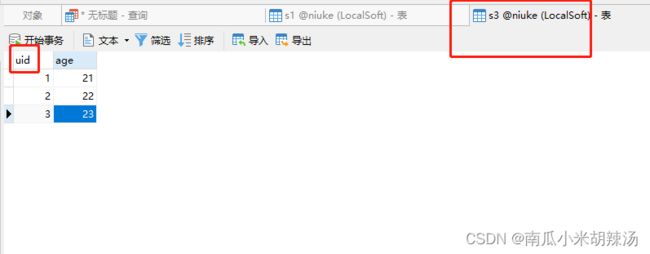

(8)除(÷)
官方解释太严肃了,不容易理解!
举个例子,就懂了!
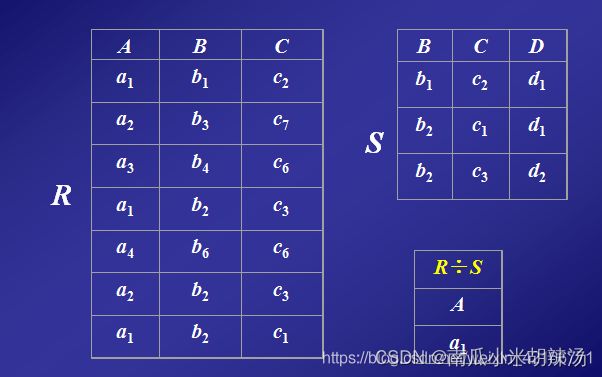
关系R和关系S拥有共同的属性B,C,R➗S得到的属性值就是关系R包含而关系S不包含的属性的,即A属性。
在R关系中A属性的值可以取{a1,a2,a3,a4}
a1对应的象集为{(b1,c2),(b2,c1),(b2.c3)}
a2 对应的象集为{(b3,c7),(b2,c3)}
a3对应的象集为{(b4,c6)}
a4 值对应的象集为{(b6,c6)}
关系S在B,C上的投影为{(b1,c2),(b2,c1),(b2,c3)}
只有a1 的值对应象集包含关系S的投影集,所以只有a1包含在A属性中
所以R➗S为a1。
没找到相应的Mysql实现代码!
12、删除语句
(1)truncate和delete只是删除表中的数据,但是Drop则是删除整个表,包括结构和数据。
(2)注意删除语句的格式问题。
Drop TABLE 表名
Delete from table 表名;
Truncate table 表名
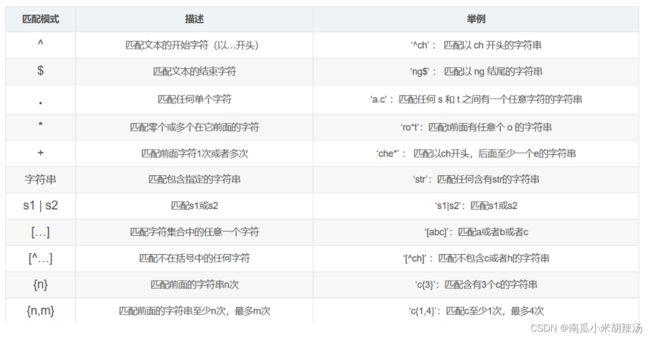
13、正则表达式