牛客网mysql经典题目
特别注意:
mysql日期函数转化:MySQL DATE_FORMAT() 函数
不要使用DISTINCT关键字,要用group by替换。
MySQL_lead()函数_判断同一id同一列两行是否相等。lead()函数
mysql8新特性:
mysql之CTE通用表达式:地址
mysql之窗口函数:窗口函数详解
mysql查询易错题:
SQL23 对所有员工的薪水按照salary降序进行1-N的排名。
select emp_no,salary,
cast(@rownum := @rownum + (@pre <> (@pre := salary)) as signed) as t_rank
from salaries a,(select @rownum := 0) b,(select @pre := -1) c
order by salary desc
mysql关联关系图:

SQL35 批量插入数据,不使用replace操作:
insert IGNORE into actor values(3,'ED','CHASE','2006-02-15 12:34:33');
SQL37 对first_name创建唯一索引uniq_idx_firstname:
对first_name创建唯一索引uniq_idx_firstname,
对last_name创建普通索引idx_lastname
create只能添加这两种索引;
创建普通索引 CREATE INDEX index_name ON table_name (column_list)
创建唯一索引 CREATE UNIQUE INDEX index_name ON table_name (column_list)
多个索引间用分号;连接
1. create (unique) index 索引名 on 表名(列名)
| 1 2 |
|
2. alter table 表名 add (unique) index 索引名(列名)
| 1 2 |
|
SQL38 针对actor表创建视图actor_name_view
create view actor_name_view (first_name_v,last_name_v)
as select first_name,last_name from actor
SQL39 针对上面的salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005,使用强制索引。
select * from salaries force index(idx_emp_no) where emp_no = 10005
SQL41 构造一个触发器audit_log
构造触发器时注意以下几点:
1、用 CREATE TRIGGER 语句构造触发器,用 BEFORE或AFTER 来指定在执行后面的SQL语句之前或之后来触发TRIGGER
2、触发器执行的内容写出 BEGIN与END 之间
3、可以使用 NEW与OLD 关键字访问触发后或触发前的employees_test表单记录
常用关键字解析:
- trigger_name:标识触发器名称,用户自行指定;
- trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
- trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
- tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
- trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句,每条语句结束要分号结尾。
MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中,触发了触发器的那一行数据。具体地:
1.在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
2.在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据;
3.在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;使用方法: NEW.columnName (columnName 为相应数据表某一列名)
create trigger audit_log after insert on employees_test
for each row
begin
insert into audit values (NEW.ID,NEW.NAME);
end;
SQL42 删除emp_no重复的记录:
delete a from titles_test a
join titles_test b
on a.emp_no = b.emp_no
where a.id > b.id
DELETE FROM titles_test
WHERE id NOT IN(
SELECT a.id FROM (
SELECT emp_no,count(*) total,min(id) id
FROM titles_test
GROUP BY emp_no
) a
)
以下两种方法适用于mysql8.0之后版本,需用到窗口函数或者CTE语法:
select * from (
select *,row_number() over(partition by emp_no order by id desc) as num
from titles_test
) a where a.num = 1
with dups as(
select id,row_number() over(partition by emp_no order by emp_no) asrow_no
from titles_test
)
DELETE FROM titles_test
WHERE id IN (
SELECT id
FROM dups
WHERE dups.row_num > 1)
SQL44 将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005,其他数据保持不变,使用replace实现,直接使用update会报错。
REPLACE INTO titles_test VALUES(5,10005,...);
#另一种写法
#UPDATE titles_test SET emp_no = REPLACE(emp_no,10001,10005) WHERE id = 5;
SQL51 查找字符串 10,A,B 中逗号,出现的次数cnt :
select length("10,A,B") - length(replace("10,A,B",",",""))
SQL53 按照dept_no进行汇总(多行拼接成一行):
select dept_no,group_concat(DISTINCT emp_no order by emp_no separator ',')employees
from dept_emp group by dept_no
扩展(一行拆分成多行):
tb_attendance_manager表:
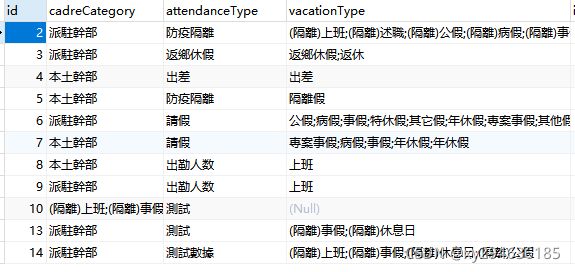
temp表:

select a.cadreCategory,a.attendanceType, substring_index(substring_index(a.vacationType, ';', b.myId + 1), ';', -1) as vacationType from tb_attendance_manager a join tb_temp b on b.myId < (length(a.vacationType) - length(replace(a.vacationType, ';', '')) + 1)
SQL60 统计salary的累计和running_total(重点 循环求和):
1.窗口函数
select emp_no,salary,sum(salary) over(order by emp_no) as running_total
from salaries
where to_date = '9999-01-01'
order by emp_no
2.子查询
select emp_no,salary,(
select sum(b.salary) from salaries b
where b.emp_no <= a.emp_no
and b.to_date = '9999-01-01'
order by b.emp_no
)
from salaries a
where a.to_date = '9999-01-01'
GROUP BY a.emp_no
3.自连接1
select a.emp_no,a.salary,sum(b.salary) as running_total
from salaries a join salaries b on a.emp_no >= b.emp_no
where a.to_date = '9999-01-01'
and b.to_date = '9999-01-01'
group by a.emp_no
order by a.emp_No asc
4.自连接2
select a.emp_no,a.salary,sum(b.salary) as running_total
from salaries a ,salaries b
where a.to_date = '9999-01-01'
and b.tp_date = '9999-01-01'
and a.emp_no >= b.emp_no
group by a.emp_no
order by a.emp_no asc
SQL61 对于employees表中,给出奇数行的first_name(重点 计数排序求奇数行):
1.子查询,查找升序排列的奇数位名称,就可以理解为:比该名称还小的名字有偶数个
select a.first_name from employees a where (select count(*) from employees b where a.first_name >= b.first_name)%2 = 1
2.窗口函数:
select first_name,emp_no,rank() over(order by first_name) as ranking from employees
3.使用临时变量:
select first_name,@norank:=@norank+1 as ra from employees es,(select @norank:=0) t1 order by first_name
SQL63 刷题通过的题目排名(双条件排序)
select id,number,dense_rank() over (order by number desc) t_rank
from passing_number
order by t_rank,id
SQL65 异常的邮件概率(关联条件做运算)
select date,round(sum(type='no_completed')*1.0/count(*),3) as p
from (
select a.date,a.type from email a
left join `user` b on a.send_id = b.id
left join `user` c on a.receive_id = c.id
and b.is_blacklist = 0 and c.is_blacklist
) c group by date
SQL68 牛客每个人最近的登录日期(自链接查询连续两天都出现的数据)
select round(count(c.user_id)/count(b.user_id),3) from(
select a.user_id,min(a.date) date from login a group by user_id
) b left join login c on b.user_id = c.user_id
and b.date = DATE_SUB(c.date,interval 1 day)
SQL69 牛客每个人最近的登录日期(查询每天新用户数量)
#明确问题:登录的当前日期=该用户所有登录日期的最小值
窗口函数:
select a.date,sum(case when num=1 then 1 else 0 end) new from (
select date,row_number() over(partition by user_id order by date) as num
from login
)a group by date
计数神器——sum+case方法
| 1 2 3 4 5 6 7 |
|
SQL70 牛客每个人最近的登录日期(五 难)
简单方法:
select a.date,(case when round(count(b.old)/count(a.new),3)
then round(count(b.old)/count(a.new),3)
else 0.000 end)
from (
T1(首次登录标记为1,作为新用户标签,记作new_u):
select user_id,date,(
case when (user_id,date) in (
select user_id,min(date) from login group by user_id
) then 1 else null end
) as new from login
)a left join (
T2(次日登录标记为2,作为次日留存标签,记作rlog):
select user_id,date,2 as old
from login
where (user_id,date)
in (select user_id,date_add(date,interval 1 day) from login)
)b on a.user_id = b.user_id group by date
T1和T2进行左连接(T1为全表,进行左连接可将次日登录标签进行(2\None)标记)
对new_u和rlog进行计数,次日登录标签总数/新用户标签总数(rlog/new_u)即可完成此答题
备注:由于题目需要将不存在表示为0.000,这里使用case方法进行值分配(不为空则为计数值,为空则为0.000)
使用2个窗口函数:第一个窗口函数看用户是否次日登陆,第二个窗口函数看用户是否计入当日新用户。
select b.date,round(ifnull(su/tal,0),3) from (
select date ,count(*) su from(
select user_id,date,lead(date,1) over(partition by user_id order by date) old,
rank() over(partition by user_id order by date) myrank from login
) b where datediff(old,date) = 1
group by date
) a right join (
select sum(case when c.new = 1 then 1 else 0 end) tal,date from(
select date,rank() over(partition by user_id order by date) new from login
)c group by date
) b on a.date =b.date
SQL71 牛客每个人最近的登录日期(六)
使用窗口函数SUM,将日期作为“窗口”计算累加刷题数量:
select b.name,a.date,a.num from (
select user_id,date,sum(number) over(partition by user_id order by date) as num
from passing_number ) a
left join user b on a.user_id = b.id order by a.date
使用自联结:
select b.name,a.date,a.num from (
select a.user_id,a.date,sum(b.number) as num FROM passing_number a,
passing_number b where a.date >= b.date and a.user_id = b.user_id
group by a.date,a.user_id
)a left join user b on a.user_id = b.id group by a.user_id,a.date order by a.date,b.name
SQL75 考试分数(四)(求奇数 偶数方法)
求中位数,只需要知道每个岗位的总数,用聚合函数count;得出总数后,再分奇/偶讨论中位数;
偶数:start=count/2,end=count/2+1;
奇数:start=count/2,得到的会是x.5,用round取整;end同理
select a.job,
case when(a.c%2=0) then round((a.c/2),0) else (round(a.c/2,0)) end as start,
case when(a.c%2=0) then round((a.c/2+1),0) else (round(a.c/2,0)) end as end
from(
select job,count(*) c
from grade
group by job
) a
order by a.job asc
SQL76 考试分数(五)(有点难,头疼)
select a.id,a.job,a.score,a.rank from (
select id,score,row_number() over(partition by job order by score desc) as `rank`,job from grade
) a inner join (
select b.job,
case when(b.num%2=0) then round((b.num/2),0) else (round(b.num/2,0)) end as start,
case when(b.num%2=0) then round((b.num/2+1),0) else (round(b.num/2,0)) end as end
from grade a right join (
select count(job) num,job from grade group by job
) b on 1=1 group by b.job
) b on a.job = b.job and (a.rank = b.start or a.rank = b.end) order by a.id
扩展操作:
柏拉图求递增:
SELECT TP,TJ,SC,SR,SUM(SR) OVER(ORDER BY TJ DESC ROWS BETWEEN UNBOUNDED PRECEDING AND 0 PRECEDING) AS PS,TP TPNAME
FROM (SELECT AA.REGION TP,COUNT(ID) TJ,SUM(COUNT(ID)) OVER(PARTITION BY AA.REGION) SC,ROUND(SUM(COUNT(ID)) OVER(PARTITION BY AA.REGION) / SUM(COUNT(ID)) OVER(),4) SR
FROM (SELECT DOA.ID,DOA.REGION
FROM T_QM_CHECKIN_INFO DOA
LEFT JOIN T_KOF_CALENDARS TKC
ON TO_CHAR(DOA.RETURN_TIME, 'YYYY-MM-DD') = TKC.DD
) AA
WHERE AA.MON>='2021-01' and AA.MON<='2022-01'
GROUP BY AA.REGION
ORDER BY SC
) BB ORDER BY TJ DESC, TP, SC, SR