文本内关键字关联挖掘&图谱可视化
提取文本内出现的产品,做关联分析,并进行可视化。
1、文本内产品提取与关联规则挖掘
import pandas as pd
#生成相似度百分比
import jieba
import jieba.posseg as pseg
from gensim import corpora, models, similarities
import xlrd
import numpy as np
import pandas as pd
def StopWordsList(filepath):
wlst = [w.strip() for w in open(filepath, 'r', encoding='utf-8').readlines()]
return wlst
def excel2matrix(path): #将excel表转换成numpy,datamatrix是全部的数组,cv是excel的第二列
data = xlrd.open_workbook(path)
table = data.sheets()[0]
nrows = table.nrows # 行数
ncols = table.ncols # 列数
cv=table.col_values(1)
# datamatrix = np.zeros((nrows, ncols))
# for i in range(ncols):
# cols = table.col_values(i)
# datamatrix[:, i] = cols
# return datamatrix,cv
return cv
def cunchu_excel(z,path_b): #再把数组转换成excel,z为数组,path为路径
a_pd = pd.DataFrame(z)
# create writer to write an excel file
writer = pd.ExcelWriter('{}'.format(path_b))
# write in ro file, 'sheet1' is the page title, float_format is the accuracy of data
a_pd.to_excel(writer, 'sheet1', float_format='%.6f')
# save file
writer.save()
# close writer
writer.close()
def seg_sentence(sentence, stop_words):
'''
{标点符号、连词、助词、副词、介词、时语素、‘的’、数词、方位词、代词}
{'x', 'c', 'u', 'd', 'p', 't', 'uj', 'm', 'f', 'r'}
去除文章中特定词性的词
:content str
:return list[str]
'''
# stop_flag = ['x', 'c', 'u', 'd', 'p', 't', 'uj', 'm', 'f', 'r']#过滤数字m
stop_flag = ['x', 'c', 'u', 'd', 'p', 't', 'uj', 'f', 'r']
sentence_seged = pseg.cut(sentence)
# sentence_seged = set(sentence_seged)
outstr = []
for word, flag in sentence_seged:
# if word not in stop_words:
if word not in stop_words and flag not in stop_flag:
outstr.append(word)
return outstr
import pandas as pd
import numpy as np
def createC1(dataSet) :
print('存放')
"""
功能:将所有元素转换为frozenset型字典,存放到列表中
:param dataSet: 原始数据集合
:return: 最初的候选频繁项
"""
C1 = []
for transaction in dataSet :
for item in transaction :
if not [item] in C1 :
C1.append([item])
C1.sort()
# 使用frozenset是为了后面可以将这些值作为字典的键
return list(map(frozenset, C1)) # frozenset一种不可变的集合,set可变集合
def scanD(D, Ck, minSupport) :
print('过滤不符合')
"""
函数功能:过滤掉不符合支持度的集合
具体逻辑:
遍历原始数据集合候选频繁项集,统计频繁项集出现的次数,
由此计算出支持度,在比对支持度是否满足要求,
不满足则剔除,同时保留每个数据的支持度。
:param D: 原始数据转化后的字典
:param Ck: 候选频繁项集
:param minSupport: 最小支持度
:return: 频繁项集列表retList 所有元素的支持度字典
"""
ssCnt = {}
for tid in D :
for can in Ck :
if can.issubset(tid) : # 判断can是否是tid的《子集》 (这里使用子集的方式来判断两者的关系)
if can not in ssCnt : # 统计该值在整个记录中满足子集的次数(以字典的形式记录,frozenset为键)
ssCnt[can] = 1
else :
ssCnt[can] += 1
numItems = float(len(D))
retList = [] # 重新记录满足条件的数据值(即支持度大于阈值的数据)
supportData = {} # 每个数据值的支持度
for key in ssCnt :
support = ssCnt[key] / numItems
if support >= minSupport :
retList.insert(0, key)
supportData[key] = support
print('过滤完成')
return retList, supportData # 排除不符合支持度元素后的元素 每个元素支持度
def aprioriGen(Lk, k) :
print('生成组合')
"""
功能: 生成所有可以组合的集合
具体逻辑:通过每次比对频繁项集相邻的k-2个元素是否相等,如果相等就构造出一个新的集合
:param Lk: 频繁项集列表Lk
:param k: 项集元素个数k,当前组成项集的个数
:return: 频繁项集列表Ck
举例:[frozenset({2, 3}), frozenset({3, 5})] -> [frozenset({2, 3, 5})]
"""
retList = []
lenLk = len(Lk)
for i in range(lenLk) : # 两层循环比较Lk中的每个元素与其它元素
for j in range(i + 1, lenLk) :
L1 = list(Lk[i])[:k - 2] # 将集合转为list后取值
L2 = list(Lk[j])[:k - 2]
L1.sort();
L2.sort() # 这里说明一下:该函数每次比较两个list的前k-2个元素,如果相同则求并集得到k个元素的集合
if L1 == L2 :
retList.append(Lk[i] | Lk[j]) # 求并集
return retList # 返回频繁项集列表Ck
def apriori(dataSet, minSupport=0.5) :
print('算法实现')
"""
function:apriori算法实现
:param dataSet: 原始数据集合
:param minSupport: 最小支持度
:return: 所有满足大于阈值的组合 集合支持度列表
"""
D = list(map(set, dataSet)) # 转换列表记录为字典,为了方便统计数据项出现的次数
C1 = createC1(dataSet) # 将每个元素转会为frozenset字典 [frozenset({A}), frozenset({B}), frozenset({C}), frozenset({D}), frozenset({E})]
# 初始候选频繁项集合
L1, supportData = scanD(D, C1, minSupport) # 过滤数据,去除不满足最小支持度的项
# L1 频繁项集列表 supportData 每个项集对应的支持度
L = [L1]
k = 2
print(k)
Ck = aprioriGen(L[k - 2], k) # Ck候选频繁项集
Lk, supK = scanD(D, Ck, minSupport) # Lk频繁项集
supportData.update(supK) # 更新字典(把新出现的集合:支持度加入到supportData中)
L.append(Lk)
# while (len(L[k - 2]) > 0) : # 若仍有满足支持度的集合则继续做关联分析
# print(k)
# Ck = aprioriGen(L[k - 2], k) # Ck候选频繁项集
# Lk, supK = scanD(D, Ck, minSupport) # Lk频繁项集
# supportData.update(supK) # 更新字典(把新出现的集合:支持度加入到supportData中)
# L.append(Lk)
# k += 1 # 每次新组合的元素都只增加了一个,所以k也+1(k表示元素个数)
return L, supportData
def calcConf(freqSet, H, supportData, brl, minConf=0.7) :
"""
对规则进行评估 获得满足最小可信度的关联规则
:param freqSet: 集合元素大于两个的频繁项集
:param H:频繁项单个元素的集合列表
:param supportData:频繁项对应的支持度
:param brl:关联规则
:param minConf:最小可信度
"""
prunedH = [] # 创建一个新的列表去返回
for conseq in H :
conf = supportData[freqSet] / supportData[freqSet - conseq] # 计算置信度
if conf >= minConf :
# print(supportData[freqSet]*1800)
print(freqSet - conseq,'-->',conseq,'conf:',conf,'个数:',supportData[freqSet]*1800*conf)
brl.append((freqSet - conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7) :
"""
功能:生成候选规则集合
:param freqSet: 集合元素大于两个的频繁项集
:param H:频繁项单个元素的集合列表
:param supportData:频繁项对应的支持度
:param brl:关联规则
:param minConf:最小可信度
:return:
"""
m = len(H[0])
if (len(freqSet) > (m + 1)) : # 尝试进一步合并
Hmp1 = aprioriGen(H, m + 1) # 将单个集合元素两两合并
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1) : # need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
def generateRules(L, supportData, minConf=0.7) : # supportData 是一个字典
print('开始计算函数')
"""
功能:获取关联规则的封装函数
:param L:频繁项列表
:param supportData:每个频繁项对应的支持度
:param minConf:最小置信度
:return:强关联规则
"""
bigRuleList = []
for i in range(1, len(L)) : # 从为2个元素的集合开始
for freqSet in L[i] :
# 只包含单个元素的集合列表
H1 = [frozenset([item]) for item in freqSet] # frozenset({2, 3}) 转换为 [frozenset({2}), frozenset({3})]
# 如果集合元素大于2个,则需要处理才能获得规则
if (i > 1) :
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) # 集合元素 集合拆分后的列表 。。。
# print(rules)
else :
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
a=pd.DataFrame(bigRuleList)
print(a)
a.to_csv('guanlian{}.csv'.format(i))
return bigRuleList
if __name__ == '__main__':
spPath = 'nouse.txt'#停用词库
tpath = '测试.txt'#需要进行挖掘的文本
we=[]
we_gua=[]
stop_words = StopWordsList(spPath)
# 1、将【文本集】生产【分词列表】
texts = [seg_sentence(seg, stop_words) for seg in open(tpath, 'r', encoding='utf-8').readlines()]
# 计算出频繁项集合对应的支持度
dataset = texts
L, suppData = apriori(dataset, minSupport=0.04)
rules = generateRules(L, suppData, minConf=0.1)
ddd = pd.DataFrame(rules)
ddd.to_csv('关联结果.csv')#强关联结果保存至.csv文件
输出结果(部分示例)
产品1 产品2 关联度
0 (服务) (团购) 0.242394
1 (团购) (服务) 0.841549
2 (环境) (团购) 0.192881
3 (团购) (环境) 0.820423
4 (口味) (接待) 0.277251
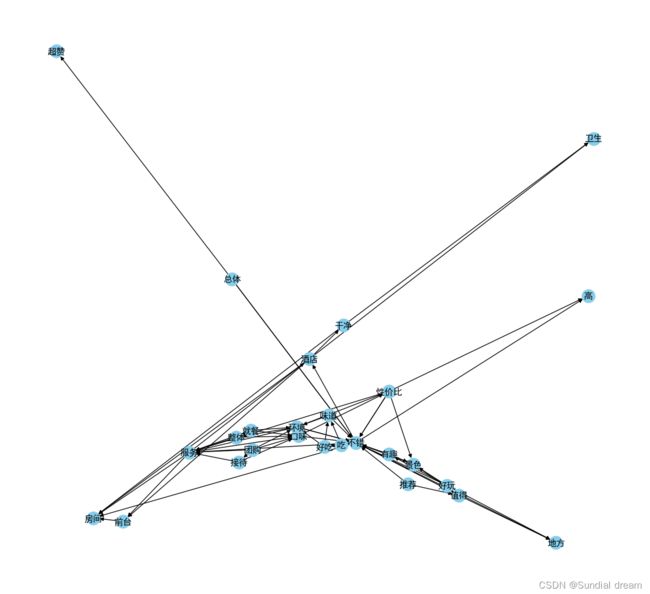
2、图谱可视化
import pandas as pd
import networkx as nx
from pylab import *
from matplotlib.font_manager import FontProperties
import matplotlib.pyplot as plt
mpl.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
dc=pd.read_csv(r'疫情后.csv')
# extract subject
source = dc['0']
# extract object
target = dc['1']
relations=dc['2']
kg_df = pd.DataFrame({'source':source, 'target':target, 'edge':relations})
G=nx.from_pandas_edgelist(kg_df, "source", "target", edge_attr=True, create_using=nx.MultiDiGraph())
plt.figure(figsize=(12,12))
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
pos = nx.spring_layout(G)
nx.draw(G, with_labels=True, node_color='skyblue', edge_cmap=plt.cm.Blues, pos = pos)
plt.show()可视化结果:
不想自己弄数据的同学可以下载上述所用数据【示例数据】