欢迎大家“Fork”,点击右上角的 “ Fork ”,可直接运行并查看代码效果
关注我的专栏 数据挖掘与可视化教程方便第一时间获取更新的项目
- 【B站美食视频图鉴】干饭人干饭魂干饭都是人上人 ✔︎
- 【【多伦多单车数据】车骑好,车停好,车锁好,车才好 ✔︎
- 【中国移动手机用户统计】-为发烧而生 TODO
- 【⛹你是真的蔡】真真假假,假假真真,真亦假时假亦真! TODO
- 全球COVID-19新冠疫苗接种数据分析 ✔︎
- 【️B站热点追溯】二次元世界的星辰大海 ✔︎
- 一饼吃透破产名单:哪些知名公司终究没能撑过疫情 ✔︎
- 【单身人士友好的“理想国”】透过探探的在线社交洞察 ✔︎
- 【♀️七仙女系列】Pandas教程 ✔︎
- 【移动5G套餐潜客识别】7步让你成为机器学习达人 ✔︎
- 【大脑还健康吗】脑中风疾病预测模型✔︎
- 【猜猜你喜欢看什么】从零构建一个电影推荐系统 推荐系统机器学习✔︎
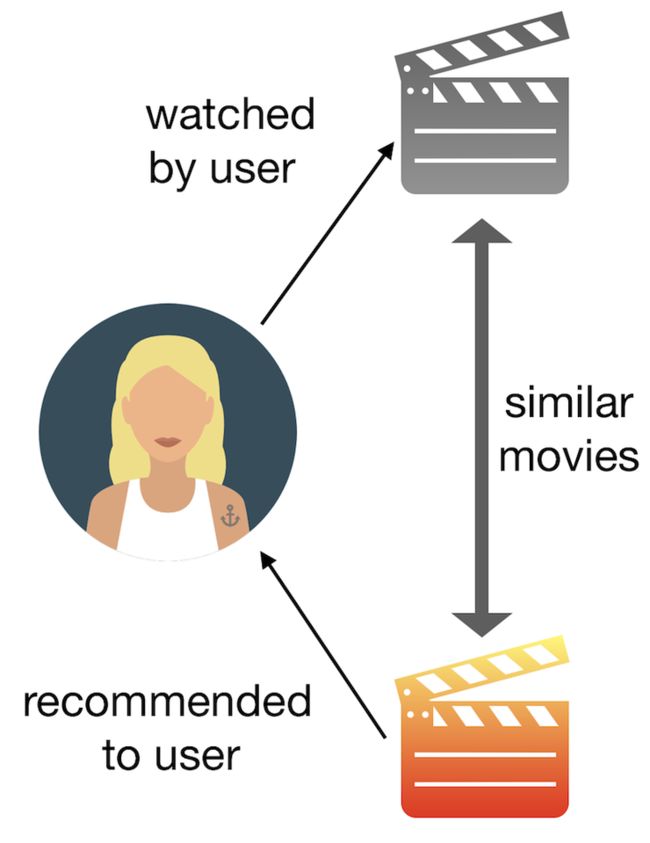
1 简介
这个项目的目标是为Netflix上的电影和电视节目开发一个基于内容的推荐引擎。我们将比较两种不同的方法:
- 使用演员、导演、国家、等级和类型作为特色。
- 用电影/电视节目中的词语作为特征。
2 导入工具包
!pip install nltk pytest -i https://pypi.tuna.tsinghua.edu.cn/simple Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: nltk in /opt/conda/lib/python3.8/site-packages (3.6.1)
Requirement already satisfied: pytest in /opt/conda/lib/python3.8/site-packages (6.2.3)
Requirement already satisfied: regex in /opt/conda/lib/python3.8/site-packages (from nltk) (2021.4.4)
Requirement already satisfied: tqdm in /opt/conda/lib/python3.8/site-packages (from nltk) (4.48.2)
Requirement already satisfied: joblib in /opt/conda/lib/python3.8/site-packages (from nltk) (0.16.0)
Requirement already satisfied: click in /opt/conda/lib/python3.8/site-packages (from nltk) (7.1.2)
Requirement already satisfied: iniconfig in /opt/conda/lib/python3.8/site-packages (from pytest) (1.1.1)
Requirement already satisfied: attrs>=19.2.0 in /opt/conda/lib/python3.8/site-packages (from pytest) (20.1.0)
Requirement already satisfied: pluggy<1.0.0a1,>=0.12 in /opt/conda/lib/python3.8/site-packages (from pytest) (0.13.1)
Requirement already satisfied: packaging in /opt/conda/lib/python3.8/site-packages (from pytest) (20.4)
Requirement already satisfied: toml in /opt/conda/lib/python3.8/site-packages (from pytest) (0.10.2)
Requirement already satisfied: py>=1.8.2 in /opt/conda/lib/python3.8/site-packages (from pytest) (1.10.0)
Requirement already satisfied: six in /opt/conda/lib/python3.8/site-packages (from packaging->pytest) (1.15.0)
Requirement already satisfied: pyparsing>=2.0.2 in /opt/conda/lib/python3.8/site-packages (from packaging->pytest) (2.4.7)`import numpy as np
import pandas as pd
import re
from tqdm import tqdm
import nltkfrom nltk.corpus import stopwords
nltk.download('stopwords')
from nltk.tokenize import word_tokenize`
3 加载数据
# 查看当前挂载的数据集目录 !ls /home/kesci/input/ netflix8714data=pd.read_csv('/home/kesci/input/netflix8714/netflix_titles.csv') data.head() | show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | s1 | TV Show | 3% | NaN | João Miguel, Bianca Comparato, Michel Gomes, R... | Brazil | August 14, 2020 | 2020 | TV-MA | 4 Seasons | International TV Shows, TV Dramas, TV Sci-Fi &... | In a future where the elite inhabit an island ... |
| 1 | s2 | Movie | 7:19 | Jorge Michel Grau | Demián Bichir, Héctor Bonilla, Oscar Serrano, ... | Mexico | December 23, 2016 | 2016 | TV-MA | 93 min | Dramas, International Movies | After a devastating earthquake hits Mexico Cit... |
| 2 | s3 | Movie | 23:59 | Gilbert Chan | Tedd Chan, Stella Chung, Henley Hii, Lawrence ... | Singapore | December 20, 2018 | 2011 | R | 78 min | Horror Movies, International Movies | When an army recruit is found dead, his fellow... |
| 3 | s4 | Movie | 9 | Shane Acker | Elijah Wood, John C. Reilly, Jennifer Connelly... | United States | November 16, 2017 | 2009 | PG-13 | 80 min | Action & Adventure, Independent Movies, Sci-Fi... | In a postapocalyptic world, rag-doll robots hi... |
| 4 | s5 | Movie | 21 | Robert Luketic | Jim Sturgess, Kevin Spacey, Kate Bosworth, Aar... | United States | January 1, 2020 | 2008 | PG-13 | 123 min | Dramas | A brilliant group of students become card-coun... |
data.groupby('type').count() | show_id | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| type | |||||||||||
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Movie | 5377 | 5377 | 5214 | 4951 | 5147 | 5377 | 5377 | 5372 | 5377 | 5377 | 5377 |
| TV Show | 2410 | 2410 | 184 | 2118 | 2133 | 2400 | 2410 | 2408 | 2410 | 2410 | 2410 |
data.isnull().sum() show_id 0
type 0
title 0
director 2389
cast 718
country 507
date_added 10
release_year 0
rating 7
duration 0
listed_in 0
description 0
dtype: int64data.shape (7787, 12)# 删除空值 data = data.dropna(subset=['cast', 'country', 'rating']) data.shape (6652, 12)4 使用cast, director, country, rating 和 genres开发推荐系统
使用演员,导演,国家/地区,评分和类型开发推荐系统
movies = data[data['type'] == 'Movie'].reset_index() movies = movies.drop(['index', 'show_id', 'type', 'date_added', 'release_year', 'duration', 'description'], axis=1) movies.head() | title | director | cast | country | rating | listed_in | |
|---|---|---|---|---|---|---|
| 0 | 7:19 | Jorge Michel Grau | Demián Bichir, Héctor Bonilla, Oscar Serrano, ... | Mexico | TV-MA | Dramas, International Movies |
| 1 | 23:59 | Gilbert Chan | Tedd Chan, Stella Chung, Henley Hii, Lawrence ... | Singapore | R | Horror Movies, International Movies |
| 2 | 9 | Shane Acker | Elijah Wood, John C. Reilly, Jennifer Connelly... | United States | PG-13 | Action & Adventure, Independent Movies, Sci-Fi... |
| 3 | 21 | Robert Luketic | Jim Sturgess, Kevin Spacey, Kate Bosworth, Aar... | United States | PG-13 | Dramas |
| 4 | 122 | Yasir Al Yasiri | Amina Khalil, Ahmed Dawood, Tarek Lotfy, Ahmed... | Egypt | TV-MA | Horror Movies, International Movies |
tv = data[data['type'] == 'TV Show'].reset_index() tv = tv.drop(['index', 'show_id', 'type', 'date_added', 'release_year', 'duration', 'description'], axis=1) tv.head() | title | director | cast | country | rating | listed_in | |
|---|---|---|---|---|---|---|
| 0 | 3% | NaN | João Miguel, Bianca Comparato, Michel Gomes, R... | Brazil | TV-MA | International TV Shows, TV Dramas, TV Sci-Fi &... |
| 1 | 46 | Serdar Akar | Erdal Beşikçioğlu, Yasemin Allen, Melis Birkan... | Turkey | TV-MA | International TV Shows, TV Dramas, TV Mysteries |
| 2 | 1983 | NaN | Robert Więckiewicz, Maciej Musiał, Michalina O... | Poland, United States | TV-MA | Crime TV Shows, International TV Shows, TV Dramas |
| 3 | SAINT SEIYA: Knights of the Zodiac | NaN | Bryson Baugus, Emily Neves, Blake Shepard, Pat... | Japan | TV-14 | Anime Series, International TV Shows |
| 4 | #blackAF | NaN | Kenya Barris, Rashida Jones, Iman Benson, Genn... | United States | TV-MA | TV Comedies |
4.1 演员one hot 编码
- 获取演员列表
- 独热编码
`# 首先获取所有的演员列表
actors = []
for i in movies['cast']:
actor = re.split(r', \s*', i)
actors.append(actor)flat_list = []
for sublist in actors:
for item in sublist:
flat_list.append(item)actors_list = sorted(set(flat_list))
len(actors_list)`
22622我们可以看到有一共有22622个演员
# 打印前10个演员 actors_list[:10] ['"Riley" Lakdhar Dridi',
"'Najite Dede",
'4Minute',
'50 Cent',
'A. Murat Özgen',
'A.C. Peterson',
'A.J. Cook',
'A.J. LoCascio',
'A.K. Hangal',
'A.R. Rahman']`binary_actors = [[0] * 0 for i in range(len(set(flat_list)))]遍历所有的数据
for i in tqdm(movies['cast']):
k = 0
# 遍历所有的演员
for j in actors_list:
# 如果演员名字出现在作品演员列表里,那么对应位置设置为1
# 例如João Miguel存在于João Miguel, Bianca Comparato, Michel Gomes
# 那么João Miguel所在actors_list的位置设置为1
if j in i:
binary_actors[k].append(1.0)
else:
# 如果演员名字没有出现在作品演员列表里,那么对应位置设置为0
binary_actors[k].append(0.0)
k+=1这样我们对每一条数据得到一个22622维度的独热编码向量
binary_actors = pd.DataFrame(binary_actors).transpose()
binary_actors`
100%|██████████| 4761/4761 [00:56<00:00, 84.33it/s]| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 22612 | 22613 | 22614 | 22615 | 22616 | 22617 | 22618 | 22619 | 22620 | 22621 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4756 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4757 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4758 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4759 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4760 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
4761 rows × 22622 columns
以下其他变量的独热编码获取思路同上
4.2 导演one hot 编码
- 获取导演列表
- 独热编码
`directors = []for i in movies['director']:
if pd.notna(i):
director = re.split(r', \s*', i)
directors.append(director)flat_list2 = []
for sublist in directors:
for item in sublist:
flat_list2.append(item)directors_list = sorted(set(flat_list2))
binary_directors = [[0] * 0 for i in range(len(set(flat_list2)))]
for i in tqdm(movies['director']):
k = 0
for j in directors_list:
if pd.isna(i):
binary_directors[k].append(0.0)
elif j in i:
binary_directors[k].append(1.0)
else:
binary_directors[k].append(0.0)
k+=1binary_directors = pd.DataFrame(binary_directors).transpose()
binary_directors.head()`
100%|██████████| 4761/4761 [00:14<00:00, 337.39it/s]| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 3823 | 3824 | 3825 | 3826 | 3827 | 3828 | 3829 | 3830 | 3831 | 3832 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 3833 columns
4.3 国家one hot 编码
- 获取导演列表
- 独热编码
`countries = []for i in movies['country']:
country = re.split(r', \s*', i)
countries.append(country)flat_list3 = []
for sublist in countries:
for item in sublist:
flat_list3.append(item)countries_list = sorted(set(flat_list3))
binary_countries = [[0] * 0 for i in range(len(set(flat_list3)))]
for i in tqdm(movies['country']):
k = 0
for j in countries_list:
if j in i:
binary_countries[k].append(1.0)
else:
binary_countries[k].append(0.0)
k+=1binary_countries = pd.DataFrame(binary_countries).transpose()
binary_countries.head()`
100%|██████████| 4761/4761 [00:00<00:00, 35151.57it/s]| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 95 | 96 | 97 | 98 | 99 | 100 | 101 | 102 | 103 | 104 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 105 columns
4.4 题材one hot 编码
- 获取题材列表
- 独热编码
`genres = []for i in movies['listed_in']:
genre = re.split(r', \s*', i)
genres.append(genre)flat_list4 = []
for sublist in genres:
for item in sublist:
flat_list4.append(item)genres_list = sorted(set(flat_list4))
binary_genres = [[0] * 0 for i in range(len(set(flat_list4)))]
for i in tqdm(movies['listed_in']):
k = 0
for j in genres_list:
if j in i:
binary_genres[k].append(1.0)
else:
binary_genres[k].append(0.0)
k+=1binary_genres = pd.DataFrame(binary_genres).transpose()
binary_genres.head()`
100%|██████████| 4761/4761 [00:00<00:00, 198223.96it/s]| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
4.5 评分one hot 编码
- 获取评分列表
- 独热编码
`ratings = []for i in movies['rating']:
ratings.append(i)ratings_list = sorted(set(ratings))
binary_ratings = [[0] * 0 for i in range(len(set(ratings_list)))]
for i in tqdm(movies['rating']):
k = 0
for j in ratings_list:
if j in i:
binary_ratings[k].append(1.0)
else:
binary_ratings[k].append(0.0)
k+=1binary_ratings = pd.DataFrame(binary_ratings).transpose()
binary_ratings`
100%|██████████| 4761/4761 [00:00<00:00, 294134.44it/s]| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4756 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4757 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4758 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4759 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4760 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
4761 rows × 14 columns
最后我们将5个特征向量进行拼接在一起
binary = pd.concat([binary_actors, binary_directors, binary_countries, binary_genres], axis=1,ignore_index=True) binary | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 26570 | 26571 | 26572 | 26573 | 26574 | 26575 | 26576 | 26577 | 26578 | 26579 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4756 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4757 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4758 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4759 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4760 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
4761 rows × 26580 columns
以上为电影所有特征向量的独热编码获取思路,接下来我们对电视节目tv也做同样的操作
`actors2 = []for i in tv['cast']:
actor2 = re.split(r', \s*', i)
actors2.append(actor2)flat_list5 = []
for sublist in actors2:
for item in sublist:
flat_list5.append(item)actors_list2 = sorted(set(flat_list5))
binary_actors2 = [[0] * 0 for i in range(len(set(flat_list5)))]
for i in tv['cast']:
k = 0
for j in actors_list2:
if j in i:
binary_actors2[k].append(1.0)
else:
binary_actors2[k].append(0.0)
k+=1binary_actors2 = pd.DataFrame(binary_actors2).transpose()
countries2 = []
for i in tv['country']:
country2 = re.split(r', \s*', i)
countries2.append(country2)flat_list6 = []
for sublist in countries2:
for item in sublist:
flat_list6.append(item)countries_list2 = sorted(set(flat_list6))
binary_countries2 = [[0] * 0 for i in range(len(set(flat_list6)))]
for i in tv['country']:
k = 0
for j in countries_list2:
if j in i:
binary_countries2[k].append(1.0)
else:
binary_countries2[k].append(0.0)
k+=1binary_countries2 = pd.DataFrame(binary_countries2).transpose()
genres2 = []
for i in tv['listed_in']:
genre2 = re.split(r', \s*', i)
genres2.append(genre2)flat_list7 = []
for sublist in genres2:
for item in sublist:
flat_list7.append(item)genres_list2 = sorted(set(flat_list7))
binary_genres2 = [[0] * 0 for i in range(len(set(flat_list7)))]
for i in tv['listed_in']:
k = 0
for j in genres_list2:
if j in i:
binary_genres2[k].append(1.0)
else:
binary_genres2[k].append(0.0)
k+=1binary_genres2 = pd.DataFrame(binary_genres2).transpose()
ratings2 = []
for i in tv['rating']:
ratings2.append(i)ratings_list2 = sorted(set(ratings2))
binary_ratings2 = [[0] * 0 for i in range(len(set(ratings_list2)))]
for i in tv['rating']:
k = 0
for j in ratings_list2:
if j in i:
binary_ratings2[k].append(1.0)
else:
binary_ratings2[k].append(0.0)
k+=1binary_ratings2 = pd.DataFrame(binary_ratings2).transpose()
binary2 = pd.concat([binary_actors2, binary_countries2, binary_genres2], axis=1, ignore_index=True)
binary2`
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 12741 | 12742 | 12743 | 12744 | 12745 | 12746 | 12747 | 12748 | 12749 | 12750 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1886 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1887 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1888 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1889 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1890 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
1891 rows × 12751 columns
4.6 基于特征向量的相似性影视推荐
`def recommender(search):
cs_list = [] # 存放余弦相似度结果
binary_list = []# 判断搜索的title是电影还是电视节目 if search in movies['title'].values: # 获取查询作品的特征向量 idx = movies[movies['title'] == search].index.item() for i in binary.iloc[idx]: binary_list.append(i) point1 = np.array(binary_list).reshape(1, -1) point1 = [val for sublist in point1 for val in sublist] # 获取所有候选集作品的特征向量 for j in tqdm(range(len(movies)),desc="searching"): binary_list2 = [] for k in binary.iloc[j]: binary_list2.append(k) point2 = np.array(binary_list2).reshape(1, -1) point2 = [val for sublist in point2 for val in sublist] # 计算查询作品特征向量与当前候选作品特征向量的余弦相似度 dot_product = np.dot(point1, point2) norm_1 = np.linalg.norm(point1) norm_2 = np.linalg.norm(point2) cos_sim = dot_product / (norm_1 * norm_2) cs_list.append(cos_sim) movies_copy = movies.copy() movies_copy['cos_sim'] = cs_list # 按照cos_sim从大到小进行排序 results = movies_copy.sort_values('cos_sim', ascending=False) results = results[results['title'] != search] # 返回相似度前5的结果 top_results = results.head(5) return(top_results) elif search in tv['title'].values: idx = tv[tv['title'] == search].index.item() for i in binary2.iloc[idx]: binary_list.append(i) point1 = np.array(binary_list).reshape(1, -1) point1 = [val for sublist in point1 for val in sublist] for j in range(len(tv)): binary_list2 = [] for k in binary2.iloc[j]: binary_list2.append(k) point2 = np.array(binary_list2).reshape(1, -1) point2 = [val for sublist in point2 for val in sublist] dot_product = np.dot(point1, point2) norm_1 = np.linalg.norm(point1) norm_2 = np.linalg.norm(point2) cos_sim = dot_product / (norm_1 * norm_2) cs_list.append(cos_sim) tv_copy = tv.copy() tv_copy['cos_sim'] = cs_list results = tv_copy.sort_values('cos_sim', ascending=False) results = results[results['title'] != search] top_results = results.head(5) return(top_results) else: return("Title not in dataset. Please check spelling.")`
4.7 电影推荐
recommender('The Conjuring') searching: 100%|██████████| 4761/4761 [10:52<00:00, 7.30it/s]| title | director | cast | country | rating | listed_in | cos_sim | |
|---|---|---|---|---|---|---|---|
| 1868 | Insidious | James Wan | Patrick Wilson, Rose Byrne, Lin Shaye, Ty Simp... | United States, Canada, United Kingdom | PG-13 | Horror Movies, Thrillers | 0.388922 |
| 968 | Creep | Patrick Brice | Mark Duplass, Patrick Brice | United States | R | Horror Movies, Independent Movies, Thrillers | 0.377964 |
| 1844 | In the Tall Grass | Vincenzo Natali | Patrick Wilson, Laysla De Oliveira, Avery Whit... | Canada, United States | TV-MA | Horror Movies, Thrillers | 0.370625 |
| 969 | Creep 2 | Patrick Brice | Mark Duplass, Desiree Akhavan, Karan Soni | United States | TV-MA | Horror Movies, Independent Movies, Thrillers | 0.356348 |
| 1077 | Desolation | Sam Patton | Jaimi Paige, Alyshia Ochse, Toby Nichols, Clau... | United States | TV-MA | Horror Movies, Thrillers | 0.356348 |
recommender("Dr. Seuss' The Cat in the Hat") searching: 100%|██████████| 4761/4761 [10:51<00:00, 7.31it/s]| title | director | cast | country | rating | listed_in | cos_sim | |
|---|---|---|---|---|---|---|---|
| 2798 | NOVA: Bird Brain | NaN | Craig Sechler | United States | TV-G | Children & Family Movies, Documentaries | 0.372104 |
| 3624 | Sugar High | Ariel Boles | Hunter March | United States | TV-G | Children & Family Movies | 0.372104 |
| 4758 | Zoom | Peter Hewitt | Tim Allen, Courteney Cox, Chevy Chase, Kate Ma... | United States | PG | Children & Family Movies, Comedies | 0.370625 |
| 4624 | What a Girl Wants | Dennie Gordon | Amanda Bynes, Colin Firth, Kelly Preston, Eile... | United States, United Kingdom | PG | Children & Family Movies, Comedies | 0.370625 |
| 3066 | Prince of Peoria: A Christmas Moose Miracle | Jon Rosenbaum | Gavin Lewis, Theodore Barnes, Shelby Simmons, ... | United States | TV-G | Children & Family Movies, Comedies | 0.369800 |
4.8 电视节目推荐
recommender('After Life') 5.使用电影/电视节目描述开发推荐引擎
5.1 划分电影和电视节目数据集
movies_des = data[data['type'] == 'Movie'].reset_index() movies_des = movies_des[['title', 'description']] movies_des.head() | title | description | |
|---|---|---|
| 0 | 7:19 | After a devastating earthquake hits Mexico Cit... |
| 1 | 23:59 | When an army recruit is found dead, his fellow... |
| 2 | 9 | In a postapocalyptic world, rag-doll robots hi... |
| 3 | 21 | A brilliant group of students become card-coun... |
| 4 | 122 | After an awful accident, a couple admitted to ... |
tv_des = data[data['type'] == 'TV Show'].reset_index() tv_des = tv_des[['title', 'description']] tv_des.head() | title | description | |
|---|---|---|
| 0 | 3% | In a future where the elite inhabit an island ... |
| 1 | 46 | A genetics professor experiments with a treatm... |
| 2 | 1983 | In this dark alt-history thriller, a naïve law... |
| 3 | SAINT SEIYA: Knights of the Zodiac | Seiya and the Knights of the Zodiac rise again... |
| 4 | #blackAF | Kenya Barris and his family navigate relations... |
5.2 构建词汇表
stopwords=['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', 'couldn', 'didn', 'doesn', 'hadn', 'hasn', 'haven', 'isn', 'ma', 'mightn', 'mustn', 'needn', 'shan', 'shouldn', 'wasn', 'weren', 'won', 'wouldn'] def word_tokenize(text): return [w.lower() for w in text.split()] `filtered_movies = []
movies_words = []for text in movies_des['description']:
text_tokens = word_tokenize(text)
tokens_without_sw = [word.lower() for word in text_tokens if not word in stopwords]
movies_words.append(tokens_without_sw)
filtered = (" ").join(tokens_without_sw)
filtered_movies.append(filtered)movies_words = [val for sublist in movies_words for val in sublist]
movies_words = sorted(set(movies_words))
movies_des['description_filtered'] = filtered_movies
movies_des.head()`
| title | description | description_filtered | |
|---|---|---|---|
| 0 | 7:19 | After a devastating earthquake hits Mexico Cit... | devastating earthquake hits mexico city, trapp... |
| 1 | 23:59 | When an army recruit is found dead, his fellow... | army recruit found dead, fellow soldiers force... |
| 2 | 9 | In a postapocalyptic world, rag-doll robots hi... | postapocalyptic world, rag-doll robots hide fe... |
| 3 | 21 | A brilliant group of students become card-coun... | brilliant group students become card-counting ... |
| 4 | 122 | After an awful accident, a couple admitted to ... | awful accident, couple admitted grisly hospita... |
`filtered_tv = []
tv_words = []
for text in tv_des['description']:
text_tokens = word_tokenize(text)
tokens_without_sw = [word.lower() for word in text_tokens if not word in stopwords]
tv_words.append(tokens_without_sw)
filtered = (" ").join(tokens_without_sw)
filtered_tv.append(filtered)tv_words = [val for sublist in tv_words for val in sublist]
tv_words = sorted(set(tv_words))
tv_des['description_filtered'] = filtered_tv
tv_des.head()`
| title | description | description_filtered | |
|---|---|---|---|
| 0 | 3% | In a future where the elite inhabit an island ... | future elite inhabit island paradise far crowd... |
| 1 | 46 | A genetics professor experiments with a treatm... | genetics professor experiments treatment comat... |
| 2 | 1983 | In this dark alt-history thriller, a naïve law... | dark alt-history thriller, naïve law student w... |
| 3 | SAINT SEIYA: Knights of the Zodiac | Seiya and the Knights of the Zodiac rise again... | seiya knights zodiac rise protect reincarnatio... |
| 4 | #blackAF | Kenya Barris and his family navigate relations... | kenya barris family navigate relationships, ra... |
5.3 构建文本one hot表示向量
`movie_word_binary = [[0] * 0 for i in range(len(set(movies_words)))]for des in movies_des['description_filtered']:
k = 0
for word in movies_words:
if word in des:
movie_word_binary[k].append(1.0)
else:
movie_word_binary[k].append(0.0)
k+=1movie_word_binary = pd.DataFrame(movie_word_binary).transpose()`
`tv_word_binary = [[0] * 0 for i in range(len(set(tv_words)))]for des in tv_des['description_filtered']:
k = 0
for word in tv_words:
if word in des:
tv_word_binary[k].append(1.0)
else:
tv_word_binary[k].append(0.0)
k+=1tv_word_binary = pd.DataFrame(tv_word_binary).transpose()`
5.4 基于内容的影视作品推荐
def recommender2(search): cs_list = [] binary_list = [] if search in movies_des['title'].values: idx = movies_des[movies_des['title'] == search].index.item() for i in movie_word_binary.iloc[idx]: binary_list.append(i) point1 = np.array(binary_list).reshape(1, -1) point1 = [val for sublist in point1 for val in sublist] for j in tqdm(range(len(movies_des))): binary_list2 = [] for k in movie_word_binary.iloc[j]: binary_list2.append(k) point2 = np.array(binary_list2).reshape(1, -1) point2 = [val for sublist in point2 for val in sublist] dot_product = np.dot(point1, point2) norm_1 = np.linalg.norm(point1) norm_2 = np.linalg.norm(point2) cos_sim = dot_product / (norm_1 * norm_2) cs_list.append(cos_sim) movies_copy = movies_des.copy() movies_copy['cos_sim'] = cs_list results = movies_copy.sort_values('cos_sim', ascending=False) results = results[results['title'] != search] top_results = results.head(5) return(top_results) elif search in tv_des['title'].values: idx = tv_des[tv_des['title'] == search].index.item() for i in tv_word_binary.iloc[idx]: binary_list.append(i) point1 = np.array(binary_list).reshape(1, -1) point1 = [val for sublist in point1 for val in sublist] for j in tqdm(range(len(tv))): binary_list2 = [] for k in tv_word_binary.iloc[j]: binary_list2.append(k) point2 = np.array(binary_list2).reshape(1, -1) point2 = [val for sublist in point2 for val in sublist] dot_product = np.dot(point1, point2) norm_1 = np.linalg.norm(point1) norm_2 = np.linalg.norm(point2) cos_sim = dot_product / (norm_1 * norm_2) cs_list.append(cos_sim) tv_copy = tv_des.copy() tv_copy['cos_sim'] = cs_list results = tv_copy.sort_values('cos_sim', ascending=False) results = results[results['title'] != search] top_results = results.head(5) return(top_results) else: return("Title not in dataset. Please check spelling.") 5.3 电影推荐
pd.options.display.max_colwidth = 300 recommender2('The Conjuring') 100%|██████████| 4761/4761 [06:03<00:00, 13.11it/s]| title | description | description_filtered | cos_sim | |
|---|---|---|---|---|
| 2549 | Mirai | Unhappy after his new baby sister displaces him, four-year-old Kun begins meeting people and pets from his family's history in their unique house. | unhappy new baby sister displaces him, four-year-old kun begins meeting people pets family's history unique house. | 0.426401 |
| 1632 | Hard Lessons | This drama based on real-life events tells the story of George McKenna, the tough, determined new principal of a notorious Los Angeles high school. | drama based real-life events tells story george mckenna, tough, determined new principal notorious los angeles high school. | 0.376256 |
| 2372 | Macchli Jal Ki Rani Hai | After relocating to a different town with her husband, a housewife begins to sense the existence of a mysterious presence in their new house. | relocating different town husband, housewife begins sense existence mysterious presence new house. | 0.375467 |
| 3910 | The Eyes of My Mother | At the remote farmhouse where she once witnessed a traumatic childhood event, a young woman develops a grisly fascination with violence. | remote farmhouse witnessed traumatic childhood event, young woman develops grisly fascination violence. | 0.371312 |
| 227 | Adrishya | A family’s harmonious existence is interrupted when the young son begins showing symptoms of anxiety that seem linked to disturbing events at home. | family’s harmonious existence interrupted young son begins showing symptoms anxiety seem linked disturbing events home. | 0.367423 |
5.4 电视节目推荐
recommender2('After Life') 100%|██████████| 1891/1891 [01:32<00:00, 20.46it/s]| title | description | description_filtered | cos_sim | |
|---|---|---|---|---|
| 1628 | The Paper | A construction magnate takes over a struggling newspaper and attempts to wield editorial influence for power and personal gain. | construction magnate takes struggling newspaper attempts wield editorial influence power personal gain. | 0.351351 |
| 1848 | Winter Sun | Years after ruthless businessmen kill his father and order the death of his twin brother, a modest fisherman adopts a new persona to exact revenge. | years ruthless businessmen kill father order death twin brother, modest fisherman adopts new persona exact revenge. | 0.311741 |
| 1768 | Under the Black Moonlight | A college art club welcomes a new member who has the secret ability to smell death and who warns one of them to leave her boyfriend ... or else. | college art club welcomes new member secret ability smell death warns one leave boyfriend ... else. | 0.277885 |
| 1180 | Private Practice | At Oceanside Wellness Center, Dr. Addison Montgomery deals with competing personalities in the new world of holistic medicine. | oceanside wellness center, dr. addison montgomery deals competing personalities new world holistic medicine. | 0.275777 |
| 1271 | Santa Clarita Diet | They're ordinary husband and wife realtors until she undergoes a dramatic change that sends them down a road of death and destruction. In a good way. | they're ordinary husband wife realtors undergoes dramatic change sends road death destruction. good way. | 0.256748 |
基于Graph的推荐引擎构建
我们这个教程的主要目的是基于Graph 节点的Adamic Adar指标来推荐相似电影。如果Adamic Adar指标越高,就代表两个节点越相近。
Adamic Adar 指标
Adamic/Adar (Frequency-Weighted Common Neighbors)
Adamic-Adar 简称AA,该指标根据共同邻居的节点的度给每个节点赋予一个权重值,即为每个节点的度的对数分之一。然后把节点对的所有共同邻居的权重值相加,其和作为该节点对的相似度值。
这个方法同样是对Common Neighbors的改进,当我们计算两个相同邻居的数量的时候,其实每个邻居的“重要程度”都是不一样的,我们认为这个邻居的邻居数量越少,就越凸显它作为“中间人”的重要性,毕竟一共只认识那么少人,却恰好是x,y的好朋友。
例如:
- x,y是两个节点(在这个例子中就是两个电影)
- N(one_node)是返回某个节点的相邻节点集合大小的函数,比如x有相邻节点a,b,c那么这个函数就返回3
这个公式的含义就是,比如对于节点x和y,遍历x和y的每一个共同节点u,然后将他们所有的 1/log(N(u))相加
的大小决定了节点u的重要性:
- 如果x和y共享节点u,并且节点u有大量的邻居节点,说明这个节点u越不重要或者越不相关:N(u)值越大,1/log((u))就越小
- 如果x和y共享节点u,并且节点u只有很少的的邻居节点,说明这个节点u越重要或者越相关:N(u)值越小,1/log((u))就越大
这个可以理解我向我们生活中,如果同学A和同学B是通过同学C认识的,而同学C的社交关系很简单或者周围人很少,说明C是能够将A和B强关联的人物
基于Graph的影视推荐系统如何应用文本描述信息?
方法1 将文本的TF-IDF权重作为Kmeans进行无监督聚类
如果两个电影同属于分组,那么这两个电影共享一个节点。如果这个分组内的电影数量越少,该聚类分组对于这两个电影越重要,但是这个结论有可能在”聚类标签之前的样本非常不均衡“的时候失效。
方法2 构建电影的TF-IDF向量表示矩阵
通过获取每一个电影的tfidf向量表示,然后基于余弦相似度获取相似性最高的top5个其他电影,然后创建一个相似节点簇,然后通过Adamin Adar评估该簇
# 导入包 import networkx as nx # 构建Graph import matplotlib.pyplot as plt import pandas as pd import numpy as np import math as math import time plt.style.use('seaborn') plt.rcParams['figure.figsize'] = [14,14] 加载数据集
`# 加载数据
df = pd.read_csv('/home/kesci/input/netflix8714/netflix_titles.csv')转换时间格式:将August 14, 2020字符串转为2020-08-14
df["date_added"] = pd.to_datetime(df['date_added'])
df['year'] = df['date_added'].dt.year # 获取年份
df['month'] = df['date_added'].dt.month # 获取月份
df['day'] = df['date_added'].dt.day # 获取天
df.head()`
| show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | year | month | day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | s1 | TV Show | 3% | NaN | João Miguel, Bianca Comparato, Michel Gomes, R... | Brazil | 2020-08-14 | 2020 | TV-MA | 4 Seasons | International TV Shows, TV Dramas, TV Sci-Fi &... | In a future where the elite inhabit an island ... | 2020.0 | 8.0 | 14.0 |
| 1 | s2 | Movie | 7:19 | Jorge Michel Grau | Demián Bichir, Héctor Bonilla, Oscar Serrano, ... | Mexico | 2016-12-23 | 2016 | TV-MA | 93 min | Dramas, International Movies | After a devastating earthquake hits Mexico Cit... | 2016.0 | 12.0 | 23.0 |
| 2 | s3 | Movie | 23:59 | Gilbert Chan | Tedd Chan, Stella Chung, Henley Hii, Lawrence ... | Singapore | 2018-12-20 | 2011 | R | 78 min | Horror Movies, International Movies | When an army recruit is found dead, his fellow... | 2018.0 | 12.0 | 20.0 |
| 3 | s4 | Movie | 9 | Shane Acker | Elijah Wood, John C. Reilly, Jennifer Connelly... | United States | 2017-11-16 | 2009 | PG-13 | 80 min | Action & Adventure, Independent Movies, Sci-Fi... | In a postapocalyptic world, rag-doll robots hi... | 2017.0 | 11.0 | 16.0 |
| 4 | s5 | Movie | 21 | Robert Luketic | Jim Sturgess, Kevin Spacey, Kate Bosworth, Aar... | United States | 2020-01-01 | 2008 | PG-13 | 123 min | Dramas | A brilliant group of students become card-coun... | 2020.0 | 1.0 | 1.0 |
通过上表输出我们可以已经获取了每个作品的year,month,day
`# 导演列表director,标签列表listed_in,演员列表cast和国家country这些列包含一组值,我们可以按照逗号,进行分割,后去列表值如果还有NAN值,我们就返回一个空列表[]
df['directors'] = df['director'].apply(lambda l: [] if pd.isna(l) else [i.strip() for i in l.split(",")])
df['categories'] = df['listed_in'].apply(lambda l: [] if pd.isna(l) else [i.strip() for i in l.split(",")])
df['actors'] = df['cast'].apply(lambda l: [] if pd.isna(l) else [i.strip() for i in l.split(",")])
df['countries'] = df['country'].apply(lambda l: [] if pd.isna(l) else [i.strip() for i in l.split(",")])df.head(3)`
| show_id | type | title | director | cast | country | date_added | release_year | rating | duration | listed_in | description | year | month | day | directors | categories | actors | countries | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | s1 | TV Show | 3% | NaN | João Miguel, Bianca Comparato, Michel Gomes, R... | Brazil | 2020-08-14 | 2020 | TV-MA | 4 Seasons | International TV Shows, TV Dramas, TV Sci-Fi &... | In a future where the elite inhabit an island ... | 2020.0 | 8.0 | 14.0 | [] | [International TV Shows, TV Dramas, TV Sci-Fi ... | [João Miguel, Bianca Comparato, Michel Gomes, ... | [Brazil] |
| 1 | s2 | Movie | 7:19 | Jorge Michel Grau | Demián Bichir, Héctor Bonilla, Oscar Serrano, ... | Mexico | 2016-12-23 | 2016 | TV-MA | 93 min | Dramas, International Movies | After a devastating earthquake hits Mexico Cit... | 2016.0 | 12.0 | 23.0 | [Jorge Michel Grau] | [Dramas, International Movies] | [Demián Bichir, Héctor Bonilla, Oscar Serrano,... | [Mexico] |
| 2 | s3 | Movie | 23:59 | Gilbert Chan | Tedd Chan, Stella Chung, Henley Hii, Lawrence ... | Singapore | 2018-12-20 | 2011 | R | 78 min | Horror Movies, International Movies | When an army recruit is found dead, his fellow... | 2018.0 | 12.0 | 20.0 | [Gilbert Chan] | [Horror Movies, International Movies] | [Tedd Chan, Stella Chung, Henley Hii, Lawrence... | [Singapore] |
我们可以看到listed_in中International TV Shows, TV Dramas, TV Sci-Fi转为[International TV Shows, TV Dramas, TV Sci-Fi ],其他几列也是
print(df.shape) (7787, 19)基于TF-IDF的Kmeans聚类
`from sklearn.feature_extraction.text import TfidfVectorizer # 构建TFIDF向量
from sklearn.metrics.pairwise import linear_kernel
from sklearn.cluster import MiniBatchKMeans # Kmeans算法构建作品文本描述tfidf矩阵
start_time = time.time()
text_content = df['description']
vector = TfidfVectorizer(max_df=0.4, # 去除文本频率大约0.4的词
min_df=1, # 词语最小出现次数
stop_words='english', # 去除停用词
lowercase=True, # 将大写字母转为小写
use_idf=True, # 使用idf
norm=u'l2', # 正则化
smooth_idf=True # 平滑因子,避免idf为0
)
tfidf = vector.fit_transform(text_content)Kmeans聚类
k = 200# 聚类中心个数
kmeans = MiniBatchKMeans(n_clusters = k)
kmeans.fit(tfidf)
centers = kmeans.cluster_centers_.argsort()[:,::-1]
terms = vector.get_feature_names()request_transform = vector.transform(df['description'])
聚类标签
df['cluster'] = kmeans.predict(request_transform)
df['cluster'].value_counts().head()`
19 7179
39 333
182 6
1 5
144 5
Name: cluster, dtype: int64我们可以看到聚类标签很不均衡,19有7179,39 有333个,所以我们不能基于聚类标签cluster来做节点创建了。
# 输入目标电影描述,查找最相似的topn个电影 def find_similar(tfidf_matrix, index, top_n = 5): cosine_similarities = linear_kernel(tfidf_matrix[index:index+1], tfidf_matrix).flatten() related_docs_indices = [i for i in cosine_similarities.argsort()[::-1] if i != index] return [index for index in related_docs_indices][0:top_n] 影视作品的知识图谱构建
节点定义
节点包括如下 :
- Movies:电影
- Person ( actor or director) :人物
- Categorie:勒边
- Countries:国家
- Cluster (description):描述
- Sim(title) top 5 similar movies in the sense of the description:相似电影电影
边定义
关系包括如下 :
- ACTED_IN:演员和电影之间的关系
- CAT_IN:类别和电影之间的关系
- DIRECTED:导演与电影之间的关系
- COU_IN:国家与电影之间的关系
- DESCRIPTION:聚类标签和电影之间的关系
- SIMILARITY:在描述意义上相似的关系
两部电影不是直接相连的,而是它们共享人物,类别,团伙和国家,所以可以构建联系
`G = nx.Graph(label="MOVIE")
start_time = time.time()
for i, rowi in df.iterrows():
if (i%1000==0):
print(" iter {} -- {} seconds --".format(i,time.time() - start_time))
G.add_node(rowi['title'],key=rowi['show_id'],label="MOVIE",mtype=rowi['type'],rating=rowi['rating'])G.add_node(rowi['cluster'],label="CLUSTER")
G.add_edge(rowi['title'], rowi['cluster'], label="DESCRIPTION")
for element in rowi['actors']: # 创建“演员”节点”,类型为PERSON G.add_node(element,label="PERSON") # 创建作品与演员的关系:ACTED_IN G.add_edge(rowi['title'], element, label="ACTED_IN") for element in rowi['categories']: # 创建“类别标签”节点“,类型为CAT G.add_node(element,label="CAT") # 创建作品与类别标签的关系:CAT_IN G.add_edge(rowi['title'], element, label="CAT_IN") for element in rowi['directors']: # 创建“导演”节点,类别为PERSON G.add_node(element,label="PERSON") # 创建作品与导演的关系:DIRECTED G.add_edge(rowi['title'], element, label="DIRECTED") for element in rowi['countries']: # 创建“国家”节点,类别为COU G.add_node(element,label="COU") # 创建作品与国家的关系:COU_IN G.add_edge(rowi['title'], element, label="COU_IN") # 创建相似作品节点 indices = find_similar(tfidf, i, top_n = 5) # 取相似性最高的top5 snode="Sim("+rowi['title'][:15].strip()+")" G.add_node(snode,label="SIMILAR") G.add_edge(rowi['title'], snode, label="SIMILARITY") for element in indices: G.add_edge(snode, df['title'].loc[element], label="SIMILARITY")print(" finish -- {} seconds --".format(time.time() - start_time))`
iter 0 -- 0.02708911895751953 seconds --
iter 1000 -- 4.080239295959473 seconds --
iter 2000 -- 8.126200675964355 seconds --
iter 3000 -- 12.209706783294678 seconds --
iter 4000 -- 16.362282037734985 seconds --
iter 5000 -- 20.392311811447144 seconds --
iter 6000 -- 24.43456506729126 seconds --
iter 7000 -- 28.474121809005737 seconds --
finish -- 31.648479461669922 seconds --构建Graph
设置不同类型节点的颜色
`def get_all_adj_nodes(list_in):
sub_graph=set()
for m in list_in:
sub_graph.add(m)
for e in G.neighbors(m):
sub_graph.add(e)
return list(sub_graph)
def draw_sub_graph(sub_graph):
subgraph = G.subgraph(sub_graph)
colors=[]
for e in subgraph.nodes():
if G.nodes[e]['label']=="MOVIE":
colors.append('blue')
elif G.nodes[e]['label']=="PERSON":
colors.append('red')
elif G.nodes[e]['label']=="CAT":
colors.append('green')
elif G.nodes[e]['label']=="COU":
colors.append('yellow')
elif G.nodes[e]['label']=="SIMILAR":
colors.append('orange')
elif G.nodes[e]['label']=="CLUSTER":
colors.append('orange')nx.draw(subgraph, with_labels=True, font_weight='bold',node_color=colors) plt.show()`
list_in=["Ocean's Twelve","Ocean's Thirteen"] sub_graph = get_all_adj_nodes(list_in) draw_sub_graph(sub_graph) 
基于影视知识图谱的推荐系统
- 探索目标电影的所在地→这是演员,导演,国家/地区和类别的列表
- 探索每个邻居的邻居→发现与目标字段共享节点的电影
- 计算 Adamic Adar度量→最终结果
`def get_recommendation(root):
commons_dict = {}
for e in G.neighbors(root):
for e2 in G.neighbors(e):
if e2==root:
continue
if G.nodes[e2]['label']=="MOVIE":
commons = commons_dict.get(e2)
if commons==None:
commons_dict.update({e2 : [e]})
else:
commons.append(e)
commons_dict.update({e2 : commons})
movies=[]
weight=[]
for key, values in commons_dict.items():
w=0.0
for e in values:
w=w+1/math.log(G.degree(e))
movies.append(key)
weight.append(w)result = pd.Series(data=np.array(weight),index=movies) result.sort_values(inplace=True,ascending=False) return result;`
推荐结果测试
result = get_recommendation("Ocean's Twelve") result2 = get_recommendation("Ocean's Thirteen") result3 = get_recommendation("The Devil Inside") result4 = get_recommendation("Stranger Things") print("*"*40+"\n Recommendation for 'Ocean's Twelve'\n"+"*"*40) print(result.head()) print("*"*40+"\n Recommendation for 'Ocean's Thirteen'\n"+"*"*40) print(result2.head()) print("*"*40+"\n Recommendation for 'Belmonte'\n"+"*"*40) print(result3.head()) print("*"*40+"\n Recommendation for 'Stranger Things'\n"+"*"*40) print(result4.head()) ****************************************
Recommendation for 'Ocean's Twelve'
****************************************
Ocean's Thirteen 7.033613
Ocean's Eleven 1.528732
The Informant! 1.252955
Babel 1.162454
Cannabis 1.116221
dtype: float64
****************************************
Recommendation for 'Ocean's Thirteen'
****************************************
Ocean's Twelve 7.033613
The Departed 2.232071
Ocean's Eleven 2.086843
Brooklyn's Finest 1.467979
Boyka: Undisputed 1.391627
dtype: float64
****************************************
Recommendation for 'Belmonte'
****************************************
The Boy 1.901648
The Devil and Father Amorth 1.413791
Making a Murderer 1.239666
Belief: The Possession of Janet Moses 1.116221
I Am Vengeance 1.116221
dtype: float64
****************************************
Recommendation for 'Stranger Things'
****************************************
Beyond Stranger Things 12.047956
Rowdy Rathore 2.585399
Big Stone Gap 2.355888
Kicking and Screaming 1.566140
Prank Encounters 1.269862
dtype: float64推荐结果画图展示
reco=list(result.index[:4].values) reco.extend(["Ocean's Twelve"]) sub_graph = get_all_adj_nodes(reco) draw_sub_graph(sub_graph) 
reco=list(result4.index[:4].values) reco.extend(["Stranger Things"]) sub_graph = get_all_adj_nodes(reco) draw_sub_graph(sub_graph) 